RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析。Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来替代Java的MapReduce实现。有了RHadoop可以让广大的R语言爱好者,有更强大的工具处理大数据1G, 10G, 100G, TB, PB。 由于大数据所带来的单机性能问题,可能会一去不复返了。
RHadoop实践是一套系列文章,主要包括”Hadoop环境搭建”,”RHadoop安装与使用”,”R实现MapReduce的协同过滤算法”,”HBase和rhbase的安装与使用”。对于单独的R语言爱好者,Java爱好者,或者Hadoop爱好者来说,同时具备三种语言知识并不容 易。此文虽为入门文章,但R,Java,Hadoop基础知识还是需要大家提前掌握。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/rhadoop-rmr2-pipemapred/

前言
一行错误难倒一片同学,今天在准备 统计之都沙龙 的时候,我也遇到相同的错误。就让我来解决一下,在使用rhadoop的rmr2中,经常会遇到的一个错误。
按照 RHadoop实践系列之二:RHadoop安装与使用 rmr2中实例所演示。
> small.ints = to.dfs(1:10)
> mapreduce(input = small.ints, map = function(k, v) cbind(v, v^2))
> from.dfs("/tmp/RtmpWnzxl4/file5deb791fcbd5")
文章目录:
- rmr2运行错误日志
- 定位错误到hadoop日志
- 从hadoop入手找解决办法 — 失败
- 从rhadoop入手找解决办法 — 成功
1. rmr2运行错误日志
R执行的错误日志如下面:
packageJobJar: [/tmp/Rtmpdf7egm/rmr-local-env3cbb70983, /tmp/Rtmpdf7egm/rmr-global-env3cbb654b85fe, /tmp/ Rtmpdf7egm/rmr-streaming-map3cbba213f2e, /home/conan/hadoop/tmp/hadoop-unjar1697638502297829404/] [] /tmp /streamjob4620072667602885650.jar tmpDir=null
13/06/23 10:44:25 INFO mapred.FileInputFormat: Total input paths to process : 1
13/06/23 10:44:25 INFO streaming.StreamJob: getLocalDirs(): [/home/conan/hadoop/tmp/mapred/local]
13/06/23 10:44:25 INFO streaming.StreamJob: Running job: job_201306231032_0001
13/06/23 10:44:25 INFO streaming.StreamJob: To kill this job, run:
13/06/23 10:44:25 INFO streaming.StreamJob: /home/conan/hadoop/hadoop-1.0.3/libexec/../bin/hadoop job -D mapred.job.tracker=hdfs://master:9001 -kill job_201306231032_0001
13/06/23 10:44:25 INFO streaming.StreamJob: Tracking URL: http://master:50030/jobdetails.jsp?jobid=job_20 1306231032_0001
13/06/23 10:44:26 INFO streaming.StreamJob: map 0% reduce 0%
13/06/23 10:45:04 INFO streaming.StreamJob: map 100% reduce 100%
13/06/23 10:45:04 INFO streaming.StreamJob: To kill this job, run:
13/06/23 10:45:04 INFO streaming.StreamJob: /home/conan/hadoop/hadoop-1.0.3/libexec/../bin/hadoop job -Dmapred.job.tracker=hdfs://master:9001 -kill job_201306231032_0001
13/06/23 10:45:04 INFO streaming.StreamJob: Tracking URL: http://master:50030/jobdetails.jsp?jobid=job_201306231032_0001
13/06/23 10:45:04 ERROR streaming.StreamJob: Job not successful. Error: # of failed Map Tasks exceeded allowed limit. FailedCount: 1. LastFailedTask: task_201306231032_0001_m_000000
13/06/23 10:45:04 INFO streaming.StreamJob: killJob...
Streaming Command Failed!
Error in mr(map = map, reduce = reduce, combine = combine, vectorized.reduce, :
hadoop streaming failed with error code 1
我们光看上面的日志,根本发现不了hadoop的实际错误是什么!
