RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析。Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来替代Java的MapReduce实现。有了RHadoop可以让广大的R语言爱好者,有更强大的工具处理大数据1G, 10G, 100G, TB, PB。 由于大数据所带来的单机性能问题,可能会一去不复返了。
RHadoop实践是一套系列文章,主要包括”Hadoop环境搭建”,”RHadoop安装与使用”,”R实现MapReduce的协同过滤算法”,”HBase和rhbase的安装与使用”。对于单独的R语言爱好者,Java爱好者,或者Hadoop爱好者来说,同时具备三种语言知识并不容 易。此文虽为入门文章,但R,Java,Hadoop基础知识还是需要大家提前掌握。
关于作者
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/rhadoop-java-basic/

前言
覆盖java基础知识,快速上手,RHadoop环境的搭建基础课。
目录
- 背景知识
- 开发环境
- JAVA的编译及运行环境
- JAVA语法
- JDK基本包介绍
- JAVA项目(ant, maven)
1. 背景知识
Java起源
Java是由Sun Microsystems公司于 1995年5月推出的Java面向对象程序设计语言(以下简称Java语言)和Java平台的总称。由James Gosling和同事们共同研发,并在1995年正式推出。用Java实现的HotJava浏览器(支持Java applet)显示了Java的魅力:跨平台、动态的Web、Internet计算。从此,Java被广泛接受并推动了Web的迅速发展,常用的浏览器均支持Javaapplet。另一方面,Java技术也不断更新。(2010年Oracle公司收购了SUN)
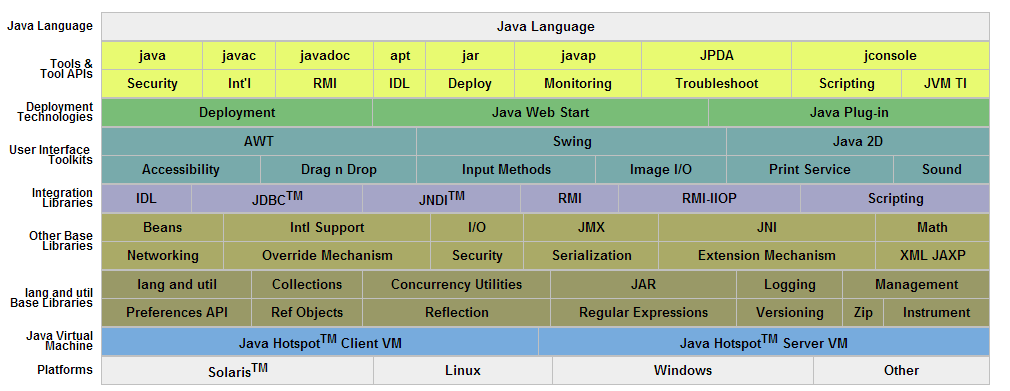
Java组成
Java由四方面组成:Java编程语言、Java类文件格式、Java虚拟机和Java应用程序接口平台(Java API)。
Java应用编程接口为Java应用提供了一个独立于操作系统的标准接口,可分为基本部分和扩展部分。在硬件或操作系统平台上安装一个Java平台之后,Java应用程序就可运行。Java平台已经嵌入了几乎所有的操作系统。这样Java程序可以只编译一次,就可以在各种系统中运行。常用的Java平台基于Java1.5,最近版本为Java8.0。
Java体系
JavaSE,standard edition,标准版,是我们通常用的一个版本.
JavaEE,enterprise edition,企业版,使用这种JDK开发JavaEE应用程序.
JavaME,micro edition,主要用于移动设备、嵌入式设备上的java应用程序.
Java版本
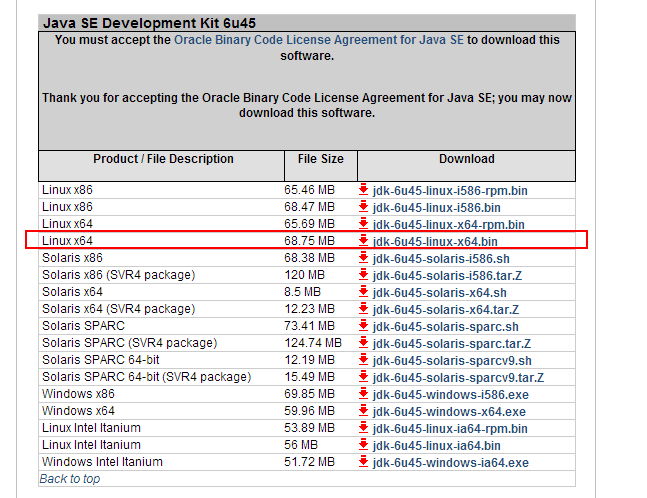
JavaSE Platform JDK6:
下载JDK6. http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-javase6-419409.html
2. 开发环境
EclipseIDE集成开发环境
http://www.eclipse.org/downloads/
3. JAVA的编译及运行环境(java,javac)
运行原理:
先编译: *.java文件 => *.class文件(字节码)
运行: *.classs => JVM(JAVA虚拟机)

4. JAVA语法
1). 命名标识符
必须以字母、美元符号或下划线开头。数字不能开头
第一个字符之后可以是任意长度的包含数字、字母、美元符号、下划线的任意组合。
不能使用Java关键字和保留字做标识符
大小写敏感的,Unicode字符会被视为普通字母对待。
A1.java, 1A.java, _a1.java, $_a1.java
2). 关键字
JavaSE6一共有50个关键字:
abstract continue for new switch
assert default goto package synchronized
boolean do if private this
break double implements protected throw
byte else import public throws
case enum instanceof return transient
catch extends int short try
char final interface static void
class finally long strictfp volatile
const float native super while
类和接口:
- class:声明类
- interface:声明接口
- abstract:声明抽象类
- implements:实现接口
- extends: 类继承
- import:包导入
- package:声明属于哪一个包
- static:静态属性,一个类下所有对象共享的属性。
- throws:声明异常
- void:空对象
基本数据类型
- int:整型
- long:长整型
- short:短整型
- float:单精度浮点型
- double:双精度浮点型
- boolean:布尔值true和false
- byte:字节型
- char:字符型
