R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员/Quant: Java,R,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-descriptr

前言
我们获得数据后需要了解数据,通常会用到统计特征来观察数据,比如字段类型,数据集长度,均值,方差,数据分布,概率密度等。
descriptr包,为了我们提供了一套用来观察数据统计特征的工具集,主要特性包括统计特征计算,离散度,频率表,交叉表,分组摘要和多个单/双向表的度量,可以让我们非常方便的观察的数据特征。
目录
- descriptr包介绍
- descriptr包函数列表
- descriptr包函数使用
1. descriptr包介绍
descriptr包,主要用于生成描述性统计信息。它提供了3种数据处理视角,连续变量、类别变量(离散变量)和可视化。descriptr包的统计特征计算部分的源代码,结构非常工整,大量用到dplyr包来构建。
开发环境所使用的系统环境
- Win10 64bit
- R: 3.4.2 x86_64-w64-mingw32/x64 b4bit
descriptr包的安装比较简单,直接用install.pacakges()函数就行。
> install.packages("descriptr")
> library(descriptr)
2. descriptr包函数列表
descriptr包,提供了3种处理视角,连续变量、类别变量、和可视化。我们将分别介绍这3种处理视角的函数。
descriptr包,提供了2个数据集,我们可以基于这2个数据集进行学习和测试。文中的例子,都是基于mtcarz的数据集进行构建的。
数据集:
- hsb, 高中数据集
- mtcarz, 汽车数据集,复制系统的mtcars数据集
2.1 连续变量
2.1.1 统计概览
- ds_summary_stats, 统计概率
- ds_auto_summary_stats, 自动统计概率
- ds_group_summary, 分组描述性统计
- ds_auto_group_summary, 自动描述性统计
- ds_tidy_stats, 多变精简统计概率
- ds_multi_stats,已弃用函数,用ds_tidy_stats()替代
2.1.2 统计特征计算
- ds_mode, 计算众数
- ds_extreme_obs, 计算极端值
- ds_freq_cont, 计算频数
- ds_freq_table, 计算频率分布表
- ds_percentiles,计算分位数
- ds_range, 计算宽度, max(x)-min(x)
- ds_kurtosis, 计算峰度
- ds_skewness, 计算偏度
- ds_gmean, 计算几何平均值, prod(x)^(1/length(x))
- ds_hmean, 计算谐波均值, length(x)/sum(sapply(x, function(x) {1/x} ))
- ds_css, 计算修正平方和, sum((x1-mean)^2+(x2-mean)^2+…)
- ds_mdev, 计算平均绝对差, sum( abs(x1-mean) + abs(x2-mean) + …)
- ds_cvar, 计算变异系数, sd(x)/mean(x) * 100%
- ds_std_error, 计算标准误差, sd(x)/(length(x)^0.5)
- ds_tailobs,计算最大最小的多个值
2.1.3 度量特征
- ds_measures_location,位置的度量,包括均值,中位数和众数
- ds_measures_symmetry, 对称性的度量,包括峰度和偏度
- ds_measures_variation,变异的度量,包括宽度,方差,标准差
2.1.4 其他函数
- ds_rindex, 计算值的索引,同which
- ds_screener, 以表格展示数据
2.2 类别变量
