从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可以帮助我们迅速建立web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站,个性化网站,我们自己的Geek网站!!
关于作者
- 张丹(Conan), 程序员Java,R,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/nodejs-alexa/
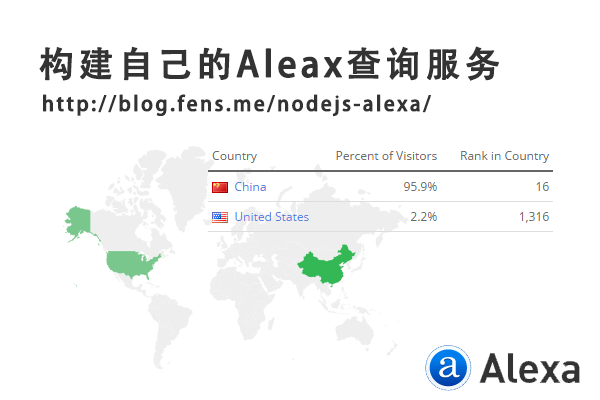
前言
每个网站的站长都会想尽办法提升网站的流量,从而获得更高的广告收入。那么评判一个网站好坏的标准,如Google的PR(PageRank),百度权重等。从PV(Page View)流量的角度,一个非常重要指标就是Alexa网站排名。
同全球的网站相比,你就能了解到自己网站的位置,让我们先挤进全球前10万的排名吧,不然都不好意思跟同行说,“自己有一个网站”。
目录
- Alexa介绍
- 用Node开发Alexa服务
1. Alexa介绍
Alexa (http://www.alexa.com/)是一家发布世界网站排名的网站,以搜索引擎起家的Alexa创建于1996年4月(美国),目的是让互联网网友在分享虚拟世界资源的同时,更多地参与互联网资源的组织。Alexa每天在网上搜集超过1TB的信息,不仅给出多达几十亿的网址链接,而且为其中的每一个网站进行了排名。可以说,Alexa是当前拥有URL数量最庞大,排名信息发布最详尽的网站。
