R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员/Quant: Java,R,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-discretization

前言
在做数据挖掘模型的时候,我们有时会需要把连续型变量转型离散变量,这种转换的过程就是数据离散化,分箱就是离散化常用的一种方法。
数据离散化处理属于数据预处理的一个过程,R语言在数据处理上有天然的优势,也有直接用于离散化计算的包,无监督的离散化可以用infotheo包,有监督的离散化可以用discretization包来处理复杂的离散化操作。
目录
- 数据离散化的需求
- 无监督的数据离散化
- 有监督的数据离散化
1. 数据离散化的需求
数据离散化,教课书上面的定义是,把无限空间中有限的个体映射到有限的空间中。数据离散化操作,大多是针对连续型变量进行的,处理之后数据从连续型变量转变为离散型变量。
离散化处理的特点:
- 快速迭代,离散化的过程,离散特征增加和减少都很容易,易于扩展。
- 高效计算,稀疏向量内积乘法运算速度快,计算结果方便存储。
- 适应性,有些分类模型适合用离散化数据做为数据指标,比如决策树虽然支持输入连续型变量,但决策树模型本身会先将连续型变量转化为离散型变量,做逻辑回归时,也通常会先把连续型特征变量离散化,变成0或1。
- 鲁棒性,数据离散化会让特征变化不是特别明显,特别是对于降低异常数据干扰。
- 稳定性,牺牲了数据的微小变化,但保证了模型的稳定性。
- 过拟合,减少的数据信息,降低了过拟合的风险。
- 业务性,业务上已经定义出了离散值的含义,需要做离散化处理。
离散化处理通常对连续型变量进行处理,但同时也可以对离散型变量再进行离散化,适用于数据聚合或重新分组。
2. 无监督的数据离散化
我们可以无监督的数据离散化方法,进行数据的分箱操作,包括等宽分箱法、等频分箱法、通过kmeans分箱法等。
- 等宽分箱法,将观察点均匀划分成n等份,每份的间距相等。
- 等频分箱法,将观察点均匀分成n等份,每份的观察点数相同。
- kmeans分箱法,先给定中心数,将观察点利用欧式距离计算与中心点的距离进行归类,再重新计算中心点,直到中心点不再发生变化,以归类的结果做为分箱的结果。
接下来,我们用R语言来实现上面提到的几种分箱的操作。
2.1 准备数据
本文所使用的系统环境
- Win10 64bit
- R: 3.2.3 x86_64-w64-mingw32/x64 b4bit
首先,生成一组数据,这组织通过3个正态分布的随机数进行叠加,主要用于体现分箱的不同特征。
# 设置随机数种子,生成符合正态分布N(0,1)的数据1000个点
> set.seed(0)
> a1<-rnorm(1000)
> set.seed(1)
> a2<-rnorm(300,0,0.2)
> set.seed(2)
> a3<-rnorm(300,3,0.5)
# 按顺序,合并3种数据
> aa<-c(a1,a2,a3)
# 查看数据
> head(aa,30)
[1] 1.26295 -0.32623 1.32980 1.27243 0.41464 -1.53995 -0.92857 -0.29472 -0.00577 2.40465 0.76359
[12] -0.79901 -1.14766 -0.28946 -0.29922 -0.41151 0.25222 -0.89192 0.43568 -1.23754 -0.22427 0.37740
[23] 0.13334 0.80419 -0.05711 0.50361 1.08577 -0.69095 -1.28460 0.04673
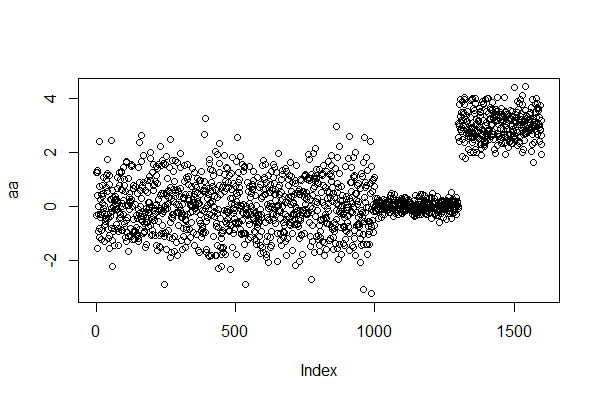
画出数据的散点图,x轴为索引序号,y轴为值。
> plot(aa)