- ds_twoway_table,计算双向表
- ds_cross_table, 展示双向表
- ds_auto_freq_table, 展示多个单向表
- ds_auto_cross_table, 展示多个双向表
- ds_tway_tables, 已弃用函数,用ds_auto_cross_table()替换
- ds_oway_tables,已弃用函数,用ds_auto_freq_table()替换
2.3 可视化
2.3.1 画图函数
- ds_plot_bar Generate bar plots
- ds_plot_bar_grouped Generate grouped bar plots
- ds_plot_bar_stacked Generate stacked bar plots
- ds_plot_box_group Compare distributions
- ds_plot_box_single Generate box plots
- ds_plot_density Generate density plots
- ds_plot_histogram Generate histograms
- ds_plot_scatter Generate scatter plots
2.3.2 已弃用函数,调用vistributions包
- dist_binom_perc, 可视化二项分布
- dist_binom_plot, 可视化二项分布
- dist_binom_prob,可视化二项分布
- dist_chi_perc, 可视化卡方分布
- dist_chi_plot, 可视化卡方分布
- dist_chi_prob, 可视化卡方分布
- dist_f_perc, 可视化F分布
- dist_f_plot, 可视化F分布
- dist_f_prob, 可视化F分布
- dist_norm_perc, 可视化正态分布
- dist_norm_plot, 可视化正态分布
- dist_norm_prob, 可视化正态分布
- dist_t_perc, 可视化T分布
- dist_t_plot, 可视化T分布
- dist_t_prob, 可视化T分布
2.4 演示小程序
一个演示的小程序,可以快速看到功能界面,使用shiny来构建的。
- ds_launch_shiny_app, Shiny演示小程序
3. descriptr包函数使用
接下来,我们找一些对于我们观察数据非常方便的函数进行列举。
首先,我们先了解一个我们要使用的数据集mtcarz
> mtcarz
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
3.1 数据展示
通过ds_screener()函数进行静态数据集展示,替代函数原系统的str()函数。
# 查看数据静态结构
> ds_screener(mtcarz)
-----------------------------------------------------------------------
| Column Name | Data Type | Levels | Missing | Missing (%) |
-----------------------------------------------------------------------
| mpg | numeric | NA | 0 | 0 |
| cyl | factor | 4 6 8 | 0 | 0 |
| disp | numeric | NA | 0 | 0 |
| hp | numeric | NA | 0 | 0 |
| drat | numeric | NA | 0 | 0 |
| wt | numeric | NA | 0 | 0 |
| qsec | numeric | NA | 0 | 0 |
| vs | factor | 0 1 | 0 | 0 |
| am | factor | 0 1 | 0 | 0 |