1999年,Alexa被美国电子商务旗舰企业“亚马逊”收购,成为后者的全资子公司。2002年春,Alexa放弃了自己的搜索引擎,转而与Google合作。
Alexa提供了网站流量统计的服务,对全球有域名的网站进行流量记录。也就是说,只要你申请了域名,在Alexa中就可以查询到你的网站的排名。Alexa的网站排名是按照每个特定网站的被浏览率进行排名的。浏览率越大,排名越靠前。
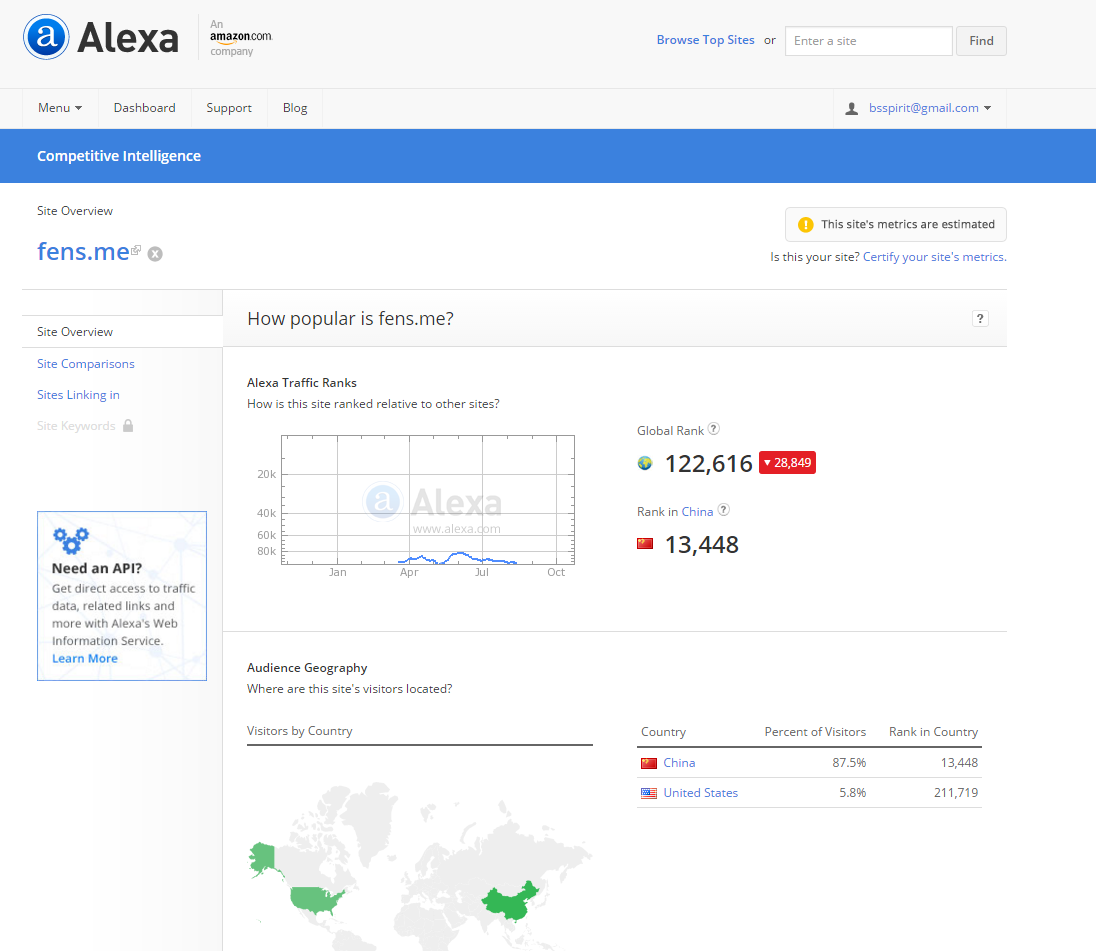
通常情况,如果你的域名刚刚注册,排名在1千万以上;接下来,你每天都经心运营网站,小有起色时,排名会进入前1百万;然后,你继续发布优质内容,坚持了一段时间,排名会升至前50万;当你的网站在某一领域小有名气时,排名可以到达10万,如粉丝日志122616(2015-10-25),这时就会有广告主愿意来投放广告了;如果你做的是以盈利为目的的网站,那么你需要再加油,进入到前1万,这个时候你的流量已经可以为你带来生意了;如果能做的更好,排名进入前2000,像雪球排名到2109(2015-10-25),那么你将会有一个很高的估值了;如果赶上一个天大的机遇,你的网站排名到了前100,那么你的网站将给你带来上市公司的价值,如京东105(2015-10-25);如果你是天才型的CEO,网站进了前10名,那么你将会成为一个产业的领袖,甚至是某个区域的首富,如百度4(2015-10-25)。
