让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务。
现在硬件越来越便宜,一台非品牌服务器,2颗24核CPU,配48G内存,2T的硬盘,已经降到2万块人民币以下了。这种配置如果简单地放几个web应用,显然是奢侈的浪费。就算是用来实现单节点的hadoop,对计算资源浪费也是非常高的。对于这么高性能的计算机,如何有效利用计算资源,就成为成本控制的一项重要议题了。
通过虚拟化技术,我们可以将一台服务器,拆分成12台VPS,每台2核CPU,4G内存,40G硬盘,并且支持资源重新分配。多么伟大的技术啊!现在我们有了12个节点的hadoop集群, 让Hadoop跑在云端,让世界加速。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/zookeeper-queue-fifo
前言
ZooKeeper是一个强大的分布式协作系统,用ZooKeeper可以方便地实现先进先出(FIFO)队列。给“队列”的技术现实多一种选择,标准化我们的程序结构。另一篇,分步式同步队列实现,请参考:ZooKeeper实现分布式队列Queue
关于ZooKeeper的基本使用,请参考:ZooKeeper伪分步式集群安装及使用
目录
- 分布式先进先出(FIFO)队列
- 设计思路
- 程序实现
1. 分布式先进先出(FIFO)队列
在计算机科学中,消息队列(Message queue)是一种进程间通信或同一进程的不同线程间的通信方式。消息队列提供了异步的通信协议,消息的发送者和接收者不需要同时与消息队列互交。消息会保存在队列中,直到接收者取回它。
先进先出(FIFO)队列,是消息队列最基本的一种实现形式,先发出的先消费。
2. 设计思路
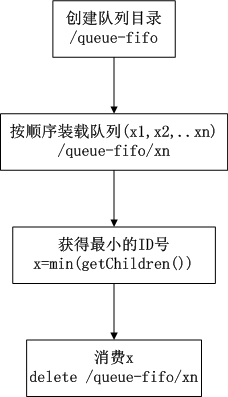
实现的思路也非常简单,在/queue-fifo的目录下创建 SEQUENTIAL 类型的子目录 /x(i),这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证FIFO。
应用实例
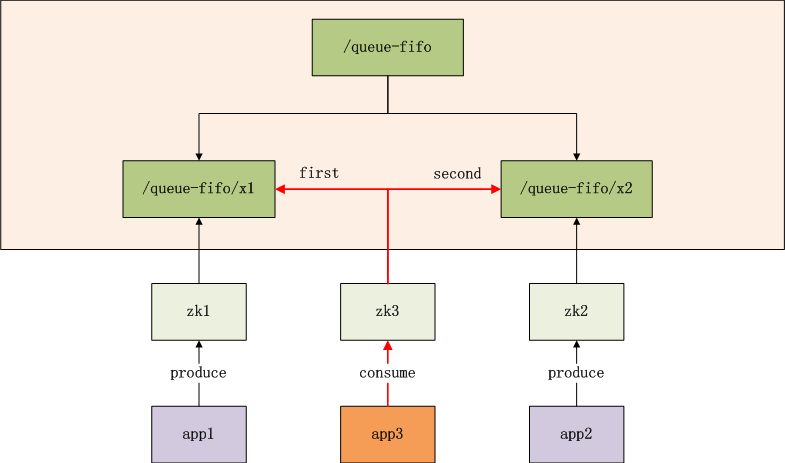
图标解释
- app1,app2,app3是3个独立的业务系统
- zk1,zk2,zk3是ZooKeeper集群的3个连接点
- /queue-fifo,是znode的队列,按顺序存储数据
- /queue-fifo/x1,是znode队列中,1号排对者,由app1提交
- /queue-fifo/x2,是znode队列中,2号排对者,由app2提交
- app3是消费者,通过zk3连接到znode队列中,找到/queue-fifo中顺序最少的节点消费,删除消费后的节点(红色线表示)
注:
- 1). app1可以通过zk2提交,app2也可通过zk3提交
- 2). app1可以提交3次请求,生成x1,x2,x3多个节点
- 3). app1可以作为消费者,消费队列数据
3. 程序实现
1). 单节点模拟实验
模拟app1,通过zk1,生产2个节点,然后再消费3个节点。
public static void doOne() throws Exception {
String host1 = "192.168.1.201:2181";
ZooKeeper zk = connection(host1);
initQueue(zk);
produce(zk, 1);
produce(zk, 2);
cosume(zk);
cosume(zk);
cosume(zk);
zk.close();
}
创建一个与服务器的连接
public static ZooKeeper connection(String host) throws IOException {
ZooKeeper zk = new ZooKeeper(host, 60000, null);
return zk;
}
出始化队列
public static ZooKeeper connection(String host) throws IOException {
return new ZooKeeper(host, 60000, new Watcher() {
public void process(WatchedEvent event) {
}
});
}
生产者
public static void produce(ZooKeeper zk, int x) throws KeeperException, InterruptedException {
System.out.println("create /queue-fifo/x" + x + " x" + x);
zk.create("/queue-fifo/x" + x, ("x" + x).getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
消费者
public static void cosume(ZooKeeper zk) throws KeeperException, InterruptedException {
List list = zk.getChildren("/queue-fifo", true);
if (list.size() > 0) {
long min = Long.MAX_VALUE;