查看数据的分布形状,x轴为值,y轴为这个值出现的次数。
# 画出数据的直方图
> hist(aa,200)
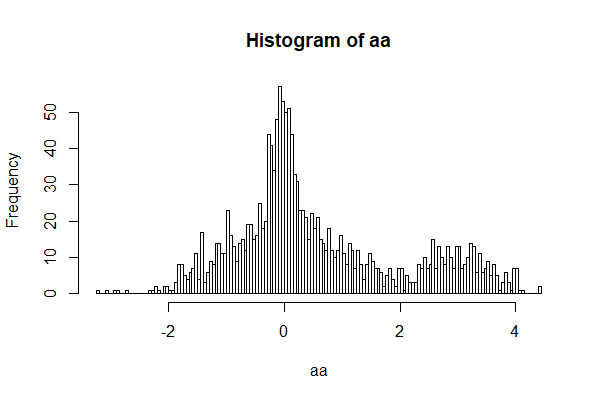
通过散点图和直方图,就可以很明显的看到数据的特征,数据有倾斜的,值在0和3附近是比较多的。
2.2 infotheo包使用
在R语言中,我们可以使用infotheo包,来做等宽分箱和等频分箱。
项目主页:https://cran.r-project.org/web/packages/infotheo/
安装infotheo包,是非常简单的,只需要一条命令。
~ R
> install.packages("infotheo")
> library(infotheo)
进行等宽分箱,将观察点均匀划分成n等份,每份的间距相等。
> d1<-discretize(aa,"equalwidth",5)
> table(d1)
d1
1 2 3 4 5
40 467 703 217 173
# 可视化分箱
> plot(aa,col=d1$X)
分为5组,第一组最少,第三组最多,每组值的区间是一样的。

进行等频率分箱,将观察点均匀分成n等份,每份的观察点数相同。
> d2<-discretize(aa,"equalfreq",5)
> table(d2)
d2
1 2 3 4 5
320 320 320 320 320
# 可视化分箱
> plot(aa,col=d2$X)
分为5组,每组的数量都相同。

kmeans分箱法,先给定中心数为5。
> d3<-kmeans(aa,5)
> table(d3$cluster)
1 2 3 4 5
121 258 303 267 651
# 5个中心
> d3$centers
[,1]
1 -1.6196
2 1.2096
3 3.0436
4 -0.7228
5 0.0736
# 可视化分箱
> plot(aa,col=d3$cluster)
5组聚类的结果。
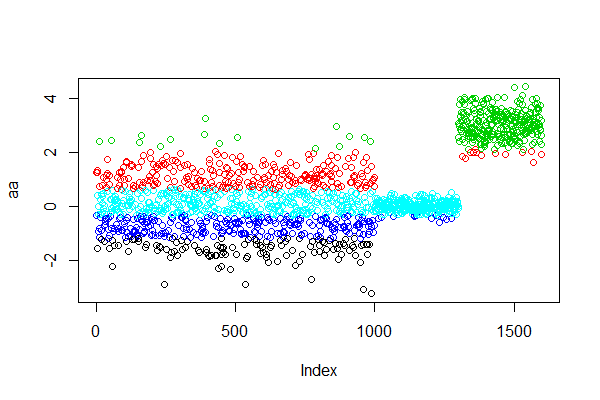
每一种方法,对于分箱的离散化的结果都是不同的,使用哪一种方法,最好都有业务上的解释,不能随便乱用。
3. 有监督的数据离散化方法
有监督的离散化的方法,可以用R语言中discretization包来操作。discretization包,是一个用来做有监督离散化的工具集,主要用于卡方分箱算法,它提供了几种常用的离散化工具函数,可以按照自上而下或自下而上,实施离散化算法。
项目主页:https://cran.r-project.org/web/packages/discretization/
安装discretization包是非常简单的,只需要一条命令。
~ R
> install.packages("discretization")
> library(discretization)
discretization提供了几个主要的离散化的工具函数:
- chiM,ChiM算法进行离散化
- chi2, Chi2算法进行离散化
- mdlp,最小描述长度原理(MDLP)进行离散化
- modChi2,改进的Chi2方法离散数值属性
- disc.Topdown,自上而下的离散化
- extendChi2,扩展Chi2算法离散数值属性
3.1 卡方分箱
卡方分箱是依赖于卡方检验的分箱方法,在统计指标上选择卡方统计量(chi-Square)进行判别。卡方分箱的基本思想是判断相邻的两个区间是否有分布差异,如果两个相邻的区间具有非常类似的分布,则这两个区间可以合并;否则,它们应当保持分开。基于卡方统计量的结果进行自下而上的合并,直到满足分箱的限制条件为止。
卡方分箱的实现步骤:
1. 预先设定一个卡方的阈值。以这个阈值为标准,我们对数据进行卡方检验,通过显著性水平和自由度,计算出数据的卡方值与这个阈值进行比较。