| gear | factor | 3 4 5 | 0 | 0 |
| carb | factor |1 2 3 4 6 8| 0 | 0 |
-----------------------------------------------------------------------
Overall Missing Values 0
Percentage of Missing Values 0 %
Rows with Missing Values 0
Columns With Missing Values 0
# str()函数的静态结构
> str(mtcarz)
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : Factor w/ 3 levels "4","6","8": 2 2 1 2 3 2 3 1 1 2 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : Factor w/ 2 levels "0","1": 1 1 2 2 1 2 1 2 2 2 ...
$ am : Factor w/ 2 levels "0","1": 2 2 2 1 1 1 1 1 1 1 ...
$ gear: Factor w/ 3 levels "3","4","5": 2 2 2 1 1 1 1 2 2 2 ...
$ carb: Factor w/ 6 levels "1","2","3","4",..: 4 4 1 1 2 1 4 2 2 4 ...
3.2 统计概览
通过ds_summary_stats()函数,查看数据集中某个连续型变量的所有统计特征值。
# 统计概览
> ds_summary_stats(mtcarz,mpg)
-------------------------------------------- Variable: mpg --------------------------------------------
Univariate Analysis
N 32.00 Variance 36.32
Missing 0.00 Std Deviation 6.03
Mean 20.09 Range 23.50
Median 19.20 Interquartile Range 7.38
Mode 10.40 Uncorrected SS 14042.31
Trimmed Mean 19.95 Corrected SS 1126.05
Skewness 0.67 Coeff Variation 30.00
Kurtosis -0.02 Std Error Mean 1.07
Quantiles
Quantile Value
Max 33.90
99% 33.44
95% 31.30
90% 30.09
Q3 22.80
Median 19.20
Q1 15.43
10% 14.34
5% 12.00
1% 10.40
Min 10.40
Extreme Values
Low High
Obs Value Obs Value
15 10.4 20 33.9
16 10.4 18 32.4
24 13.3 19 30.4
7 14.3 28 30.4
17 14.7 26 27.3
输出分成了3个部分:Univariate Analysis(单变量分析),Quantiles(分位数),Extreme Values(极值)。
- Univariate Analysis(单变量分析),包括N(个数),Missing(缺失值),Mean(均值),Median(中位数),Mode(众数),Trimmed Mean(修正均值),Skewness(偏度),Kurtosis(峰度),Variance(方差),Std Deviation(标准差),Range(范围,最大-最小),Interquartile Range(四分位数范围),Uncorrected SS(未修正平方和),Corrected SS(修正平方和), Coeff Variation(变异系数,标准差/均值),Std Error Mean(标准误差均值)
