Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/mahout-recommend-engine/

前言
Mahout框架中cf.taste包实现了推荐算法引擎,它提供了一套完整的推荐算法工具集,同时规范了数据结构,并标准化了程序开发过程。应用推荐算法时,代码也就7-8行,简单地有点像R了。为了使用简单的目标,Mahout推荐引擎必然要做到精巧的程序设计。
本文将介绍Mahout推荐引擎的程序设计。
目录
- Mahout推荐引擎概况
- 标准化的程序开发过程
- 数据模型
- 相似度算法工具集
- 近邻算法工具集
- 推荐算法工具集
- 创建自己的推荐引擎构造器
1. Mahout推荐引擎概况
Mahout的推荐引擎,要从org.apache.mahout.cf.taste包说起。
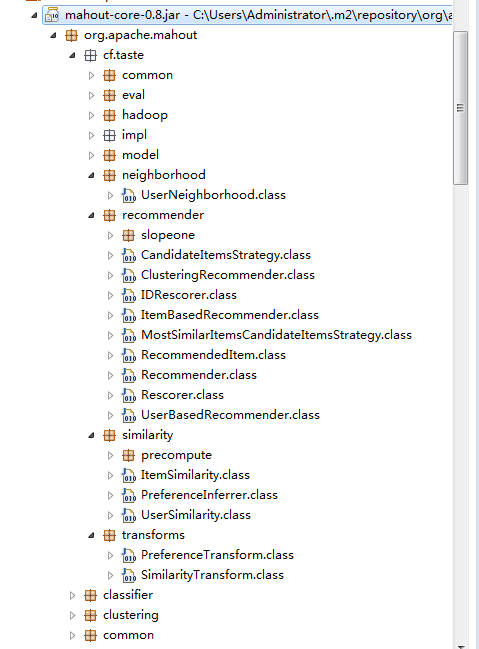
packages的说明:
- common: 公共类包括,异常,数据刷新接口,权重常量
- eval: 定义构造器接口,类似于工厂模式
- model: 定义数据模型接口
- neighborhood: 定义近邻算法的接口
- recommender: 定义推荐算法的接口
- similarity: 定义相似度算法的接口
- transforms: 定义数据转换的接口
- hadoop: 基于hadoop的分步式算法的实现类
- impl: 单机内存算法实现类
从上面的package情况,我可以粗略地看出推荐引擎分为5个主要部分组成:数据模型,相似度算法,近邻算法,推荐算法,算法评分器。
从数据处理能力上,算法可以分为:单机内存算法,基于hadoop的分步式算法。
下面我们将基于单机内存算法,研究Mahout的推荐引擎的结构。
2. 标准化的程序开发过程
以UserCF的推荐算法为例,官方建议我们的开发过程:
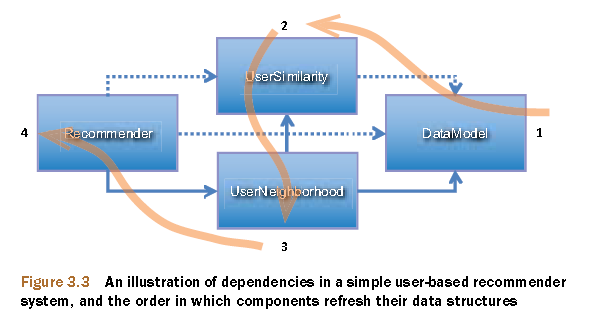