- enum:枚举类型
流程控制
- if:条件语句
- else:条件分支
- for:循环语句
- while:循环语句
- do和while:循环语句
- break:跳出循环语句
- continue:只跳出本次循环,还要继续执行下一次的循环
- return:返回
- switch:多条件语句
- case:多条件分支
- default:默认值
访问范围
- private:声明私有类型,只能供当前类内部访问
- 默认属性:不加任何访问权限修饰符,可以被同包的类访问
- protected:声明保护类型,可以被同包的类和不同包的子类访问
- public:声明公共类型,可以供所有其它类访问
类的实例
- new:创建一个新的对象实例
- this:引用相前对象实例
- super:引用超类对象实例
异常处理
- try:开始捕获错误的语句
- catch:捕获错误的语句
- finally:无论有没有异常发生都执行代码
很少会用到的
- native是方法修饰符。调用其他语言的JNI接口
- transient:变量修饰符。对象存储时,变量状态不会被持久化
- volatile:修饰变量。在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存
- strictfp修饰类和方法,意思是FP-strict,精确浮点,符合IEEE-754规范的。当一个class或interface用strictfp声明,内部所有的float和double表达式都会成为strictfp的。接口的method不能被声明为strictfp的,class的可以
- goto:被保留的关键字
3). 变量
所谓变量,就是值可以被改变的量。
public class Variable{
public static void main(String[] args){
String myName ="nabula";
myName = "nebulayao";
System.out.println(myName);
}
}
4). 常量
所谓常量,值不允许改变的量。要声明一个常量用final 修饰,常量按照Java命名规范需要用全部大写,单词之间用下划线隔开:
// 游戏方向设定 北 南 东 西
final int NORTH = 1;
final int SOUTH = 2;
final int EAST = 3;
final int WEST = 4;
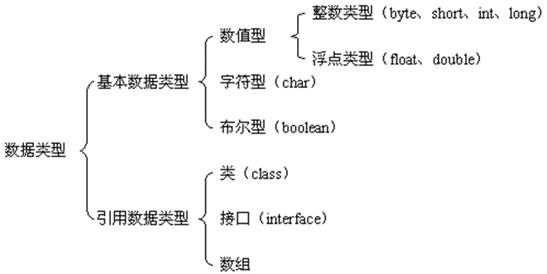
5). 数据类型
- 分为基本数据类型(Primitive Type)
- 引用数据类型(Reference Data Type)
6). 赋值
“=” 是个赋值运算符,都是把右侧的值赋予左侧的变量。
public class Assignment{
public static void main(String[] args){
int a=1;
int b=1,c=1;
int d=a=b=c=2;
System.out.println("a="+a+" b="+b +" c="+c+" d="+d);
}
}
7). 注释
程序中的注释是程序设计者与程序阅读者之间沟通的手段,是写给程序员看的代码。通常情况下编译器会忽略注释部分,不做语法检查。
Java中的注释有三种:
- // 注释一行
- /* 注释若干行 */
- /**注释若干行,并写入 javadoc 文档 */
8). 运算符
算术运算符
+(加), –(减), *(乘), /(除), %(求余), ++(递增), –-(递减)
逻辑运算符
逻辑运算符只对布尔型操作数进行运算并返回一个布尔型数据。
6个逻辑运算符:&& , || ,& , | ,!, ^
位运算符
位运算符是对整数操作数以二进制的每一位进行操作,返回结果也是一个整数。
逻辑位运算符:按位取反~, 按位与&, 按位或 |, 按位异或 ^,移位运算符有 左移<< , 右移>>
赋值运算符
运算符 举例 等效表达式
+= a += b a = a+b
-= a -= b a = a-b
*= a *= b a = a*b
/= a /= b a = a/b
%= a %= b a = a%b
&= a &= b a = a&b
|= a |= b a = a|b
^= a ^= b a = a^b
<<= a <<= b a = a<<b
>>= a >>= b a = a>>b
>>>= a >>>= b a = a>>>b
关系运算符
运算符 功能 举例 运算结果 可运算类型
> 大于 'a'>'b' false 整数、浮点数、字符
< 小于 2<3.0 true 整数、浮点数、字符
== 等于 'x'==88 true 任意
!= 不等于 true!=true false 任意
>= 大于等于 6.6>=8.9 false 整数、浮点数、字符
<= 小于等于 'M'<=88 true 整数、浮点数、字符
相等性运算符
== 和 != 这两个关系运算符比较的是两个相似事物的是否相等。
对于整数和浮点数之间的相等性如果值相等就相等。
对于引用类型的变量之间,看他们是否引用了同一个对象,引用地址相等就相等。
instanceof
instanceof 运算符只值能用于比较对象引用变量,可以检查对象是否是某种类型。这里的类型是指类、接口类型数组
三目运算符
对于条件表达式b?x:y,先计算条件b,然后进行判断。如果b的值为true,计算x的值,运算结果为x的值;否则,计算y的值,运算结果为y的值。
运算符优先级
- () [] .