- Quantiles(分位数),从最小值到最小值,按顺序排列,对应的数值。
- Extreme Values(极值),包括最小值前5个,最大值前5个。
3.3 统计特征快速查看
通过ds_tidy_stats()函数,查看数据集中各变量的统计特征,维度比较少。
# 多变量统计
> ds_tidy_stats(mtcarz, mpg, disp, hp)
# A tibble: 3 x 16
vars min max mean t_mean median mode range variance stdev skew kurtosis coeff_var
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 disp 71.1 472 231. 228 196. 276. 401. 15361. 124. 0.420 -1.07 53.7
2 hp 52 335 147. 144. 123 110 283 4701. 68.6 0.799 0.275 46.7
3 mpg 10.4 33.9 20.1 20.0 19.2 10.4 23.5 36.3 6.03 0.672 -0.0220 30.0
# ... with 3 more variables: q1 <dbl>, q3 <dbl>, iqrange <dbl>3.4 频率表
通过ds_freq_table()函数,把数据集中某个连续型变量,进行等宽划分,形成频率表。
# 划分成5个等宽的频率
> ds_freq_table(mtcarz,mpg,5)
Variable: mpg
|-----------------------------------------------------------------------|
| Bins | Frequency | Cum Frequency | Percent | Cum Percent |
|-----------------------------------------------------------------------|
| 10.4 - 15.1 | 6 | 6 | 18.75 | 18.75 |
|-----------------------------------------------------------------------|
| 15.1 - 19.8 | 12 | 18 | 37.5 | 56.25 |
|-----------------------------------------------------------------------|
| 19.8 - 24.5 | 8 | 26 | 25 | 81.25 |
|-----------------------------------------------------------------------|
| 24.5 - 29.2 | 2 | 28 | 6.25 | 87.5 |
|-----------------------------------------------------------------------|
| 29.2 - 33.9 | 4 | 32 | 12.5 | 100 |
|-----------------------------------------------------------------------|
| Total | 32 | - | 100.00 | - |
|-----------------------------------------------------------------------|
3.5 分组统计
通过ds_group_summary()函数,把数据集中变量进行分组,再分别计算统计特征。
> k<-ds_group_summary(mtcarz,cyl,mpg);k
mpg by cyl
