R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-catools/

前言
R语言生来就是自由的,不像Java,PHP等有统一的规范约束。R语言不仅命名、语法各包各异,就连功能也是各种混搭。caTools库就是这种混搭库,包括了不相关的几组函数工具集,有图片处理的,有编解码的,有分类器的,有向量计算的,有科学计算的。而且都很好用!
以致于我都不知道,如何用简短的语言去描述这个包了!!唯有“奇特”来概括它的特点。
目录
- caTools介绍
- caTools安装
- caTools的API介绍
- caTools使用
1. caTools介绍
caTools是一个基础的工具包,包括移动窗口统计,二进制图片读写,快速计算AUC,LogitBoost分类器,base64的编码器/解码器,快速计算舍入、误差、求和、累计求和等函数。
发布页地址:http://cran.r-project.org/web/packages/caTools/index.html
2. caTools安装
系统环境
- Linux: Ubuntu Server 12.04.2 LTS 64bit
- R: 3.0.1 x86_64-pc-linux-gnu
- RStudio Server online
安装caTools
~ R
> install.packages("caTools")
* installing *source* package ‘caTools’ ...
** package ‘caTools’ successfully unpacked and MD5 sums checked
** libs
g++ -I/usr/share/R/include -DNDEBUG -fpic -O3 -pipe -g -c Gif2R.cpp -o Gif2R.o
g++ -I/usr/share/R/include -DNDEBUG -fpic -O3 -pipe -g -c GifTools.cpp -o GifTools.o
gcc -std=gnu99 -I/usr/share/R/include -DNDEBUG -fpic -O3 -pipe -g -c runfunc.c -o runfunc.o
g++ -shared -o caTools.so Gif2R.o GifTools.o runfunc.o -L/usr/lib/R/lib -lR
installing to /home/conan/R/x86_64-pc-linux-gnu-library/3.0/caTools/libs
** R
** preparing package for lazy loading
** help
*** installing help indices
** building package indices
** testing if installed package can be loaded
* DONE (caTools)
3. caTools的API介绍
二进制图片读写
- read.gif & write.gif: gif格式图片的读写
- read.ENVI & write.ENVI: ENVI格式图片的读写,如GIS图片
base64的编码器/解码器: http://zh.wikipedia.org/wiki/Base64
- base64encode: 编码器
- base64decode: 解码器
快速计算AUC
- colAUC: 计算ROC曲线(AUC)的面积
- combs: 向量元素的无序组合
- trapz: 数值积分形梯形法则
LogitBoost分类器
- LogitBoost: logitBoost分类算法
- predict.LogitBoost: 预测logitBoost分类
- sample.split: 把数据切分成训练集和测试集
快速计算工具
- runmad: 计算向量中位数
- runmean: 计算向量均值
- runmin & runmax: 计算向量最小值 和 最大值
- runquantile: 计算向量位数
- runsd: 计算向量标准差
- sumexact, cumsumexact: 无误差求和,针对于编程语言对于double类型的精度优化
4. caTools使用
加载类库
> library(caTools)- 1). 二进制图片读写gif
- 2). base64的编码器/解码器
- 3). ROC计算
- 4). 向量元素的无序组合
