R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-rpostgressql/

前言
PostgreSQL和R通常可以一起用于数据分析,PostgreSQL作为数据库引擎,R作为统计工具。在R语言中,有2个包可以直接通过R连接PostgreSQL数据库,分别是RPostgreSQL包和RPostgres包,本文将先介绍用RPostgreSQL包进行直接连接PostgreSQL数据库。间接的连接方法还有RJDBC,RODBC等,以后再有专门的文章进行介绍。
PostgreSQL的数据库安装和基本信息,请参考文章在Ubuntu上安装PostgreSQL
目录
- RPostgreSQL包介绍
- 安装RPostgreSQL包
- RPostgreSQL包的API使用
- window客户端环境的中文乱码解决方案
1. RPostgreSQL包介绍
RPostgreSQL一个R语言程序包,由官方提供访问 PostgreSQL数据库的R语言接口程序,RPostgreSQL主要依赖于DBI项目,以访问 PostgreSQL 数据库系统。CRAN中的项目地址
https://cran.r-project.org/web/packages/RPostgreSQL/index.html
2. 安装RPostgreSQL包
RPostgreSQL包的安装过程非常简单,就是一条语句就能够搞定了,不管是在Window环境还是Linux环境。
在Linux Ubuntu中,需要先安装libpq-dev系统库,不然会出现libpq-fe.h错误
In file included from RS-PQescape.c:7:
RS-PostgreSQL.h:23:14: fatal error: libpq-fe.h: No such file or directory
23 | # include "libpq-fe.h"
| ^~~~~~~~~~~~
安装libpq-dev系统库
~ sudo apt install libpq-dev
安装和加载RPostgreSQL包
> install.packages("RPostgreSQL")
> library(RPostgreSQL)
3. RPostgreSQL包的API使用
RPostgreSQL包,提供了很多的API函数,API的使用过程,我们可以分成6个部分来介绍。
- 3.1 数据库连接
- 3.2 数据库状态查看
- 3.3 数据直接查询
- 3.4 数据交互查询
- 3.5 数据批量插入
- 3.6 事务处理
3.1 建立数据库链接
# 加载PostgreSQL驱动
> drv = dbDriver("PostgreSQL")
# 建立数据库连接
> con1 = dbConnect(drv, dbname="testdb",user = "test", password = "test", host ="192.168.1.5")
3.2 数据库状态查看
# 再建立2个数据库连接
> con2 = dbConnect(drv, dbname="testdb",user = "test", password = "test", host ="192.168.1.5")
> con3 = dbConnect(drv, dbname="testdb",user = "test", password = "test", host ="192.168.1.5")
查看驱动状态
> dbGetInfo(drv)
$drvName
[1] "PostgreSQL"
$connectionIds # 连接1
$connectionIds[[1]]
<postgresqlconnection>
$connectionIds[[2]] # 连接2
<postgresqlconnection>
$connectionIds[[3]] # 连接3
<postgresqlconnection>
$fetch_default_rec
[1] 500
$managerId
<postgresqldriver>
$length
[1] 16
$num_con
[1] 3
$counter
[1] 9
查看con1数据连接状态
> dbGetInfo(con1)
$host
[1] "192.168.1.5"
$port
[1] "5432"
$user
[1] "test"
$dbname
[1] "testdb"
$serverVersion
[1] "12.0.4"
$protocolVersion
[1] 3
$backendPId
[1] 27263
$rsId
list()
关闭连接
# 关闭连接1
> dbDisconnect(con1)
[1] TRUE
# 查看con1状态
> isPostgresqlIdCurrent(con1)
[1] FALSE
# 查睦con1信息
> dbGetInfo(con1)
Error in postgresqlConnectionInfo(dbObj, ...) :
expired PostgreSQLConnection dbObj
关闭全部连接
# 通过循环关闭全部连接
> for(con in dbListConnections(drv)){
+ dbDisconnect(con)
+ }
# 查询驱动状态,没有活动连接
> dbGetInfo(drv)
$drvName
[1] "PostgreSQL"
$connectionIds # 没有活动连接
list()
$fetch_default_rec
[1] 500
$managerId
<postgresqldriver>
$length
[1] 16
$num_con
[1] 0
$counter
[1] 9
3.3 数据直接查询
数据直接查询可以通过直接读取整个表数据dbReadTable()函数,或者执行查询语句dbGetQuery()函数来实现。
建立新连接
> con1 = dbConnect(drv, dbname="testdb",user = "test", password = "test", host ="192.168.1.5")
查看数据库中,所有的表。