-----------------------------------------------------------------------------------------
| Statistic/Levels| 4| 6| 8|
-----------------------------------------------------------------------------------------
| Obs| 11| 7| 14|
| Minimum| 21.4| 17.8| 10.4|
| Maximum| 33.9| 21.4| 19.2|
| Mean| 26.66| 19.74| 15.1|
| Median| 26| 19.7| 15.2|
| Mode| 22.8| 21| 10.4|
| Std. Deviation| 4.51| 1.45| 2.56|
| Variance| 20.34| 2.11| 6.55|
| Skewness| 0.35| -0.26| -0.46|
| Kurtosis| -1.43| -1.83| 0.33|
| Uncorrected SS| 8023.83| 2741.14| 3277.34|
| Corrected SS| 203.39| 12.68| 85.2|
| Coeff Variation| 16.91| 7.36| 16.95|
| Std. Error Mean| 1.36| 0.55| 0.68|
| Range| 12.5| 3.6| 8.8|
| Interquartile Range| 7.6| 2.35| 1.85|
-----------------------------------------------------------------------------------------
3.6 分组分类统计
通过ds_auto_group_summary()函数,把数据集中变量进行分组,再分别两两计算统计特征。
# 分组分类
> ds_auto_group_summary(mtcarz, cyl, gear, mpg)
mpg by cyl
-----------------------------------------------------------------------------------------
| Statistic/Levels| 4| 6| 8|
-----------------------------------------------------------------------------------------
| Obs| 11| 7| 14|
| Minimum| 21.4| 17.8| 10.4|
| Maximum| 33.9| 21.4| 19.2|
| Mean| 26.66| 19.74| 15.1|
| Median| 26| 19.7| 15.2|
| Mode| 22.8| 21| 10.4|
| Std. Deviation| 4.51| 1.45| 2.56|
| Variance| 20.34| 2.11| 6.55|
| Skewness| 0.35| -0.26| -0.46|
| Kurtosis| -1.43| -1.83| 0.33|
| Uncorrected SS| 8023.83| 2741.14| 3277.34|
| Corrected SS| 203.39| 12.68| 85.2|
| Coeff Variation| 16.91| 7.36| 16.95|
| Std. Error Mean| 1.36| 0.55| 0.68|
| Range| 12.5| 3.6| 8.8|
| Interquartile Range| 7.6| 2.35| 1.85|
-----------------------------------------------------------------------------------------
mpg by gear