- 5). 数值积分形梯形法则
- 6). LogitBoost分类器
- 7). 快速计算工具:runmean
- 8). 快速计算工具组合
- 9). 无误差求和
1). 二进制图片读写gif
读写一个gif图片
#取datasets::volcano数据集
#写入volcano.gif
> write.gif(volcano, "volcano.gif", col=terrain.colors, flip=TRUE, scale="always", comment="Maunga Whau Volcano")
#读入图片到变量y
> y = read.gif("volcano.gif", verbose=TRUE, flip=TRUE)
GIF image header
Global colormap with 256 colors
Comment Extension
Image [61 x 87]: 3585 bytes
GIF Terminator
#通过y变量画图
image(y$image, col=y$col, main=y$comment, asp=1)
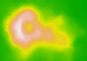
创建一个git动画
x <- y <- seq(-4*pi, 4*pi, len=200)
r <- sqrt(outer(x^2, y^2, "+"))
image = array(0, c(200, 200, 10))
for(i in 1:10) image[,,i] = cos(r-(2*pi*i/10))/(r^.25)
write.gif(image, "wave.gif", col="rainbow")
y = read.gif("wave.gif")
for(i in 1:10) image(y$image[,,i], col=y$col, breaks=(0:256)-0.5, asp=1)
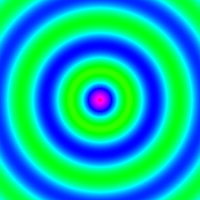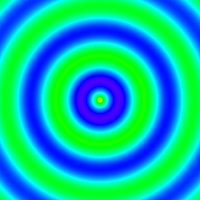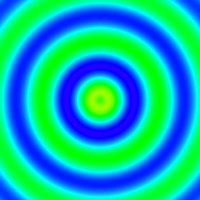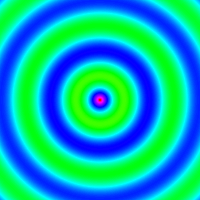
与谢益辉的animation有一样的GIF输出动画功能,且不需要依赖其他软件库。
注:animation::saveGIF需要依赖于ImageMagick或者GraphicsMagick。
2). base64的编码器/解码器
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email,email via MIME,在XML中存储复杂数据.
把一个boolean向量编解码
#设置每个元素占用的字节数
> size=1
> x = (10*runif(10)>5)
> y = base64encode(x, size=size)
> z = base64decode(y, typeof(x), size=size)
#原始数据
> x
[1] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE
#编码后的密文
> y
[1] "AAAAAAEBAAAAAA=="
#解码后的明文
> z
[1] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE
把一个字符串编解码
> x = "Hello R!!" # character
> y = base64encode(x)
> z = base64decode(y, typeof(x))
#原始数据
> x
[1] "Hello R!!"
#编码后的密文
> y
[1] "SGVsbG8gUiEh"
#解码后的明文
> z
[1] "Hello R!!"
3). ROC计算
在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是一种座标图式的分析工具,用于 (1) 选择最佳的信号侦测模型、舍弃次佳的模型。 (2) 在同一模型中设定最佳阈值。
在做决策时,ROC分析能不受成本/效益的影响,给出客观中立的建议。
ROC曲线首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。数十年来,ROC分析被用于医学、无线电、生物学、犯罪心理学领域中,而且最近在机器学习(machine learning)和数据挖掘(data mining)领域也得到了很好的发展。
