算法为王系列文章,涵盖了计算机算法,数据挖掘(机器学习)算法,统计算法,金融算法等的多种跨学科算法组合。在大数据时代的背景下,算法已经成为了金字塔顶的明星。一个好的算法可以创造一个伟大帝国,就像Google。
算法为王的时代正式到来….
关于作者:
- 张丹, 分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-graph-leidan/
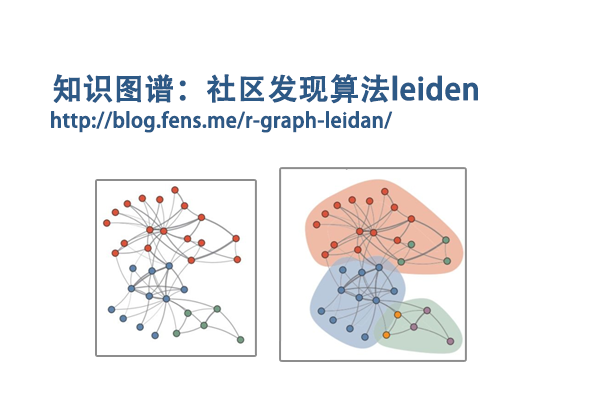
前言
基于知识图谱的技术,已经越来越普遍的应用于各种业务场景中了,比如互联网领域的搜索推荐、智能客服;金融领域的智能风控、反欺诈识别;水利领域的最近的数字孪生建设规划也加入了知识平台的建设。
图算法方向,有很多的算法模型,本文将介绍Leiden算法,用于社区检测,帮助我们了解大型复杂网络的结构。新的技术趋势已经打开,抓住时代的机遇,用技术提升社会生产力。
目录
- Leiden算法介绍
- 用R语言加载leidenAlg包
1. Leiden算法介绍
社区检测通常用于了解大型复杂网络的结构。Leiden 算法是一种在大型关系网络上的社区检测算法,leiden算法计算社区之间的节点和边的关系,保证社区内部连接的有效性,并实现社区的分隔。当迭代应用 Leiden 算法时,它收敛到一个分区,在该分区中所有社区的所有子集都被局部最优分配,从而产生保证连接的社区。
leidan算法的论文:https://www.nature.com/articles/s41598-019-41695-z
Leiden 算法是为了改进 Louvain 算法的缺陷,Louvain 算法可能会发现任意连接不良的社区。 因此,Leiden保证了社区之间的良好连接, 而且算法速度更快,可扩展性更好,并且可以在数百万个节点的图上运行(只要它们可以放入内存)。
Leiden 算法包括三个阶段:
- 节点局部移动,快速找到分区
- 分区细化
- 基于细化分区的网络聚合,利用非细化分区为聚合网络创建初始分区。 迭代步骤直到收敛。
2. leidenAlg包算法实现
R语言中,已经有了Leiden算法的实现,Leiden算法是在2019年刚推出,R社区的开发效率真是很高!我们可以加载leidanAlg包来使用Leiden算法,结合igraph进行社区发现可视化展示。
项目地址:https://github.com/kharchenkolab/leidenAlg
首先,安装和加载leidanAlg包。安装过程很简单,如果igraph之前装过,可能会需要升级igraph到高版本。
