Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-maven-eclipse/

前言
Hadoop的MapReduce环境是一个复杂的编程环境,所以我们要尽可能地简化构建MapReduce项目的过程。Maven是一个很不错的自动化项目构建工具,通过Maven来帮助我们从复杂的环境配置中解脱出来,从而标准化开发过程。所以,写MapReduce之前,让我们先花点时间把刀磨快!!当然,除了Maven还有其他的选择Gradle(推荐), Ivy….
后面将会有介绍几篇MapReduce开发的文章,都要依赖于本文中Maven的构建的MapReduce环境。
目录
- Maven介绍
- Maven安装(win)
- Hadoop开发环境介绍
- 用Maven构建Hadoop环境
- MapReduce程序开发
- 模板项目上传github
1. Maven介绍
Apache Maven,是一个Java的项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。
maven的开发者在他们开发网站上指出,maven的目标是要使得项目的构建更加容易,它把编译、打包、测试、发布等开发过程中的不同环节有机的串联了起来,并产生一致的、高质量的项目信息,使得项目成员能够及时地得到反馈。maven有效地支持了测试优先、持续集成,体现了鼓励沟通,及时反馈的软件开发理念。如果说Ant的复用是建立在”拷贝–粘贴”的基础上的,那么Maven通过插件的机制实现了项目构建逻辑的真正复用。
2. Maven安装(win)
下载Maven:http://maven.apache.org/download.cgi
下载最新的xxx-bin.zip文件,在win上解压到 D:\toolkit\maven3
并把maven/bin目录设置在环境变量PATH:
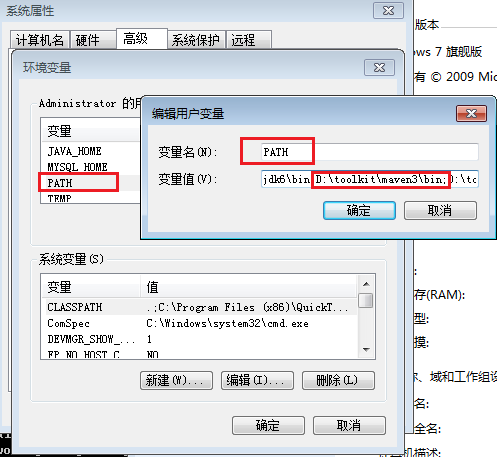
然后,打开命令行输入mvn,我们会看到mvn命令的运行效果
~ C:\Users\Administrator>mvn
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.086s
[INFO] Finished at: Mon Sep 30 18:26:58 CST 2013
[INFO] Final Memory: 2M/179M
[INFO] ------------------------------------------------------------------------
[ERROR] No goals have been specified for this build. You must specify a valid lifecycle phase or a goal in the format : or :[:]:. Available lifecycle phases are: validate, initialize, generate-sources, process-sources, generate-resources, process-resources, compile, process-class
es, generate-test-sources, process-test-sources, generate-test-resources, process-test-resources, test-compile, process-test-classes, test, prepare-package, package, pre-integration-test, integration-test, post-integration-test, verify, install, deploy, pre-clean, clean, post-clean, pre-site, site, post-site, site-deploy. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/NoGoalSpecifiedException
安装Eclipse的Maven插件:Maven Integration for Eclipse
Maven的Eclipse插件配置

3. Hadoop开发环境介绍
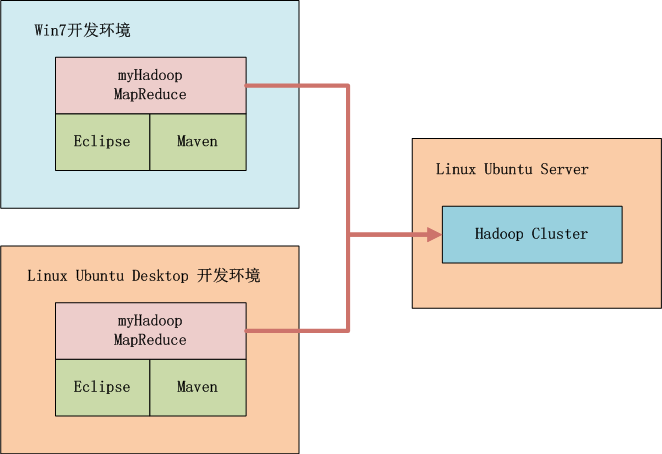
如上图所示,我们可以选择在win中开发,也可以在linux中开发,本地启动Hadoop或者远程调用Hadoop,标配的工具都是Maven和Eclipse。
Hadoop集群系统环境:
- Linux: Ubuntu 12.04.2 LTS 64bit Server
- Java: 1.6.0_29
- Hadoop: hadoop-1.0.3,单节点,IP:192.168.1.210
4. 用Maven构建Hadoop环境
- 1. 用Maven创建一个标准化的Java项目
- 2. 导入项目到eclipse
- 3. 增加hadoop依赖,修改pom.xml
- 4. 下载依赖
- 5. 从Hadoop集群环境下载hadoop配置文件
- 6. 配置本地host
1). 用Maven创建一个标准化的Java项目
~ D:\workspace\java>mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=org.conan.myhadoop.mr
-DartifactId=myHadoop -DpackageName=org.conan.myhadoop.mr -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] >>> maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom >>>
[INFO]
[INFO] <<< maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom <<<
[INFO]
[INFO] --- maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom ---
[INFO] Generating project in Batch mode
[INFO] No archetype defined. Using maven-archetype-quickstart (org.apache.maven.archetypes:maven-archetype-quickstart:1.
0)
Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archet
ype-quickstart-1.0.jar
Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archety
pe-quickstart-1.0.jar (5 KB at 4.3 KB/sec)
Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archet