介绍文字,摘自:ROC曲线
取MASS::cats数据集,3列分别Sex(性别),Bwt(体重),Hwt(心脏重量)
> library(MASS)
> data(cats)
> head(cats)
Sex Bwt Hwt
1 F 2.0 7.0
2 F 2.0 7.4
3 F 2.0 9.5
4 F 2.1 7.2
5 F 2.1 7.3
6 F 2.1 7.6
> colAUC(cats[,2:3], cats[,1], plotROC=TRUE)
Bwt Hwt
F vs. M 0.8338451 0.759048
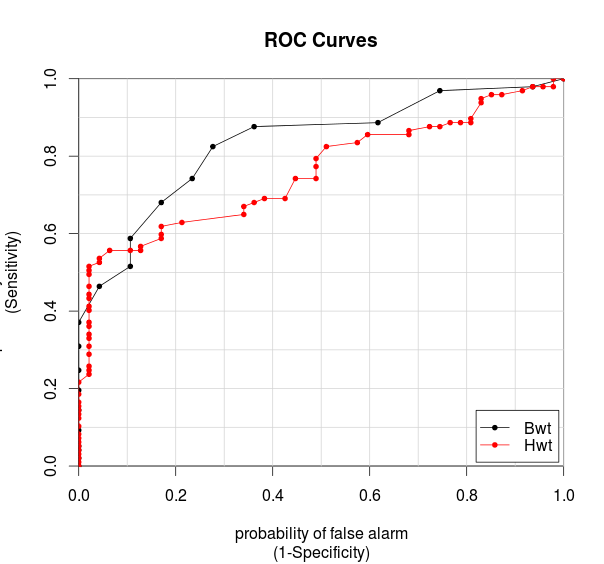
从AUC判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
对结果的解释:
从上图中,我们看到Bwt和Hwt都在(0.5,1)之间,因此,cats的数据集是一个真实有效数据集。如果cats的数据集,是一个通过分类预测的数据集,用AUC对数据集的评分,就可以检验分类器的好坏了。
4). 向量元素的无序组合
combs(v,k)
v:向量
k:组合数量小于等v的长度,[1,length(v)]
> combs(2:5, 3)
[,1] [,2] [,3]
[1,] 2 3 4
[2,] 2 3 5
[3,] 2 4 5
[4,] 3 4 5
> combs(c("cats", "dogs", "mice"), 2)
[,1] [,2]
[1,] "cats" "dogs"
[2,] "cats" "mice"
[3,] "dogs" "mice"
#快速构建矩阵
> a = combs(1:4, 2)
> a
[,1] [,2]
[1,] 1 2
[2,] 1 3
[3,] 1 4
[4,] 2 3
[5,] 2 4
[6,] 3 4
> b = matrix( c(1,1,1,2,2,3,2,3,4,3,4,4), 6, 2)
> b
[,1] [,2]
[1,] 1 2
[2,] 1 3
[3,] 1 4
[4,] 2 3
[5,] 2 4
[6,] 3 4
5). 数值积分形梯形法则
梯形法则原理:将被积函数近似为直线函数,被积的部分近似为梯形。请参考:牛顿-柯特斯公式
# integral of sine function in [0, pi] range suppose to be exactly 2.
# lets calculate it using 10 samples:
> x = (1:10)*pi/10
> trapz(x, sin(x))
[1] 1.934983
> x = (1:1000)*pi/1000
> trapz(x, sin(x))
[1] 1.999993
6). LogitBoost分类器
取datasets::iris数据集,5列分别Sepal.Length(花萼长), Sepal.Width((花萼宽), Petal.Length(花瓣长), Petal.Width(花瓣宽),Species(种属)
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> Data = iris[,-5]
> Label = iris[, 5]
#训练模型
> model = LogitBoost(Data, Label, nIter=20)
#预测
> Lab = predict(model, Data)
> Prob = predict(model, Data, type="raw")
#预测结果
> t = cbind(Lab, Prob)
> head(t)
Lab setosa versicolor virginica
[1,] 1 1 0.017986210 1.522998e-08
[2,] 1 1 0.002472623 3.353501e-04
[3,] 1 1 0.017986210 8.315280e-07
[4,] 1 1 0.002472623 4.539787e-05
[5,] 1 1 0.017986210 1.522998e-08
[6,] 1 1 0.017986210 1.522998e-08
#增加迭代次数
> table(predict(model, Data, nIter= 2), Label)
Label
setosa versicolor virginica
setosa 48 0 0