- ! +(正) -(负) ~ ++ –
- * / %
- +(加) -(减)
- << >> >>>
- < <= > >= instanceof
- == !=
- &(按位与)
- ^
- |
- &&
- ||
- ?:
- = += -= *= /= %= &= |= ^= ~= <<= >>= >>>=
9). 流程控制
if-else分支控制语句
if后的小括号不能省略,括号里表达式的值最终必须返回的是布尔值
如果条件体内只有一条语句需要执行,那么if后面的大括号可以省略
对于给定的if,else语句是可选的,else if 语句也是可选的
else和else if同时出现时,else必须出现在else if之后
如果有多条else if语句同时出现,那么如果有一条else if语句的表达式测试成功,那么会忽略掉其他所有else if和else分支。
如果出现多个if,只有一个else的情形,else子句归属于最内层的if语句
if(){}
if(){}else{}
if(){}else if(){}
if(){}else if(){}else{}
switch分支控制语句
switch表达式必须能被求值成char byte short int 或 enum
case常量必须是编译时解析的常量
switch(){case}
switch(){case,default}
switch(){case,break,default}
while循环
当条件为真时执行while循环,一直到条件为假时再退出循环体。while括号后的表达式,要求和if语句一样是一个布尔值,判断是否进入循环的条件。
do-while循环
进行循环之前,先执行一次代码。其他操作同while循环。
for循环
当知道可以循环多少次时,是使用for循环的最佳时机。
for循环的三个部分任意部分都可以省略,最简单的for循环就是这样的 for(;;){ }
中间的条件表达式必须返回一个布尔值,用来作为是否进行循环的判断依据
初始化语句可以由初始化多个变量,多个变量之间可以用逗号隔开,在for循环中声明的变量作用范围就只在for循环内部
最后的迭代语句一般是i++,j++ 这样的表达式。
for-each循环
for-each循环又叫增强型for循环,它用来遍历数组和集合中的元素
for(type var : arr) {}
跳出循环 break 、continue
break:用来终止循环或switch语句
continue:用来终止循环的当前迭代
当存在多层循环时,不带标签的break和continue只能终止离它所在的最内层循环
10). 面向对象
类和对象的概念
人类自古就喜欢听故事,也喜欢写故事,我们从小也被要求写作文,为了帮助你写作文。老师还总结了一些规律,譬如记叙文六要素:时间、地点、人物、起因、经过、结果。 有了这样指导性的东西,我们写作文的时候就简单了许多。
面向对象程序语言的核心思想就是把一个事物的状态和行为封装起来作为一个整体看待。类描述的就是对象知道知道什么和执行什么。
举例一架飞机:
以顾客角度看飞机,名字波音777,座位数380人,飞行速度940公里每小时,行为飞行从A地送到B地。
以航空公司角度看飞机,名字波音777,资产编号HNHK20100321,购买价格18.7亿人民币,行为能赚钱。
我们从不同角度去看待和抽象同一架飞机它的状态和行为不相同。
类和对象的关系
类是对象的骨架,对象是根据骨架建造出来的实例。
举例我们设计一个模拟WOW的格斗游戏
人和怪兽战斗,战斗需要武器。那么圣骑士就是个"类",人类圣骑士"锦马超"就是一个对象。双手剑件是个类,那么拿在“锦马超”手里的“霜之哀伤”就是一个对象。
举例我们要建立一个全班同学的通讯录
设计一个通讯录的格式,包括姓名、性别、手机号、QQ号、宿舍号。然后我们按照一定的格式印出来,交由每个同学填写,那么每个同学填写的那一份就叫对象,我们填写的通讯录格式本身就是类。
定义类创建对象
定义一个类的步骤是:定义类名,编写类的属性(状态),编写类的方法(行为)
public class Dog {
private int size;// 定义了狗的大小的属性
public void setSize(int size) {// 定义设置大小的方法
if (size > 0 && size < 10) {
this.size = size;
} else {
size = 1;
}
}
public int getSize() {// 定义获取大小的方法
return size;
}
public void bark(){ // 定义狗叫的方法
if(size<5){
System.out.println("汪汪汪!");
}else{
System.out.println("嗷!嗷!");
}
}
public static void main(String[] args) {//定义main方法
Dog xiaoHang = new Dog();//创建了名字叫小黄的狗对象
xiaoHang.setSize(3);//设置它的大小属性
xiaoHang.bark(); //调用它的叫方法
Dog daHang = new Dog();//创建了名字叫大黄的狗对象
daHang.setSize(7); //设置它的大小属性
daHang.bark();//调用它的叫方法
}
}
面向对象的三大特性(封装、继承、多态)
封装(encapsulation):就是把属性私有化,提供公共方法访问私有对象。 有两层意思,第一隐藏数据,第二把数据和对数据操作的方法绑定。
- 1 修改属性的可见性来限制对属性的访问。
- 2 为每个属性创建一对赋值方法和取值方法,用于对这些属性的访问。
- 3 在赋值和取值方法中,加入对属性的存取限制。
封装的优点:
- 1 隐藏类的实现细节;
- 2 可加入控制逻辑,限制对属性的不合理操作;
- 3 便于修改,增强代码的可维护性;
继承(inheritance):同类事物之间有它的共同性也有各自的独特性,把共同的部分抽离出来作为父类,保留自己特有的属性和方法做为子类。通过继承让子类也具有父类的属性和方法。
举例:马儿都有四条腿,马儿都有会跑
这些共同性抽象出来就成了马类;其中有一些马是白色的马,还有一些是黑色的马,就成了白马类和黑马类。那么白马类和马类之间的关系就是继承关系。它们是父子关系,马类是父类、白马类是子类。
继承的优点:
简化了人们对事物的认识和描述,清晰的体现了相关类间的层次关系。
功能抽象、继承促进了代码复用、继承也带来了多态性。
多态(polymorphism):多态就是“一种定义、多种实现” 。
当父类对象引用变量引用子类对象时,被引用对象的类型决定了调用的成员方法,但是这个被调用的方法必须是在超类中定义过的,也就是说被子类覆盖的方法。
