R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-encode-decode/
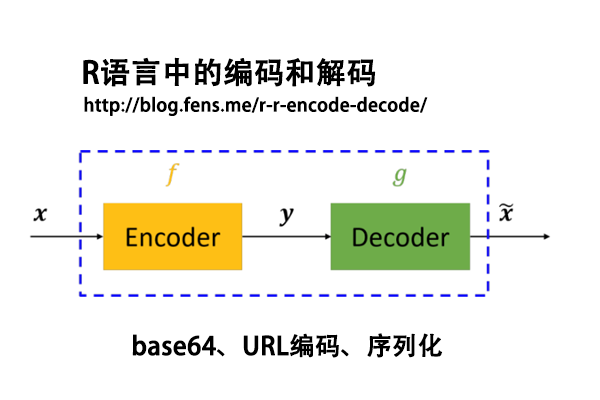
前言
编码是信息从一种形式或格式转换为另一种形式的过程,解码是编码的逆过程。编码和解码的应用场景,普遍存在于数据通信,不同系统的对接,数据格式标准化等领域。
本文主要介绍了3种类型的编码和解码的方法,都有对应的R语言函数来支持,这样就让我们的开发工作变得更容易了。
目录
- base64编码和解码
- URL编码和解码
- 序列化和反序列化
1. base64编码和解码
base64编码,是在网络数据传输过程中,一种常用的数据编码格式。Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。
Base64是一种编码方式,最初是在“MIME内容传输编码规范”中提出。Base64不是一种加密算法,它是一种二进制转换到文本的编码方式,它能够将任意二进制数据转换为ASCII字符串的形式,以便在只支持文本的环境中也能够顺利地传输二进制数据。
- base64编码(encode):把二进制数据转为字符;
- base64解码(decode):把字符转为二进制数据;
我们可以使用R语言的base64enc包,进行base64编码和解码。
# 加载base64enc包
> library(base64enc)
# 原始文本数据
> value<-"abc=!@#$%^&*()_+abc试试中文"
# 字符串转换为原始字节
> x <- charToRaw(value);x
[1] 61 62 63 3d 21 40 23 24 25 5e 26 2a 28 29 5f 2b 61 62 63
[20] ca d4 ca d4 d6 d0 ce c4
# base64编码
> y <- base64encode(x);y
[1] "YWJjPSFAIyQlXiYqKClfK2FiY8rUytTW0M7E"
# base64解码
> z <- base64decode(y);z
[1] 61 62 63 3d 21 40 23 24 25 5e 26 2a 28 29 5f 2b 61 62 63
[20] ca d4 ca d4 d6 d0 ce c4
# 字节转换为字符串
> a <- rawToChar(z);a
[1] "abc=!@#$%^&*()_+abc试试中文"
同时,也可以使用jsonlite包进行,进行base64编码和解码。
# 加载jsonlite包
> library(jsonlite)
# 原始文本数据
> value<-"abc=!@#$%^&*()_+abc试试中文"
# base64编码,默认会做charToRaw
> a<-base64_enc(value);a
[1] "YWJjPSFAIyQlXiYqKClfK2FiY8rUytTW0M7E"
# base64解码,字节转换为字符串
> b<-rawToChar(base64_dec(a));b
[1] "abc=!@#$%^&*()_+abc试试中文"
上面2种方法,都可以正确地进行base64的编码和解码。
2. URL编码和解码
URL encoding是Uniform Resource Identifier(URI)规范文档中对特殊字符编码制定的规则。本质是把一个字符转为%加上UTF-8编码对应的16进制数字。
url编码是一种浏览器用来打包表单输入的格式的方法。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。服务器端的表单输入格式,如: theName=Ichabod+Crane&gender=male&status=missing&headless=yes
URL 只支持 ASCII 码传输,URL encoding 使用 % 加上两个十六进制数编码不支持的字符,URL 不能含有空格,URL encoding 替换空格成 %20 。
- URL编码(encode):把URL文本转换为URL编码
- URL解码(decode):把URL编码转换为URL文本
# 原始URL
> url<-"http://blog.fens.me/abc=中@文&action=你 好"
# URL编码
> a1<-URLencode(url);a1
[1] "http://blog.fens.me/abc=%D6%D0@%CE%C4&action=%C4%E3%20%BA%C3"
# URL解码
> b1<-URLdecode(a);b1
[1] "http://blog.fens.me/abc=中@文&action=你 好"
# 把'保留'字符编码,如http://中的://
> a2<-URLencode(url,reserved = TRUE);a2
[1] "http%3A%2F%2Fblog.fens.me%2Fabc%3D%D6%D0%40%CE%C4%26action%3D%C4%E3%20%BA%C3"
# URL解码
> b2<-URLdecode(a);b2
[1] "http://blog.fens.me/abc=中@文&action=你 好"
3. 序列化和反序列化
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
序列化的目标:以某种存储形式使自定义对象持久化,将对象从一个地方传递到另一个地方,使程序更具维护性。基本上只要是涉及到跨平台存储或者进行网络传输的数据,都需要进行序列化。
- seriallization 序列化 : 将对象转化为便于传输的格式, 常见的序列化格式:二进制格式,字节数组,json字符串,xml字符串。
- deseriallization 反序列化:将序列化的数据恢复为对象的过程。
字符数据序列化。
# 原始字符数据
> value<-"abc=!@#$%^&*()_+abc试试中文"
# 序列化
> a<-serialize(value,NULL);a
[1] 58 0a 00 00 00 03 00 04 00 03 00 03 05 00 00 00 00 05 43 50
[21] 39 33 36 00 00 00 10 00 00 00 01 00 00 00 09 00 00 00 1b 61
[41] 62 63 3d 21 40 23 24 25 5e 26 2a 28 29 5f 2b 61 62 63 ca d4
[61] ca d4 d6 d0 ce c4
# 反序列化
> b<-unserialize(a);b
[1] "abc=!@#$%^&*()_+abc试试中文"
data.frame数据序列化。
# 原始数据
> dat<-mtcars[1:2,];dat
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
# 序列化
> a<-serialize(dat,NULL);a
[1] 58 0a 00 00 00 03 00 04 00 03 00 03 05 00 00 00 00 05 43
[20] 50 39 33 36 00 00 03 13 00 00 00 0b 00 00 00 0e 00 00 00