-----------------------------------------------------------------------------------------
| Statistic/Levels| 3| 4| 5|
-----------------------------------------------------------------------------------------
| Obs| 15| 12| 5|
| Minimum| 10.4| 17.8| 15|
| Maximum| 21.5| 33.9| 30.4|
| Mean| 16.11| 24.53| 21.38|
| Median| 15.5| 22.8| 19.7|
| Mode| 10.4| 21| 15|
| Std. Deviation| 3.37| 5.28| 6.66|
| Variance| 11.37| 27.84| 44.34|
| Skewness| -0.09| 0.7| 0.56|
| Kurtosis| -0.38| -0.77| -1.83|
| Uncorrected SS| 4050.52| 7528.9| 2462.89|
| Corrected SS| 159.15| 306.29| 177.37|
| Coeff Variation| 20.93| 21.51| 31.15|
| Std. Error Mean| 0.87| 1.52| 2.98|
| Range| 11.1| 16.1| 15.4|
| Interquartile Range| 3.9| 7.08| 10.2|
-----------------------------------------------------------------------------------------
3.7 测量
通过ds_measures_xxx()的几个函数,把数据集中变量,分别进行不同维度的统计特征。如果您想要查看位置,变化,对称性,百分位数和极端观测值的度量,请使用以下函数。 除了ds_extreme_obs()之外,所有这些都将使用单个或多个变量。 如果未指定变量,则它们将返回数据集中所有连续变量的结果。
数据集变化分析:范围,四分位范围,方差,标准差,变异系数,标准误差
> ds_measures_variation(mtcarz)
# A tibble: 6 x 7
var range iqr variance sd coeff_var std_error
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 disp 401. 205. 15361. 124. 53.7 21.9
2 drat 2.17 0.840 0.286 0.535 14.9 0.0945
3 hp 283 83.5 4701. 68.6 46.7 12.1
4 mpg 23.5 7.38 36.3 6.03 30.0 1.07
5 qsec 8.40 2.01 3.19 1.79 10.0 0.316
6 wt 3.91 1.03 0.957 0.978 30.4 0.173
数据集数值分析:均值,修正均值,中位数,众数
> ds_measures_location(mtcarz)
# A tibble: 6 x 5
var mean trim_mean median mode
<chr> <dbl> <dbl> <dbl> <dbl>
1 disp 231. 228 196. 276.
2 drat 3.60 3.58 3.70 3.07
3 hp 147. 144. 123 110
4 mpg 20.1 20.0 19.2 10.4
5 qsec 17.8 17.8 17.7 17.0
6 wt 3.22 3.20 3.32 3.44
数据集分位数分析:从最小值到最大值排序
> ds_percentiles(mtcarz)
# A tibble: 6 x 12
var min per1 per5 per10 q1 median q3 per95 per90 per99 max