2. 定位错误到hadoop日志
接下来需要定位到实际错误的位置。为了方便查询日志,我们打开jobtracker的控制台:http://192.168.1.210:50030/jobtracker.jsp
并找到刚才出现错误的, 日志中有提示的网页位置, Tracking URL: http://master:50030/jobdetails.jsp?jobid=job_201306231032_0001
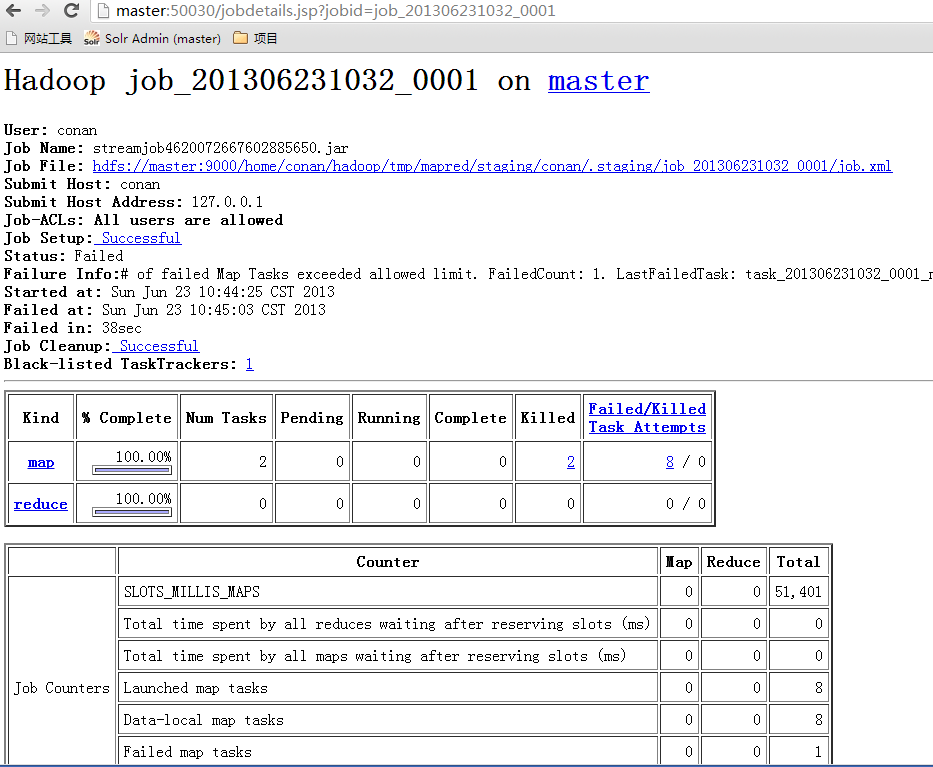
查看map的错误,现在已经明确有了错误定义。
Running a job using hadoop streaming and mrjob: PipeMapRed.waitOutputThreads(): subprocess failed with code 1
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1 at
org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:362) at
org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:576) at
org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:135) at
org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:57) at
org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:36) at
org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:436) at
org.apache.hadoop.mapred.MapTask.run(MapTask.java:372) at
org.apache.hadoop.mapred.Child$4.run(Child.java:255) at
java.security.AccessController.doPrivileged(Native Method) at
javax.security.auth.Subject.doAs(Subject.java:396) at
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121) at
org.apache.hadoop.mapred.Child.main(Child.java:249)
3. 从hadoop入手找解决办法 — 失败
查看hadoop错误列表:code 1的错误
“OS error code 1: Operation not permitted”"OS error code 2: No such file or directory”
我来分析一下:hadoop和R的用户和用户组
启动hadoop, 用户conan, 用户组conan
启动R, 用户conan, 用户组conan
既然都是相同权限的用户,怎么会有权限的问题呢。
再找另一个hadoop环境做测试,用户使用root,没有错误如文章所示,RHadoop实践系列之二:RHadoop安装与使用
好了,这样问题已经很具体了,我们去网上查找一下错误原因。
通过google搜索,找到 org.apache.hadoop.security.AccessControlException解决办法文章
http://www.51testing.com/?uid-445759-action-viewspace-itemid-821244
具体的错误原因,在文章中有写,我就不再列出了。我们参考他的方法二,对我们的hadoop环境进行调整。
在hdfs-site.xml中增加dfs.permissions.superusergroup的定义。
superusergroup,默认值用什么我们可以在系统中查一下。
~ hadoop fs -ls /
drwxr-xr-x - conan supergroup 0 2013-04-24 01:52 /hbase
drwxr-xr-x - conan supergroup 0 2013-04-25 04:59 /home
drwxr-xr-x - conan supergroup 0 2013-06-23 10:44 /tmp
drwxr-xr-x - conan supergroup 0 2013-04-24 19:28 /user
这样就得到了supergroup的名字是supergroup, 我们修改hdfs-site.xml,增加dfs.permissions.superusergroup的定义
~ vi $HADOOP_HOME/conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/conan/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>supergroup</value>
</property>
</configuration>
重启hadoop,重启R程序,重新执行rmr2脚本。还是有错误,没有解决问题。
4. 从rhadoop入手找解决办法 — 成功
我们找到rhadoop的作者github的issue 122:
https://github.com/RevolutionAnalytics/RHadoop/issues/122
发现其他人也遇到了,类似的错误。这issue已经是closed状态,证明错误已经解决。
根据作者的回答我们发现,错误是由于:“R的类库在特定的用户下面,而不是标准合位置,导致类库不能被hadoop找到”。
在我们的环境中,发现也是同样的配置,与错误描述一致。
~ R
> .libPaths()
[1] "/home/conan/R/x86_64-pc-linux-gnu-library/2.15"
[2] "/usr/local/lib/R/site-library"
[3] "/usr/lib/R/site-library"
[4] "/usr/lib/R/library"
~ ls /home/conan/R/x86_64-pc-linux-gnu-library/2.15
colorspace functional iterators munsell RColorBrewer rhdfs rmr2