ype-quickstart-1.0.pom
Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archety
pe-quickstart-1.0.pom (703 B at 1.6 KB/sec)
[INFO] ----------------------------------------------------------------------------
[INFO] Using following parameters for creating project from Old (1.x) Archetype: maven-archetype-quickstart:1.0
[INFO] ----------------------------------------------------------------------------
[INFO] Parameter: groupId, Value: org.conan.myhadoop.mr
[INFO] Parameter: packageName, Value: org.conan.myhadoop.mr
[INFO] Parameter: package, Value: org.conan.myhadoop.mr
[INFO] Parameter: artifactId, Value: myHadoop
[INFO] Parameter: basedir, Value: D:\workspace\java
[INFO] Parameter: version, Value: 1.0-SNAPSHOT
[INFO] project created from Old (1.x) Archetype in dir: D:\workspace\java\myHadoop
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 8.896s
[INFO] Finished at: Sun Sep 29 20:57:07 CST 2013
[INFO] Final Memory: 9M/179M
[INFO] ------------------------------------------------------------------------
进入项目,执行mvn命令
~ D:\workspace\java>cd myHadoop
~ D:\workspace\java\myHadoop>mvn clean install
[INFO]
[INFO] --- maven-jar-plugin:2.3.2:jar (default-jar) @ myHadoop ---
[INFO] Building jar: D:\workspace\java\myHadoop\target\myHadoop-1.0-SNAPSHOT.jar
[INFO]
[INFO] --- maven-install-plugin:2.3.1:install (default-install) @ myHadoop ---
[INFO] Installing D:\workspace\java\myHadoop\target\myHadoop-1.0-SNAPSHOT.jar to C:\Users\Administrator\.m2\repository\o
rg\conan\myhadoop\mr\myHadoop\1.0-SNAPSHOT\myHadoop-1.0-SNAPSHOT.jar
[INFO] Installing D:\workspace\java\myHadoop\pom.xml to C:\Users\Administrator\.m2\repository\org\conan\myhadoop\mr\myHa
doop\1.0-SNAPSHOT\myHadoop-1.0-SNAPSHOT.pom
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 4.348s
[INFO] Finished at: Sun Sep 29 20:58:43 CST 2013
[INFO] Final Memory: 11M/179M
[INFO] ------------------------------------------------------------------------
2). 导入项目到eclipse
我们创建好了一个基本的maven项目,然后导入到eclipse中。 这里我们最好已安装好了Maven的插件。
3). 增加hadoop依赖
这里我使用hadoop-1.0.3版本,修改文件:pom.xml
~ vi pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.conan.myhadoop.mr</groupId>
<artifactId>myHadoop</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>myHadoop</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
4). 下载依赖
下载依赖:
~ mvn clean install在eclipse中刷新项目:
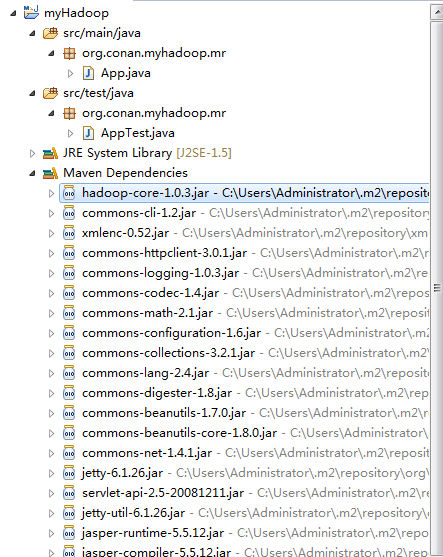
项目的依赖程序,被自动加载的库路径下面。
5). 从Hadoop集群环境下载hadoop配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
查看core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/conan/hadoop/tmp</value>
</property>
<property>
<name>io.sort.mb</name>
<value>256</value>
</property>
</configuration>
查看hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/conan/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
查看mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://master:9001</value>
</property>
</configuration>
保存在src/main/resources/hadoop目录下面
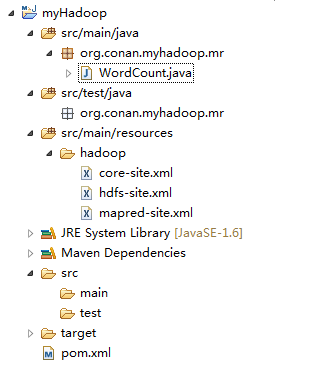
删除原自动生成的文件:App.java和AppTest.java
6).配置本地host,增加master的域名指向
~ vi c:/Windows/System32/drivers/etc/hosts
192.168.1.210 master
6. MapReduce程序开发
编写一个简单的MapReduce程序,实现wordcount功能。