站长们,加油!
2. 用Node开发Alexa服务
2.1 Alexa开放API
Alexa网站排名被业界普通的认可,排名数据会经常地被引用,每次都在网站上查询就会显得不方便。Amazon提供的Alexa的API,让开发者可以构建自己的Alexa查询的应用。
Alexa有2个主要的数据API服务。
- Alexa Web Information Service,查询单个网站的排名信息
- Alexa Top Sites,查询网站的综合排名
通常情况,只需要调用UrlInfo数据接口,就可以获得网站的流量数据了。当然,这个接口的定义,并不像我之前想象的那么好用,而且开放出来的数据有限。
UrlInfo接口的API,如下图所示。
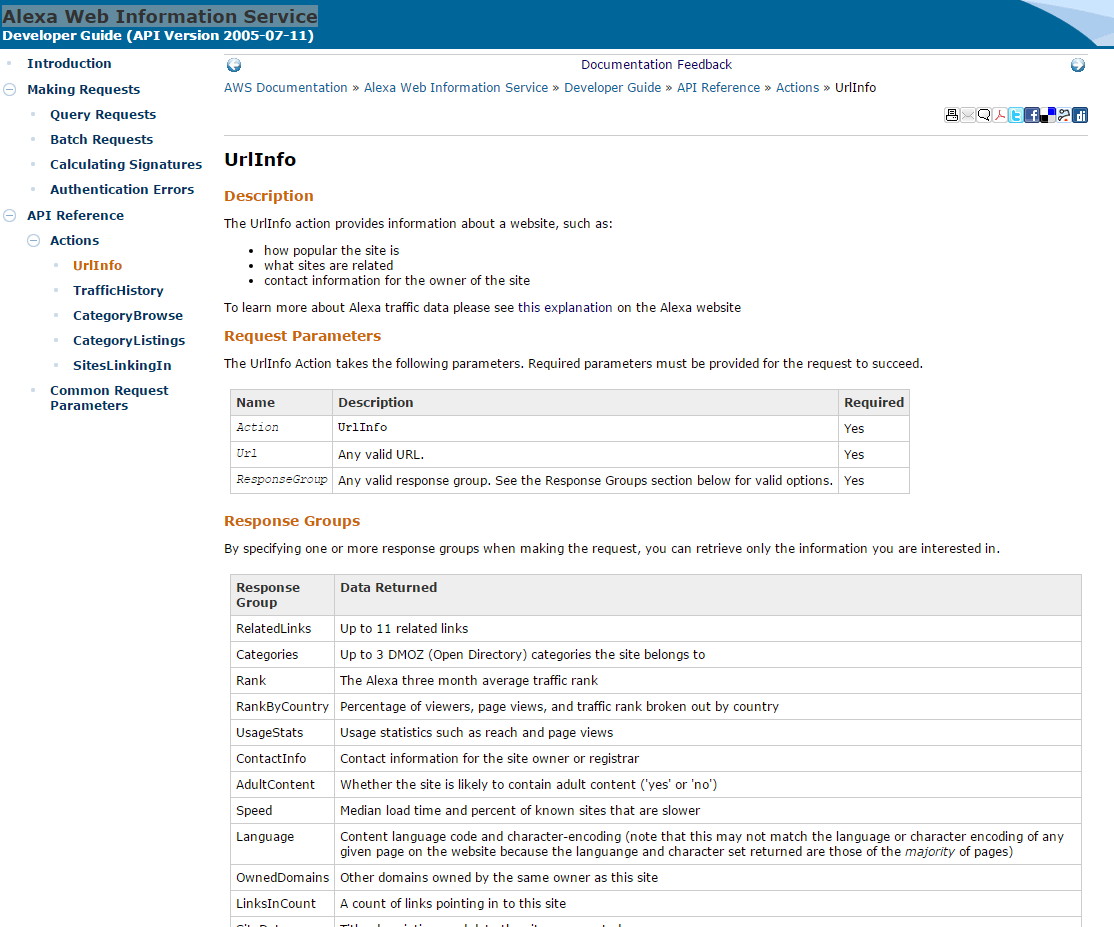
官方提供了多语言的SDK工具包,我觉得还是Node.js最方便。我构建的一个Alexa数据查询服务,http://fens.me/alexa
2.2 创建AWS的API密钥
我们在使用AWS的API之前,需要先创建密钥,类似于OAuth2的访问的机制。
1. 注册AWS账号,请大家自己完成。注册
2. 进入AWS账号管理控制台,控制台
