R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者
- 张丹,数据分析师/程序员/Quant: R,Java,Nodejs
- blog: http://fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-timetk/
前言
时间序列分析,是统计分析一个重要的分支,我们日常生活的很多数据,都是时间序列数据,至少包含一个时间项和数据值。如果能很好地观察时间序列数据,对于我们理解数据能起到非常重要的作用。
timetk就是一个非常方便地观察时间序列数据的包,从多个角度让我们快速理解数据。
目录
- timetk包是介绍
- timetk的安装
- timetk的核心函数
- 可视化:基本时间序列图
- 可视化:时间序列分组
- 可视化:时间序列分箱
- 可视化:时间序列回归
- 可视化:时间序列异常检测
- 可视化:时间序列季节性分解
- 可视化:时间序列重采样
1. timetk包是介绍
timetk是R语言的一个时间序列处理工具包,可轻松实现时间序列数据的可视化、整理和特征工程,用于预测和机器学习建模。整合并扩展了包括 dplyr、stats、xts、forecast、slider、padr、recipes 和 rsample 等包中的时间序列功能。Timetk 是一个功能强大的包,属于 modeltime 生态系统的一部分,用于时间序列分析和预测。
官方网站:https://business-science.github.io/timetk/
timetk 包让用户在 R 语言中更便捷地处理时间序列对象。该工具包提供了用于检查和处理基于时间的索引、扩展用于数据挖掘和机器学习的时间特征,以及在不同时间序列类之间进行转换的功能。
主要优势如下:
- 索引提取:从任意时间序列对象中提取时间序列索引。
- 时间序列理解:基于时间序列索引生成特征摘要和汇总信息。
- 构建未来时间序列:根据已有索引创建未来时间序列。
- 基于时间的tibble类型与主流时间序列数据类型(xts、zoo、zooreg、ts)之间的相互转换:简化转换过程,并在转换为规则时间序列(如 ts)时最大程度保留基于时间的数据信息。
2. timetk的安装
timetk包的安装,安装timetk包非常简单,2条命令就可以完成,安装和加载。
# 安装
> install.packages("timetk")
# 加载
> library(timetk)
3. timetk的核心函数
使用timetk包,可以针对不同R语言时间序列类型做适配,如tk_tbl()适配tibble类型, tk_zoo()适配zoo类型,tk_xts()适配xts类型等。
timetk包中最核心的函数就是画图函数,支持11种可视化的画图效果。
- plot_time_series 一个或多个时间序列的交互式绘图
- plot_time_series_boxplot 交互式时间序列箱线图
- plot_time_series_regression 可视化时间序列线性回归公式
- plot_anomalies 可视化一个或多个时间序列的异常值
- plot_anomalies_cleaned 可视化一个或多个时间序列的异常值(清理后)
- plot_anomalies_decomp 可视化一个或多个时间序列的异常值(分解后)
- plot_anomaly_diagnostics 可视化一个或多个时间序列的异常值诊断
- plot_seasonal_diagnostics 可视化一个或多个时间序列的多种季节性特征
- plot_stl_diagnostics 可视化一个或多个时间序列的 STL 分解特征
- plot_acf_diagnostics 可视化一个或多个时间序列的 ACF、PACF 和 CCF
- plot_time_series_cv_plan 可视化时间序列重采样方案
4. 可视化:基本时间序列图
以timetk包自带的数据集taylor_30_min为例,taylor_30_min数据集。为半小时电力需求,2000年6月5日星期一至2000年8月27日星期日期间英格兰和威尔士的半小时电力需求。
taylor_30_min数据集为 tibble类型, 4,032 行 × 2 列:
- date:日期时间变量,间隔为 30 分钟
- value:电力需求,单位为兆瓦
查看数据情况