新一个Java文件:WordCount.java
package org.conan.myhadoop.mr;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class WordCountMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = "hdfs://192.168.1.210:9000/user/hdfs/o_t_account";
String output = "hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result";
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(WordCountMapper.class);
conf.setCombinerClass(WordCountReducer.class);
conf.setReducerClass(WordCountReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
}
启动Java APP.
控制台错误
2013-9-30 19:25:02 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-9-30 19:25:02 org.apache.hadoop.security.UserGroupInformation doAs
严重: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator1702422322\.staging to 0700
Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator1702422322\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:850)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:824)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1261)
at org.conan.myhadoop.mr.WordCount.main(WordCount.java:78)
这个错误是win中开发特有的错误,文件权限问题,在Linux下可以正常运行。
解决方法是,修改/hadoop-1.0.3/src/core/org/apache/hadoop/fs/FileUtil.java文件
688-692行注释,然后重新编译源代码,重新打一个hadoop.jar的包。
685 private static void checkReturnValue(boolean rv, File p,
686 FsPermission permission
687 ) throws IOException {
688 /*if (!rv) {
689 throw new IOException("Failed to set permissions of path: " + p +
690 " to " +
691 String.format("%04o", permission.toShort()));
692 }*/
693 }
我这里自己打了一个hadoop-core-1.0.3.jar包,放到了lib下面。
我们还要替换maven中的hadoop类库。
~ cp lib/hadoop-core-1.0.3.jar C:\Users\Administrator\.m2\repository\org\apache\hadoop\hadoop-core\1.0.3\hadoop-core-1.0.3.jar
再次启动Java APP,控制台输出:
2013-9-30 19:50:49 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-9-30 19:50:49 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-9-30 19:50:49 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
2013-9-30 19:50:49 org.apache.hadoop.io.compress.snappy.LoadSnappy
警告: Snappy native library not loaded
2013-9-30 19:50:49 org.apache.hadoop.mapred.FileInputFormat listStatus
信息: Total input paths to process : 4
2013-9-30 19:50:50 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2013-9-30 19:50:50 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask runOldMapper
信息: numReduceTasks: 1
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-9-30 19:50:50 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-9-30 19:50:51 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 0% reduce 0%
2013-9-30 19:50:53 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00003:0+119
2013-9-30 19:50:53 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2013-9-30 19:50:53 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask runOldMapper
信息: numReduceTasks: 1
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-9-30 19:50:53 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
2013-9-30 19:50:54 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2013-9-30 19:50:56 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00000:0+113
2013-9-30 19:50:56 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000001_0' done.