# 安装leidenAlg 和 igraph包
> install.packages("leidenAlg")
> install.packages("igraph")
# 加载程序包
> library(leidenAlg)
> library(igraph)
# 设置工作目录
> setwd("C:/work/R/graph")
2.1 社区发现算法
首先,我先使用leidenAlg提供的一个数据集exampleGraph,进行算法的测试。
# 加载数据集exampleGraph
> data(exampleGraph)
# 查看数据集数据
> exampleGraph
IGRAPH 05dba3a UNW- 100 242 --
+ attr: name (v/c), weight (e/n), type (e/n)
+ edges from 05dba3a (vertex names):
[1] MantonBM1_HiSeq_1-GGAACTTCACTGTCGG-1--MantonBM2_HiSeq_1-CTGATAGAGCGTTCCG-1
[2] MantonBM1_HiSeq_1-ACGCCAGAGTACCGGA-1--MantonBM2_HiSeq_1-GGAAAGCCAGACGCCT-1
[3] MantonBM1_HiSeq_1-ATCACGAAGGAGTCTG-1--MantonBM2_HiSeq_1-TTTGCGCGTAGCGCTC-1
[4] MantonBM2_HiSeq_1-TTTGCGCGTAGCGCTC-1--MantonBM1_HiSeq_1-TTGGCAATCTTGAGAC-1
[5] MantonBM2_HiSeq_1-TTTGCGCGTAGCGCTC-1--MantonBM1_HiSeq_1-ACGGGTCTCCACGACG-1
[6] MantonBM2_HiSeq_1-TTTGCGCGTAGCGCTC-1--MantonBM1_HiSeq_1-GTCATTTGTCAGATAA-1
[7] MantonBM2_HiSeq_1-TTTGCGCGTAGCGCTC-1--MantonBM1_HiSeq_1-CAGGTGCTCCACGTGG-1
[8] MantonBM2_HiSeq_1-TTTGCGCGTAGCGCTC-1--MantonBM1_HiSeq_1-TTGGCAAGTCAGAATA-1
+ ... omitted several edges
可视化展示数据集的网路关系
> e<-exampleGraph
# 不现实节点名
> V(e)$label<-""
# 画图
> plot(e)