图片摘自Mahout in Action
从上图中我们可以看到,算法是被模块化的,通过1,2,3,4的过程进行方法调用。
程序代码:
public class UserCF {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws IOException, TasteException {
String file = "datafile/item.csv";
DataModel model = new FileDataModel(new File(file));
UserSimilarity user = new EuclideanDistanceSimilarity(model);
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);
Recommender r = new GenericUserBasedRecommender(model, neighbor, user);
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = r.recommend(uid, RECOMMENDER_NUM);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
}
我们调用算法的程序,要用到4个对象:DataModel, UserSimilarity, NearestNUserNeighborhood, Recommender。
3. 数据模型
Mahout的推荐引擎的数据模型,以DataModel接口为父类。
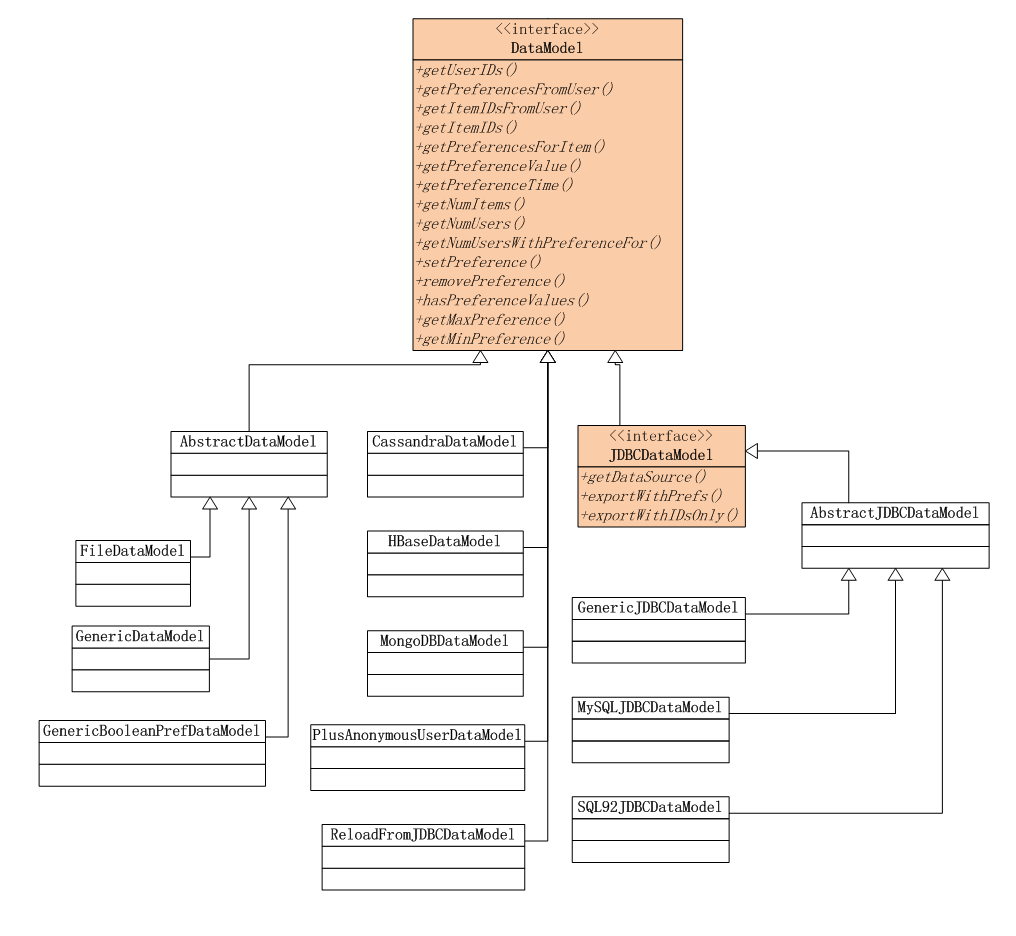
通过“策略模式”匹配不同的数据源,支持File, JDBC(MySQL, PostgreSQL), NoSQL(Cassandra, HBase, MongoDB)。
注:NoSQL的实现在mahout-integration-0.8.jar中。