2013-9-30 19:50:56 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask runOldMapper
信息: numReduceTasks: 1
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-9-30 19:50:56 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000002_0 is done. And is in the process of commiting
2013-9-30 19:50:59 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00001:0+110
2013-9-30 19:50:59 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00001:0+110
2013-9-30 19:50:59 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000002_0' done.
2013-9-30 19:50:59 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask runOldMapper
信息: numReduceTasks: 1
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-9-30 19:50:59 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000003_0 is done. And is in the process of commiting
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00002:0+79
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000003_0' done.
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-9-30 19:51:02 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 4 sorted segments
2013-9-30 19:51:02 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 4 segments left of total size: 442 bytes
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2013-9-30 19:51:02 org.apache.hadoop.mapred.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result
2013-9-30 19:51:05 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-9-30 19:51:05 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2013-9-30 19:51:06 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-9-30 19:51:06 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Counters: 20
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=421
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=348
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=7377
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=1535
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=209510
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=348
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=458
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Map input records=11
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=30
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=509
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1838546944
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Map input bytes=421
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=452
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Combine input records=22
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=15
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=13
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Combine output records=15
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=13
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
信息: Map output records=22
成功运行了wordcount程序,通过命令我们查看输出结果
~ hadoop fs -ls hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result
Found 2 items
-rw-r--r-- 3 Administrator supergroup 0 2013-09-30 19:51 /user/hdfs/o_t_account/result/_SUCCESS
-rw-r--r-- 3 Administrator supergroup 348 2013-09-30 19:51 /user/hdfs/o_t_account/result/part-00000
~ hadoop fs -cat hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result/part-00000
1,abc@163.com,2013-04-22 1
10,ade121@sohu.com,2013-04-23 1
11,addde@sohu.com,2013-04-23 1
17:21:24.0 5
2,dedac@163.com,2013-04-22 1
20:21:39.0 6
3,qq8fed@163.com,2013-04-22 1
4,qw1@163.com,2013-04-22 1
5,af3d@163.com,2013-04-22 1
6,ab34@163.com,2013-04-22 1
7,q8d1@gmail.com,2013-04-23 1
8,conan@gmail.com,2013-04-23 1
9,adeg@sohu.com,2013-04-23 1
这样,我们就实现了在win7中的开发,通过Maven构建Hadoop依赖环境,在Eclipse中开发MapReduce的程序,然后运行JavaAPP。Hadoop应用会自动把我们的MR程序打成jar包,再上传的远程的hadoop环境中运行,返回日志在Eclipse控制台输出。
7. 模板项目上传github
https://github.com/bsspirit/maven_hadoop_template
大家可以下载这个项目,做为开发的起点。
~ git clone https://github.com/bsspirit/maven_hadoop_template.git
我们完成第一步,下面就将正式进入MapReduce开发实践。
转载请注明出处:
http://blog.fens.me/hadoop-maven-eclipse/

[…] 用Maven构建Hadoop项目 […]
[…] 请参考文章:用Maven构建Hadoop项目 […]
[…] 用ant重新打包后,就生成了可以在win运行的hadoop-core-1.1.2.jar!使用方法可以参考文章:用Maven构建Hadoop项目,我们后面一直会用到! […]
[…] win7的开发环境 和 Hadoop的运行环境 ,请参考文章:用Maven构建Hadoop项目 […]
貌似程序只是用了HDFS上的数据,程序并没有真正在集群上运行啊,你看看提交job的编号都是attempt_local的
你提的这个问题很好啊!我之前都往这方面想过。
我去看看源代码,找找是什么原因。
还有那个mahout分布式的例子也没有运行在集群上 oooops
找出原因了没有?