- 显著性水平,当置信度90%时显著性水平为10%,ChiMerge算法推荐使用置信度为0.90、0.95、0.99。
- 自由度,比分类数量小1。例如:有3类,自由度为2。
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6。大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
2. 初始化:根据要离散化的数据对实例进行排序,每个实例属于一个区间
3. 合并区间:
1) 计算每一个对相邻区间的卡方值
2) 将卡方值最小的一对区间合并

卡方统计量衡量了区间内样本的频数分布与整体样本的频数分布的差异性,在做分箱处理时可以使用两种限制条件:
- 分箱个数:限制最终的分箱个数结果,每次将样本中具有最小卡方值的区间与相邻的最小卡方区间进行合并,直到分箱个数达到限制条件为止。
- 卡方阈值:根据自由度和显著性水平得到对应的卡方阈值,如果分箱的各区间最小卡方值小于卡方阈值,则继续合并,直到最小卡方值超过设定阈值为止。
4.评估指标
分为箱之后需要评估,常用的评估手段是计算出WOE和IV值。对于WOE和IV值的含义,参考文章:https://blog.csdn.net/kevin7658/article/details/50780391
3.2 数据准备
有监督的离散化算法,只少需要数据为2列,一列用于离散化的向量数据,一列是分类的评价标准数据,所以我们需要重新选择一个数据集,具有分类标准的数据。
我们使用一个系统自带的数据集iris,这个着名的Fisher的鸢尾花数据。iris包含150个记录,和5个变量的数据框,名为Sepal.Length(萼片的长度),Sepal.Width(萼片的宽度),Petal.Length(花瓣的长度),Petal.Width(花瓣的长度)和Species(种类,setosa,versicolor和virginica)。
查看数据集
> data(iris)
> head(iris,10)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
接下来,我们分别用不同的算法,把这个数据集进行离散化处理。
3.3 chiM算法进行离散化
ChiM()函数,使用ChiMerge算法基于卡方检验进行自下而上的合并。通过卡方检验判断相邻阈值的相对类频率,是否有明显不同,或者它们是否足够相似,从而合并为一个区间。
chiM(data,alpha)函数解读。
- 第一个参数data,是输入数据集,要求最后一列是分类属性。
- 第二个参数alpha,表示显著性水平。
- 自由度,通过数据计算获得是2,一共3个分类减去1。
下面使用chiM()进行计算。
# 离散化计算
> chi1<-chiM(iris,alpha=0.05)
# 查看前10条结果
> head(chi1$Disc.data,10)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 3 1 1 setosa
2 1 2 1 1 setosa
3 1 2 1 1 setosa
4 1 2 1 1 setosa
5 1 3 1 1 setosa
6 1 3 1 1 setosa
7 1 3 1 1 setosa
8 1 3 1 1 setosa
9 1 1 1 1 setosa
10 1 2 1 1 setosa
chi2算法的结果解读,从输出结果可以看出,Sepal.Length Sepal.Width Petal.Length Petal.Width,这几个变量被自动地离散化处理了。
查看这4个列的离散化情况。
> apply(chi1$Disc.data,2,table)
$Sepal.Length
1 2 3 4
52 21 65 12
$Sepal.Width
1 2 3
57 56 37
$Petal.Length
1 2 3 4
50 45 21 34