public abstract class Vehicle {
abstract void go(Address address);
}
public class Car extends Vehicle{
@Override public void go(Address address){
System.out.println("Car to " + address.getName());
}
}
public class Plane extends Vehicle{
@Override void go(Address address) {
System.out.println("Plane to " + address.getName());
}
}
//多态,父类引用指向子类对象,实际传过来的是抽象类Vehicle的子类,然后编译器会根据具体实现类,来找实现方法。
public void drive(Vehicle v){
v.go(new Address("杭州(abstract)"));
}
多态的优点
- 可替换性。多态对已存在的代码具有可替换性。
- 可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。
- 接口性。多态是超类通过方法签名,向子类提供了一个共同接口,由子类来完善或者覆盖它而实现的
- 灵活性。它在应用中体现了灵活多样的操作,提高了使用效率。
- 简化性。多态简化了对应用软件的代码编写和修改过程,尤其在处理大量对象的运算和操作时,这个特点尤为突出和重要。值得注意的是,多态并不能够解决提高执行速度的问题,因为它基于动态装载和地址引用,或称动态绑定。
11). 包:类的组织和管理方式
包的用途有以下三种:
- 将功能相近的类放在同一个包里,方便使用和查找
- 类名相同的文件可以放在不同的包里而不会产生冲突
- 可以依据包设定访问权限
12). 方法:类或对象的行为
方法的声明
修饰符,可选,用于指定谁有权限访问此方法。
返回值类型,必选,用于指定该方法的返回值数据类型;如果该方法没有返回值,则要用关键字 void 进行标示。方法的返回值只能有一个。
参数列表,可以有0到多个,多个参数之间要用逗号隔开,参数的写法形如:String[] args, int age 这样。
方法名,必选,这个……,好吧命名规则是方法名和变量名的首字母要小写,别丢我人,弄个大写方法名出来。
方法体,可选,这个……,
大括号,大括号不写的方法叫抽象方法。
public void go(int size) throws Exception;方法重写override
当子类继承父类时,如果子类方法的签名和父类方法的签名相同时,子类的方法就覆盖了父类的方法,我们称之为重写。
举例:动物会喝水,但是猫喝水和人喝水的具体行为就不同。
重写规则:
参数列表必须与重写的方法的参数列表完全匹配(方法签名相同)。如果不匹配,你得到的将是方法重载。
返回类型必须与超类中被重写方法中原先声明的返回类型或其子类型相同。
访问级别的限制性可以比被重写方法弱,但是访问级别的限制性一定不能比被重写方法的更严格。
仅当实例方法被子类继承时,它们才能被重写。子类和超类在同一个包内时,子类可以重写未标示为private和final的任何超类方法。不同包的子类只能重写标示为public或protected的非final方法。
无论父类的方法是否抛出某种运行时异常,子类的重写方法都可以抛出任意类型的运行时异常。
重写方法一定不能抛出比被重写方法声明的检验异常更新或更广的检验异常,可以抛出更少或更有限的异常。
不能重写标示为final的方法。
不能重写标示为static的方法。
如果方法不能被继承,那么方法不能被重写。
方法重载overload
在Java 中允许类定义中多个方法的方法名相同,只要它们的参数声明不同即可,这种方法就被称为重载(overloaded)。如狗的叫声,参数不同叫声也不同。
重载规则:
重载方法必须改变方法参数列表
重载方法可以改变返回类型
重载方法可以改变访问修饰符
重载方法可以声明新的或更广的检验异常
方法能够在同一个类或者一个子类中被重载
13) main方法:
main()方法是Java应用程序的入口方法。这个方法和其他的方法有很大的不同,比如方法的名字必须是main,方法必须是public static void 类型的,方法必须接收一个字符串数组的参数等等。
public staitc void main(String[] args){}14) 构造函数
在Java中,对象是构造出来的,用new关键字来标示这个创建的过程。
构造函数或者说构造方法不是方法。它们之间的三大区别:
构造函数没有返回值
构造函数名称和类名相同
构造函数不能用final,static,abstract
15). 接口
为什么要有接口
Java中只支持单继承,只能有一个父类。为了提供类似多重继承的功能,Java提供了接口的功能。
接口的几个规则
接口名用 interface 修饰, 相对应的 类名用 class修饰
接口里定义的方法都是抽象方法,可以用abstract修饰,当然也可以不用它修饰
接口只能被实现 ( implements )
可以用抽象类实现接口,也就是说虽然实现了,但是没有真正写接口的任何方法,它把责任推给了抽象类的子类
普通类实现接口,则必须按照接口的契约,实现接口所定义的所有方法。
接口可以继承接口,或者说一个接口可以是另一个接口的父类
一个接口可以继承多个父类,也就是说一个接口之间可以多重继承。
16). 抽象类和抽象方法
用abstract 修饰的类定义,我们称之为抽象类,抽象类不能被实例化。
用abstract 修饰的方法,我们称之为抽象方法,抽象方法不能有方法体。
面向对象中,所有的对象都是某一个类的实例,但是并不是每个类都可以实例化成一个对象。如果一个类中没有足够的信息来描绘一个具体的对象,那么这个类就不能被实例化,我们称之为抽象类。
抽象类实际上是定义了一个标准和规范,等着他的子类们去实现,譬如动物这个抽象类里定义了一个发出声音的抽象方法,它就定义了一个规则,那就是谁要是动物类的子类,谁就要去实现这个抽象方法。
17). 初始化块
我们已经知道在类中有两个位置可以放置执行操作的代码,这两个位置是方法和构造函数。初始化块是第三个可以放置执行操作的位置。当首次加载类(静态初始化块)或者创建一个实例(实例初始化块)时,就会运行初始化块。
初始化块的语法相当简单,它没有名称,没有参数,也没有返回值,只有一个大括号,用static 修饰的初始化块就要静态初始化块。
静态初始化块在首次加载类时会运行一次。
实例初始化块在每次创建对象时会运行一次。
实例初始化块在构造函数的super()调用之后运行。
初始化块之间的运行顺序取决于他们在类文件中出现的顺序,出现在前面的先执行。