还没有,最近没有时间看这个问题。
不过影响不大,因为文章讲的开发环境,并不是生产环境。
想要直接通过eclipse让程序运行在集群上需要使用eclipse的hadoop插件 或者打包好上传到集群上运行
Configuration conf = new Configuration();
conf.set(“mapred.job.tracker”, “hadoop-master:9001”);
main方法中设置了这句话时,就会将本地写的任务提交到远程去执行,如果没有显示的指明mapred.job.tracker属性,默认任务都是以local模式运行的,但是同时,如果设置了这个属性,程序会报classNotFound 的错误,大概意思就是Mapper和Reduce找不到,这个要解决的办法要将一些资源和Mapper、Reduce加入到classpath就不会了吧
我也遇到这样的问题,set完”mapred.job.tracker”以后,运行会报“找不到类”的错误,但是,我在本已经导入了相关的jar文件啊,怎么回事??
哥们你的联系方式是啥? 加一下我的联系邮箱:tangluling@gmail.com
看起来,Maven在最初的建立的时候,并没有像apache官网上的instruction所说的,建立M2_HOME和M2环境变量。这些在后面的操作中会有影响么?另外,想请教下,Optional: Add the MAVEN_OPTS environment variable to specify JVM properties, e.g. export MAVEN_OPTS=”-Xms256m -Xmx512m”. This environment variable can be used to supply extra options to Maven. 这个设置会对Maven提供哪些额外选项?
谢谢老师。
1. 有没有环境变量没什么影响
2. MAVEN_OPTS都是JVM的参数,设置内存分配的。
老师,你好。想请教一下,多次提到的pom.xml文件究竟是一个什么样的文件。谢谢
找到文章的 vi pom.xml
你好,lib下单hadoop*.jar 版本是1.3 的,麻烦问下文章中你提到的hadoop-eclipse插件版本是哪个?目前官方提供的只有1.2版的插件?
我没有试用 hadoop-eclipse插件。
这个你可以根据自己的hadoop版本在本地编译一个hadoop-eclipse插件,网络上有很多编译办法,希望你用到
你好,
hadoop fs -ls hdfs:// ip :9000/user/hdfs/o_t_account在我的集群上执行不了啊?
[xdr@node11 conf]$ hadoop fs -ls hdfs://node11:9000/user/
14/02/23 21:27:50 INFO ipc.Client: Retrying connect to server: node11/10.1.100.11:9000. Already tried 0 time(s).
14/02/23 21:27:51 INFO ipc.Client: Retrying connect to server: node11/10.1.100.11:9000. Already tried 1 time(s).
14/02/23 21:27:52 INFO ipc.Client: Retrying connect to server: node11/10.1.100.11:9000. Already tried 2 time(s).
就是说hadoop fs -ls hdfs://node11:9000/user/中,hdfs://node11:9000/user/指定了node11或者静态ip,这个hdfs命令就报错,请问是什么原因?
[aone@localhost ~]$ hadoop fs -ls hdfs://localhost:9000/
Found 5 items
drwxr-xrwx – aone supergroup 0 2013-12-15 02:48 /hbase
drwxr-xr-x – aone supergroup 0 2013-12-21 00:17 /home
drwxrwxr-x – aone supergroup 0 2013-12-20 18:01 /test
drwxr-xr-x – aone supergroup 0 2013-12-02 00:59 /tmp
drwxr-xr-x – aone supergroup 0 2013-12-21 00:17 /user
把localhost换成静态ip 192.168.1.3就连不上了
[aone@localhost ~]$ hadoop fs -ls hdfs://192.168.1.3:9000/
14/02/23 05:52:36 INFO ipc.Client: Retrying connect to server: /192.168.1.3:9000. Already tried 0 time(s).