# 所有表的列表
> dbListTables(con1)
[1] "account" "iris"
# 确认表名是否存在
> dbExistsTable(con1,"iris")
[1] TRUE
通过表名,读取整个表的数据
> dbReadTable(con1,"iris")
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
通过SQL语句,读取表中的数据
> dbGetQuery(con1, "SELECT * FROM iris")
row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
3.4 数据交互查询
数据交互查询,可以通过发送一条sql请求dbSendQuery()函数来实现,返回数据访问句柄,再用dbFetch()函数来分批次获取数据。
# 发送SQL
> rs = dbSendQuery(con1, statement = "SELECT * FROM iris")
# 判断rs句柄是否完成
> dbHasCompleted(rs)
[1] FALSE
# 取数据n=-1时,取全表数据
> dbFetch(rs,n=-1)
row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
# 判断rs句柄是否完成
> dbHasCompleted(rs)
[1] TRUE
# 取完数据后,句柄rs就失效了
> dbFetch(rs,n=1)
data frame with 0 columns and 0 rows
我们在获得句柄后,可以查到关于句柄的详细信息。
# 发送SQL,获得句柄rs
> rs = dbSendQuery(con1, statement = "SELECT * FROM iris")
# 查看rs信息
> dbGetInfo(rs)
$statement
[1] "SELECT * FROM iris"
$isSelect
[1] 1
$rowsAffected
[1] -1
$rowCount
[1] 0
$completed
[1] 0
$fieldDescription
$fieldDescription[[1]]
$fieldDescription[[1]]$name
[1] "row.names" "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
$fieldDescription[[1]]$Sclass
[1] 16 14 14 14 14 16
$fieldDescription[[1]]$type
[1] 25 701 701 701 701 25
$fieldDescription[[1]]$len
[1] -1 8 8 8 8 -1
$fieldDescription[[1]]$precision
[1] -1 -1 -1 -1 -1 -1
$fieldDescription[[1]]$scale
[1] -1 -1 -1 -1 -1 -1
$fieldDescription[[1]]$nullOK
[1] TRUE TRUE TRUE TRUE TRUE TRUE
# 查看执行SQL语句
> dbGetStatement(rs)
[1] "SELECT * FROM iris"
# 查看数据结构
> dbColumnInfo(rs)
name Sclass type len precision scale nullOK
1 row.names character TEXT -1 -1 -1 TRUE
2 Sepal.Length double FLOAT8 8 -1 -1 TRUE
3 Sepal.Width double FLOAT8 8 -1 -1 TRUE
4 Petal.Length double FLOAT8 8 -1 -1 TRUE
5 Petal.Width double FLOAT8 8 -1 -1 TRUE
6 Species character TEXT -1 -1 -1 TRUE
# 查看已获取的行
> dbGetRowCount(rs)
[1] 0
# 获取2行
> ret1 <- dbFetch(rs, 2)
> ret1
row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
# 查看已获取的行
> dbGetRowCount(rs)
[1] 2
# 查看句柄是否完成
> dbHasCompleted(rs)
[1] FALSE
# 获取剩余的行
> ret2 <- dbFetch(rs, -1)
> ret2
row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
# 查看句柄是否完成
> dbHasCompleted(rs)
[1] TRUE
# 清空rs句柄
> dbClearResult(rs)
[1] TRUE
# 拼接完整数据集
> rbind(ret1,ret2)
row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
3.5 数据批量插入
R语言中,数据组织方式是用data.frame的,data.frame可以批量地进行数据操作,在操作数据库时,我们也可以直接用data.frame与PostgreSQL数据库进行这种批量的操作。
当数据库没表时,dbWriteTable()函数会新建一个数据表。
# 新建数据表iris-table,插入5条数据
> dbWriteTable(con1,'iris-table',iris[1:5,])
[1] TRUE
# 读取数据表
> dbReadTable(con1,'iris-table')
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
再进行数据表插入,由于表已存在,所以提示不能插入,如果需求追加插入时,可以增加append的合并参数。
# 插入数据失败
> dbWriteTable(con1,'iris-table',iris[6:10,])
[1] FALSE