# 查看数据前6条
> head(taylor_30_min)
# A tibble: 6 × 2
date value
1 2000-06-05 00:00:00 22262
2 2000-06-05 00:30:00 21756
3 2000-06-05 01:00:00 22247
4 2000-06-05 01:30:00 22759
5 2000-06-05 02:00:00 22549
6 2000-06-05 02:30:00 22313
# 查看数据2列统计概览
> summary(taylor_30_min)
date value
Min. :2000-06-05 00:00:00 Min. :18640
1st Qu.:2000-06-25 23:52:30 1st Qu.:24272
Median :2000-07-16 23:45:00 Median :29485
Mean :2000-07-16 23:45:00 Mean :29617
3rd Qu.:2000-08-06 23:37:30 3rd Qu.:35132
Max. :2000-08-27 23:30:00 Max. :38777
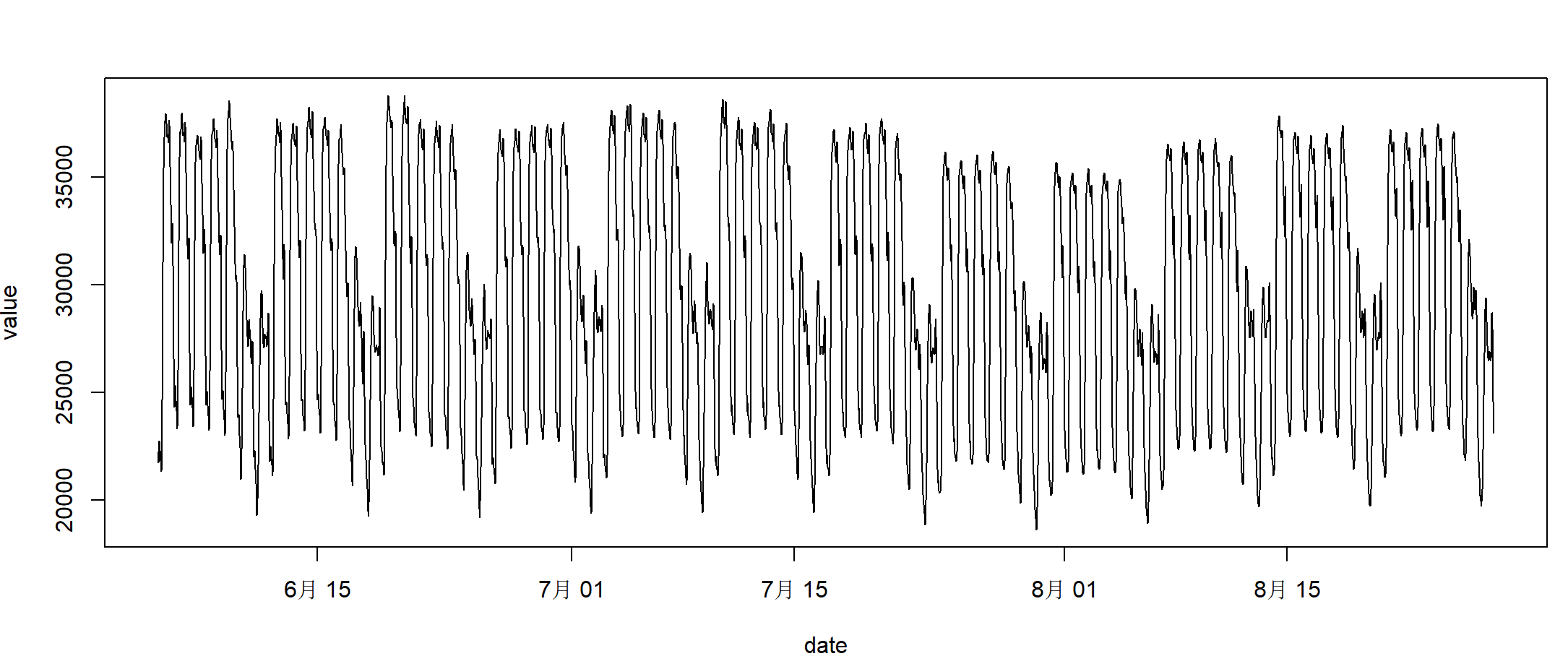
基于数据画图,使用基本plot()函数画图。
> plot(taylor_30_min,type="l")
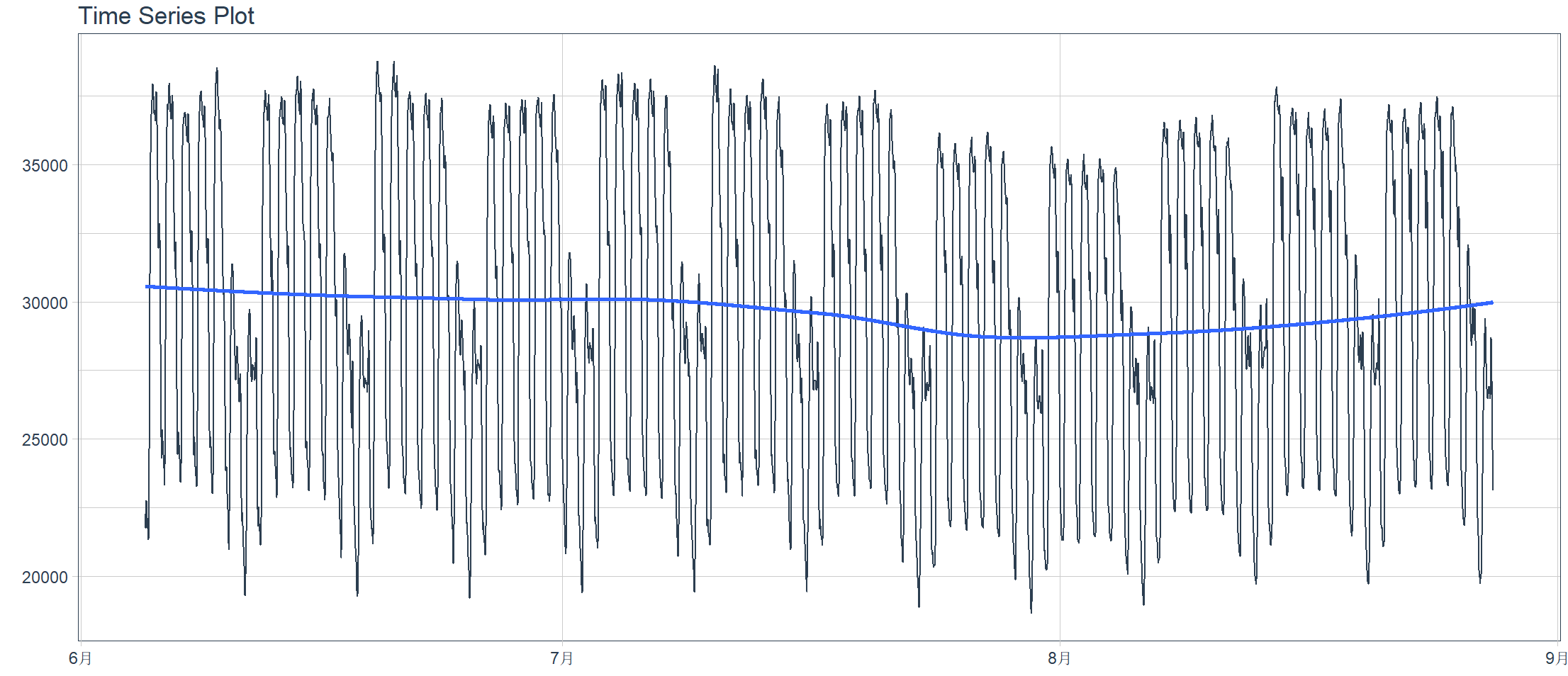
使用timetk画图,并进行数据拟合
# 加载包
> library(dplyr)
> library(ggplot2)
> library(lubridate)
> library(magrittr)
# 生成基于ggplot2的静态图
> interactive <- FALSE # 画图拟合 > taylor_30_min %>%
+ plot_time_series(date, value,
+ .interactive = interactive,
+ .plotly_slider = TRUE)
Ignoring unknown labels:
• colour : "Legend"
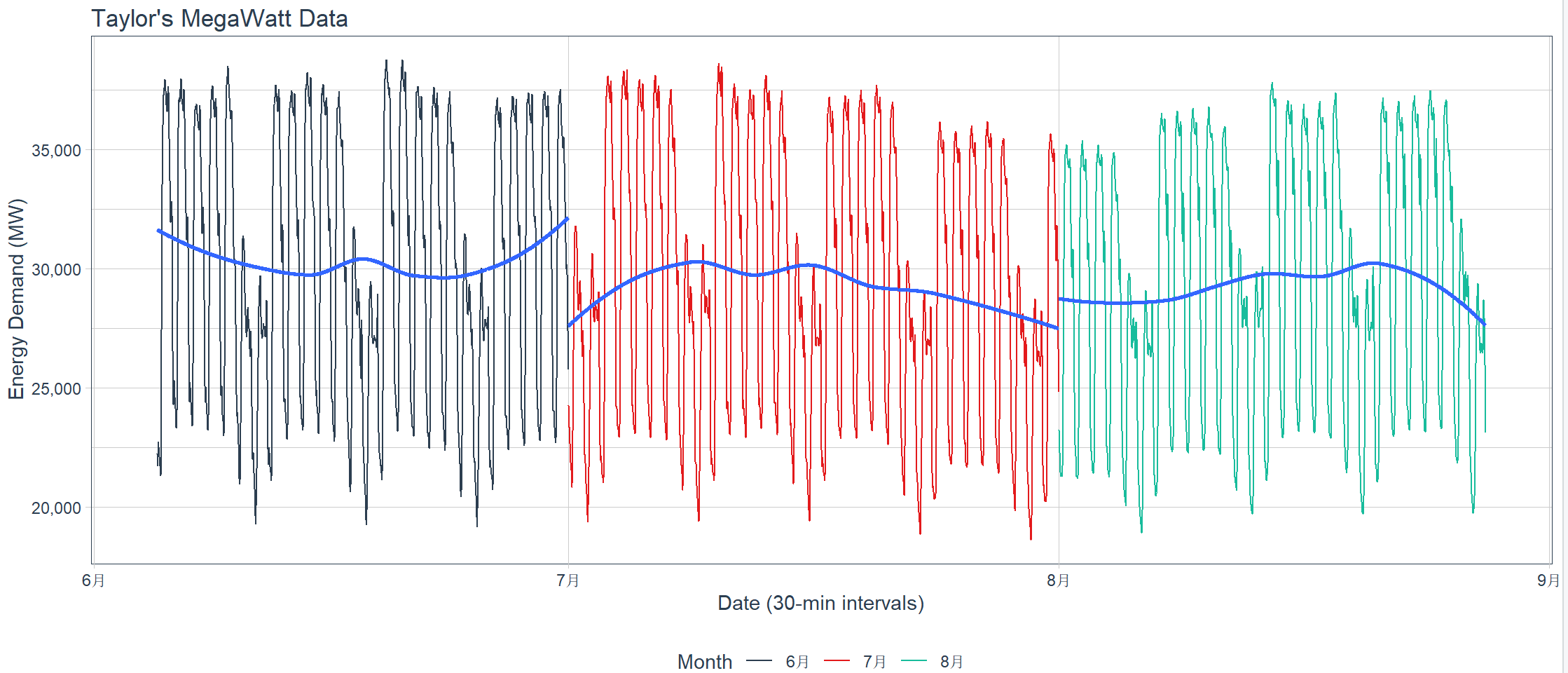
按月度进行数据拆分拟合
# 画图拟合
> taylor_30_min %>%
+ plot_time_series(date, value,
+ .color_var = month(date, label = TRUE),
+ .interactive = interactive,
+ .title = "Taylor's MegaWatt Data",
+ .x_lab = "Date (30-min intervals)",
+ .y_lab = "Energy Demand (MW)",
+ .color_lab = "Month") +
+ scale_y_continuous(labels = scales::label_comma())
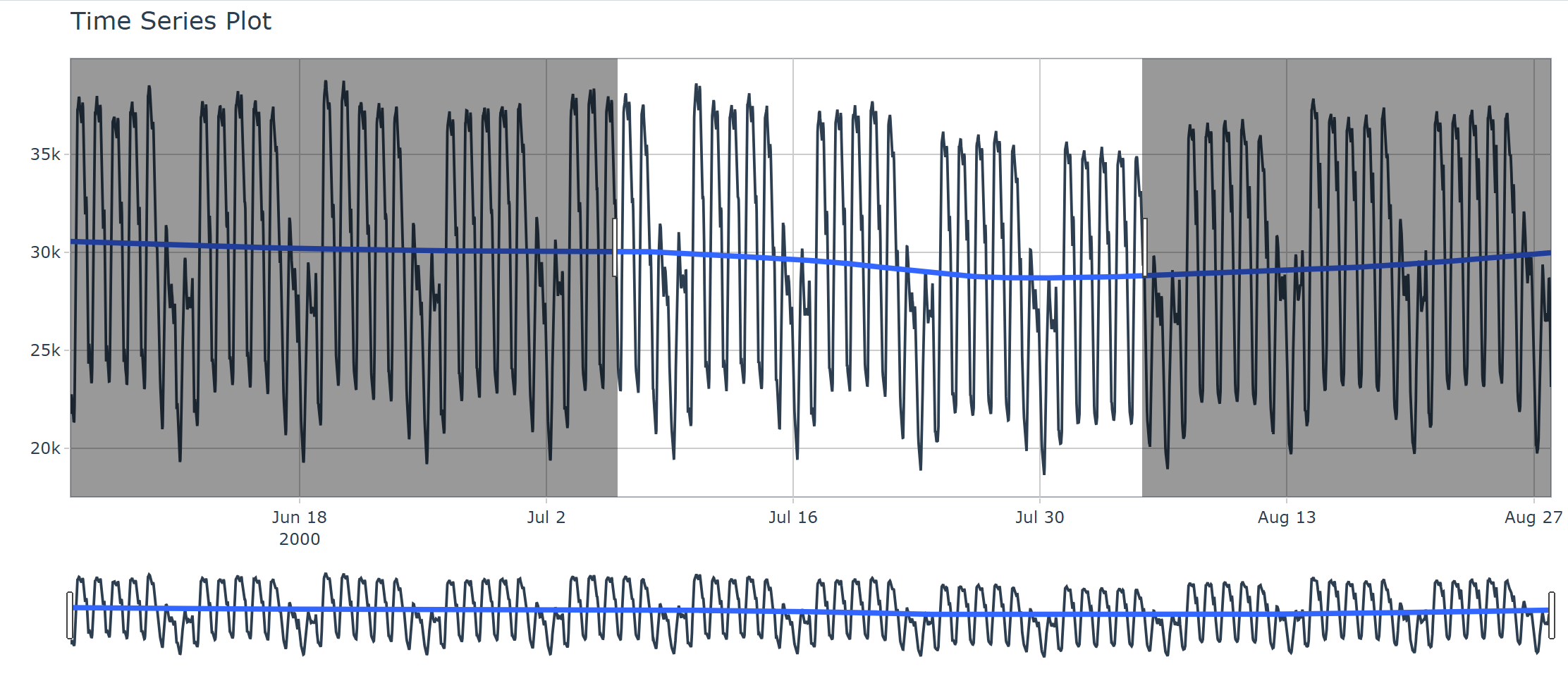
使用可交互的画图输出, interactive=TRUE。可生成基于plotly的动态交互的结果。
> taylor_30_min %>%
+ plot_time_series(date, value,
+ .interactive = TRUE,
+ .plotly_slider = TRUE)
Ignoring unknown labels:
• colour : "Legend"
5. 可视化:时间序列分组
1. 分组展示
我们再换一组数据集m4_daily,进行演示测试。m4_daily数据集来源:M4 竞赛(2018 年 1 月 – 5 月),完整竞赛总序列数:100,000 条,本样本:4 条日度时间序列,行数:9,743,列:id、date、value。
- id 因子型 4 条序列各自的唯一标识符
- date 日期型 每日时间戳
- value 数值型 对应时间戳的数值
由于这些数据来自 M4 竞赛,每条序列很可能来自不同的领域(例如微观、工业、宏观、金融、人口统计等),并可能表现出:趋势,季节性(周度、年度),异方差性,零值或间歇性数值,不同长度(日度序列的历史数据长度往往各不相同)。
# 查看数据集
> head(m4_daily)