数据格式支持2种:
- GenericDataModel: 用户ID,物品ID,用户对物品的打分(UserID,ItemID,PreferenceValue)
- GenericBooleanPrefDataModel: 用户ID,物品ID (UserID,ItemID),这种方式表达用户是否浏览过该物品,但并未对物品进行打分。
4. 相似度算法工具集
相似度算法分为2种
- 基于用户(UserCF)的相似度算法
- 基于物品(ItemCF)的相似度算法
1). 基于用户(UserCF)的相似度算法
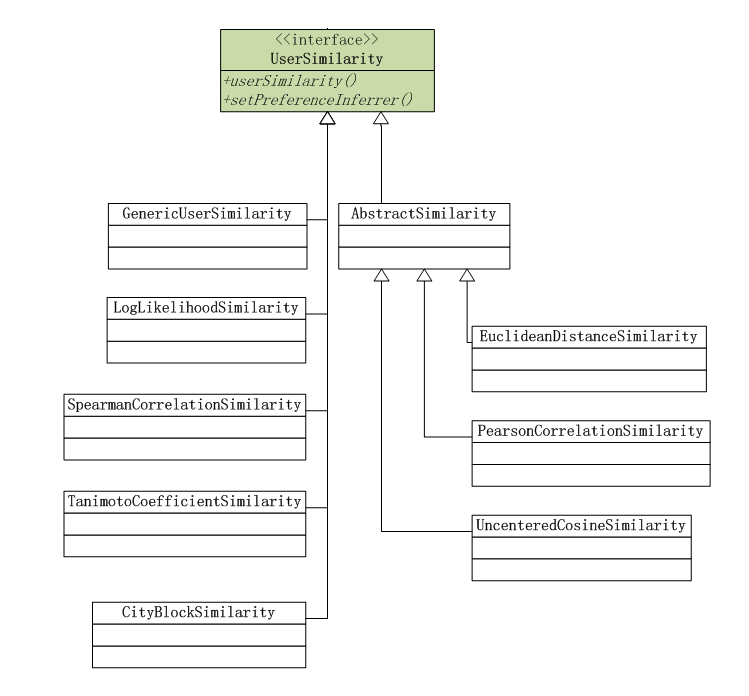
计算用户的相似矩阵,可以通过上图中几种算法。
2). 基于物品(ItemCF)的相似度算法
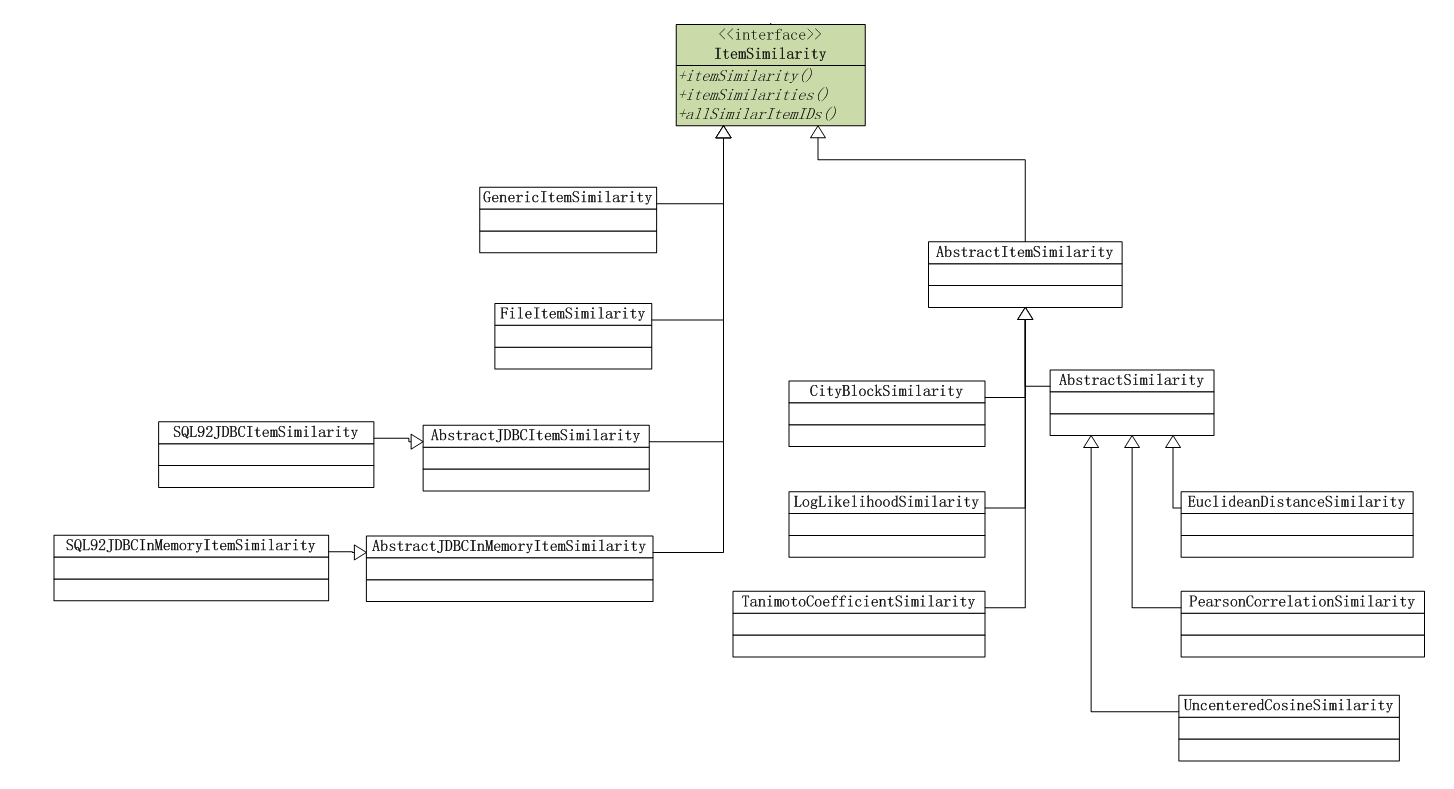
计算物品的相似矩阵,可以通过上图中几种算法。
关于相似度距离的说明:
- EuclideanDistanceSimilarity: 欧氏距离相似度
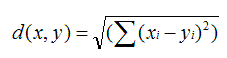
原理:利用欧式距离d定义的相似度s,s=1 / (1+d)。
范围:[0,1],值越大,说明d越小,也就是距离越近,则相似度越大。
说明:同皮尔森相似度一样,该相似度也没有考虑重叠数对结果的影响,同样地,Mahout通过增加一个枚举类型(Weighting)的参数来使得重叠数也成为计算相似度的影响因子。
- PearsonCorrelationSimilarity: 皮尔森相似度
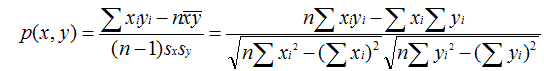
原理:用来反映两个变量线性相关程度的统计量
范围:[-1,1],绝对值越大,说明相关性越强,负相关对于推荐的意义小。
说明:1、 不考虑重叠的数量;2、 如果只有一项重叠,无法计算相似性(计算过程被除数有n-1);3、 如果重叠的值都相等,也无法计算相似性(标准差为0,做除数)。