3. 从控制台选择“安全证书”
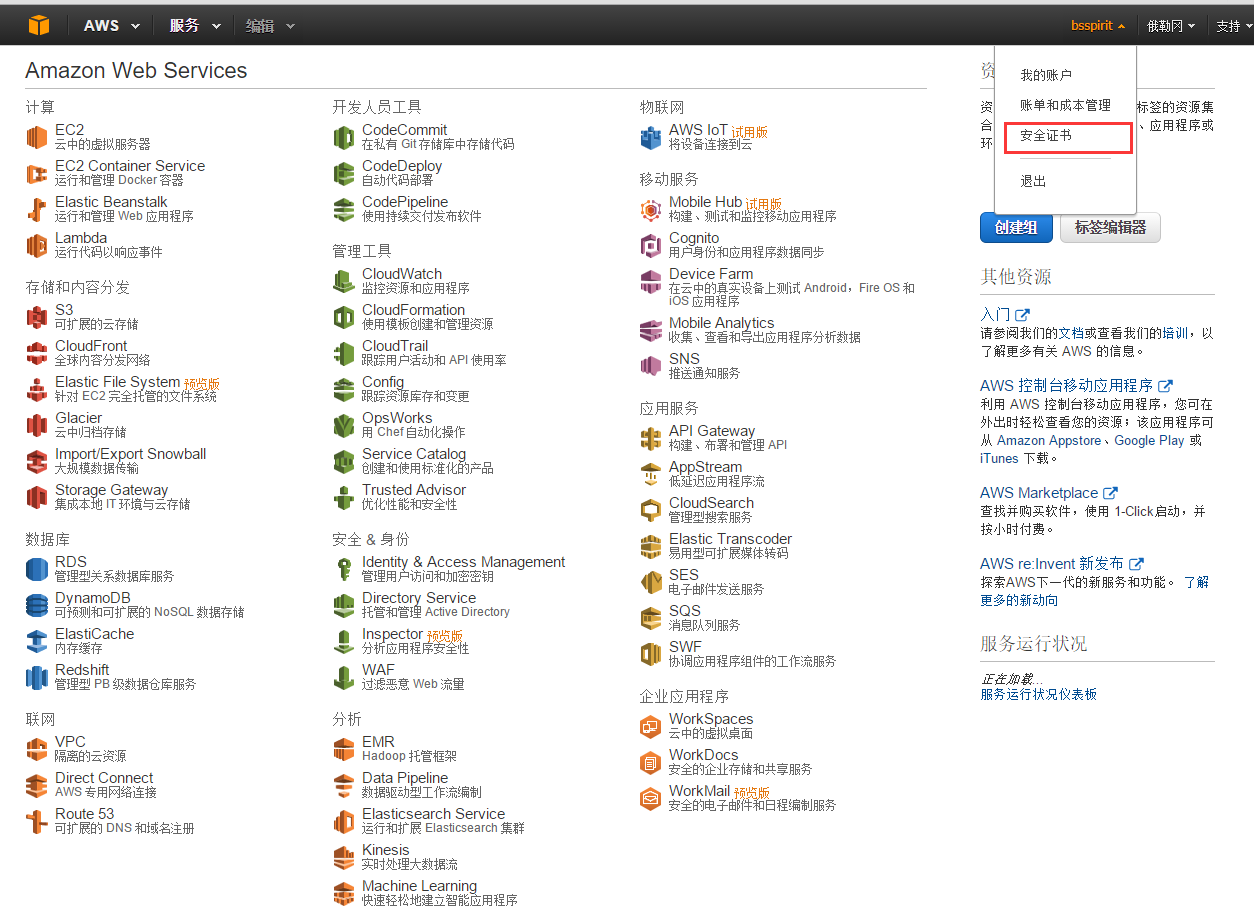
4. 创建访问密钥(访问密钥 ID 和私有访问密钥)
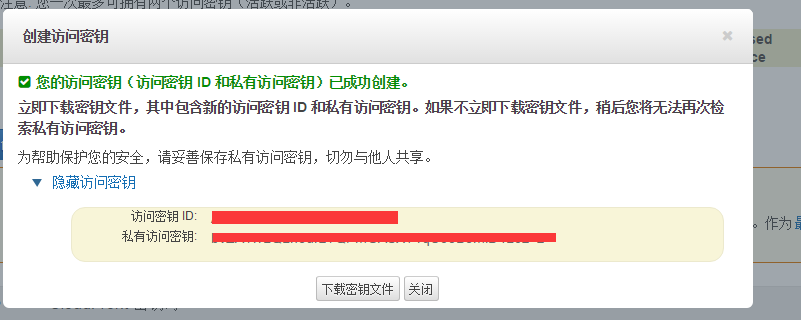
我们一会写程序的时候,需要输入创建的访问密钥 ID 和私有访问密钥。
2.3 用Node开发Alexa服务
接下来,介绍用Node构建一个Alexa的项目。
我的系统环境
- Win10 64bit
- Node v0.12.3
- NPM 2.9.1
创建项目
~ D:\workspace\nodejs>mkdir nodejs-alexa && cd nodejs-alexa
新建Node项目配置文件:package.json
~ vi package.json
{
"name": "alexa-demo",
"version": "0.0.1",
"description": "alexa web demo",
"license": "MIT",
"dependencies": {
"awis": "0.0.8"
}
}
安装awis包
~ D:\workspace\nodejs\nodejs-alexa>npm install
npm WARN package.json alexa-demo@0.0.1 No repository field.