# A tibble: 6 × 3
id date value
1 D10 2014-07-03 2076.
2 D10 2014-07-04 2073.
3 D10 2014-07-05 2049.
4 D10 2014-07-06 2049.
5 D10 2014-07-07 2006.
6 D10 2014-07-08 2018.
# 统计概览
> summary(m4_daily)
id date value
D10 : 674 Min. :1978-06-23 Min. : 1735
D160:4197 1st Qu.:2003-01-12 1st Qu.: 5719
D410: 676 Median :2006-05-14 Median : 8253
D500:4196 Mean :2005-02-14 Mean : 8280
3rd Qu.:2009-09-13 3rd Qu.:11219
Max. :2016-05-06 Max. :19433
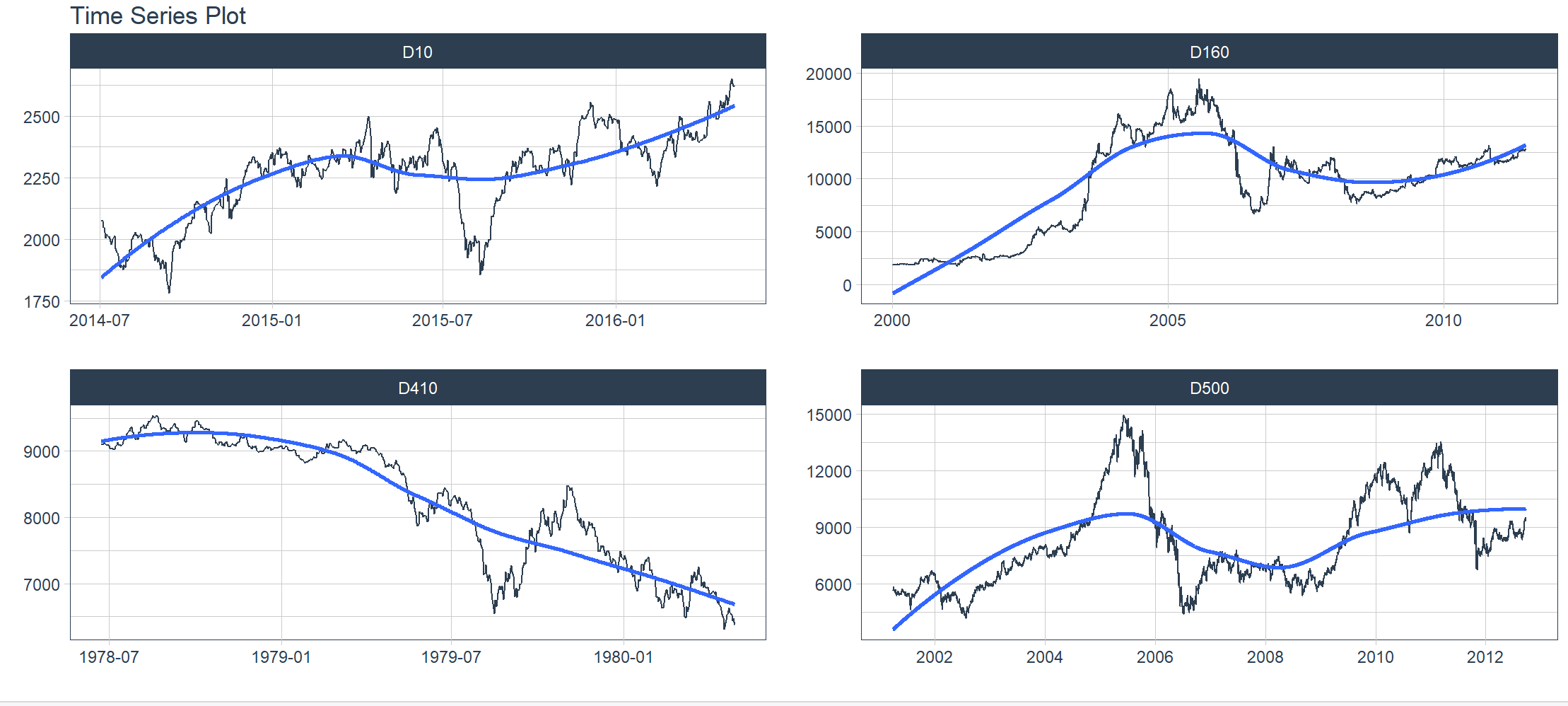
分组数据的可视化只需在将数据传入 plot_time_series() 函数之前使用 group_by() 对数据集进行分组即可。关键点如下:
- 可以通过两种方式添加分组:使用 group_by(),或通过 … 参数添加分组。
- 分组随后会转换为分面图。
- .facet_ncol = 2 生成一个两列的分面图。
- .facet_scales = “free” 允许每个图的 x 轴和 y 轴独立于其他图进行缩放。
> m4_daily %>%
+ group_by(id) %>%
+ plot_time_series(date, value,
+ .facet_ncol = 2, .facet_scales = "free",
+ .interactive = interactive)
Ignoring unknown labels:
• colour : "Legend"
2. 对数变换与子分组
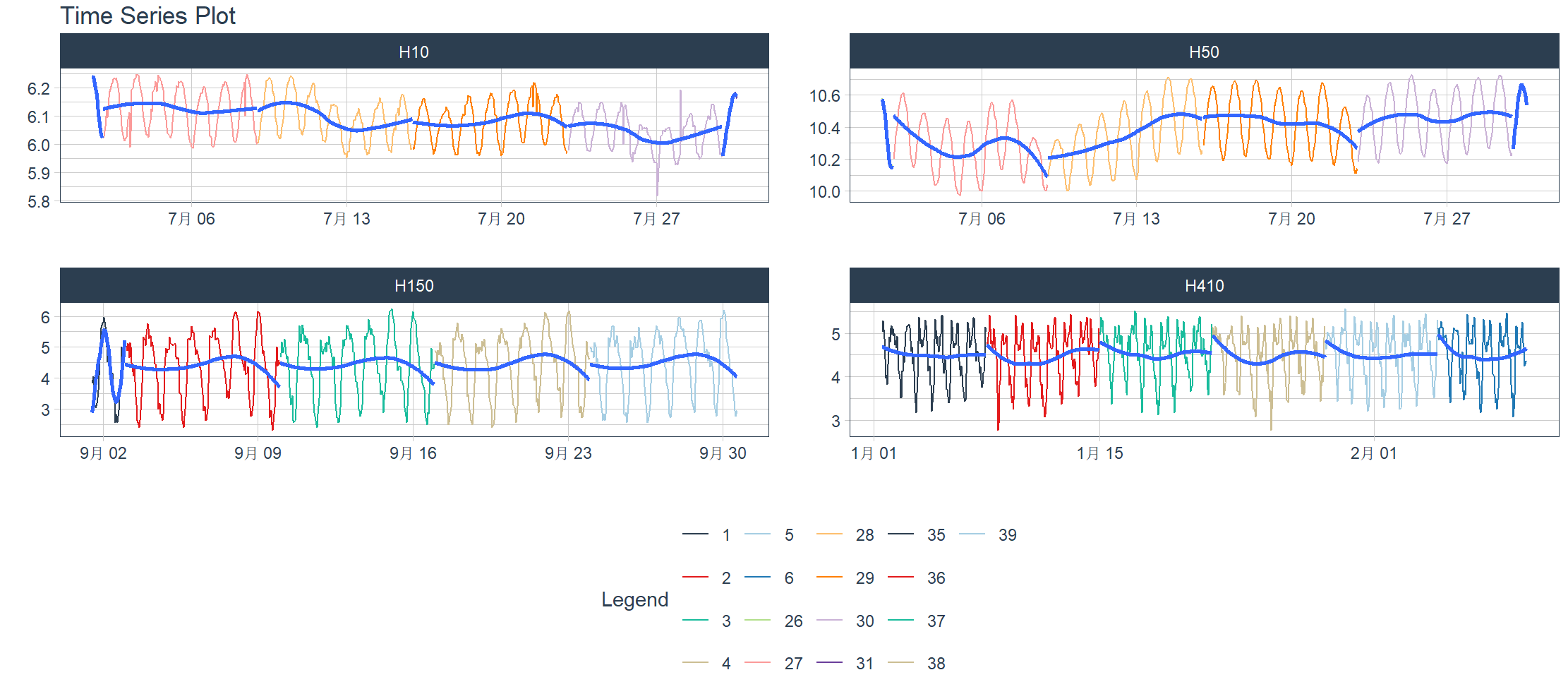
让我们切换到一个包含多个分组的小时级数据集。我们可以展示以下内容。其意图是在分面图中展示分组,同时突出数据中的每周窗口(子分组),并对数值进行 log() 变换。
- .value = log(value):应用对数变换
- .color_var = week(date):将日期列转换为 lubridate::week() 的周数,颜色将应用于每个周数。
换成m4_hourly,M4 竞赛始于 2018 年 1 月 1 日,于 2018 年 5 月 31 日结束。该竞赛包含 100,000 个时间序列数据集。本数据集包含来自该竞赛的 4 个小时度时间序列样本。
> m4_hourly %>%
+ group_by(id) %>%
+ plot_time_series(date, log(value), # Apply a Log Transformation
+ .color_var = week(date), # Color applied to Week transformation
+ # Facet formatting
+ .facet_ncol = 2,
+ .facet_scales = "free",
+ .interactive = interactive)
6. 可视化:时间序列分箱
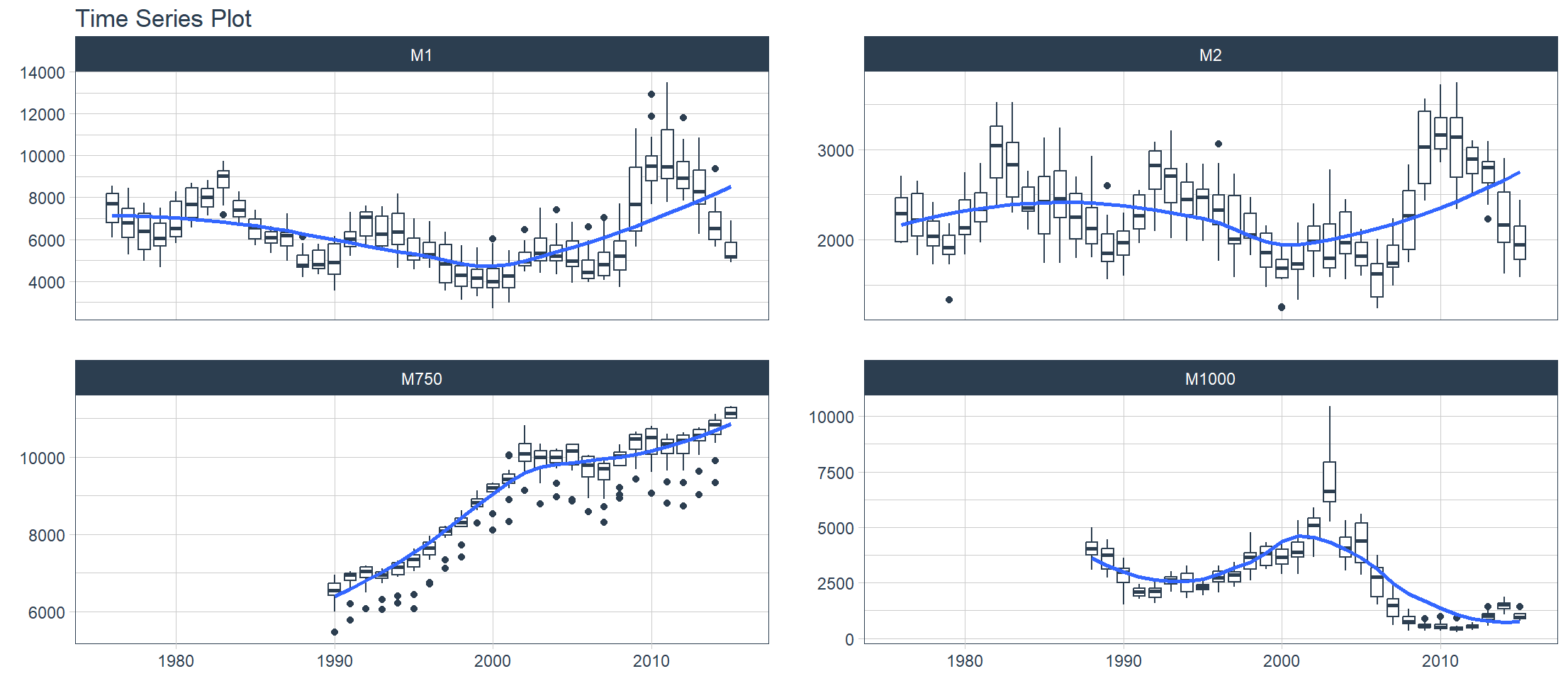
plot_time_series_boxplot() 函数可用于绘制箱线图。箱线图使用聚合方式,这是由 .period 参数定义的分箱参数。