versicolor 0 45 1
virginica 0 3 45
> table(predict(model, Data, nIter=10), Label)
Label
setosa versicolor virginica
setosa 50 0 0
versicolor 0 47 0
virginica 0 1 47
> table(predict(model, Data), Label)
Label
setosa versicolor virginica
setosa 50 0 0
versicolor 0 49 0
virginica 0 0 48
#随机划分训练集和测试集,并预测
> mask = sample.split(Label)
> model = LogitBoost(Data[mask,], Label[mask], nIter=10)
> table(predict(model, Data[!mask,], nIter=2), Label[!mask])
setosa versicolor virginica
setosa 16 0 0
versicolor 0 15 3
virginica 0 1 12
> table(predict(model, Data[!mask,]), Label[!mask])
setosa versicolor virginica
setosa 17 0 0
versicolor 0 16 4
virginica 0 1 13
7). 快速计算工具runmean
对时间序列数据,取均线。
#取datasets::BJsales数据集
> BJsales
Time Series:
Start = 1
End = 150
Frequency = 1
[1] 200.1 199.5 199.4 198.9 199.0 200.2 198.6 200.0 200.3 201.2 201.6 201.5
[13] 201.5 203.5 204.9 207.1 210.5 210.5 209.8 208.8 209.5 213.2 213.7 215.1
[25] 218.7 219.8 220.5 223.8 222.8 223.8 221.7 222.3 220.8 219.4 220.1 220.6
[37] 218.9 217.8 217.7 215.0 215.3 215.9 216.7 216.7 217.7 218.7 222.9 224.9
[49] 222.2 220.7 220.0 218.7 217.0 215.9 215.8 214.1 212.3 213.9 214.6 213.6
[61] 212.1 211.4 213.1 212.9 213.3 211.5 212.3 213.0 211.0 210.7 210.1 211.4
[73] 210.0 209.7 208.8 208.8 208.8 210.6 211.9 212.8 212.5 214.8 215.3 217.5
[85] 218.8 220.7 222.2 226.7 228.4 233.2 235.7 237.1 240.6 243.8 245.3 246.0
[97] 246.3 247.7 247.6 247.8 249.4 249.0 249.9 250.5 251.5 249.0 247.6 248.8
[109] 250.4 250.7 253.0 253.7 255.0 256.2 256.0 257.4 260.4 260.0 261.3 260.4
[121] 261.6 260.8 259.8 259.0 258.9 257.4 257.7 257.9 257.4 257.3 257.6 258.9
[133] 257.8 257.7 257.2 257.5 256.8 257.5 257.0 257.6 257.3 257.5 259.6 261.1
[145] 262.9 263.3 262.8 261.8 262.2 262.7
plot(BJsales, col="black", main = "Moving Window Means")
lines(runmean(BJsales, 3), col="red")
lines(runmean(BJsales, 8), col="green")
lines(runmean(BJsales,15), col="blue")
lines(runmean(BJsales,24), col="magenta")