14/02/23 05:52:37 INFO ipc.Client: Retrying connect to server: /192.168.1.3:9000. Already tried 1 time(s).
ls: Call to /192.168.1.3:9000 failed on connection exception: java.net.ConnectException: Connection refused
为什么呢?
ip的问题,有两种方法配置。
1. 在host文件中,增加192.168.1.3和localhost的对应关系
2. 通过DNS服务器,增加ip和域名的对应关系
另外,你的问题localhost可以,ip不可能,还有可能是因为master和slave文件的配置,指定了localhost这个域名所引起的问题。
网络配置是Linux的基础知识,花点时间自己补补吧,后面问题还多着呢。
多谢你的回复。
解决了, 修改了:
fs.default.name
hdfs://master:9000
这里原来配置的是localhost,即namenode的ip为127.0.0.1,虽然该机子的静态ip为192.168.1.3,也不好使。
请问找不到Input Path 是什么原因?报如下的错误:
七月 02, 2014 9:28:40 下午 org.apache.hadoop.security.UserGroupInformation doAs
严重: PriviledgedActionException as:xolvtp cause:org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://192.168.1.102:9000/user/hdfs/o_t_account
Exception in thread “main” org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://192.168.1.102:9000/user/hdfs/o_t_account
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:197)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:208)
at org.apache.hadoop.mapred.JobClient.writeOldSplits(JobClient.java:1051)
at org.apache.hadoop.mapred.JobClient.writeSplits(JobClient.java:1043)
at org.apache.hadoop.mapred.JobClient.access$700(JobClient.java:179)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:959)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:912)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1149)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:912)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:886)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1323)
at org.kenny.myhadoop.mr.WordCount.main(WordCount.java:74)
问题已经解决,看了下一章 先执行了
./hadoop fs -mkdir hdfs://192.168.1.102:9000/usr/hdfs/o_t_account 就好
教程里没有写哦~ 但是我这里跑完结果好像很不一样
另外 1.1.2 和 1.0.3 可能有些不同,代码里有些地方要小改一下~
为什么我跑出来结果里没值呢,作者在结果里那么多邮箱地址是哪里冒出来的?是不是有个输入文件没写上呢?
懂了,要用copyFromLocal先复制一个文件进去?~
你自问自答就解决了!多想想,别着急问问题,自己解决不是更有乐趣。
试了一下,确实要这样
copy哪个文件
写得不错,谢谢分享!
public static class WordCountReducer extends MapReduceBase implements Reducer
The type WordCount.WordCountReducer must implement the inherited abstract method Reducer.reduce(Text, Iterator, OutputCollector, Reporter) WordCount.java /myHadoop/src/main/java/org/conan/myhadoop/mc line 38 Java Problem
程序这一行,报这个错,不会解啊,有什么办法么?
WordCountReducer.java类,必须实现一个抽象的reduce()方法,应该是编译错误。
运行的时候报找不到map类的错误
看看名字,是不是配对了?
conf.setMapperClass(WordCountMapper.class);
conf.setCombinerClass(WordCountReducer.class);
conf.setReducerClass(WordCountReducer.class);
老师您好,我运行时也报上面类似错误,照着hadoop-example-1.0.0.jar包里面的代码写的,还是不行,怎么解决?
如果不行的话,那就别用这种方式了,window+eclipse开发毕竟只是一个折中方案。
[…] 请参考文章:用Maven构建Hadoop项目 […]
为什么我运行mvn clean install后刷新,项目的依赖目录没有自动加载到库呢?运行完后显示时BUILT SUCCESS
解决了,thank you!
🙂
你好,这个问题你是怎么解决的,我的依赖目录也没有加载,我用的hadoop2.4.0,请告知,谢谢!
没有添加core-site.sh/hdfs-site.sh/mapred-ste.sh三个配置文件,以及在程序中也没有添加,程序也能正常运行
如果你是用Eclipse装好Hadoop的插件,也是正常的;在没有IDE的情况下,需要这3个文件。
运行起来报错啊。老师
二月 27, 2015 8:59:17 下午 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
二月 27, 2015 8:59:17
下午 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
二月 27, 2015 8:59:17 下午 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
二月 27, 2015 8:59:47 下午 org.apache.hadoop.ipc.Client$Connection handleConnectionFailure
想问下hadoop集群配置的参考资料有吗?和这个网页上的项目配套的?