该相似度并不是最好的选择,也不是最坏的选择,只是因为其容易理解,在早期研究中经常被提起。使用Pearson线性相关系数必须假设数据是成对地从正态分布中取得的,并且数据至少在逻辑范畴内必须是等间距的数据。Mahout中,为皮尔森相关计算提供了一个扩展,通过增加一个枚举类型(Weighting)的参数来使得重叠数也成为计算相似度的影响因子。
- UncenteredCosineSimilarity: 余弦相似度
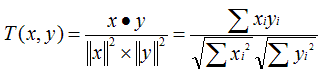
原理:多维空间两点与所设定的点形成夹角的余弦值。
范围:[-1,1],值越大,说明夹角越大,两点相距就越远,相似度就越小。
说明:在数学表达中,如果对两个项的属性进行了数据中心化,计算出来的余弦相似度和皮尔森相似度是一样的,在mahout中,实现了数据中心化的过程,所以皮尔森相似度值也是数据中心化后的余弦相似度。另外在新版本中,Mahout提供了UncenteredCosineSimilarity类作为计算非中心化数据的余弦相似度。
- SpearmanCorrelationSimilarity: Spearman秩相关系数相似度
原理:Spearman秩相关系数通常被认为是排列后的变量之间的Pearson线性相关系数。
范围:{-1.0,1.0},当一致时为1.0,不一致时为-1.0。
说明:计算非常慢,有大量排序。针对推荐系统中的数据集来讲,用Spearman秩相关系数作为相似度量是不合适的。
- CityBlockSimilarity: 曼哈顿距离相似度
原理:曼哈顿距离的实现,同欧式距离相似,都是用于多维数据空间距离的测度
范围:[0,1],同欧式距离一致,值越小,说明距离值越大,相似度越大。
说明:比欧式距离计算量少,性能相对高。
- LogLikelihoodSimilarity: 对数似然相似度
原理:重叠的个数,不重叠的个数,都没有的个数
范围:具体可去百度文库中查找论文《Accurate Methods for the Statistics of Surprise and Coincidence》