lines(runmean(BJsales,50), col="cyan")
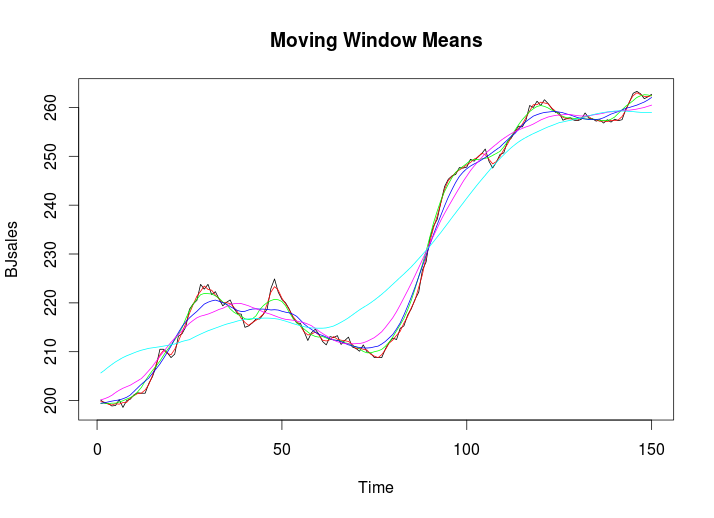
我们从图中看到6条线,黑色是原始数据。其他各颜色代表,几个点的均线。比如,红色(red)线表示3点的平均,绿色(green)线表示8个线的平均。
均线在股票上,是非常流行,实用一种看盘指标。
6).快速计算工具组合
对数据集取,最大runmax ,最小runmin ,均值runmean,中位数runmed
k=25; n=200;
x = rnorm(n,sd=30) + abs(seq(n)-n/4)
plot(x, col=col[1], main = "Moving Window Analysis Functions (window size=25)")
lines(runmin (x,k), col="red")
lines(runmed (x,k), col="green")
lines(runmean(x,k), col="blue")
lines(runmax (x,k), col="cyan")
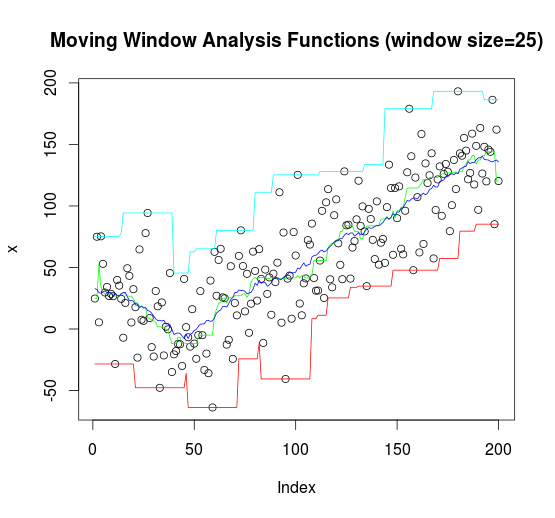
与上例子的均线一样,这次我们取4种不同的线。
7). 无误差求和
sum求和
> x = c(1, 1e20, 1e40, -1e40, -1e20, -1)
> a = sum(x); print(a)
[1] -1e+20
> b = sumexact(x); print(b)
[1] 0
我们看到x向量中的,正负加起来正好为0.但是sum函数,结果是-1e+20,由于编程精度的问题造成的计算误差。通过sumexact函数修正后,就没有误差了。
cumsum积累求和
> a = cumsum(x); print(a)
[1] 1e+00 1e+20 1e+40 0e+00 -1e+20 -1e+20
> b = cumsumexact(x); print(b)
[1] 1e+00 1e+20 1e+40 1e+20 1e+00 0e+00
cumsum同样出现了精度的误差,需要用cumsumexact来修正。
最后还是要用“奇特”来概括这个工具集,相信你也发现了他的奇特。
转载请注明出处:
http://blog.fens.me/r-catools/

很好奇博主文章开头的图片是用什么工具做的,看着很舒服—
Photoshop
楼主好强大,请问楼主做什么方向的?数据挖掘?
主要做量化金融,数据挖掘是前2年做的事情了。
[…] websockets库依赖于caTools库,caTools是一个工具集,请参考文章:caTools一个奇特的工具集 […]
学习了,的确是很奇异的工具包啊,不知道算哪一类了。
谢谢博主分享
感觉你打算每篇文章都读一遍呢!
还真有可能。
您的博客文章整理的非常棒,更像是一本书。
并且涵盖的内容刚好都是我想学习的。
内容跟新也非常快。
另外排版也是一级棒,精心的文字与插图。
感谢博主的这份坚持。
谢谢!有这么高的评价。
有一些内容,已经整理成图书了,纠正了博客文字的错误和代码中的bug,近期会出版。
OK,到时候一定买。
补赞一条,博主特别热血,回复特别速度,哈哈。以后还希望能多多得到您的指点。另外想请教您,您是做量化金融的,平时主要使用R吗?
1. 谢谢支持。
2. Disqus和手机绑定了,一有回复就能看到。
3. 我是在做量化金融,R只是算法引擎,还有Java, Hadoop, Javascript等的其他的技术。
赞,全能的r包,佩服楼主的探索精神
这个包的作者,应该也是想法很多的。
> library(‘caTools’)
> library(‘EBImage’)
>
> lnk gif
> png(‘Rinoa.png’)
> image(gif$image[,,1], col=gif$col, xlab=’x’, ylab=’y’, breaks=(0:256)-0.5, asp=1)
> title(main=’FF VIII’, font.main=4)
> dev.off()
> display(readImage(‘Rinoa.png’))
> file.remove(‘Rinoa.png’)
有空的时候,再阅读一下怎么切片,然后通过display把整个animation 的 gif 动态图像逐个逐个看。。。
http://www.bricol.net/research/leafranks/11-01MS/EBImage-introduction.pdf
COOL!