从上图中,可以看到整个网络是由多个小的社区组成的,肉眼是可以明显进行划分的。接下来,通过leiden算法,进行社区自动化的分隔。
# leidan算法计算
> lc<-leiden.community(e)
# 把不同的社区涂上不同的颜色
> library(RColorBrewer)
> node.cols <- brewer.pal(max(c(3, lc$membership)),"Pastel1")[lc$membership]
Warning message:
In brewer.pal(max(c(3, lc$membership)), "Pastel1") :
n too large, allowed maximum for palette Pastel1 is 9
Returning the palette you asked for with that many colors
# 画图
> plot(e, vertex.color = node.cols, vertex.label="")

涂色后,可以直接进行观察,每个社区都刚好形成独立的颜色。leiden算法,可以自动地进行社区的识别。
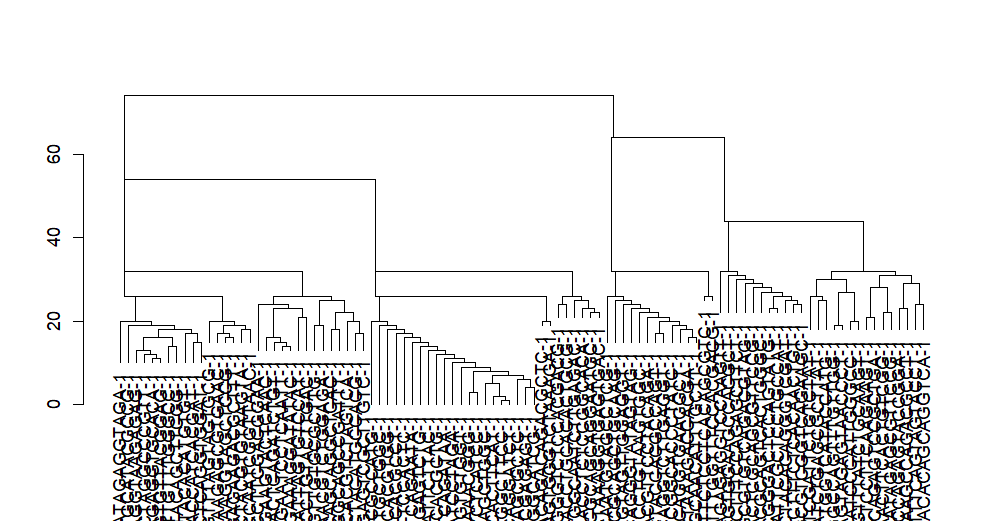
2.2 递归聚类
递归 leiden算法, 使用 rleiden.community()函数 构建一个 n 步递归聚类,并返回树型图,用来展示社区各个对象之间的聚类关系。
建立深度为2的社区树型结构。
> r2 = rleiden.community(e, n.cores=1,max.depth=2)
> rs2<-as.dendrogram.fakeCommunities(r2)
> plot(rs2)
2.3 权重设置
构建一个新的网络关系图谱,我们用于边的权重,对社区划分的计算的影响。
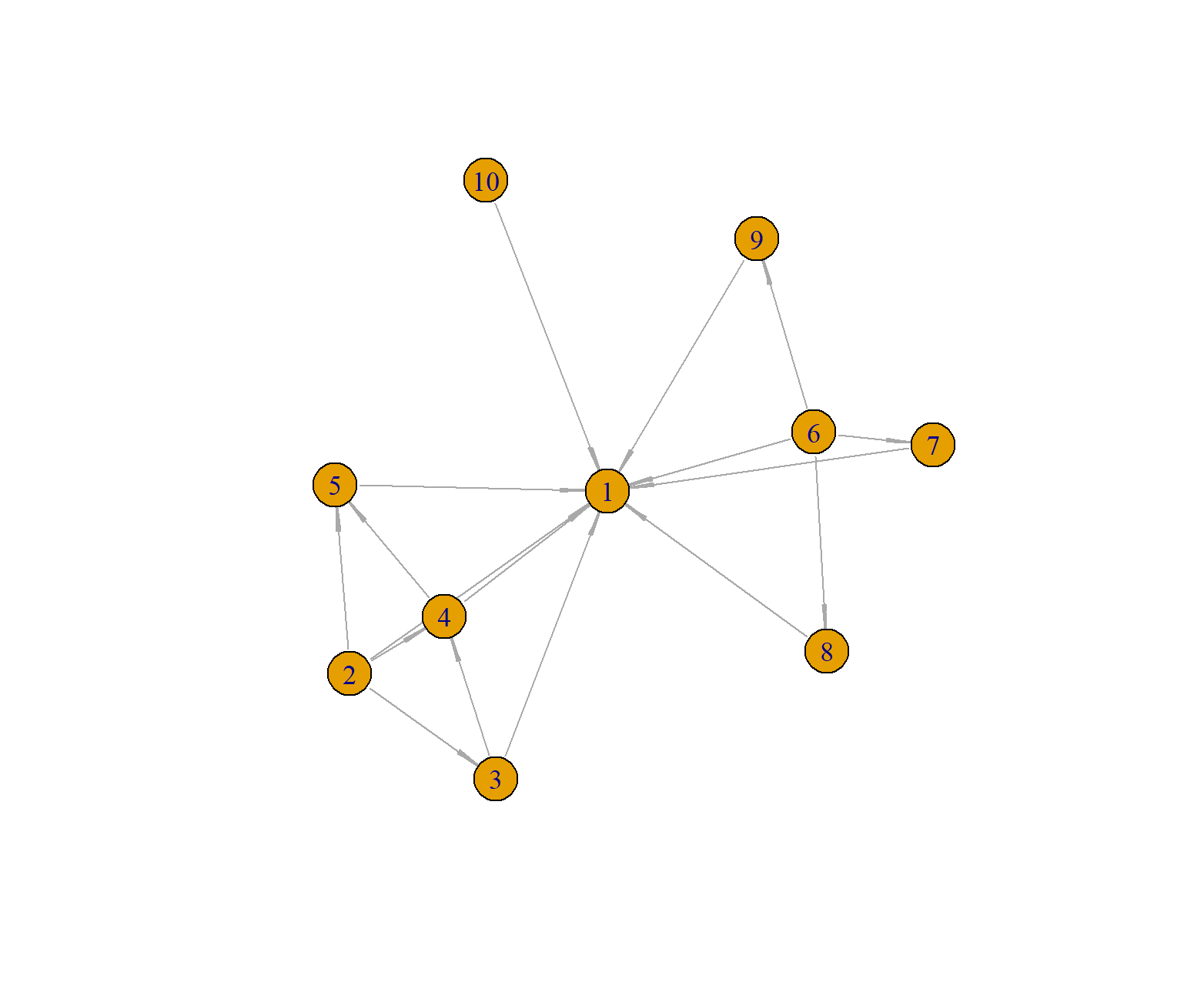
首先,建立10节点的图谱,并设置边的连接和方向。
# 建立节点
> g <- make_star(10)
> g<-add_edges(g,c(2,3,3,4, 4,5,2,4,2,5))
> g<-add_edges(g,c(6,7,6,8,6,9))
> E(g)$arrow.size<-0.2
> E(g)$arrow.width<-0.2
# 查看图谱结构
> g
IGRAPH d3bc7a7 D--- 10 17 -- In-star
+ attr: name (g/c), mode (g/c), center (g/n), arrow.size (e/n), arrow.width (e/n)