换成m4_monthly,M4 竞赛始于 2018 年 1 月 1 日,于 2018 年 5 月 31 日结束。该竞赛包含 100,000 个时间序列数据集。本数据集包含来自该竞赛的 4 个月度时间序列样本。
> m4_monthly %>%
+ group_by(id) %>%
+ plot_time_series_boxplot(
+ date, value,
+ .period = "1 year",
+ .facet_ncol = 2,
+ .interactive = FALSE)
Ignoring unknown labels:
• colour : "Legend"
7. 可视化:时间序列回归
使用时间序列回归图函数 plot_time_series_regression() 可用于快速评估与时间序列相关的关键特征。该函数内部会将一个公式传递给 stats::lm() 函数。通过设置 show_summary = TRUE,可以输出线性回归的摘要信息。
换成m4_monthly数据画图
> m4_monthly %>%
+ group_by(id) %>%
+ plot_time_series_regression(
+ .date_var = date,
+ .formula = log(value) ~ as.numeric(date) + month(date, label = TRUE),
+ .facet_ncol = 2,
+ .interactive = FALSE,
+ .show_summary = FALSE
+ )
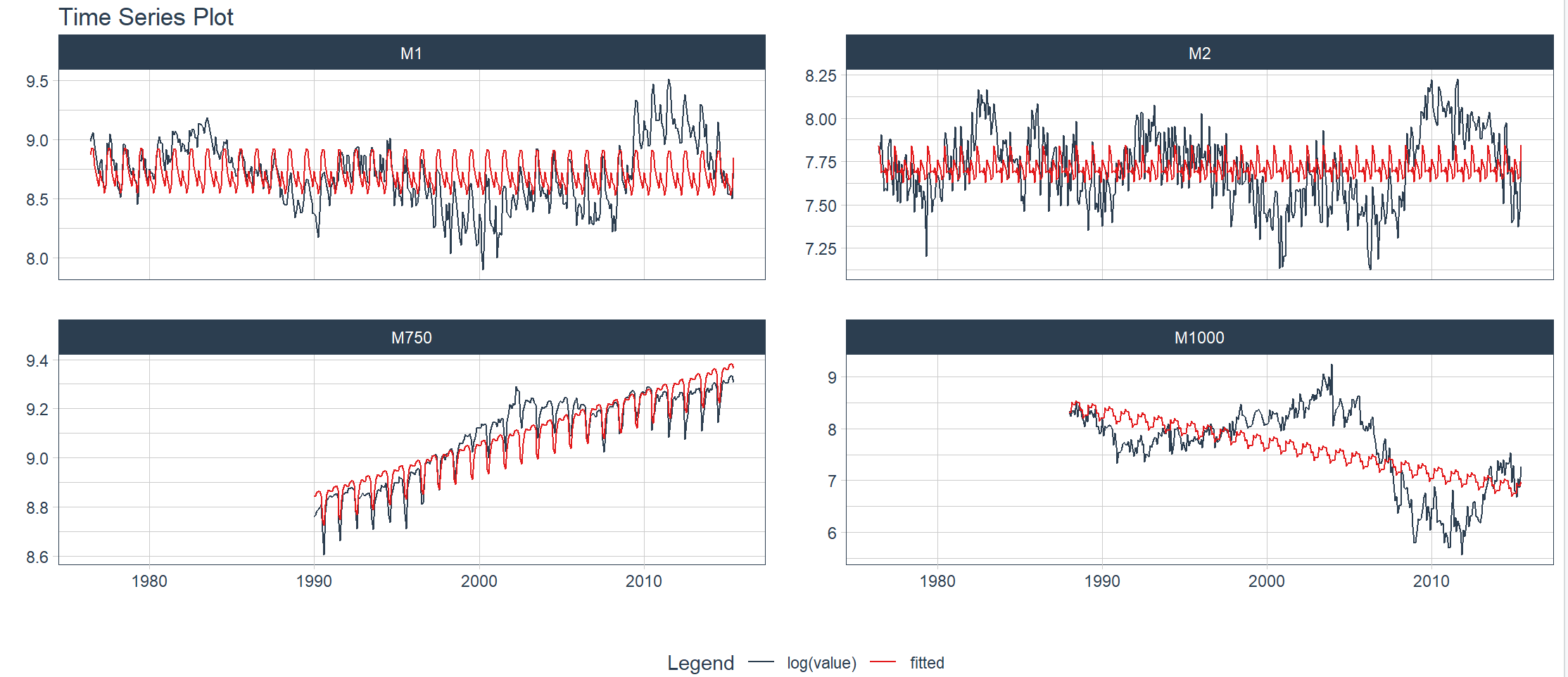
8. 可视化:时间序列异常检测
使用walmart_sales_weekly数据集, 可视化一个或多个时间序列的异常值。
walmart_sales_weekly数据集,沃尔玛招聘——门店销售额预测”竞赛使用了零售数据,涉及门店与店内各个部门的组合。该竞赛于2014年2月20日开始,于2014年5月5日结束。竞赛数据包含位于不同地区的45家零售门店。数据集包含多种外部特征,包括节假日信息、气温、燃油价格和降价信息。本数据集包含门店ID为1的7个部门的样本(共7个时间序列)。
查看数据walmart_sales_weekly
# 查看数据
> head(walmart_sales_weekly)
# A tibble: 6 × 17
id Store Dept Date Weekly_Sales IsHoliday Type Size Temperature Fuel_Price MarkDown1 MarkDown2 MarkDown3 MarkDown4
1 1_1 1 1 2010-02-05 24924. FALSE A 151315 42.3 2.57 NA NA NA NA
2 1_1 1 1 2010-02-12 46039. TRUE A 151315 38.5 2.55 NA NA NA NA
3 1_1 1 1 2010-02-19 41596. FALSE A 151315 39.9 2.51 NA NA NA NA
4 1_1 1 1 2010-02-26 19404. FALSE A 151315 46.6 2.56 NA NA NA NA
5 1_1 1 1 2010-03-05 21828. FALSE A 151315 46.5 2.62 NA NA NA NA
6 1_1 1 1 2010-03-12 21043. FALSE A 151315 57.8 2.67 NA NA NA NA