尊敬前辈你好请问你的那个安装maven插件怎么弄啊 看不懂啊。
1 安装Eclipse的Maven插件:Maven Integration for Eclipse
2 Maven的Eclipse插件配置
请问1 和2是两个都必须做的步骤码?
我没有做1,因为看不懂,导致后面修改pom.xml后4). 下载依赖 刷新eclipse里面的项目,什么也没有啊,什么原因啊
1. 通过 Eclipse market 安装下载就行了,类似APP商店的方式
2. 是的。
建议你先学一个Maven的基本操作,再用Eclipse配合使用。
前辈老师你好!
他都没有生成hadoo-1.0.3.jar啊,也就是说我cmd里面执行mvn clean install后 刷新eclipse 没有看到那些maven的依赖和相应的jar包啊。
—————— 原始邮件 ——————
发件人: “Disqus”;;
发送时间: 2015年5月2日(星期六) 上午9:57
收件人: “★追梦人★”;
主题: Re: Comment on 用Maven构建Hadoop项目
“1. 通过 Eclipse market 安装下载就行了,类似APP商店的方式 2. 是的。 建议你先学一个Maven的基本操作,再用Eclipse配合使用。” Settings
A new comment was posted on bsspirit
Conan Zhang
1. 通过 Eclipse market 安装下载就行了,类似APP商店的方式
2. 是的。
建议你先学一个Maven的基本操作,再用Eclipse配合使用。
9:57 p.m., Friday May 1 | Other comments by Conan Zhang
Reply to Conan Zhang
Conan Zhang’s comment is in reply to zhouchanghua:
尊敬前辈你好请问你的那个安装maven插件怎么弄啊 看不懂啊。
1 安装Eclipse的Maven插件:Maven Integration for Eclipse
2 Maven的Eclipse插件配置
请问1 和2是两个都必须做的步骤码?
我没有做1,因为看不懂,导致后面修改pom.xml后4). 下载依赖 刷新eclipse里面的项目,什么也没有啊,什么原因啊
Read more
You’re receiving this message because you’re signed up to receive notifications about replies to zhouchanghua.
You can unsubscribe from emails about replies to zhouchanghua by replying to this email with “unsubscribe” or reduce the rate with which these emails are sent by adjusting your notification settings.
你如果没有装maven eclipse的插件,在Eclpise中是不会看到hadoop.jar被加载。
5). 从Hadoop集群环境下载hadoop配置文件
老师你好,问下你这步下载hadoop那3个配置文件,是先去hadoop官网下载hadoop-1.0.3.zip 还是用具体的命令下载啊?
后面这些hadoop命令 在win7下 用不了啊
Hadoop本身是需要在Linux上运行的,尽量避免在WIN上用。
问下大家 怎么配置啊
2015-7-21 15:57:37 org.apache.hadoop.ipc.Client$Connection handleConnectionFailure
信息: Retrying connect to server: 192.168.1.210/192.168.1.210:9000. Already tried 0 time(s).
2015-7-21 15:57:58 org.apache.hadoop.ipc.Client$Connection handleConnectionFailure
信息: Retrying connect to server: 192.168.1.210/192.168.1.210:9000. Already tried 1 time(s).
mapred.job.tracker
hdfs://192.168.1.210:9000
并没有指定master
不知道你的hadoop版本,如果版本与本文不一致,可能有些代码是跑不通的。
2015-7-24 11:07:26 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2015-7-24 11:07:26 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
2015-7-24 11:07:47 org.apache.hadoop.ipc.Client$Connection handleConnectionFailure
信息: Retrying connect to server: master/192.168.1.210:9000. Already tried 0 time(s).
2015-7-24 11:08:08 org.apache.hadoop.ipc.Client$Connection handleConnectionFailure
信息: Retrying connect to server: master/192.168.1.210:9000. Already tried 1 time(s).