[39] 02 40 35 00 00 00 00 00 00 40 35 00 00 00 00 00 00 00 00
[58] 00 0e 00 00 00 02 40 18 00 00 00 00 00 00 40 18 00 00 00
[77] 00 00 00 00 00 00 0e 00 00 00 02 40 64 00 00 00 00 00 00
[96] 40 64 00 00 00 00 00 00 00 00 00 0e 00 00 00 02 40 5b 80
[115] 00 00 00 00 00 40 5b 80 00 00 00 00 00 00 00 00 0e 00 00
[134] 00 02 40 0f 33 33 33 33 33 33 40 0f 33 33 33 33 33 33 00
[153] 00 00 0e 00 00 00 02 40 04 f5 c2 8f 5c 28 f6 40 07 00 00
[172] 00 00 00 00 00 00 00 0e 00 00 00 02 40 30 75 c2 8f 5c 28
[191] f6 40 31 05 1e b8 51 eb 85 00 00 00 0e 00 00 00 02 00 00
[210] 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0e 00
[229] 00 00 02 3f f0 00 00 00 00 00 00 3f f0 00 00 00 00 00 00
[248] 00 00 00 0e 00 00 00 02 40 10 00 00 00 00 00 00 40 10 00
[267] 00 00 00 00 00 00 00 00 0e 00 00 00 02 40 10 00 00 00 00
[286] 00 00 40 10 00 00 00 00 00 00 00 00 04 02 00 00 00 01 00
[305] 04 00 09 00 00 00 05 6e 61 6d 65 73 00 00 00 10 00 00 00
[324] 0b 00 04 00 09 00 00 00 03 6d 70 67 00 04 00 09 00 00 00
[343] 03 63 79 6c 00 04 00 09 00 00 00 04 64 69 73 70 00 04 00
[362] 09 00 00 00 02 68 70 00 04 00 09 00 00 00 04 64 72 61 74
[381] 00 04 00 09 00 00 00 02 77 74 00 04 00 09 00 00 00 04 71
[400] 73 65 63 00 04 00 09 00 00 00 02 76 73 00 04 00 09 00 00
[419] 00 02 61 6d 00 04 00 09 00 00 00 04 67 65 61 72 00 04 00
[438] 09 00 00 00 04 63 61 72 62 00 00 04 02 00 00 00 01 00 04
[457] 00 09 00 00 00 09 72 6f 77 2e 6e 61 6d 65 73 00 00 00 10
[476] 00 00 00 02 00 04 00 09 00 00 00 09 4d 61 7a 64 61 20 52
[495] 58 34 00 04 00 09 00 00 00 0d 4d 61 7a 64 61 20 52 58 34
[514] 20 57 61 67 00 00 04 02 00 00 00 01 00 04 00 09 00 00 00
[533] 05 63 6c 61 73 73 00 00 00 10 00 00 00 01 00 04 00 09 00
[552] 00 00 0a 64 61 74 61 2e 66 72 61 6d 65 00 00 00 fe
# 反序列化
> b<-unserialize(a);b
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
JSON序列化,把用于把data.frame的数据结构,转换为JSON结构的过程。
# 原始数据
> dat<-mtcars[1:2,];dat
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
# JSON序列化
> s1 <- serializeJSON(dat);s1
{"type":"list","attributes":{"names":{"type":"character","attributes":{},"value":["mpg","cyl","disp","hp","drat","wt","qsec","vs","am","gear","carb"]},"row.names":{"type":"character","attributes":{},"value":["Mazda RX4","Mazda RX4 Wag"]},"class":{"type":"character","attributes":{},"value":["data.frame"]}},"value":[{"type":"double","attributes":{},"value":[21,21]},{"type":"double","attributes":{},"value":[6,6]},{"type":"double","attributes":{},"value":[160,160]},{"type":"double","attributes":{},"value":[110,110]},{"type":"double","attributes":{},"value":[3.9,3.9]},{"type":"double","attributes":{},"value":[2.62,2.875]},{"type":"double","attributes":{},"value":[16.46,17.02]},{"type":"double","attributes":{},"value":[0,0]},{"type":"double","attributes":{},"value":[1,1]},{"type":"double","attributes":{},"value":[4,4]},{"type":"double","attributes":{},"value":[4,4]}]}
# JSON反序列化
> s2 <- unserializeJSON(jsoncars);s2
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
# 对比序列化前后的数据是否一致
> identical(dat, s2)
[1] TRUE
本文总结了3种常用的编码和解码的方法,让R语言能在工程的过程中,有了底层工具的支持,为我们的开发有提供便利性。不用关心底层,用心做好模型。
本文代码已上传到github: https://github.com/bsspirit/encrypt/blob/master/encode.r
转载请注明出处:
http://blog.fens.me/r-encode-decode/