# ℹ 3 more variables: MarkDown5 , CPI , Unemployment
# 统计概览
> summary(walmart_sales_weekly)
id Store Dept Date Weekly_Sales IsHoliday Type
1_1 :143 Min. :1 Min. : 1.00 Min. :2010-02-05 Min. : 6166 Mode :logical Length:1001
1_3 :143 1st Qu.:1 1st Qu.: 3.00 1st Qu.:2010-10-08 1st Qu.: 28257 FALSE:931 Class :character
1_8 :143 Median :1 Median :13.00 Median :2011-06-17 Median : 39886 TRUE :70 Mode :character
1_13 :143 Mean :1 Mean :35.86 Mean :2011-06-17 Mean : 54646
1_38 :143 3rd Qu.:1 3rd Qu.:93.00 3rd Qu.:2012-02-24 3rd Qu.: 77944
1_93 :143 Max. :1 Max. :95.00 Max. :2012-10-26 Max. :148798
(Other):143
Size Temperature Fuel_Price MarkDown1 MarkDown2 MarkDown3 MarkDown4
Min. :151315 Min. :35.40 Min. :2.514 Min. : 410.3 Min. : 0.50 Min. : 0.25 Min. : 8.0
1st Qu.:151315 1st Qu.:57.79 1st Qu.:2.759 1st Qu.: 4039.4 1st Qu.: 40.48 1st Qu.: 6.00 1st Qu.: 577.1
Median :151315 Median :69.64 Median :3.290 Median : 6154.1 Median : 144.87 Median : 25.96 Median : 1822.5
Mean :151315 Mean :68.31 Mean :3.220 Mean : 8090.8 Mean : 2941.32 Mean : 1225.40 Mean : 3746.1
3rd Qu.:151315 3rd Qu.:80.49 3rd Qu.:3.594 3rd Qu.:10122.0 3rd Qu.: 1569.00 3rd Qu.: 101.64 3rd Qu.: 3750.6
Max. :151315 Max. :91.65 Max. :3.907 Max. :34577.1 Max. :46011.38 Max. :55805.51 Max. :32403.9
NA's :644 NA's :707 NA's :651 NA's :644
MarkDown5 CPI Unemployment
Min. : 554.9 Min. :210.3 Min. :6.573
1st Qu.: 3127.9 1st Qu.:211.5 1st Qu.:7.348
Median : 4325.2 Median :215.5 Median :7.787
Mean : 5018.7 Mean :216.0 Mean :7.610
3rd Qu.: 6222.2 3rd Qu.:220.6 3rd Qu.:7.838