npm WARN package.json alexa-demo@0.0.1 No README data
alexarank@0.1.1 node_modules\alexarank
├── xml2js@0.4.13 (sax@1.1.4, xmlbuilder@3.1.0)
└── request@2.30.0 (forever-agent@0.5.2, aws-sign2@0.5.0, qs@0.6.6, tunnel-agent@0.3.0, oauth-sign@0.3.0, json-stringify-safe@5.0.1, mime@1.2.11, node-uuid@1.4.3, tough-cookie@0.9.15, form-data@0.1.4, hawk@1.0.0, http-signature@0.10.1)
awis@0.0.8 node_modules\awis
├── xml2js@0.4.13 (sax@1.1.4, xmlbuilder@3.1.0)
├── lodash@3.10.1
└── request@2.65.0 (aws-sign2@0.6.0, forever-agent@0.6.1, caseless@0.11.0, stringstream@0.0.4, oauth-sign@0.8.0, tunnel-agent@0.4.1, isstream@0.1.2, json-stringify-safe@5.0.1, extend@3.0.0, node-uuid@1.4.3, qs@5.2.0, tough-cookie@2.2.0, combined-stream@1.0.5, mime-types@2.1.7, form-data@1.0.0-rc3, http-signature@0.11.0, hawk@3.1.0, bl@1.0.0, har-validator@2.0.2)
新建文件alexa.js,调用AWS Alexa网站排名API。
~ vi alexa.js
// 定义AWS密钥
var key = 'xxxxxxxxxxxxxxx';
var sercet = 'xxxxxxxxxxxxxxx';
// 创建awis实例化对象
var awis = require('awis');
var client = awis({
key: key,
secret: sercet
});
// 调用UrlInfo接口
console.log("=============UrlInfo=================");
client({
'Action': 'UrlInfo', //UrlInfo接口
'Url': 'fens.me', //查询的网站
'ResponseGroup': 'TrafficData,ContentData' //需要的数据组
}, function (err, data) {
if(err) console.log(err);
console.log(data);
});
运行程序node alexa.js
~ D:\workspace\nodejs\nodejs-alexa>node alexa.js
=============UrlInfo=================
{ contentData:
{ dataUrl: 'fens.me',
siteData:
{ title: '粉丝日志',
description: '跨界的IT博客|Hadoop家族, R, RHadoop, Nodejs, AngularJS, NoSQL, IT金融' },
speed: { medianLoadTime: '982', percentile: '70' },
adultContent: '',
language: '',
linksInCount: '198',
keywords: '',
ownedDomains: '' },
trafficData:
{ dataUrl: 'fens.me',
rank: '122616',
usageStatistics: { usageStatistic: [Object] },
contributingSubdomains: { contributingSubdomain: [Object] } } }
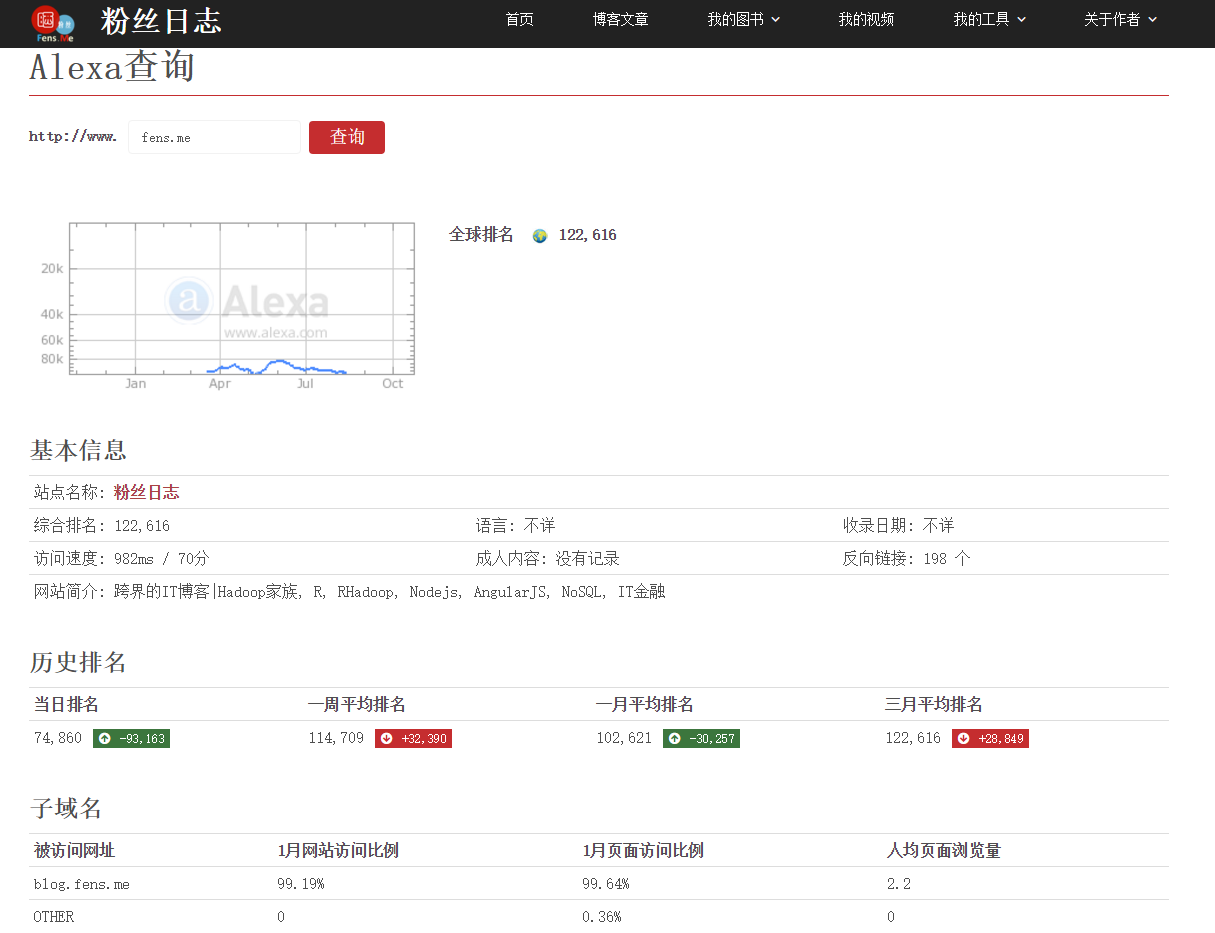
简简单单地几行代码,都获得了Alexa的排名信息。后台打印时Object没有转到成对象,我做了一个服务,可以通过HTTP输出查看完整的返回。http://api.fens.me/alexa/fens.me
我们查检一下awis包的源代码可以发现,其实AWS Alexa服务返回是XML,awis的自动帮我们做了JSON的转型处理,如果想查看原始的返回值,可以修改awis包中index.js文件parse()函数。
function parse(xml, req, cb) {
console.log(xml); //打印
....
}
运行程序
D:\workspace\nodejs\nodejs-alexa>node alexa.js