$Petal.Width
1 2 3
50 54 46
$Species
setosa versicolor virginica
50 50 50
再查看每个列的阈值。
# 查看分组阈值
> chi1$cutp
[[1]]
[1] 5.45 5.75 7.05
[[2]]
[1] 2.95 3.35
[[3]]
[1] 2.45 4.75 5.15
[[4]]
[1] 0.80 1.75
以第一组Sepal.Length举例,被分为4类,当源数据Sepal.Length列的值,小于 5.45值为1类,大于5.45同时小于5.75为2类,大于5.75同时小于7.05为3类,大于7.05为4类。
我们把离散化后的数据,与源数据进行合并进行观察。第一列是离散化后的数据,第二列是源数据。
> chi1df<-cbind(chi1$Disc.data$Sepal.Length,iris$Sepal.Length)
> head(chi1df,20)
[,1] [,2]
[1,] 1 5.1
[2,] 1 4.9
[3,] 1 4.7
[4,] 1 4.6
[5,] 1 5.0
[6,] 1 5.4
[7,] 1 4.6
[8,] 1 5.0
[9,] 1 4.4
[10,] 1 4.9
[11,] 1 5.4
[12,] 1 4.8
[13,] 1 4.8
[14,] 1 4.3
[15,] 3 5.8
[16,] 2 5.7
[17,] 1 5.4
[18,] 1 5.1
[19,] 2 5.7
[20,] 1 5.1
这样就完成了卡方分箱的操作,接下来的其他几个函数的使用,与chiM()的算法类似,就不再过多讨论了。
3.4 其他算法
chi2()算法,查看分组阈值。
> chi2<-chi2(iris,alp=0.5,del=0.05)
> chi2$cutp
[[1]]
[1] 3.5 4.5 6.5
[[2]]
[1] 3.5 4.5
[[3]]
[1] 1.5 2.5 3.5
[[4]]
[1] 1.5 3.5
modChi2()算法,查看分组阈值。
> chi3<-modChi2(iris,alp=0.5)
> chi3$cutp
[[1]]
[1] 1.5 2.5
[[2]]
[1] 2.5
[[3]]
[1] 1.5 2.5
[[4]]
[1] 1.5 2.5
extendChi2()算法,查看分组阈值。
> chi4<-extendChi2(iris,alp = 0.5)
> chi4$cutp
[[1]]
[1] 1.5 2.5
[[2]]
[1] 1.5 2.5
[[3]]
[1] 1.5 2.5
[[4]]
[1] 1.5 2.5
> m1<-mdlp(iris)
> m1$cutp
[[1]]
[1] 5.55 6.15
[[2]]
[1] 2.95 3.35
[[3]]
[1] 2.45 4.75
[[4]]
[1] 0.80 1.75
disc.Topdown()算法,查看分组阈值。
> d1<-disc.Topdown(iris,method=1)
> d1$cutp
[[1]]
[1] 4.30 5.55 6.25 7.90
[[2]]
[1] 2.00 2.95 3.05 4.40
[[3]]
[1] 1.00 2.45 4.75 6.90
[[4]]
[1] 0.10 0.80 1.75 2.50
最后,分箱需要注意的是,分完箱之后,某些箱区间里可能数据分布比例极不均匀,那么这样子会直接导致后续计算WOE时出现inf无穷大的情况,这是不合理的。这种情况,说明分箱太细,需要进一步缩小分箱的数量。
本文详细地介绍了无监督的离散化方法和有监督的离散化方法,针对不同的场景,我们可以选择不同的方法进行使用。R语言中,包提供了各种离散化的工具函数,使用起来很方便,可以大幅提供数据处理过程的效率。
转载请注明出处:
http://blog.fens.me/r-discretization