Max. :20475.3 Max. :223.4 Max. :8.106
NA's :644
> walmart_sales_weekly %>%
+ filter(id %in% c("1_1", "1_3")) %>%
+ group_by(id) %>%
+ anomalize(Date, Weekly_Sales) %>%
+ plot_anomalies(Date, .facet_ncol = 2, .ribbon_alpha = 0.25, .interactive = FALSE)
frequency = 13 observations per 1 quarter
trend = 52 observations per 1 year
frequency = 13 observations per 1 quarter
trend = 52 observations per 1 year
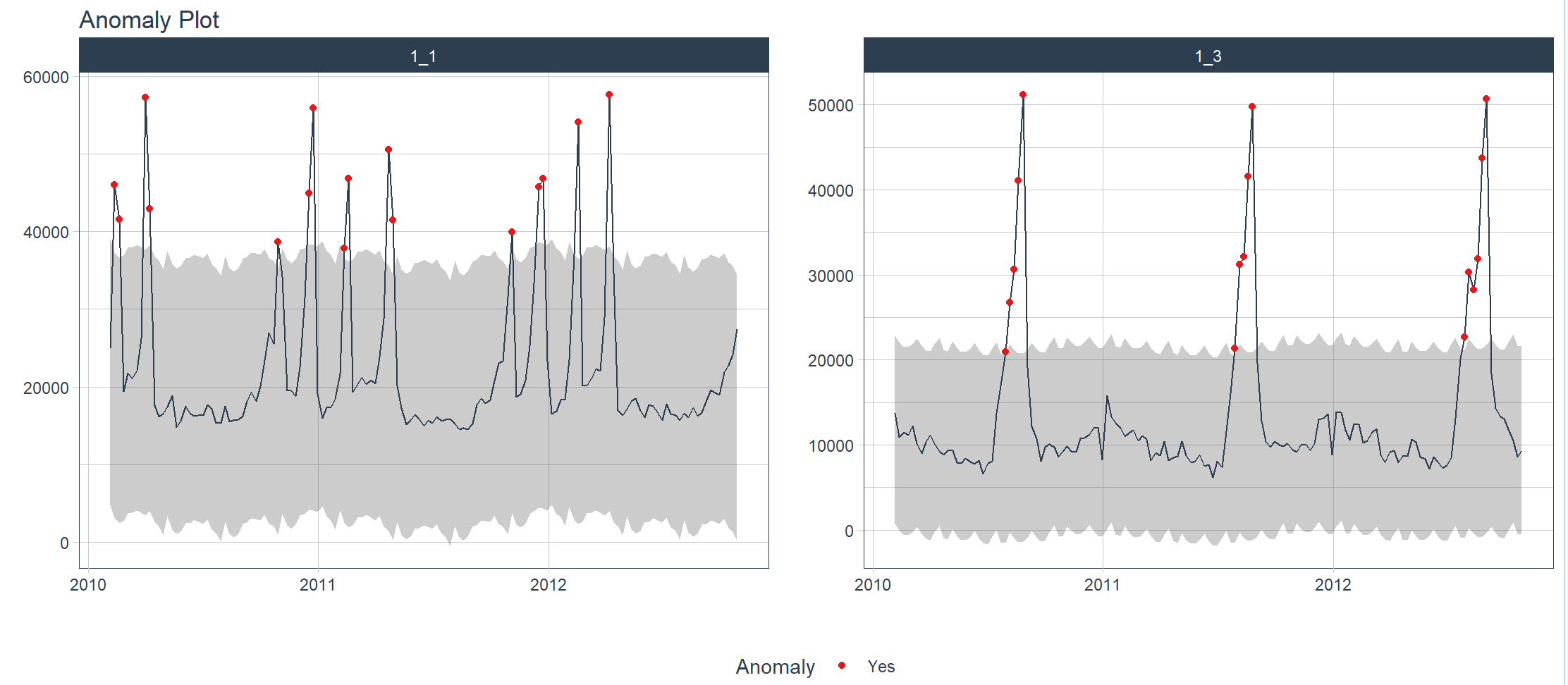
可视化一个或多个时间序列的异常值,自动进行数据清理后的结果。
> walmart_sales_weekly %>%
+ filter(id %in% c("1_1", "1_3")) %>%
+ group_by(id) %>%
+ anomalize(Date, Weekly_Sales, .message = FALSE) %>%
+ plot_anomalies_cleaned(Date, .facet_ncol = 2, .interactive = FALSE)
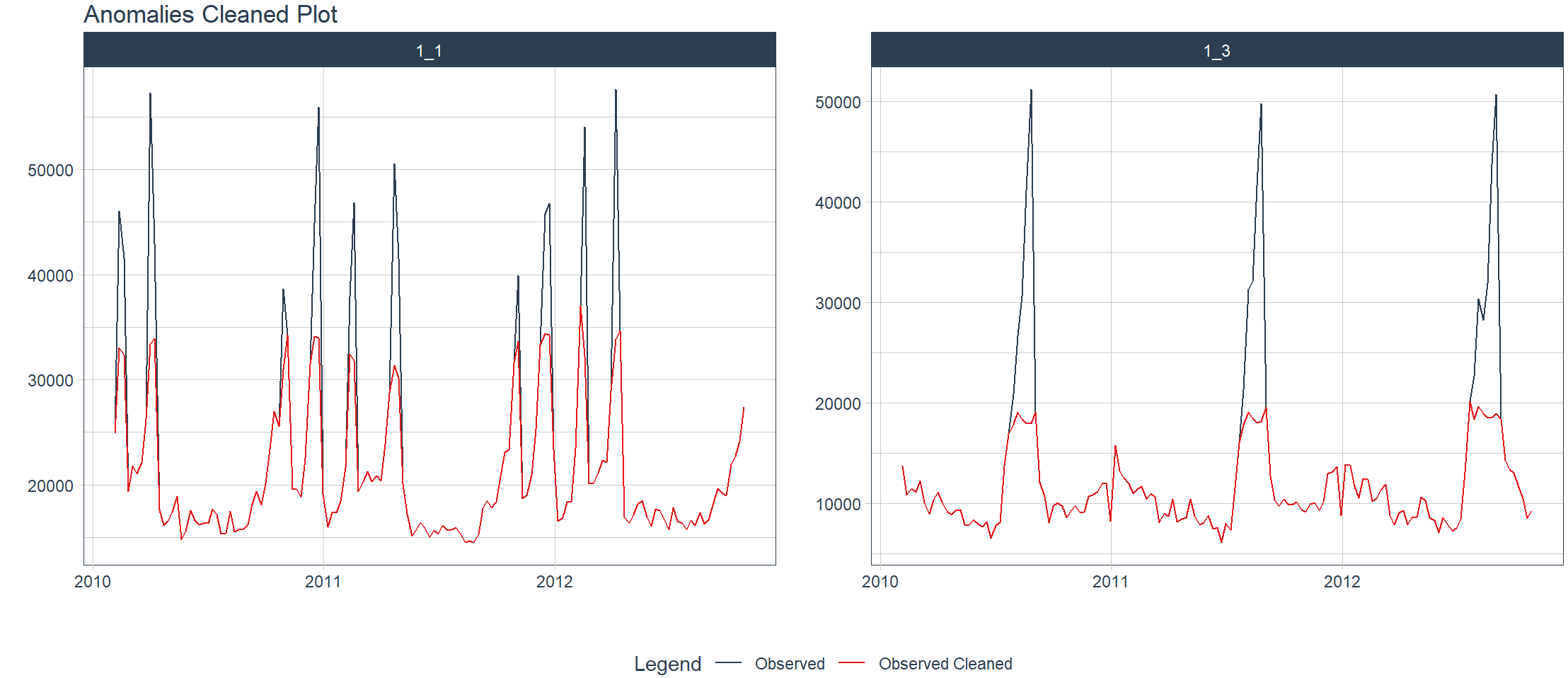
把数据按时间序列的多维度进行分解。
> walmart_sales_weekly %>%
+ filter(id %in% c("1_1", "1_3")) %>%
+ group_by(id) %>%
+ anomalize(Date, Weekly_Sales, .message = FALSE) %>%
+ plot_anomalies_decomp(Date, .interactive = FALSE)
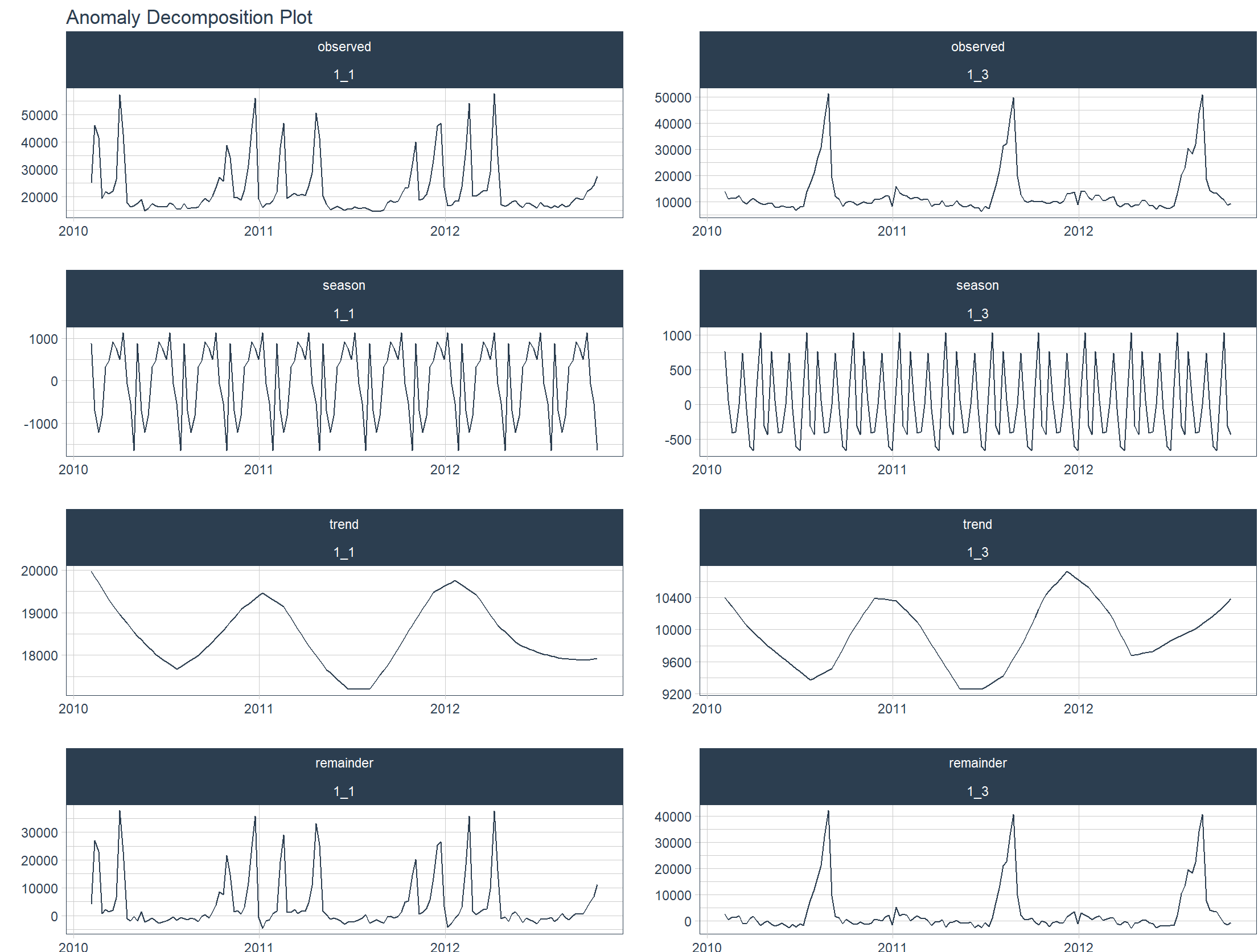
把数据按时间序列进行异常诊断。
> walmart_sales_weekly %>%
+ group_by(id) %>%
+ plot_anomaly_diagnostics(Date, Weekly_Sales,
+ .message = FALSE,
+ .facet_ncol = 3,
+ .ribbon_alpha = 0.25,
+ .interactive = FALSE)
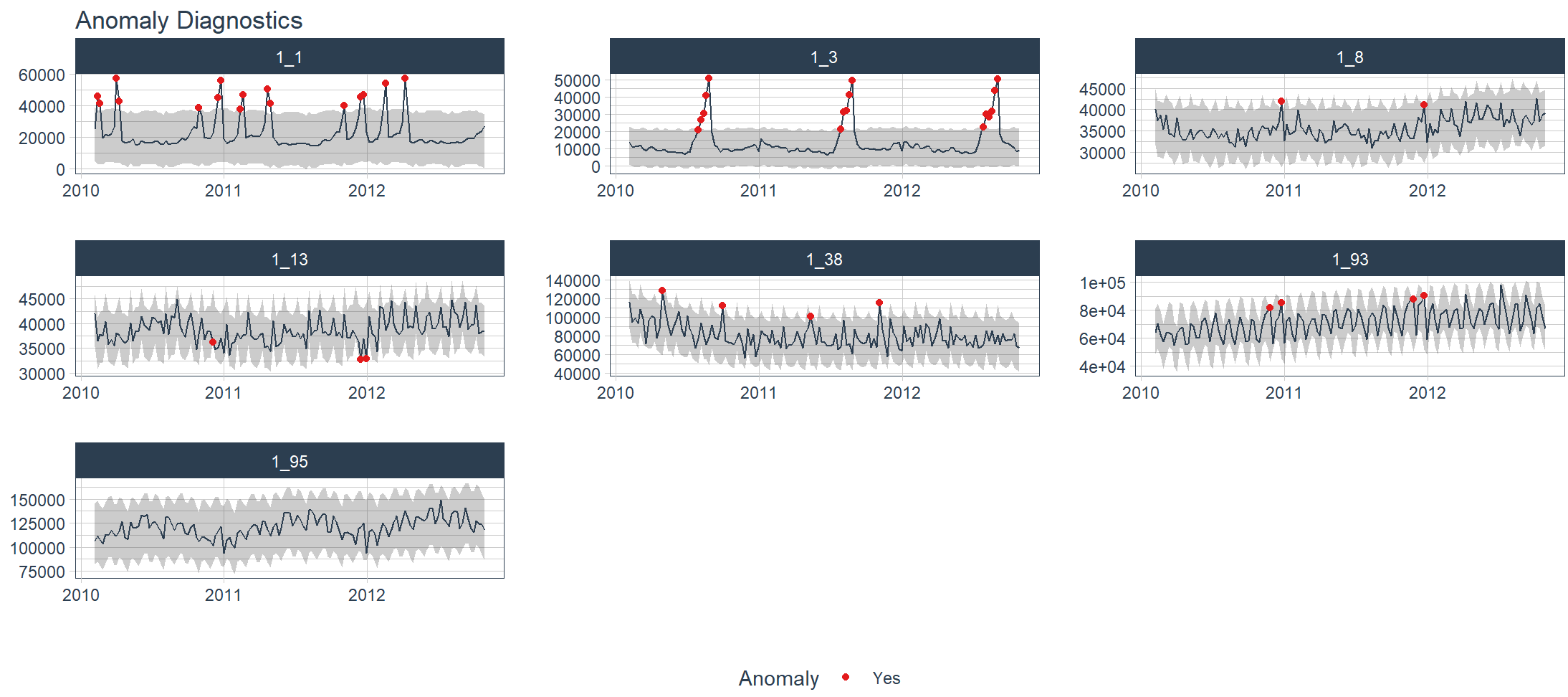
9. 可视化:时间序列季节性分解
季节分析,可视化一个或多个时间序列的多种季节性特征,分别按日期,星期,周,月的4个维度,生成可视化看板。
> taylor_30_min %>%
+ plot_seasonal_diagnostics(date, value, .interactive = FALSE)
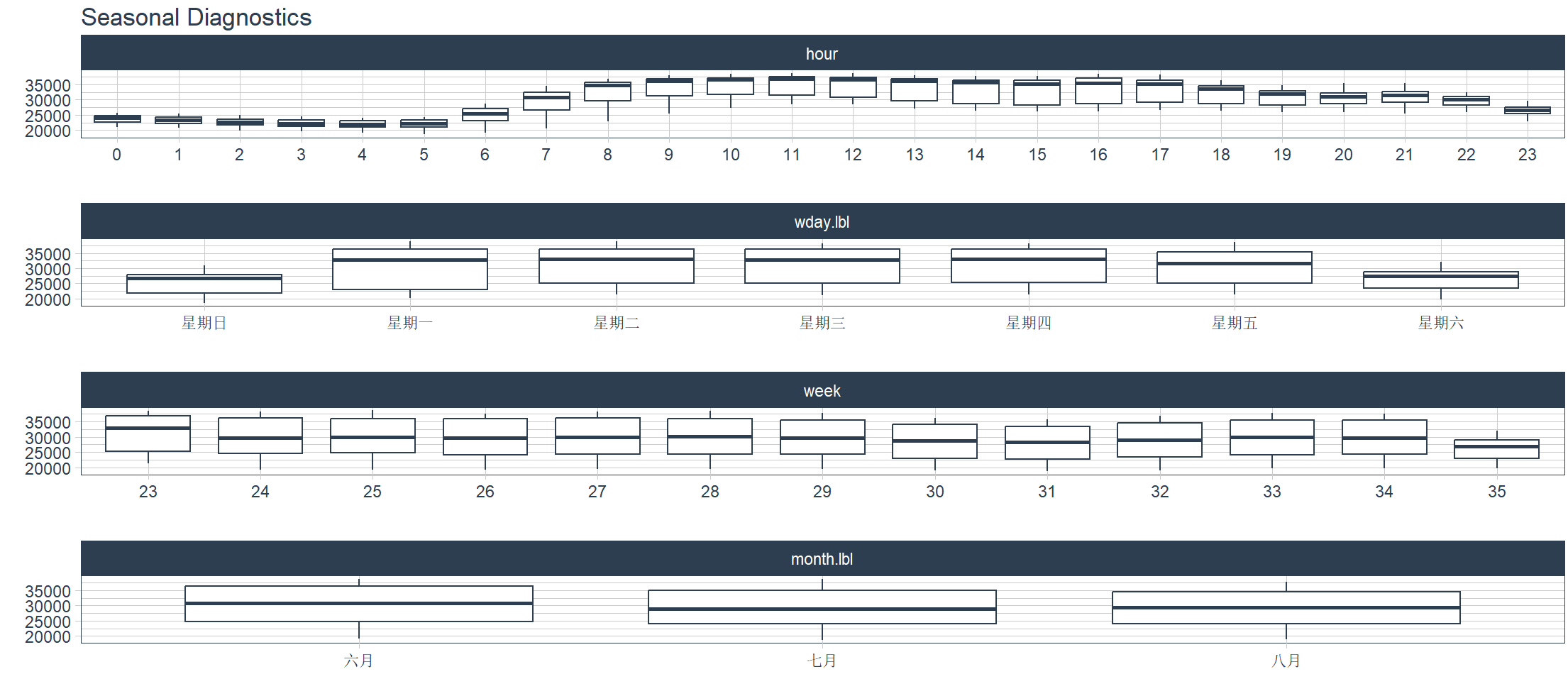
STL分解,按STL分解特征拆分,基于局部加权回归的季节性趋势分解。STL分解是一种将时间序列分解为三个组成部分的统计方法:
- 趋势分量 (Trend) 数据的长期变化方向,反映平滑的总体走势
- 季节分量 (Seasonal) 周期性重复的模式,如每周、每月或每年的规律性波动
- 余项分量 (Remainder) 剔除趋势和季节后剩余的随机波动或噪声