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 disp 71.1 72.5 77.4 80.6 121. 196. 326 449 396. 468. 472
2 drat 2.76 2.76 2.85 3.01 3.08 3.70 3.92 4.31 4.21 4.78 4.93
3 hp 52 55.1 63.6 66 96.5 123 180 254. 244. 313. 335
4 mpg 10.4 10.4 12.0 14.3 15.4 19.2 22.8 31.3 30.1 33.4 33.9
5 qsec 14.5 14.5 15.0 15.5 16.9 17.7 18.9 20.1 20.0 22.1 22.9
6 wt 1.51 1.54 1.74 1.96 2.58 3.32 3.61 5.29 4.05 5.40 5.42
极值分析
> ds_extreme_obs(mtcarz,mpg)
# A tibble: 10 x 3
type value index
<chr> <dbl> <int>
1 high 33.9 20
2 high 32.4 18
3 high 30.4 19
4 high 30.4 28
5 high 27.3 26
6 low 10.4 15
7 low 10.4 16
8 low 13.3 24
9 low 14.3 7
10 low 14.7 17
3.8 类别变量频率表
通过ds_cross_table()函数,查看数据集中类别变量的双向表。
> ds_cross_table(mtcarz, cyl, gear)
Cell Contents
|---------------|
| Frequency |
| Percent |
| Row Pct |
| Col Pct |
|---------------|
Total Observations: 32
----------------------------------------------------------------------------
| | gear |
----------------------------------------------------------------------------
| cyl | 3 | 4 | 5 | Row Total |
----------------------------------------------------------------------------
| 4 | 1 | 8 | 2 | 11 |
| | 0.031 | 0.25 | 0.062 | |
| | 0.09 | 0.73 | 0.18 | 0.34 |
| | 0.07 | 0.67 | 0.4 | |
----------------------------------------------------------------------------
| 6 | 2 | 4 | 1 | 7 |
| | 0.062 | 0.125 | 0.031 | |
| | 0.29 | 0.57 | 0.14 | 0.22 |
| | 0.13 | 0.33 | 0.2 | |
----------------------------------------------------------------------------
| 8 | 12 | 0 | 2 | 14 |
| | 0.375 | 0 | 0.062 | |
| | 0.86 | 0 | 0.14 | 0.44 |
| | 0.8 | 0 | 0.4 | |
----------------------------------------------------------------------------
| Column Total | 15 | 12 | 5 | 32 |