Warning message:
In postgresqlWriteTable(conn, name, value, ...) :
table iris-table exists in database: aborting assignTable
# 追加插入数据
> dbWriteTable(con1,'iris-table',iris[6:10,],append=TRUE)
[1] TRUE
# 查看数据表,变成了10行。
> dbReadTable(con1,'iris-table')
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
当表不需要后,可以直接删除数据表
# 删除数据表
> dbRemoveTable(con1,"iris-table")
[1] TRUE
# 删除后,数据表读取失败
> dbReadTable(con1,'iris-table')
Error in postgresqlExecStatement(conn, statement, ...) :
RS-DBI driver: (could not Retrieve the result : ERROR: relation "iris-table" does not exist
LINE 1: SELECT * from "iris-table"
^
)
Error in names(out) <- make.names(names(out), unique = TRUE) :
NULL是不能有属性的
此外: Warning message:
In postgresqlQuickSQL(conn, statement, ...) :
Could not create execute: SELECT * from "iris-table"
3.6 事务提交和回滚
RPostgreSQL包的事务控制,是通过dbSendQuery()函数,配合事务控制dbBegin()函数,dbRollback()函数,dbCommit()函数来完成的。
我们模拟一个事务的场景,当删除一条数据时,判断这条数据影响多少行,如果删除超过1行则不执行删除进行回滚,如果正好为1行,则进行删除。
# 查看数据集,共5行
> df1<-dbGetQuery(con1, "select * from iris");df1
row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
# 开始事务
> dbBegin(con1)
[1] TRUE
# 进行删除
> rs <- dbSendQuery(con1, "Delete from iris where \"Species\" = 'setosa'")
# 删除判断,影响大于1行则回滚,
> if(dbGetInfo(rs, what = "rowsAffected") > 1){
+ warning("Rolling back transaction")
+ dbRollback(con1)
+ }else{
+ dbCommit(con1)
+ }
[1] TRUE
Warning message:
Rolling back transaction # 进行回滚
# 再查询数据表结果,未发生删除
> dbGetQuery(con1, "select count(*) from iris")
count
1 5
4. window客户端环境的中文乱码解决方案
执行查询,出现中文乱码。我们就需要逐步排查,到底是哪个环节产生了乱码,统一把编码以UTF-8做为编码标准。
# 创建中文data.frame
> acc<-data.frame(
+ user_id=1:3,
+ useranme=c("a1","小明","粉丝日志"),
+ password=c("678fdaiufda","jfdaked21+_~!","E!SM<I*")
+ )
# 建表,插入数据
> dbWriteTable(con1,"acc",acc)
[1] TRUE
# 读取数据
> df3<-dbReadTable(con1,"acc");df3
user_id useranme password
1 1 a1 678fdaiufda
2 2 灏忔槑 jfdaked21+_~!
3 3 绮変笣鏃ュ織 E!SM<I*
我们插入的是正确,但读出来的数据是乱码。我们用pgadmin客户端,检查一下数据表,验证一下数据库中数据是否显示正常。
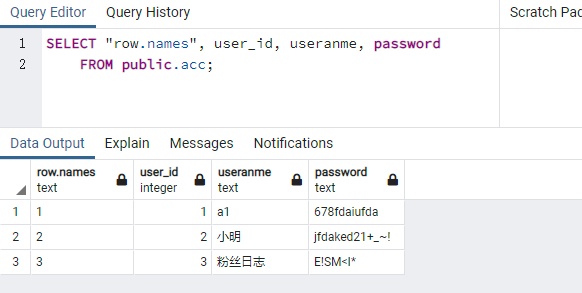
接下来,再检查一下PostgreSQL数据库中testdb库的编码为UTF8。
在服务器上,启动psql查询客户端。
# 启动psql客户端
~ sudo -u postgres psql
# 检查数据库
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/postgres +
| | | | | postgres=CTc/postgres+
| | | | | test=CTc/postgres
(4 rows)
再检查一下,客户端通信的字符编码,也是UTF8是正常的。
> dbGetQuery(con1, "SHOW CLIENT_ENCODING")
client_encoding
1 UTF8
最后,考虑到Windows环境下,R的客户端默认编码为GBK,所以我们再试一下,把数据在R中进行编码转型。
# 字符编码转型
> df3a <- as.data.frame(apply(df3, 2, function(x){
+ iconv(x, 'UTF-8', 'GBK')
+ }))
# 查看输出结果
> df3a
user_id useranme password
1 1 a1 678fdaiufda
2 2 小明 jfdaked21+_~!
3 3 粉丝日志 E!SM<I*
这样就可以解决了,中文乱码的问题了。
我们已经完成,掌握了RPostgreSQL包的各种使用技巧,希望大家理解原理后,能少犯错误,提高工作效率!
转载请注明出处:
http://blog.fens.me/r-postgressql/