dichromat ggplot2 itertools plyr Rcpp rJava scales
digest gtable labeling proto reshape2 RJSONIO stringr
~ ls /usr/local/lib/R/site-library
我们环境安装的所有类库,都在/home/conan目录下面,而/usr/local/lib/R/site-library一个库类都没有。
我们按照rhadoop作者指示,把包进行重新安装。
#切换到root下面
~ sudo -i
#查看R的类库路径
~ R
> .libPaths()
[1] "/usr/local/lib/R/site-library" "/usr/lib/R/site-library"
[3] "/usr/lib/R/library"
#在root下进行安装
~ R CMD javareconf
~ R
#启动R程序
install.packages("rJava")
install.packages("reshape2")
install.packages("Rcpp")
install.packages("iterators")
install.packages("itertools")
install.packages("digest")
install.packages("RJSONIO")
install.packages("functional")
~ cd /home/conan/R
~ R CMD INSTALL rmr2_2.1.0.tar.gz
~ ls /usr/local/lib/R/site-library
digest functional iterators itertools plyr Rcpp reshape2 rJava RJSONIO rmr2 stringr
依赖包都安装在了/usr/local/lib/R/site-library下面,我们退出root用户,重新启动R程序测试
~ exit
~ whoami
conan
~ R
> library(rmr2)
Loading required package: Rcpp
Loading required package: RJSONIO
Loading required package: digest
Loading required package: functional
Loading required package: stringr
Loading required package: plyr
Loading required package: reshape
#再次运行 rmr2程序
> small.ints = to.dfs(1:10)
> mapreduce(input = small.ints, map = function(k, v) cbind(v, v^2))
packageJobJar: [/tmp/RtmpM87JEc/rmr-local-env1c7588ca7ed, /tmp/RtmpM87JEc/rmr-global-env1c77fdcab5f, /tmp /RtmpM87JEc/rmr-streaming-map1c76a4ddf6e, /home/conan/hadoop/tmp/hadoop-unjar6992113986427459004/] [] /tm p/streamjob2762947354578034435.jar tmpDir=null
13/06/23 13:27:36 INFO mapred.FileInputFormat: Total input paths to process : 1
13/06/23 13:27:36 INFO streaming.StreamJob: getLocalDirs(): [/home/conan/hadoop/tmp/mapred/local]
13/06/23 13:27:36 INFO streaming.StreamJob: Running job: job_201306231141_0007
13/06/23 13:27:36 INFO streaming.StreamJob: To kill this job, run:
13/06/23 13:27:36 INFO streaming.StreamJob: /home/conan/hadoop/hadoop-1.0.3/libexec/../bin/hadoop job -D mapred.job.tracker=hdfs://master:9001 -kill job_201306231141_0007
13/06/23 13:27:36 INFO streaming.StreamJob: Tracking URL: http://master:50030/jobdetails.jsp?jobid=job_20 1306231141_0007
13/06/23 13:27:37 INFO streaming.StreamJob: map 0% reduce 0%
13/06/23 13:27:51 INFO streaming.StreamJob: map 100% reduce 0%
13/06/23 13:27:58 INFO streaming.StreamJob: map 100% reduce 100%
13/06/23 13:27:58 INFO streaming.StreamJob: Job complete: job_201306231141_0007
13/06/23 13:27:58 INFO streaming.StreamJob: Output: /tmp/RtmpM87JEc/file1c722c5c6ae
执行成功, 错误解决!!
本文从发现错误,定位错误,查找错误,解决错误,4个步骤解决上面的问题。
希望给遇到问题束手无策的同学,不仅提供直接的错误帮助,更有一个思路上的认识,提高自己的动手能力!!
转载请注明出处:
http://blog.fens.me/rhadoop-rmr2-pipemapred/

往Hadoop里面添加数据是不是有大小限制呢?
超过1G的数据就传不进去是吗?
大家看看这个矩阵是16000*10的小矩阵
很快就显示Successfully loaded
昨天我传的一个16000000*10的大矩阵传了很久 最后显示killed
退出了rhadoop
而且16000000*10的大矩阵其实也就不到1.2G 也不能算很大吧
请各位大神帮忙看看啊
为啥对于三个节点的hadoop集群来说
1.2G的大矩阵都传不上去呢??