说明:处理无打分的偏好数据,比Tanimoto系数的计算方法更为智能。
- TanimotoCoefficientSimilarity: Tanimoto系数相似度
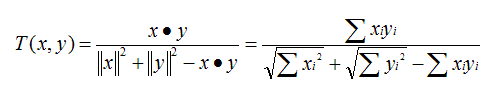
原理:又名广义Jaccard系数,是对Jaccard系数的扩展,等式为
范围:[0,1],完全重叠时为1,无重叠项时为0,越接近1说明越相似。
说明:处理无打分的偏好数据。
相似度算法介绍,摘自:http://www.cnblogs.com/dlts26/archive/2012/06/20/2555772.html
5. 近邻算法工具集
近邻算法只对于UserCF适用,通过近邻算法给相似的用户进行排序,选出前N个最相似的,作为最终推荐的参考的用户。
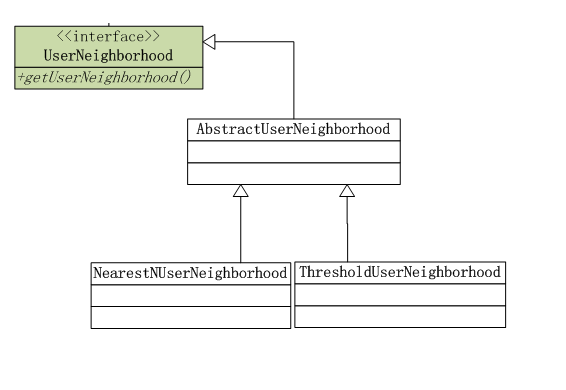
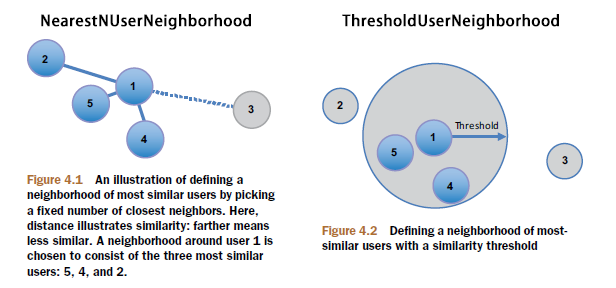
近邻算法分为2种:
- NearestNUserNeighborhood:指定N的个数,比如,选出前10最相似的用户。
- ThresholdUserNeighborhood:指定比例,比如,选择前10%最相似的用户。
6. 推荐算法工具集
推荐算法是以Recommender作为基础的父类,关于推荐算法的详细介绍,请参考文章:Mahout推荐算法API详解
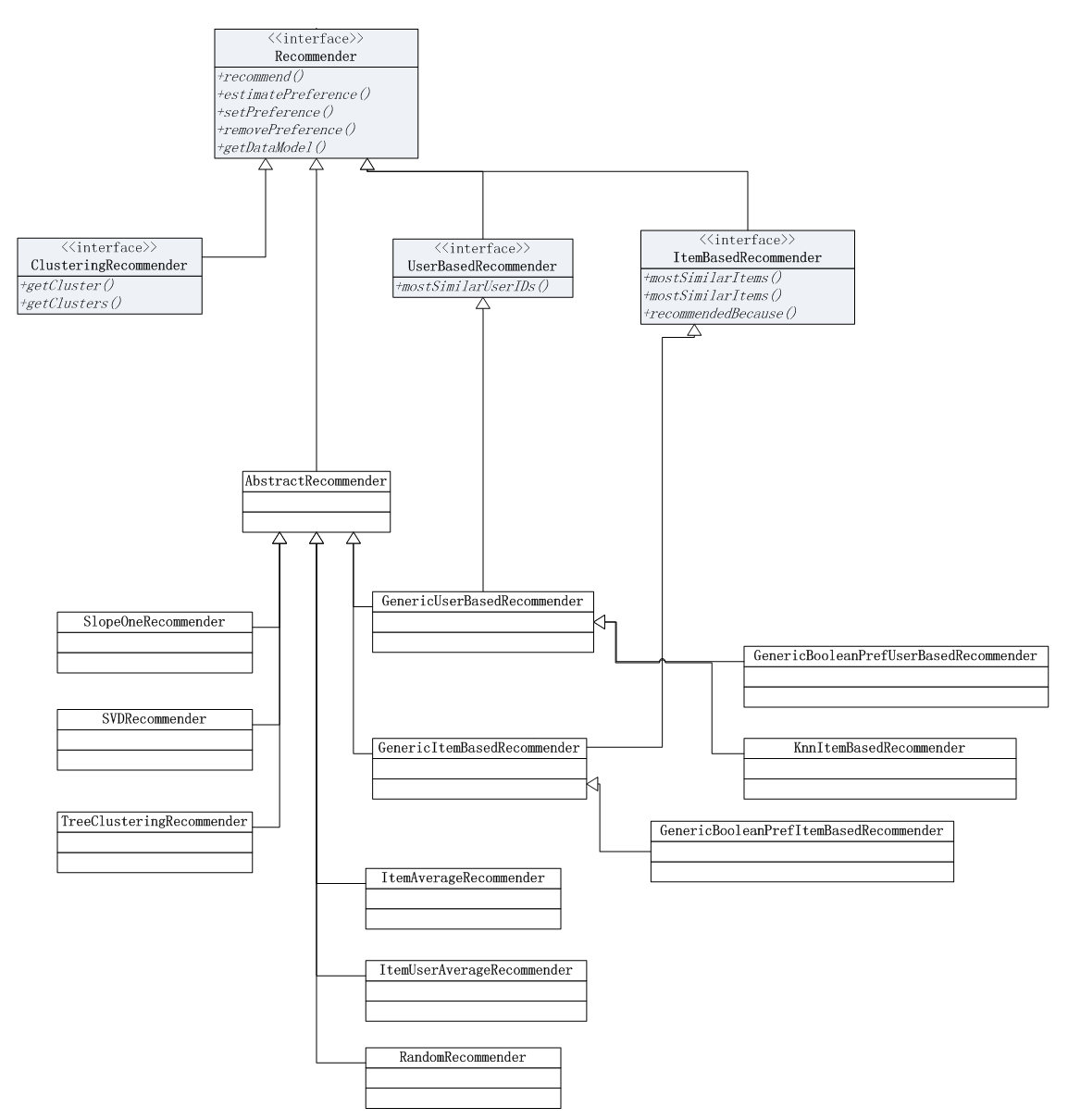
7. 创建自己的推荐引擎构造器
有了上面的知识,我就清楚地知道了Mahout推荐引擎的原理和使用,我们就可以写一个自己的构造器,通过“策略模式”实现,算法的组合。
新建文件:org.conan.mymahout.recommendation.job.RecommendFactory.java
public final class RecommendFactory {
...