2015-7-24 11:08:29 org.apache.hadoop.ipc.Client$Connection handleConnectionFailure
信息: Retrying connect to server: master/192.168.1.210:9000. Already tried 2 time(s).
……
我在Myeclipse上运行,没有报错就是一直连接不上,老师这是为什么?
不知道你的hadoop版本,如果版本与本文不一致,可能有些代码是跑不通的。
关闭服务器集群上面的防火墙试试
博主,您好!请问您在windows的eclipse跑mapreduce,没有安装和配置cygwin吗?
我用的是git客户端,带bash的环境。
博主,您好!请问使用git客户端什么意思?这个不是在windows下面用git做版本控制的工具吗?难道它还能实现在windows的eclipse下直接使用在Ubuntu上搭建的Hadoop环境?
git的window客户端,会自带一个叫Mingw的Linux命令行工具,可以执行简单的shell命令,与cygwin功能类似,仅此而已。
谢谢,博主。但我还是不太明白。请问您的Hadoop是安装在哪个?Mingw?cygwin?还是其他的上面?谢谢!
Hadoop装在linux服务器上面
谢谢,博主。我最近一直在找一种方法能在windows的eclipse下跑linux的Hadoop集群(因为在linux上跑eclipse感觉比较慢,还要来回切换),这样会比较方便而且便于调试;尝试了cygwin,但它很多配置太奇葩,而且它没有运行linux上的集群,不符合要求。
我刚刚简单搜了一下Mingw,但多数其实用于eclipse配置c++运行环境的,所以很困惑。请问您能否写篇blog详细介绍一下怎么用git客户端配置的这个环境?十分感谢!
做Hadoop开发,还是尽量不用window比较好。
博主你好,我在本地eclipse中运行WordCount这个demo时,在main方法中这样设置过:
Configuration conf = new Configuration();
conf.set(“mapred.job.tracker”, “192.168.56.10:9001”);
但是程序每次运行都会报classNotFound 的错误,怎么解决?但是向服务器hdfs上传本地文件时不报错
是不是hadoop版本的问题。
小白问几个问题:1.Windows下一定要装git客户端么?
2. WordCount.java里的路径要根据本地hadoop集群环境修改吧?
请问“从Hadoop集群环境下载hadoop配置文件”这一步怎么实现的谢谢
1. ssh 登陆服务器,用vi打开,复制就行了。
2. 或者用scp下载文件
懂了,谢谢您,老师我想用Python做推荐系统的话应该怎么实现呢?我没有找到相关的文章,谢谢您
Python我不熟,你本书看吧。
嗯,好的,谢谢您
控制台错误 解决方法是,修改/hadoop-1.0.3/src/core/org/apache/hadoop/fs/FileUtil.java文件
这一要修改的文件 怎么没有找到呢? 求教
如果你用了高版本的hadoop,这个问题应该已经解决了,不用手动再修改了。
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread “main” java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120)
at org.apache.hadoop.mapreduce.Cluster.(Cluster.java:82)
at org.apache.hadoop.mapreduce.Cluster.(Cluster.java:75)
at org.apache.hadoop.mapred.JobClient.init(JobClient.java:470)
at org.apache.hadoop.mapred.JobClient.(JobClient.java:449)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:832)
at org.conan.myhadoop.mr.WordCount.main(WordCount.java:59)
楼主。。。请问这是什么问题?
Cannot initialize Cluster,集群初始化失败,检查一下配置吧。
“这样,我们就实现了在win7中的开发,通过Maven构建Hadoop依赖环境,在Eclipse中开发MapReduce的程序,然后运行JavaAPP。Hadoop应用会自动把我们的MR程序打成jar包,再上传的远程的hadoop环境中运行,返回日志在Eclipse控制台输出。”按照上面的操作,好像达不到这个效果,是不是还有其他配置,现在只能打成jar包,放到hadoop集群上运行,不能做到自动把我们的MR程序打成jar包,再上传的远程的hadoop环境中运行,返回日志在Eclipse控制台输出。
你好,没有别的什么配置了,除非是版本的问题。
或者换一种方式,你装一个eclipse的hadoop的插件,这个插件也可以实现本地开发,远程自己部署的效果。