+ edges from d3bc7a7:
[1] 2->1 3->1 4->1 5->1 6->1 7->1 8->1 9->1 10->1 2->3 3->4 4->5 2->4 2->5 6->7 6->8 6->9
# 画图
> plot(g)
给边设置权重,分别把1,2,3以随机数的方式,设置到不同的边上。
# 取随机权重,设置边的大小,设置边的颜色
> E(g)$width <- sample(1:3,ecount(g),replace = TRUE)
> E(g)$color<-E(g)$width
> E(g)$width
[1] 1 2 1 1 2 1 3 1 3 3 2 3 3 2 3 1 2
# 画图
> plot(g)

上图中,按照权重的关系,我们把边凃上了颜色,可以查看图中节点和边的值。
# 查看图中节点和边的值
> as_data_frame(g)
from to arrow.size arrow.width width color
1 2 1 0.2 0.2 1 1
2 3 1 0.2 0.2 2 2
3 4 1 0.2 0.2 1 1
4 5 1 0.2 0.2 1 1
5 6 1 0.2 0.2 2 2
6 7 1 0.2 0.2 1 1
7 8 1 0.2 0.2 3 3
8 9 1 0.2 0.2 1 1
9 10 1 0.2 0.2 3 3
10 2 3 0.2 0.2 3 3
11 3 4 0.2 0.2 2 2
12 4 5 0.2 0.2 3 3
13 2 4 0.2 0.2 3 3
14 2 5 0.2 0.2 2 2
15 6 7 0.2 0.2 3 3
16 6 8 0.2 0.2 1 1
17 6 9 0.2 0.2 2 2
最后,用leiden算法进行对节点的社区划分并涂色,就能看到最后,被社区分隔的结果。
# 根据权重进行社区划分计算,设置节点的颜色
> V(g)$color<-find_partition(g, E(g)$width)
# 画图
> plot(g)
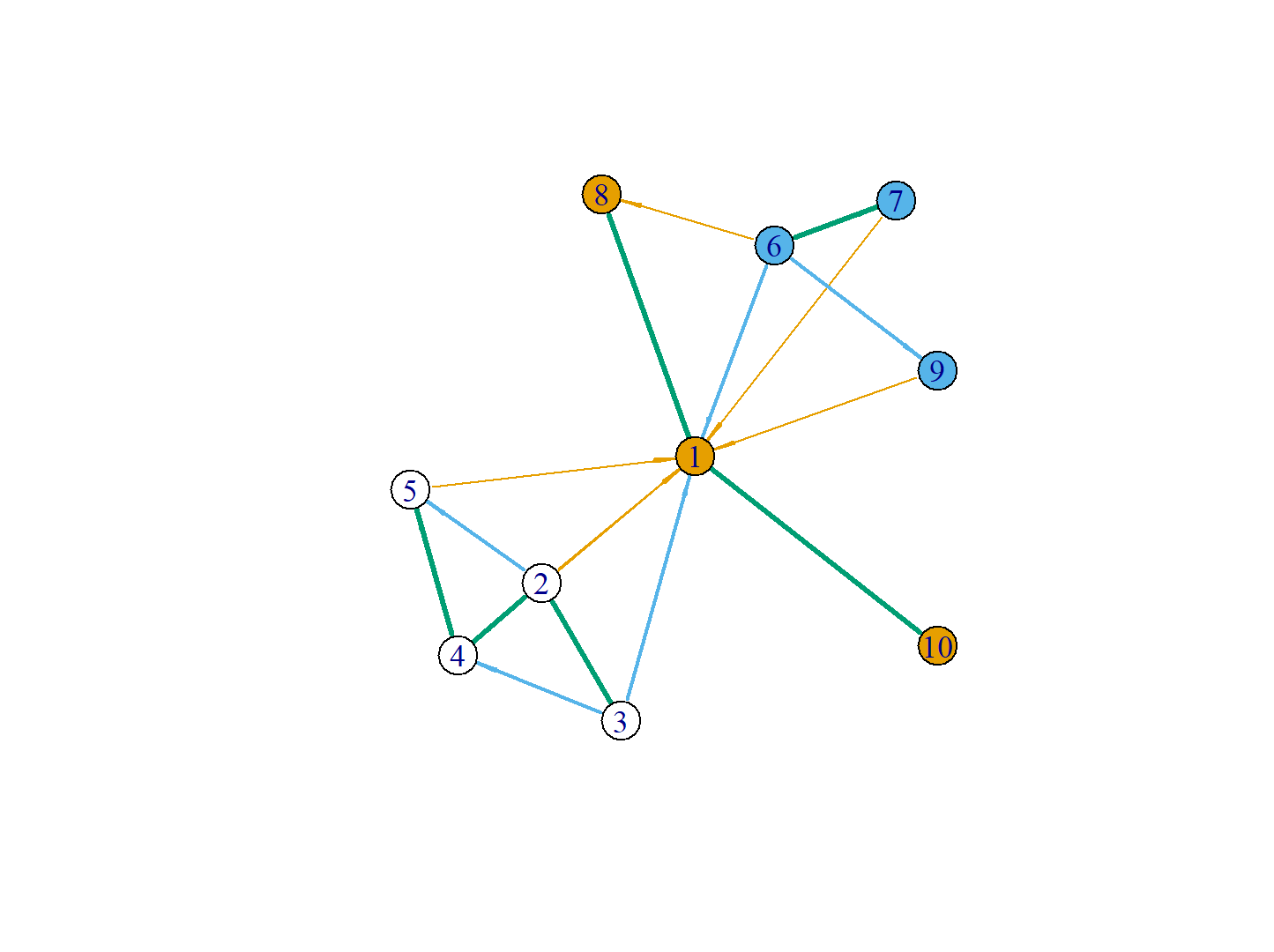
权重的设置,可以改进leiden算法的社区发现的识别结果,自动地帮我们把强关联社区进行锁定,可以提升智能化的社区发现效率。
好的技术,用在合适的场景中,事半功倍。
本文算法代码已上传到github: https://github.com/bsspirit/graph/blob/main/leiden.r
转载请注明出处:
http://blog.fens.me/r-graph-leidan/