}
1). 构造数据模型
public static DataModel buildDataModel(String file) throws TasteException, IOException {
return new FileDataModel(new File(file));
}
public static DataModel buildDataModelNoPref(String file) throws TasteException, IOException {
return new GenericBooleanPrefDataModel(GenericBooleanPrefDataModel.toDataMap(new FileDataModel(new File(file))));
}
public static DataModelBuilder buildDataModelNoPrefBuilder() {
return new DataModelBuilder() {
@Override
public DataModel buildDataModel(FastByIDMap trainingData) {
return new GenericBooleanPrefDataModel(GenericBooleanPrefDataModel.toDataMap(trainingData));
}
};
}
2). 构造相似度算法模型
public enum SIMILARITY {
PEARSON, EUCLIDEAN, COSINE, TANIMOTO, LOGLIKELIHOOD, FARTHEST_NEIGHBOR_CLUSTER, NEAREST_NEIGHBOR_CLUSTER
}
public static UserSimilarity userSimilarity(SIMILARITY type, DataModel m) throws TasteException {
switch (type) {
case PEARSON:
return new PearsonCorrelationSimilarity(m);
case COSINE:
return new UncenteredCosineSimilarity(m);
case TANIMOTO:
return new TanimotoCoefficientSimilarity(m);
case LOGLIKELIHOOD:
return new LogLikelihoodSimilarity(m);
case EUCLIDEAN:
default:
return new EuclideanDistanceSimilarity(m);
}
}
public static ItemSimilarity itemSimilarity(SIMILARITY type, DataModel m) throws TasteException {
switch (type) {
case LOGLIKELIHOOD:
return new LogLikelihoodSimilarity(m);
case TANIMOTO:
default:
return new TanimotoCoefficientSimilarity(m);
}
}
public static ClusterSimilarity clusterSimilarity(SIMILARITY type, UserSimilarity us) throws TasteException {
switch (type) {
case NEAREST_NEIGHBOR_CLUSTER:
return new NearestNeighborClusterSimilarity(us);
case FARTHEST_NEIGHBOR_CLUSTER:
default:
return new FarthestNeighborClusterSimilarity(us);
}
}
3). 构造近邻算法模型
public enum NEIGHBORHOOD {
NEAREST, THRESHOLD
}
public static UserNeighborhood userNeighborhood(NEIGHBORHOOD type, UserSimilarity s, DataModel m, double num) throws TasteException {
switch (type) {
case NEAREST:
return new NearestNUserNeighborhood((int) num, s, m);
case THRESHOLD:
default:
return new ThresholdUserNeighborhood(num, s, m);
}
}
4). 构造推荐算法模型
public enum RECOMMENDER {
USER, ITEM
}
public static RecommenderBuilder userRecommender(final UserSimilarity us, final UserNeighborhood un, boolean pref) throws TasteException {
return pref ? new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericUserBasedRecommender(model, un, us);
}
} : new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericBooleanPrefUserBasedRecommender(model, un, us);
}
};
}
public static RecommenderBuilder itemRecommender(final ItemSimilarity is, boolean pref) throws TasteException {
return pref ? new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericItemBasedRecommender(model, is);
}
} : new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
return new GenericBooleanPrefItemBasedRecommender(model, is);
}
};
}
public static RecommenderBuilder slopeOneRecommender() throws TasteException {
return new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
return new SlopeOneRecommender(dataModel);
}
};
}
public static RecommenderBuilder itemKNNRecommender(final ItemSimilarity is, final Optimizer op, final int n) throws TasteException {
return new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
return new KnnItemBasedRecommender(dataModel, is, op, n);
}
};
}
public static RecommenderBuilder svdRecommender(final Factorizer factorizer) throws TasteException {
return new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