=============UrlInfo=================
<?xml version="1.0"?>
<aws:UrlInfoResponse xmlns:aws="http://alexa.amazonaws.com/doc/2005-10-05/"><aws:Response xmlns:aws="http://awis.amazonaws.com/doc/2005-07-11"><aws:OperationRequest><aws:RequestId>1e7d8406-4b62-3460-27fb-325fc3dc3e85</aws:RequestId></aws:OperationRequest><aws:UrlInfoResult><aws:Alexa>
<aws:ContentData>
<aws:DataUrl type="canonical">fens.me</aws:DataUrl>
<aws:SiteData>
<aws:Title>粉丝日志</aws:Title>
<aws:Description>跨界的IT博客|Hadoop家族, R, RHadoop, Nodejs, AngularJS, NoSQL, IT金融</aws:Description>
</aws:SiteData>
<aws:Speed>
<aws:MedianLoadTime>982</aws:MedianLoadTime>
<aws:Percentile>70</aws:Percentile>
</aws:Speed>
<aws:AdultContent/>
<aws:Language/>
<aws:LinksInCount>198</aws:LinksInCount>
<aws:Keywords/>
<aws:OwnedDomains/>
</aws:ContentData>
<aws:TrafficData>
<aws:DataUrl type="canonical">fens.me</aws:DataUrl>
<aws:Rank>122616</aws:Rank>
<aws:UsageStatistics>
<aws:UsageStatistic>
<aws:TimeRange>
<aws:Months>3</aws:Months>
</aws:TimeRange>
<aws:Rank>
<aws:Value>122616</aws:Value>
<aws:Delta>+28849</aws:Delta>
</aws:Rank>
<aws:Reach>
<aws:Rank>
<aws:Value>110056</aws:Value>
<aws:Delta>+25785</aws:Delta>
</aws:Rank>
<aws:PerMillion>
<aws:Value>12.5</aws:Value>
<aws:Delta>-24.68%</aws:Delta>
</aws:PerMillion>
</aws:Reach>
<aws:PageViews>
<aws:PerMillion>
<aws:Value>0.27</aws:Value>
<aws:Delta>-24.84%</aws:Delta>
</aws:PerMillion>
<aws:Rank>
<aws:Value>194189</aws:Value>
<aws:Delta>43945</aws:Delta>
</aws:Rank>
<aws:PerUser>
<aws:Value>1.9</aws:Value>
<aws:Delta>0%</aws:Delta>
</aws:PerUser>
</aws:PageViews>
</aws:UsageStatistic>
<aws:UsageStatistic>
<aws:TimeRange>
<aws:Months>1</aws:Months>
</aws:TimeRange>
<aws:Rank>
<aws:Value>102621</aws:Value>
<aws:Delta>-30257</aws:Delta>
</aws:Rank>
<aws:Reach>
<aws:Rank>
<aws:Value>95663</aws:Value>
<aws:Delta>-20326</aws:Delta>
</aws:Rank>
<aws:PerMillion>
<aws:Value>15</aws:Value>
<aws:Delta>+20%</aws:Delta>
</aws:PerMillion>
</aws:Reach>
<aws:PageViews>
<aws:PerMillion>
<aws:Value>0.37</aws:Value>
<aws:Delta>+60%</aws:Delta>
</aws:PerMillion>
<aws:Rank>
<aws:Value>153976</aws:Value>
<aws:Delta>-69981</aws:Delta>
</aws:Rank>
<aws:PerUser>
<aws:Value>2.2</aws:Value>
<aws:Delta>+30%</aws:Delta>