| | 0.468 | 0.375 | 0.155 | |
----------------------------------------------------------------------------
3.9 类别变量的双向表
通过ds_twoway_table()函数,查看数据集中类别变量的分组后的情况。
> ds_twoway_table(mtcarz, cyl, gear)
Joining, by = c("cyl", "gear", "count")
# A tibble: 8 x 6
cyl gear count percent row_percent col_percent
<fct> <fct> <int> <dbl> <dbl> <dbl>
1 4 3 1 0.0312 0.0909 0.0667
2 4 4 8 0.25 0.727 0.667
3 4 5 2 0.0625 0.182 0.4
4 6 3 2 0.0625 0.286 0.133
5 6 4 4 0.125 0.571 0.333
6 6 5 1 0.0312 0.143 0.2
7 8 3 12 0.375 0.857 0.8
8 8 5 2 0.0625 0.143 0.4
3.10 可视化连续型数据
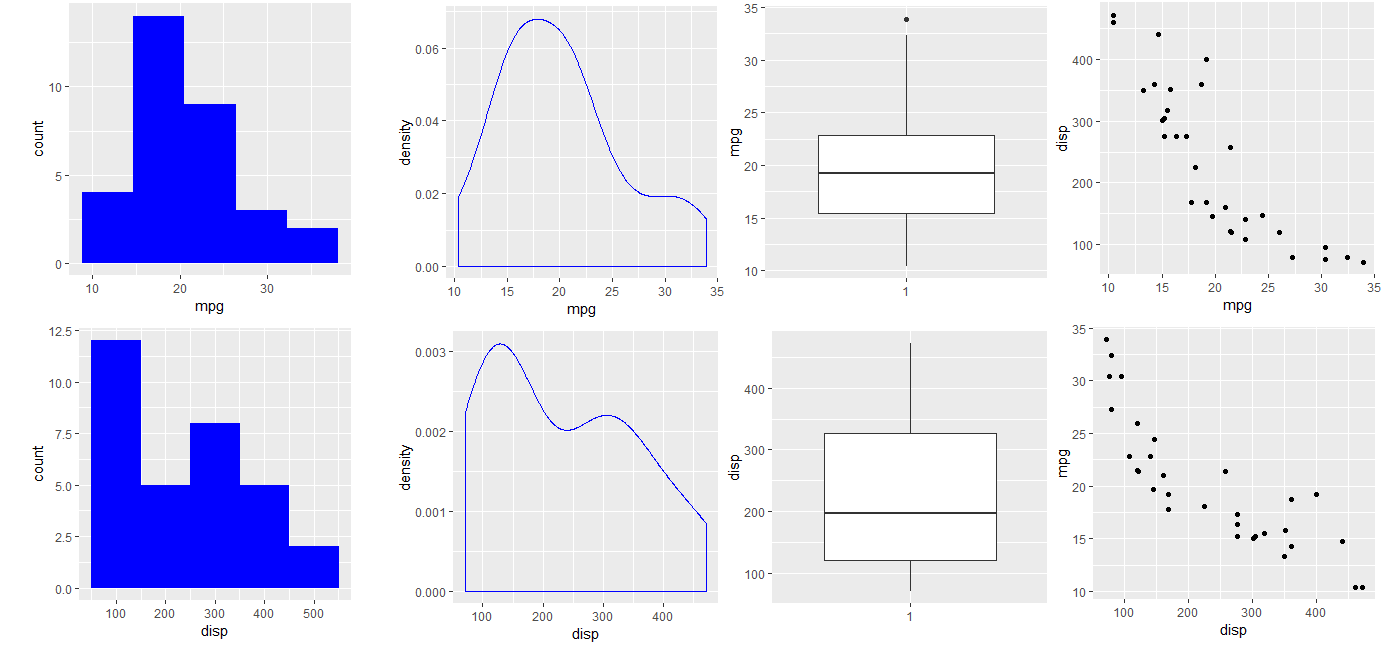
分别以柱状图,密度图,分箱图,散点图,对连续型数据进行可视化,从左到右的4个图。
> ds_plot_histogram(mtcarz, mpg, disp)
> ds_plot_density(mtcarz, mpg, disp)
> ds_plot_box_single(mtcarz, mpg, disp)
> ds_plot_scatter(mtcarz, mpg, disp)
3.11 可视化类别型数据
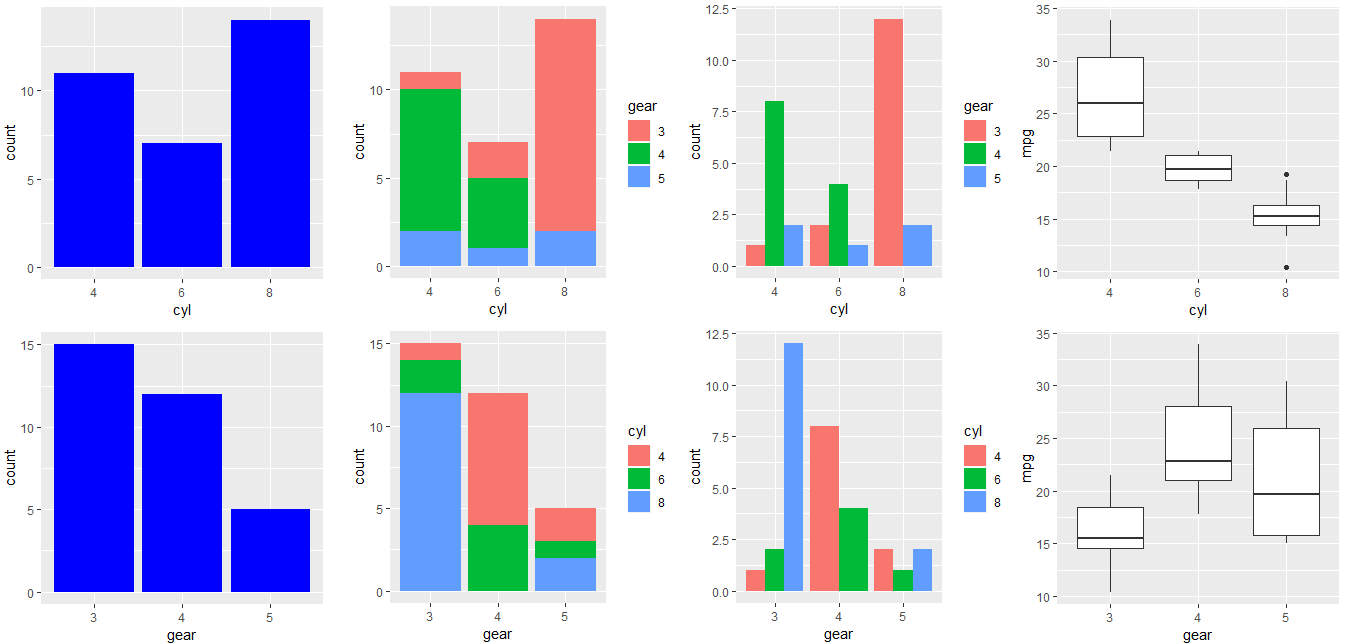
分别以bar图对类别型数据可视化,从左到右的4个图。
> ds_plot_bar(mtcarz,cyl, gear)
> ds_plot_bar_stacked(mtcarz, cyl, gear)
> ds_plot_bar_grouped(mtcarz, cyl, gear)
> ds_plot_box_group(mtcarz, cyl, gear, mpg)
3.12 可视化分布图
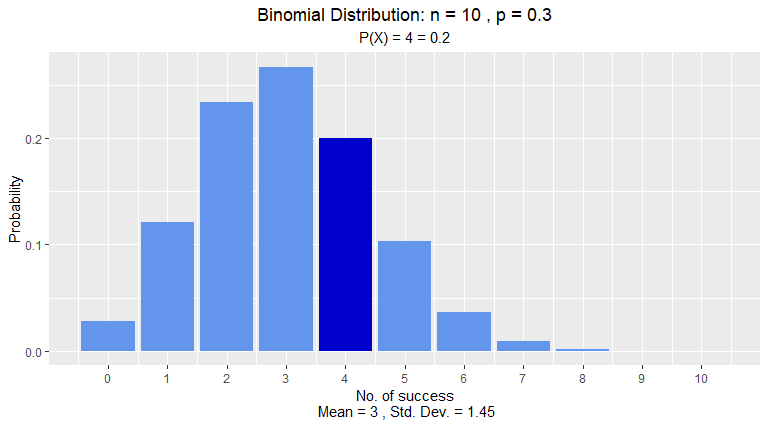
5种统计分布的可视化效果,由于使用时提示已弃用,改为调用vistributions包的对应函数,所以大家可以改用vistributions包。
二项分布
> dist_binom_prob(10, 0.3, 4, type = 'exact')
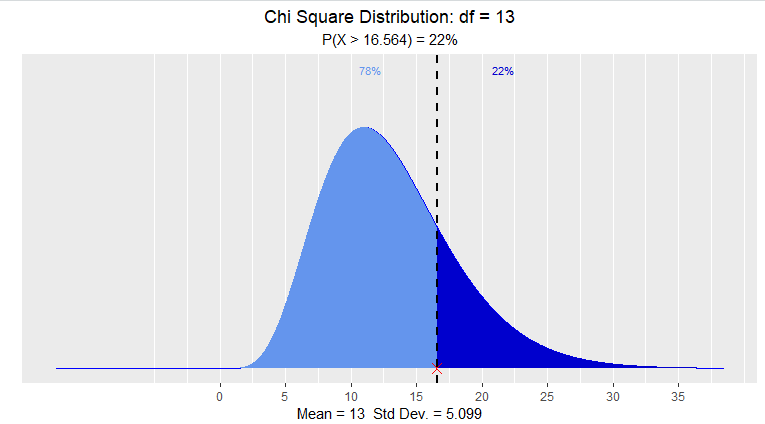
卡方分布
> dist_chi_perc(0.22, 13, 'upper')
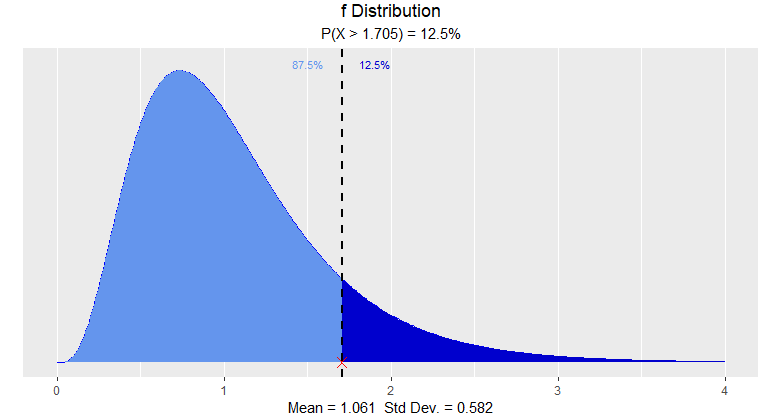
F分布
> dist_f_perc(0.125, 9, 35, 'upper')
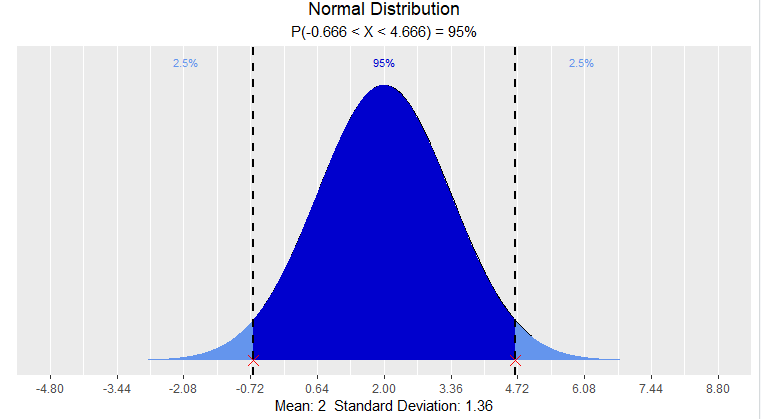
正态分布
> dist_norm_perc(0.95, mean = 2, sd = 1.36, type = 'both')
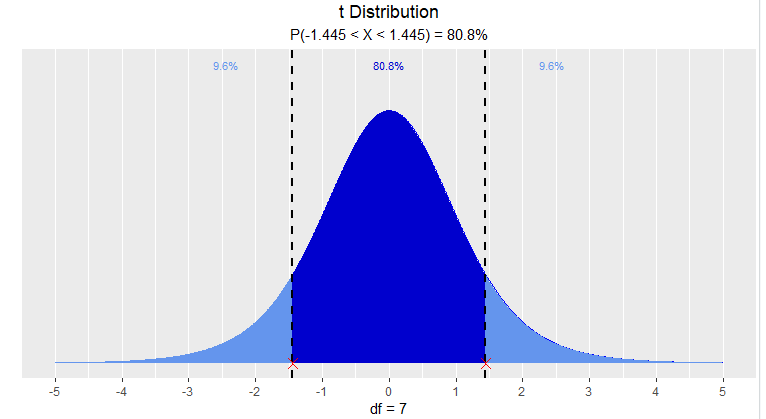
T分布
> dist_t_prob(1.445, 7, 'interval')
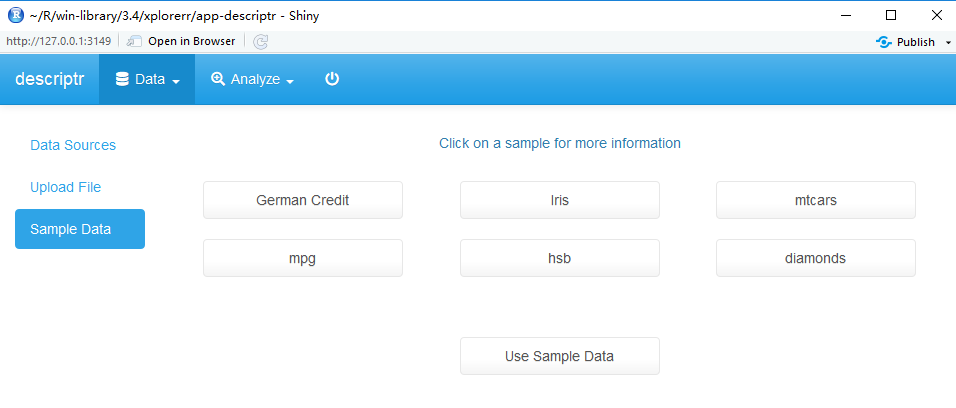
3.13 启动shiny小程序
提供了一个界面,方便小白进行操作,其实没什么用。>_<
本文对于descriptr包进行的完整的介绍,descriptr主要用于统计特征的快速查看,一个方便的工具包,对于初识数据集是非常有帮助的。
转载请注明出处:
http://blog.fens.me/r-descriptr