return new SVDRecommender(dataModel, factorizer);
}
};
}
public static RecommenderBuilder treeClusterRecommender(final ClusterSimilarity cs, final int n) throws TasteException {
return new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
return new TreeClusteringRecommender(dataModel, cs, n);
}
};
}
5). 构造算法评估模型
public enum EVALUATOR {
AVERAGE_ABSOLUTE_DIFFERENCE, RMS
}
public static RecommenderEvaluator buildEvaluator(EVALUATOR type) {
switch (type) {
case RMS:
return new RMSRecommenderEvaluator();
case AVERAGE_ABSOLUTE_DIFFERENCE:
default:
return new AverageAbsoluteDifferenceRecommenderEvaluator();
}
}
public static void evaluate(EVALUATOR type, RecommenderBuilder rb, DataModelBuilder mb, DataModel dm, double trainPt) throws TasteException {
System.out.printf("%s Evaluater Score:%s\n", type.toString(), buildEvaluator(type).evaluate(rb, mb, dm, trainPt, 1.0));
}
public static void evaluate(RecommenderEvaluator re, RecommenderBuilder rb, DataModelBuilder mb, DataModel dm, double trainPt) throws TasteException {
System.out.printf("Evaluater Score:%s\n", re.evaluate(rb, mb, dm, trainPt, 1.0));
}
/**
* statsEvaluator
*/
public static void statsEvaluator(RecommenderBuilder rb, DataModelBuilder mb, DataModel m, int topn) throws TasteException {
RecommenderIRStatsEvaluator evaluator = new GenericRecommenderIRStatsEvaluator();
IRStatistics stats = evaluator.evaluate(rb, mb, m, null, topn, GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD, 1.0);
// System.out.printf("Recommender IR Evaluator: %s\n", stats);
System.out.printf("Recommender IR Evaluator: [Precision:%s,Recall:%s]\n", stats.getPrecision(), stats.getRecall());
}
6). 推荐结果输出
public static void showItems(long uid, List recommendations, boolean skip) {
if (!skip || recommendations.size() > 0) {
System.out.printf("uid:%s,", uid);
for (RecommendedItem recommendation : recommendations) {
System.out.printf("(%s,%f)", recommendation.getItemID(), recommendation.getValue());
}
System.out.println();
}
}
7). 完整源代码文件及使用样例:
https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8/src/main/java/org/conan/mymahout/recommendation/job
转载请注明出处:
http://blog.fens.me/mahout-recommend-engine/

[…] 更详细的介绍,请参考文章:从源代码剖析Mahout推荐引擎 […]
请问在5). 构造算法评估模型中
public static void evaluate和public static void statsEvaluator这两个算法评估模型有什么区别?
为什么在recommendtest.java中分别运行recommendfactory.evaluate()与recommendfactory.statsEvaluator(),得到的推荐结果差距非常大?
1.statsEvaluator是构造recall和precision,evaluate是构造AVERAGE_ABSOLUTE_DIFFERENCE。
区别参考:http://blog.fens.me/mahout-recommendation-api/
2. recommendtest.java??这个类在文章中没有出现吧?我不知道是什么。
evaluate和statsEvaluator,是不一样的概念,结果当然是不同的。
多谢多谢! 还有个问题,请问在测试evaluate states 的时候 怎样只测试一个id呢? 现在是数据中所有的用户都被测试了一次,时间太长了, 我只是想测试一个用户而已。
计算一个用户的结果,也需要读入整个数据集。结果是基于数据计算出来的。
你需要补充一下,数据挖掘的概念再动手做,不然你全是问题,自己什么都解决不了。
不好意思,我可能表达的不准确。 我知道怎么说都要读入整个数据集的。 举个例子说下面的是我测试的时候很多的output之一
[main] INFO org.apache.mahout.cf.taste.impl.model.GenericDataModel – Processed 1000000 users
[main] INFO org.apache.mahout.cf.taste.impl.eval.GenericRecommenderIRStatsEvaluator – Evaluated with user 411685 in 27ms
[main] INFO org.apache.mahout.cf.taste.impl.eval.GenericRecommenderIRStatsEvaluator – Precision/recall/fall-out/nDCG/reach: 0.013888888888888888 / 0.013888888888888888 / 0.003079191603781768 / 0.00934041868172875 / 1.0
假设我有1百万个user id 那这个evaluate states 就计算评估了1百万个user id 换句话说数据集被读入1百万次。 这种情况下,会很慢很慢。。。。所以我只想评估计算一个指定的user id, 那数据集也只需要读入一次而已。 我查了下mahout api貌似也没看到怎么个做法,这个想法有办法实现么??