</aws:PerUser>
</aws:PageViews>
</aws:UsageStatistic>
<aws:UsageStatistic>
<aws:TimeRange>
<aws:Days>7</aws:Days>
</aws:TimeRange>
<aws:Rank>
<aws:Value>114709</aws:Value>
<aws:Delta>+32390</aws:Delta>
</aws:Rank>
<aws:Reach>
<aws:Rank>
<aws:Value>103552</aws:Value>
<aws:Delta>+27312</aws:Delta>
</aws:Rank>
<aws:PerMillion>
<aws:Value>14</aws:Value>
<aws:Delta>-28.59%</aws:Delta>
</aws:PerMillion>
</aws:Reach>
<aws:PageViews>
<aws:PerMillion>
<aws:Value>0.3</aws:Value>
<aws:Delta>-37.28%</aws:Delta>
</aws:PerMillion>
<aws:Rank>
<aws:Value>188124</aws:Value>
<aws:Delta>58655</aws:Delta>
</aws:Rank>
<aws:PerUser>
<aws:Value>2.0</aws:Value>
<aws:Delta>-12.11%</aws:Delta>
</aws:PerUser>
</aws:PageViews>
</aws:UsageStatistic>
<aws:UsageStatistic>
<aws:TimeRange>
<aws:Days>1</aws:Days>
</aws:TimeRange>
<aws:Rank>
<aws:Value>74860</aws:Value>
<aws:Delta>-93163</aws:Delta>
</aws:Rank>
<aws:Reach>
<aws:Rank>
<aws:Value>70563</aws:Value>
<aws:Delta>-54001</aws:Delta>
</aws:Rank>
<aws:PerMillion>
<aws:Value>20</aws:Value>
<aws:Delta>+60%</aws:Delta>
</aws:PerMillion>
</aws:Reach>
<aws:PageViews>
<aws:PerMillion>
<aws:Value>0.6</aws:Value>
<aws:Delta>+300%</aws:Delta>
</aws:PerMillion>
<aws:Rank>
<aws:Value>111541</aws:Value>
<aws:Delta>-210757</aws:Delta>
</aws:Rank>
<aws:PerUser>
<aws:Value>2</aws:Value>
<aws:Delta>+100%</aws:Delta>
</aws:PerUser>
</aws:PageViews>
</aws:UsageStatistic>
</aws:UsageStatistics>
<aws:ContributingSubdomains>
<aws:ContributingSubdomain>
<aws:DataUrl>blog.fens.me</aws:DataUrl>
<aws:TimeRange>
<aws:Months>1</aws:Months>
</aws:TimeRange>
<aws:Reach>
<aws:Percentage>99.19%</aws:Percentage>
</aws:Reach>
<aws:PageViews>
<aws:Percentage>99.64%</aws:Percentage>
<aws:PerUser>2.2</aws:PerUser>
</aws:PageViews>
</aws:ContributingSubdomain>
<aws:ContributingSubdomain>
<aws:DataUrl>OTHER</aws:DataUrl>
<aws:TimeRange>
<aws:Months>1</aws:Months>
</aws:TimeRange>
<aws:Reach>
<aws:Percentage>0</aws:Percentage>
</aws:Reach>
<aws:PageViews>
<aws:Percentage>0.36%</aws:Percentage>
<aws:PerUser>0</aws:PerUser>
</aws:PageViews>
</aws:ContributingSubdomain>
</aws:ContributingSubdomains>
</aws:TrafficData>