数学表达式为:
观测值 = 趋势 + 季节 + 余项
> m4_hourly %>%
+ filter(id == "H10") %>%
+ plot_stl_diagnostics(
+ date, value,
+ # Set features to return, desired frequency and trend
+ .feature_set = c("observed", "season", "trend", "remainder"),
+ .frequency = "24 hours",
+ .trend = "1 week",
+ .interactive = FALSE)
frequency = 24 observations per 24 hours
trend = 168 observations per 1 week
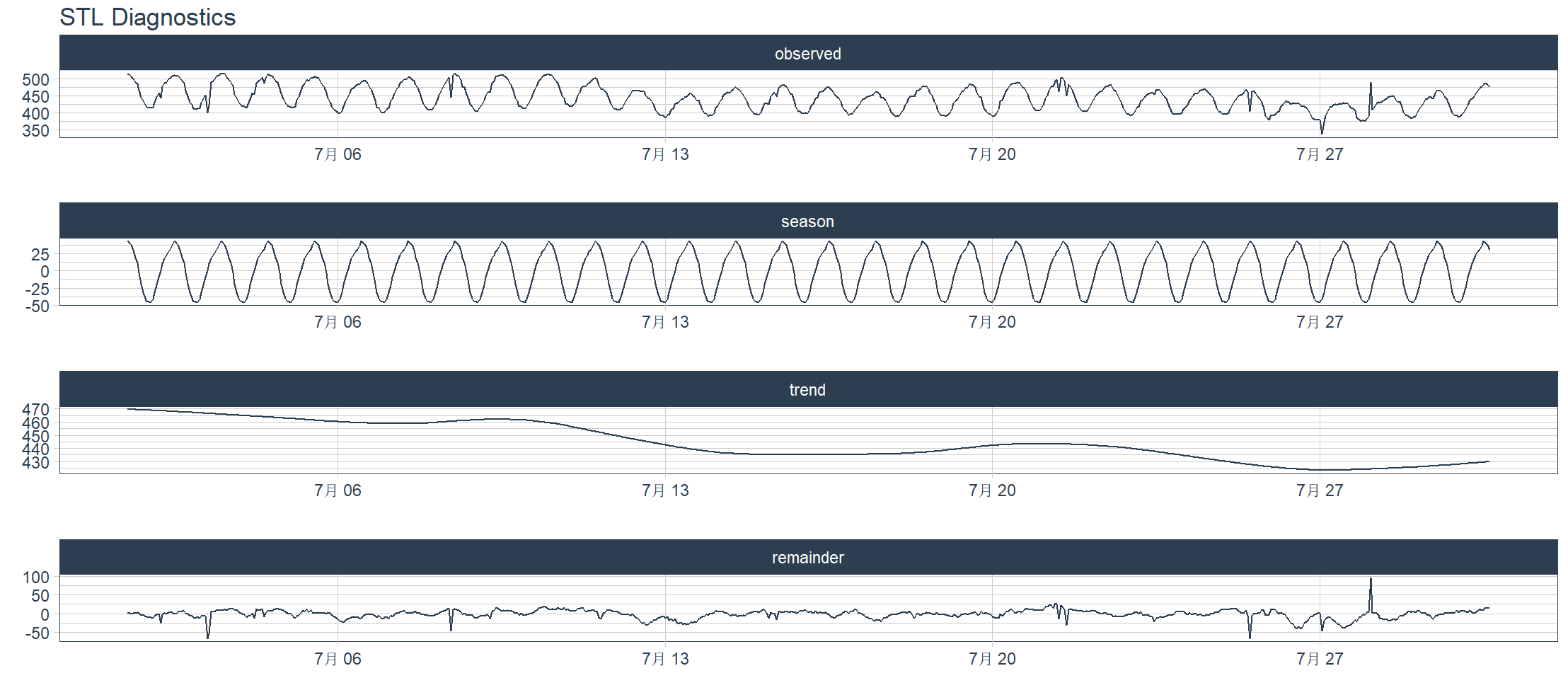
可视化ACF, PACF, and CCFs检测
> m4_hourly %>%
+ group_by(id) %>%
+ plot_acf_diagnostics(
+ date, value, # ACF & PACF
+ .lags = "7 days", # 7-Days of hourly lags
+ .interactive = FALSE
+ )
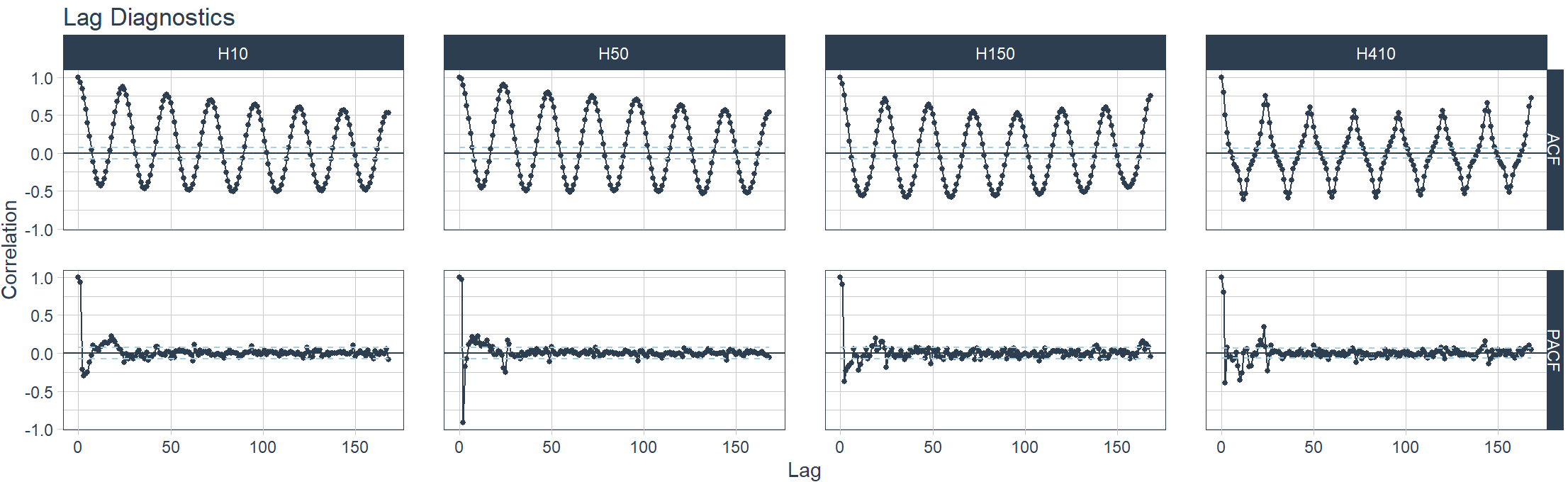
10. 可视化:时间序列重采样
使用FANG数据集,FANG是包含科技股(“FB”、“AMZN”、“NFLX”和“GOOG”)每日历史股价的数据集,时间跨度从2013年初到2016年底。FANG包含 4,032 行和 8 个变量的“tibble”(“整洁”数据框):symbol股票代码符号,开高低收等信息。
> head(FANG)
# A tibble: 6 × 8
symbol date open high low close volume adjusted
1 FB 2013-01-02 27.4 28.2 27.4 28 69846400 28
2 FB 2013-01-03 27.9 28.5 27.6 27.8 63140600 27.8
3 FB 2013-01-04 28.0 28.9 27.8 28.8 72715400 28.8
4 FB 2013-01-07 28.7 29.8 28.6 29.4 83781800 29.4
5 FB 2013-01-08 29.5 29.6 28.9 29.1 45871300 29.1
6 FB 2013-01-09 29.7 30.6 29.5 30.6 104787700 30.6
# 数据概览
> summary(FANG)
symbol date open high low close
Length:4032 Min. :2013-01-02 Min. : 22.99 Min. : 23.09 Min. : 22.67 Min. : 22.9
Class :character 1st Qu.:2014-01-01 1st Qu.: 106.31 1st Qu.: 107.75 1st Qu.: 104.50 1st Qu.: 106.2
Mode :character Median :2015-01-01 Median : 335.67 Median : 340.68 Median : 331.20 Median : 335.1
Mean :2015-01-01 Mean : 382.70 Mean : 386.38 Mean : 378.67 Mean : 382.6