初始化块从书写惯例上应该写在靠近类文件的顶部,构造函数附近的某个位置。
18). 内部类
普通内部类
所谓内部类,就是嵌套在类中的类。被嵌套的类叫外部类。
public class Outer {
public class Inner{
}
}
内部类就像一个实例成员一样存在于外部类中。
内部类可以访问外部类的所有成员就想访问自己的成员一样没有限制。
内部类中的this指的是内部类的实例对象本身,如果要用外部类的实例对象就可以用类名.this的方式获得。
内部类对象中不能有静态成员,原因很简单,内部类的实例对象是外部类实例对象的一个成员。
内部类的创建方法:
在外部类的内部,可以用 Inner inner = new Inner(); 方法直接创建
在外部类外部,必须先创建外部类实例,然后再创建内部类实例。
Outer outer = new Outer();
Inner inner = outer.new Inner();
静态内部类
和普通的类一样,内部类也可以有静态的。不过和非静态内部类相比,区别就在于静态内部类没有了指向外部的引用。除此之外,在任何非静态内部类中,都不能有静态数据,静态方法或者又一个静态内部类(内部类的嵌套可以不止一层)。不过静态内部类中却可以拥有这一切。这也算是两者的第二个区别吧。
public class Outer {
public static class Inner{
}
}
局部内部类
们也可以把类定义在方法内部,这时候我们称这个类叫局部内部类。
局部内部类的地位和方法内的局部变量的位置类似,因此不能修饰局部变量的修饰符也不能修饰局部内部类,譬如public、private、protected、static、transient等
局部内部类只能在声明的方法内是可见的,因此定义局部内部类之后,想用的话就要在方法内直接实例化,记住这里顺序不能反了,一定是要先声明后使用,否则编译器会说找不到。
局部内部类不能访问定义它的方法内的局部变量,除非这个变量被定义为final 。
interface World {
String sayHello();
}
public class Outer {
public class Inner {
public World hello() {
class World2 implements World {
private String name;
@Override
public String sayHello() {
return "hello " + name;
}
}
return new World2();
}
}
}
匿名内部类
当我们把内部类的定义和声明写到一起时,就不用给这个类起个类名而是直接使用了,这种形式的内部类根本就没有类名,因此我们叫它匿名内部类。
匿名内部类可以是某个类的继承子类也可以是某个接口的实现类。
interface World {
String sayHello();
}
public class Outer {
public class Inner {
public World hello() {
return new World() {
private String name;
@Override
public String sayHello() {
return "hello " + name;
}
};
}
}
}
19). 数组
数组是有序数据的集合,数组中的每个元素具有相同的数组名和下标来唯一地确定数组中的元素。
一维数据
int[] number1;
int number2[];
Java中使用关键字new创建数组对象,格式为:
int[] number1 = new int[5];
多维数据
String[][] s1; //二维数组
String[][][][] s2; //四维数组
String[] s3[]; //怪异写法的二维数组
构建数组 | 创建数组 | 实例化数组
构建数组意味着在堆上创建数组对象(所有的对象都存储在堆上,堆是一种内存存储结构,既然要存储就设计空间分配问题,因此此时需要指定数组的大小)。而此时虽然有了数组对象,但数组对象里还没有值。
int[] scores; //声明数组
scores = new int[34]; //创建数组
int[] i = new int[22]; //声明并创建数组
声明数组时如果没写长度,只是定义了一个变量,只没有分配空间。
int[][] xy= new int[2][3]; //声明并创建二维数组
int[][] mn= new int[2][]; //声明并创建二维数组,只创建第一级数组也是可以的。
初始化数组 | 给数组赋值
初始化数组就是把内容放在数组中。数组中的内容就是数组的元素。他们可以是基本数据类型也可以是引用数据类型。如同引用类型的变量中保存的是指向对象的引用而不是对象本身一样。数组中保存的也是对象的引用而不是对象本身。
Pig[] pigs = new Pig[3]; //声明并创建猪数组
pigs[0] = new Pig(); //给每一个元素赋值,创建了三个猪对象,此时数组里才真正有了对象
pigs[1] = new Pig(); //数组用下标来赋值和访问,下标写在[]中,数组下标最大是声明数量减1
pigs[2] = new Pig();
int[] numbers;
numbers=new int[]{0,1,2,3,4,5,6,7,8,9}; //创建匿名数组并赋值
int[][] xy= new int[][]{{2,3},{4,5},{5,6}}; //创建二维匿名数组并赋值
20). 异常
异常及异常的分类
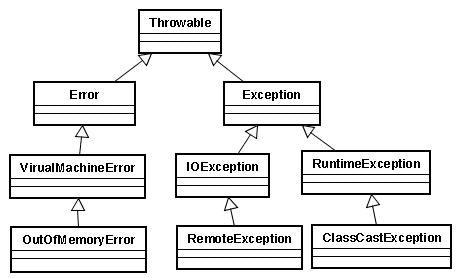
异常是指在程序中出现的异常状况,在Java中异常被抽象成一个叫做Throwable的类。
其中如果程序出错并不是由程序本身引起的,而是硬件等其他原因引起的,我们称之为Error,一般情况下Error一旦产生,对程序来说都是致命的错误,程序本身无能为力,所以我们可以不对Error作出任何处理和响应。
异常如果是由程序引起的我们称之为Exception,Exception又分两种,我们把运行时才会出现的异常叫做 RuntimeException,RuntimeException我们不好在程序编写阶段加以事先处理,而其他异常则可以在程序编写和编译阶段加以事先检查和处理,我们把这种异常叫做检验异常。
程序只需要捕捉和处理检验异常
相应的我们把除检验异常(可检查异常)之外的异常称之为非检验异常,包括Error和RuntimeException ,非检验异常可以捕捉也可以不捕捉,更多的时候我们不捕捉,因为捕捉了我们也没办法处理,譬如程序运行时发生了一个VirtualMachineError异常,虚拟机都出错了,作为运行在虚拟机内的程序又有什么办法处理呢?