</aws:Alexa></aws:UrlInfoResult><aws:ResponseStatus xmlns:aws="http://alexa.amazonaws.com/doc/2005-10-05/"><aws:StatusCode>Success</aws:StatusCode></aws:ResponseStatus></aws:Response></aws:UrlInfoResponse>
除了UrlInfo接口还有几个接口可以使用。
TrafficHistory接口
console.log("=============TrafficHistory=================");
client({
'Action': 'TrafficHistory',
'Url': 'fens.me',
'ResponseGroup': 'History'
}, function (err, res) {
if(err) console.log(err);
console.log(res.trafficHistory);
console.log(res.trafficHistory.range);
console.log(res.trafficHistory.site);
console.log(res.trafficHistory.start);
console.log(res.trafficHistory.historicalData);
console.log(res.trafficHistory.historicalData.data);
console.log(res.trafficHistory.historicalData.data.length);
res.trafficHistory.historicalData.data.forEach(function (item) {
console.log(item.date);
console.log(item.pageViews);
console.log(item.rank);
console.log(item.reach);
});
});
运行程序
~ D:\workspace\nodejs\nodejs-alexa>node alexa.js
=============TrafficHistory=================
{ range: '31',
site: 'fens.me',
start: '2015-09-23',
historicalData:
{ data:
[ [Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object] ] } }
// 省略输出
SitesLinkingIn接口
console.log("=============SitesLinkingIn=================");
client({
'Action': 'SitesLinkingIn',
'Url': 'fens.me',
'ResponseGroup': 'SitesLinkingIn'
}, function (err, data) {
if(err) console.log(err);
console.log(data);
});
运行程序
~ D:\workspace\nodejs\nodejs-alexa>node alexa.js
=============SitesLinkingIn=================
{ sitesLinkingIn:
{ site:
[ [Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object],
[Object] ] } }
CategoryBrowse接口
console.log("=============CategoryBrowse=================");
client({
'Action': 'CategoryBrowse',
'Url': 'fens.me',
'Path': 'Top/china',
'ResponseGroup': 'LanguageCategories'
}, function (err, data) {
if(err) console.log(err);
console.log(data);
});
运行程序
~ D:\workspace\nodejs\nodejs-alexa>node alexa.js
=============CategoryBrowse=================
{ categoryBrowse: { languageCategories: '' } }
最后,我们只需要把这个程序用web封装一下,就可以提供对用户的服务了,参考我的网站 http://fens.me/alexa 。
本文对应的代码请通过github进行下载,下载地址为:https://github.com/bsspirit/nodejs-alexa
Alexa网站排名以第三方的视角给全球的每个网站进行了排名,甚至是定价。做为一个优秀的网长,我们要使用好Alexa工具,了解自己的网站和竞争对手的网站,才能网站脱颖而出,成为成功的站长!
转载请注明出处:
http://blog.fens.me/nodejs-alexa/