你好
[…] 从源代码剖析Mahout推荐引擎 […]
请问recommenderbuilder 是每次需要重新build么? 可不可以保存然后用来下次recommend使用?
recommenderbuilder,用于建模,不加载数据,也不占用时间。只有循环计算时showItems才会加载数据,比较耗时。
mahout的协同过滤,没有训练集的概念。
谢谢,不过builder建模后,不能保存模型么? 就像weka建模一样可以保存的那种功能没有么?
不能保存模型,和weka不一样。
监督学习(分类算法)才需要保存模型,不基于数据且可以快速构建的模型,都不需要保存模型。
[…] 针对上面的数据,我将用7种算法组合进行测试:有关Mahout算法组合的详细解释,请参考文章:从源代码剖析Mahout推荐引擎 […]
您好!女程序媛一名,最近刚开始研究推荐系统,有些问题,请不吝赐教!非常感谢!
1.原始数据只有(userid,itemid,二值项),如何构造出SVD推荐所需要的Factorizer等?
2.model,similarity,neib,recommender,evaluate这五步在很庞大的原始数据下,哪些耗时很长?recommender是否可以在用户登录之后实时根据其id进行计算?还是说会耗时很长需要提前计算好存储起来?
3.很多网站的推荐系统都是每日离线计算第二天的推荐信息,计算时是根据网站目前所有的用户历史操作记录全量进行计算,日积月累,终会垮掉,mahout有提供增量计算(每日记录)来修正全量计算结果的方法吗?
4.推荐的实时性,按照项亮《推荐系统实践》里说的,我理解是说网站至少应该有储存三张表,一张是item相关表,即里面储存所有item的相似度,一张是user相关表,即里面储存所有user的相似度,第三张是推荐表,即按照mahout的5步进行下来的(用户id,推荐列表)。item相关表主要是为了解决当用户实时对某item进行操作了之后,根据item相关表可以对用户新行为及时调整推荐结果(即推荐与用户此时操作的item相似度最高的几个item)以满足用户最新的兴趣;users相关表也是这个道理。
请问这种想法是否合理?
你好,女程序员加油!
1. SVD,我好像没有文章介绍,这个算法不适合用海量数据。只是样本数据集,竞赛时表现的很好。
2. recommender,evaluate,是耗时的操作,itemCF有些情况可以存储起来,需要自己实现。
3. 增量计算mahout没有提供,需要自己实现算法。同第二问的存储思路。
4. 《推荐系统实践》应用场景主要是竞赛和样本数据。你可以设计数据结构,保存这些计算的中间结果,解决时时推荐和冷启动的问题。但准确度肯定会下降,这就是时间和准确度的取舍。
从头构建一个推荐系统是非常容易的,提高推荐系统的准确度,才是要花时间去研究的课题。而且每种场景推荐算法都不一样,有的是密集数据,有的是稀疏数据,那么同一个算法表现也会差距非常大。
很多时候,要结合概率和统计的知识,去思考整个的过程,只从计算机考虑,结果大都不是最好的。
非常感谢!请问对于稀疏度达98%以上的数据,一般采取哪种算法准确度比较高?
没有通用的算法,能让稀疏数据准确度很高的。需要自己建模!
你好,博主,我在调试你的分布式ItemCF时,出现下面的错误,不仅没有结果输出而且其他目录下的输出文件中都是乱码
你好博主, 我在用recommeder.estimatePreference的时候有时候会出现Nan,这个值,具体会出现这种情况的是什么原因啊?有什么思路可以去解决这类问题吗?
NAN, 表示计算出错。 比如,1 / 0 = NAN
请问具体的原因你知道是为什么吗?当我在用mahout 来估分就有时候会估成NaN。但是,同样的情况,我用Lenkit的 scorePredictor 就可以估出来,那lenskit是怎么解决这种情况的呢?
从源代码检查吧
你好:myzk的包中的数据测试什么的?org.conan.myzk.hadoop.Purchase
你好:org.conan.myzk.hadoop.Purchase能问一下这个包是干什么用的吗
你好博主,请问mahout可以得到推荐原因的信息吗?比如推荐这个商品是因为我买过另外一件商品?
可以,协同过滤算法是可解释的
请问如何解释?
根据计算原理解释。参考案例:
http://blog.fens.me/hadoop-mahout-recommend-book/