我的每个节点都有4G内存的
以截图为证
如果您有时间请回复邮件 非常感激
1. Hadoop存储只和datanode有关。
2. 你用R生成matrix时,是在单机的内存中,很有可能是内存不够。
3. 所以,你的问题和Hadoop没有关系。
非常感谢。错误解决了。
张老师,为什么 R安装的库的位置会有3个,不同的用户权限安装的位置不一样? 我安装的只有如下图:另外两个是如何产生的?
你是自己动手安装的?
文章介绍的是Ubuntu用apt-get安装,默认会区分多用户的权限。
我的是redhat linux 安装的时候只有一个库路径
你在work用户下面安装的吧?这个用户有没有调用java的权限,及访问hadoop集群的权限?
错误如下:
java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:93)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:64)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:117)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:432)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:372)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:88)
… 9 more
Caused by: java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:93)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:64)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:117)
at org.apache.hadoop.mapred.MapRunner.configure(MapRunner.java:34)
… 14 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:88)
… 17 more
Caused by: java.lang.RuntimeException: configuration exception
at org.apache.hadoop.streaming.PipeMapRed.configure(PipeMapRed.java:230)
at org.apache.hadoop.streaming.PipeMapper.configure(PipeMapper.java:66)
… 22 more
Caused by: java.io.IOException: Cannot run program “Rscript”: java.io.IOException: error=2, No such file or directory
at java.lang.ProcessBuilder.start(ProcessBuilder.java:460)
at org.apache.hadoop.streaming.PipeMapRed.configure(PipeMapRed.java:214)
… 23 more
Caused by: java.io.IOException: java.io.IOException: error=2, No such file or directory
at java.lang.UNIXProcess.(UNIXProcess.java:148)
at java.lang.ProcessImpl.start(ProcessImpl.java:65)
at java.lang.ProcessBuilder.start(ProcessBuilder.java:453)
看着像权限的问题,找不到脚本。
Cannot run program “Rscript”: java.io.IOException: error=2, No such file or directory
运行rmr2的时候出现了错误,如下,请问怎么解决?
所有的包都用root安装的,但是还是错误信息:
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:362)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:576)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:135)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:57)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:36)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:436)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:372)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1149)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
rmr2包,安装有问题吧。
张老师,
small.ints = to.dfs(1:10)
mapreduce(input = small.ints, map = function(k, v) cbind(v, v^2))
这两行代码都执行成功了,但是我在运行您另一篇博客中关于统计邮箱数量点程序时,还是发生了问题:
错误于mr(map = map, reduce = reduce, combine = combine,vectorized.reduce, :
hadoop streaming failed with error code 1
查看错误日志,仍然有这样的结果:
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1 at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:366) at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:576) at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:136) at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61) at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:36) at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:397) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:330) at org.apache.hadoop.mapred.Child$4.run(Child.java:217) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:396) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:742) at org.apache.hadoop.mapred.Child.main(Child.java:211)
追踪到stderr,有这样的信息:
Loading required package: rhdfs
Error : .onLoad failed in loadNamespace() for ‘rhdfs’, details:
call: fun(libname, pkgname)
error: Environment variable HADOOP_CMD must be set before loading package rhdfs
FUN(c(“base”, “methods”, “datasets”, “utils”, “grDevices”, “graphics”, 里有警告:
can’t load rhdfs
但是我明明已经设置过HADOOP_CMD,无论是采用Sys.setenv的方式,还是export的方式
写到/etc/environment 试试
张老师您好,
我运行您的small.ints = to.dfs(1:10)mapreduce(input = small.ints, map = function(k, v) cbind(v, v^2))时出了问题,错误信息如下,而且按照您上面写的用root的方式将rmr2所需的包都安装了一遍,还是出错,请问是什么原因呢?谢谢!!
而且我的rmr2好像没有正常安装,会有如下警告信息,不知是否是这个因素引起的呢,若是的话该如何解决啊?谢谢您!
library(rmr2)
Please review your hadoop settings. See help(hadoop.settings)
警告信息:
S3方法‘gorder.default’, ‘gorder.factor’, ‘gorder.data.frame’, ‘gorder.matrix’, ‘gorder.raw’在NAMESPACE里有声明但不存在
这个问题,似乎就是不兼容的问题。
S3方法‘gorder.default’, ‘gorder.factor’, ‘gorder.data.frame’, ‘gorder.matrix’, ‘gorder.raw’在NAMESPACE
我也是同样情况,不过不影响使用,我google了一下,gorder只在启动测试时使用,不影响实际使用。
这种问题,check应该不过的。
本文主要针对是Hadoop 1.x, Java 1.6.x, R 2.15.x,如果你用了新的版本,可能也会出错不兼容的问题。
Hadoop的错误输出很烂。我遇到这个错误,看着是用户权限问题,其实是input里面有一个Invalid的record, mapper处理不了。
对,开源项目就是这样的。踩坑多了,就知道了。