异常的处理
try{}catch(){}finally{}
异常处理的几条规则
try用于定义可能发生异常的代码段,这个代码块被称为监视区域,所有可能出现检验异常的代码写在这里。
catch代码段紧跟在try代码段后面,中间不能有任何其他代码。
try后面可以没catch代码段,这实际上是放弃了捕捉异常,把异常捕捉的任务交给调用栈的上一层代码。
try后面可以有一个或者多个catch代码段,如果有多个catch代码段那么程序只会进入其中某一个catch。
catch捕捉的多个异常之间有继承关系的话,要先捕捉子类后捕捉父类。
finally代码段可以要也可以不要。
如果try代码段没有产生异常,那么finally代码段会被立即执行,如果产生了异常,那么finally代码段会在catch代码段执行完成后立即执行。
可以只有try和finally没有catch。
5. JDK基本包介绍
JDK(Java Development Kit)是Sun Microsystems针对Java开发员的产品。自从Java推出以来,JDK已经成为使用最广泛的Java SDK。JDK 是整个Java的核心,包括了Java运行环境、Java工具和Java基础类库。JDK是学好Java的第一步。
1). 基础包
- java.lang: 这个是系统的基础类,比如String等都是这里面的,这个包是唯一一个可以不用引入(import)就可以使用的包
- java.io: 这里面是所有输入输出有关的类,比如文件操作等
- java.nio;为了完善io包中的功能,提高io包中性能而写的一个新包 ,例如NIO非堵塞应用
- java.net: 这里面是与网络有关的类,比如URL,URLConnection等。
- java.util: 这个是系统辅助类,特别是集合类Collection,List,Map等。
- java.sql: 这个是数据库操作的类,Connection, Statement,ResultSet等
- javax.servlet: 这个是JSP,Servlet等使用到的类
2). 字符串(java.lang.String)
程序开发的工作中80%的操作都和字符串有关。
public final class String implements java.io.Serializable, Comparable, CharSequence{} String永远不可能有子类,它的实例也是无法改变的。
创建字符串对象
String s1 = new String("Milestone");
String s2 = "String";
第一种是常规写法,创建一个对象当然就可以用new跟上个构造函数完成。第二种写法,最常用,效率也高。
字符串操作中的加号
我们经常要把两个或者更多的字符串拼接成一个字符串,除了普通的连接字符串的方法以外,Java语言专门为String提供了一个字符串连接符号“+”
String s3 = "a"+"b";字符串中的常用方法
- charAt() 返回位于指定索引处的字符串
- concat() 将一个字符串追加到另一个字符串的末尾
- equalseIgnoseCase() 判断两个字符串的相等性,忽略大小写
- length() 返回字符串中的字符个数
- replace() 用新字符代替指定的字符
- substring() 返回字符串的一部分
- toLowerCase() 将字符串中的大写字符转换成小写字符返回
- toString() 返回字符串的值
- toUpperCase() 将字符串中的小写字符转换成大写字符返回
- trim() 删除字符串前后的空格
- splite() 将字符串按照指定的规则拆分成字符串数组
3). 集合(java.util.Collection)
colection 集合,用来表示任何一种数据结构 Collection 集合接口,指的是 java.util.Collection接口,是 Set、List 和 Queue 接口的超类接口 Collections 集合工具类,指的是 java.util.Collections 类。
集合类和集合接口
Collection , Set , SortedSet , List , Map , SortedMap , Queue , NavigableSet , NavigableMap, Iterator, HashMap , Hashtable ,TreeMap , LinkedHashMap , HashSet , LinkedHashSet ,TreeSet , ArrayList , Vector , LinkedList , PriorityQueuee , Collections , Arrays
- List 关注事物的索引列表
- Set 关注事物的唯一性
- Queue 关注事物被处理时的顺序
- Map 关注事物的映射和键值的唯一性
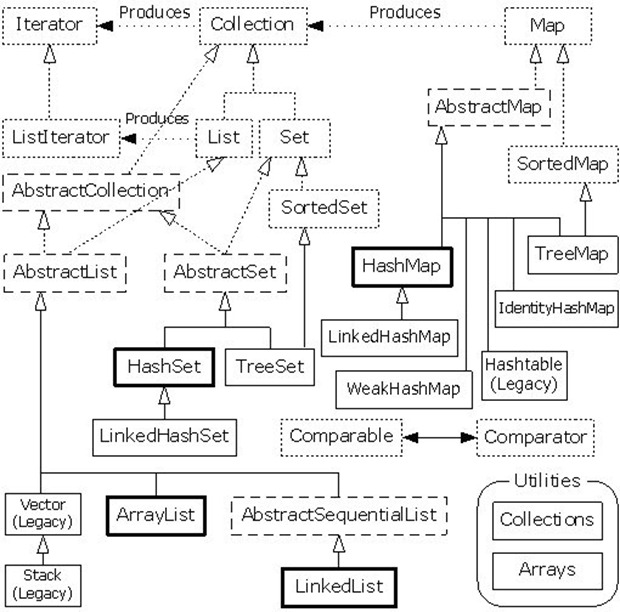
上图中加粗线的ArrayList 和 HashMap 是我们重点讲解的对象。下面这张图看起来层级结构更清晰些。