3rd Qu.:2016-01-01 3rd Qu.: 581.47 3rd Qu.: 585.86 3rd Qu.: 576.52 3rd Qu.: 582.1
Max. :2016-12-30 Max. :1226.80 Max. :1228.88 Max. :1218.60 Max. :1220.2
volume adjusted
Min. : 7900 Min. : 13.14
1st Qu.: 2699875 1st Qu.: 74.82
Median : 7285600 Median :190.75
Mean : 16489749 Mean :297.12
3rd Qu.: 21942350 3rd Qu.:531.37
Max. :365457900 Max. :844.36
数据处理,重采样
> FB_tbl <- FANG %>%
+ filter(symbol == "FB") %>%
+ select(symbol, date, adjusted)
# 重采样参数配置
> resample_spec <- time_series_cv(
+ FB_tbl,
+ initial = "1 year",
+ assess = "6 weeks",
+ skip = "3 months",
+ lag = "1 month",
+ cumulative = FALSE,
+ slice_limit = 6
+ )
Using date_var: date
# 重采样输出
> resample_spec %>% tk_time_series_cv_plan()
# A tibble: 1,812 × 5
.id .key symbol date adjusted
1 Slice1 training FB 2015-11-19 106.
2 Slice1 training FB 2015-11-20 107.
3 Slice1 training FB 2015-11-23 107.
4 Slice1 training FB 2015-11-24 106.
5 Slice1 training FB 2015-11-25 105.
6 Slice1 training FB 2015-11-27 105.
7 Slice1 training FB 2015-11-30 104.
8 Slice1 training FB 2015-12-01 107.
9 Slice1 training FB 2015-12-02 106.
10 Slice1 training FB 2015-12-03 104.
# ℹ 1,802 more rows
# ℹ Use `print(n = ...)` to see more rows
# 可视化
> resample_spec %>%
+ tk_time_series_cv_plan() %>%
+ plot_time_series_cv_plan(
+ date, adjusted, # date variable and value variable
+ # Additional arguments passed to plot_time_series(),
+ .facet_ncol = 2,
+ .line_alpha = 0.5,
+ .interactive = FALSE
+ )
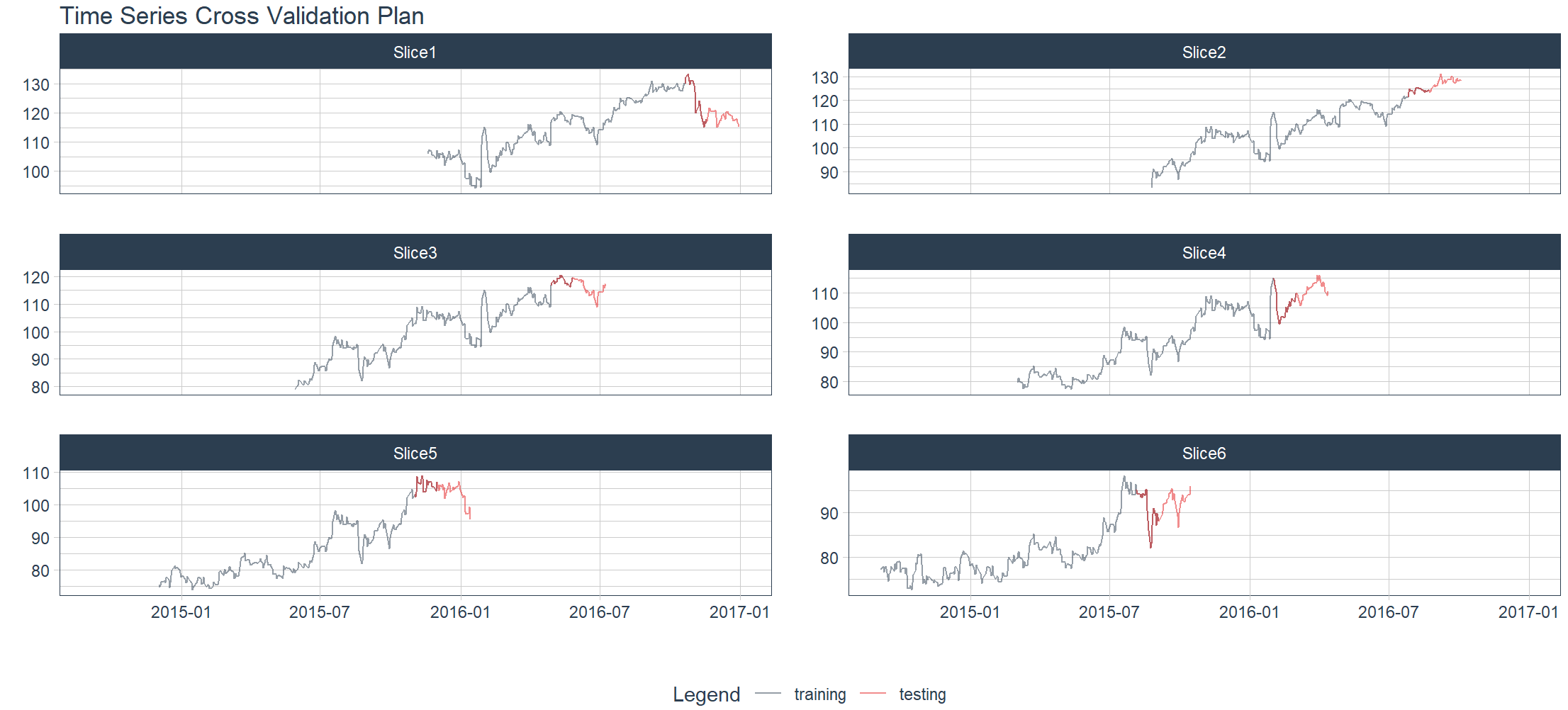
timetk体验起来是非常棒的,短信几行代码,就把如何观察时间序列数据看得明明白白。
转载请注明出处:
http://blog.fens.me/r-timetk/