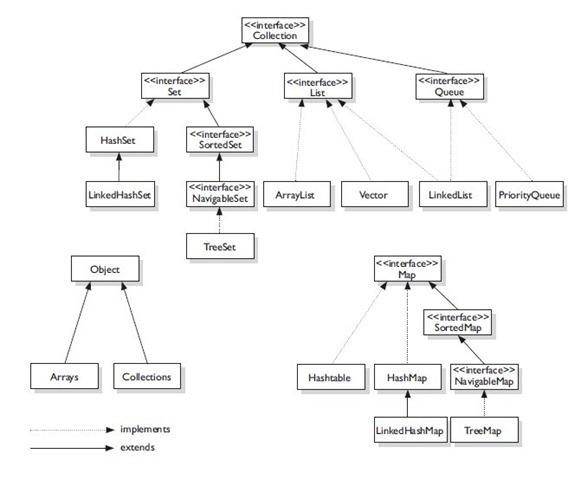
Collection 接口
Collection接口是 Set 、List 和 Queue 接口的父接口,提供了多数集合常用的方法声明,包括 add()、remove()、contains() 、size() 、iterator() 等。
- add(E e) 将指定对象添加到集合中
- remove(Object o) 将指定的对象从集合中移除,移除成功返回true,不成功返回false
- contains(Object o) 查看该集合中是否包含指定的对象,包含返回true,不包含返回flase
- size() 返回集合中存放的对象的个数。返回值为int
- clear() 移除该集合中的所有对象,清空该集合。
- iterator() 返回一个包含所有对象的iterator对象,用来循环遍历
- toArray() 返回一个包含所有对象的数组,类型是Object
- toArray(T[] t) 返回一个包含所有对象的指定类型的数组
List接口
List 关心的是索引,与其他集合相比,List特有的就是和索引相关的一些方法:get(int index) 、 add(int index,Object o) 、 indexOf(Object o) 。
ArrayList 可以将它理解成一个可增长的数组,它提供快速迭代和快速随机访问的能力。
LinkedList 中的元素之间是双链接的,当需要快速插入和删除时LinkedList成为List中的不二选择。
Vector 是ArrayList的线程安全版本,性能比ArrayList要低,现在已经很少使用
Set接口
Set关心唯一性,它不允许重复。
HashSet 当不希望集合中有重复值,并且不关心元素之间的顺序时可以使用此类。
LinkedHashset 当不希望集合中有重复值,并且希望按照元素的插入顺序进行迭代遍历时可采用此类。
TreeSet 当不希望集合中有重复值,并且希望按照元素的自然顺序进行排序时可以采用此类。(自然顺序意思是某种和插入顺序无关,而是和元素本身的内容和特质有关的排序方式,譬如“abc”排在“abd”前面。)
Queue接口
Queue用于保存将要执行的任务列表。
LinkedList 同样实现了Queue接口,可以实现先进先出的队列。
PriorityQueue 用来创建自然排序的优先级队列。
Map接口
Map关心的是唯一的标识符。他将唯一的键映射到某个元素。当然键和值都是对象。
HashMap 当需要键值对表示,又不关心顺序时可采用HashMap。
Hashtable 注意Hashtable中的t是小写的,它是HashMap的线程安全版本,现在已经很少使用。
LinkedHashMap 当需要键值对,并且关心插入顺序时可采用它。
TreeMap 当需要键值对,并关心元素的自然排序时可采用它。
ArrayList的使用
ArrayList是一个可变长的数组实现,读取效率很高,是最常用的集合类型。
在Java5版本之前我们使用:
List list = new ArrayList();在Java5版本之后,我们使用带泛型的写法:
List<String> list = new ArrayList<String>();上面的代码定义了一个只允许保存字符串的列表,尖括号括住的类型就是参数类型,也成泛型。带泛型的写法给了我们一个类型安全的集合。
Map的接口
Map接口的常用方法如下表所示:
- put(K key, V value) 向集合中添加指定的键值对
- putAll(Map t) 把一个Map中的所有键值对添加到该集合
- containsKey(Object key) 如果包含该键,则返回true
- containsValue(Object value) 如果包含该值,则返回true
- get(Object key) 根据键,返回相应的值对象
- keySet() 将该集合中的所有键以Set集合形式返回
- values() 将该集合中所有的值以Collection形式返回
- remove(Object key) 如果存在指定的键,则移除该键值对,返回键所对应的值,如果不存在则返回null
- clear() 移除Map中的所有键值对,或者说就是清空集合
- isEmpty() 查看Map中是否存在键值对
- size() 查看集合中包含键值对的个数,返回int类型
因为Map中的键必须是唯一的,所以虽然键可以是null,只能由一个键是null,而Map中的值可没有这种限制,值为null的情况经常出现,因此get(Object key)方法返回null,有两种情况一种是确实不存在该键值对,二是该键对应的值对象为null。为了确保某Map中确实有某个键,应该使用的方法是 containsKey(Object key) 。
HashMap使用
HashMap是最常用的Map集合,它的键值对在存储时要根据键的哈希码来确定值放在哪里。
在Java5版本之前我们使用:
Map map = new HashMap();在Java5版本之后,我们使用带泛型的写法:
Map<String,Integer> map = new HashMap<String,Interger>();4). IO(java.io)
Java 的 I/O 操作类在包 java.io 下,大概有将近 80 个类,但是这些类大概可以分成四组,分别是:
- 基于字节操作的 I/O 接口:InputStream 和 OutputStream
- 基于字符操作的 I/O 接口:Writer 和 Reader
- 基于磁盘操作的 I/O 接口:File
- 基于网络操作的 I/O 接口:Socket
前两组主要是根据传输数据的数据格式,后两组主要是根据传输数据的方式,虽然 Socket 类并不在 java.io 包下,但是我仍然把它们划分在一起,因为我个人认为 I/O 的核心问题要么是数据格式影响 I/O 操作,要么是传输方式影响 I/O 操作,也就是将什么样的数据写到什么地方的问题,I/O 只是人与机器或者机器与机器交互的手段,除了在它们能够完成这个交互功能外,我们关注的就是如何提高它的运行效率了,而数据格式和传输方式是影响效率最关键的因素了。
输入
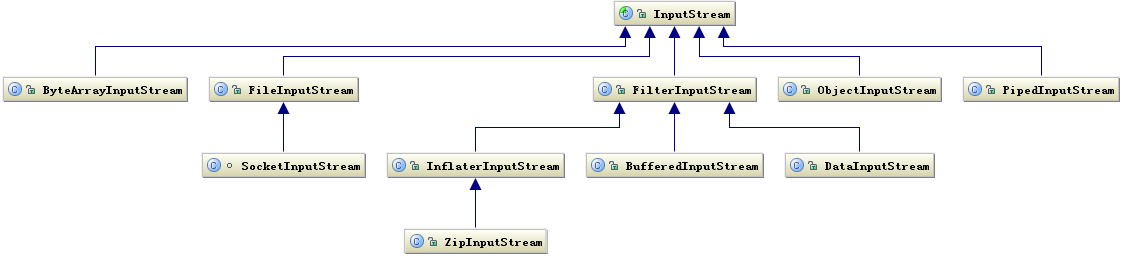
输出

同步与异步
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列。要么成功都成功,失败都失败,两个任务的状态可以保持一致。而异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。我们可以用打电话和发短信来很好的比喻同步与异步操作。
阻塞与非阻塞
阻塞与非阻塞主要是从 CPU 的消耗上来说的,阻塞就是 CPU 停下来等待一个慢的操作完成 CPU 才接着完成其它的事。非阻塞就是在这个慢的操作在执行时 CPU 去干其它别的事,等这个慢的操作完成时,CPU 再接着完成后续的操作。虽然表面上看非阻塞的方式可以明显的提高 CPU 的利用率,但是也带了另外一种后果就是系统的线程切换增加。增加的 CPU 使用时间能不能补偿系统的切换成本需要好好评估。
两种的方式的组合
分别是:同步阻塞、同步非阻塞、异步阻塞、异步非阻塞,这四种方式都对 I/O 性能有影响。下面给出分析,并有一些常用的设计用例参考。
- 同步阻塞:最常用的一种用法,使用也是最简单的,但是 I/O 性能一般很差,CPU 大部分在空闲状态。
- 同步非阻塞:提升 I/O 性能的常用手段,就是将 I/O 的阻塞改成非阻塞方式,尤其在网络 I/O 是长连接,同时传输数据也不是很多的情况下,提升性能非常有效。这种方式通常能提升 I/O 性能,但是会增加 CPU 消耗,要考虑增加的 I/O 性能能不能补偿 CPU 的消耗,也就是系统的瓶颈是在 I/O 还是在 CPU 上。
- 异步阻塞:这种方式在分布式数据库中经常用到,例如在网一个分布式数据库中写一条记录,通常会有一份是同步阻塞的记录,而还有两至三份是备份记录会写到其它机器上,这些备份记录通常都是采用异步阻塞的方式写 I/O。异步阻塞对网络 I/O 能够提升效率,尤其像上面这种同时写多份相同数据的情况。
- 异步非阻塞:这种组合方式用起来比较复杂,只有在一些非常复杂的分布式情况下使用,像集群之间的消息同步机制一般用这种 I/O 组合方式。如 Cassandra 的 Gossip 通信机制就是采用异步非阻塞的方式。它适合同时要传多份相同的数据到集群中不同的机器,同时数据的传输量虽然不大,但是却非常频繁。这种网络 I/O 用这个方式性能能达到最高。
6. JAVA项目(Ant, Maven)
ANT
Apache Ant,是一个将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具,大多用于Java环境中的软件开发。由Apache软件基金会所提供。默认情况下,它的buildfile(XML文件)名为build.xml。每一个buildfile含有一个
http://ant.apache.org/
Maven
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。
http://maven.apache.org
参考文章列表
http://android.yaohuiji.com/
http://zh.wikipedia.org/wiki/
http://baike.baidu.com/
转载请注明出处:
http://blog.fens.me/rhadoop-java-basic/

本来放弃了看java,看博主的blog,精神劲又来了,博主太牛了,还这么乐于分享,只为赞而来。
学Java需要长期努力和坚持,等熬了最苦日子,离成功就不远了。
collection 虽然是个概括,但有醍壶灌顶之效。继续学习。
加油!
//有笔误 没有使用带泛型的写法
在Java5版本之后,我们使用带泛型的写法:
List list = new ArrayList();
多谢提醒,已经修改,没有处理<的HTML转义
总结归纳的真好!
extentds: 类继承 (extends)
已修改,多谢!!:-)