for (String num : list) {
if (min > Long.parseLong(num.substring(1))) {
min = Long.parseLong(num.substring(1));
}
}
System.out.println("delete /queue/x" + min);
zk.delete("/queue-fifo/x" + min, 0);
} else {
System.out.println("No node to cosume");
}
}
启动main函数
public static void main(String[] args) throws Exception {
doOne();
}
运行结果:
/queue-fifo is exist!
create /queue-fifo/x1 x1
create /queue-fifo/x2 x2
delete /queue/x10000000032
delete /queue/x20000000033
No node to cosume
完全符合我的们预期,由于produce时,我们创建的节点模式是EPHEMERAL_SEQUENTIAL,所以系统会在x(i)(n),随机生成n=0000000032,输出为x10000000032。
接下来我们看分布式环境。
2). 分布式模拟实验
app1通过zk1生产x1, app2通过zk2生产x2, app3通过zk3消费3个节点
public static void doAction(int client) throws Exception {
String host1 = "192.168.1.201:2181";
String host2 = "192.168.1.201:2182";
String host3 = "192.168.1.201:2183";
ZooKeeper zk = null;
switch (client) {
case 1:
zk = connection(host1);
initQueue(zk);
produce(zk, 1);
break;
case 2:
zk = connection(host2);
initQueue(zk);
produce(zk, 2);
break;
case 3:
zk = connection(host3);
initQueue(zk);
cosume(zk);
cosume(zk);
cosume(zk);
break;
}
}
启动main函数
public static void main(String[] args) throws Exception {
if (args.length == 0) {
doOne();
} else {
doAction(Integer.parseInt(args[0]));
}
}
程序启动方法,分3次启动,命令行传不同的参数,分别是1,2,3
run1: 执行app1–>zk1
#日志输出
/queue-fifo is exist!
create /queue-fifo/x1 x1
run2: 执行app2–>zk2
#日志输出
/queue-fifo is exist!
create /queue-fifo/x2 x2
run3: 执行app3–>zk3
#日志输出
/queue-fifo is exist!
delete /queue/x10000000034
delete /queue/x20000000035
No node to cosume
我们完成分布式队列的实验,由于时间仓促。文字说明及代码难免有一些问题,请发现问题的同学帮忙指正。
下面贴一下完整的代码:
package org.conan.zookeeper.demo;
import java.io.IOException;
import java.util.List;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
public class FIFOZooKeeper {
public static void main(String[] args) throws Exception {
if (args.length == 0) {
doOne();
} else {
doAction(Integer.parseInt(args[0]));
}
}
public static void doOne() throws Exception {
String host1 = "192.168.1.201:2181";
ZooKeeper zk = connection(host1);
initQueue(zk);
produce(zk, 1);
produce(zk, 2);
cosume(zk);
cosume(zk);
cosume(zk);
zk.close();
}
public static void doAction(int client) throws Exception {
String host1 = "192.168.1.201:2181";
String host2 = "192.168.1.201:2182";
String host3 = "192.168.1.201:2183";
ZooKeeper zk = null;
switch (client) {
case 1:
zk = connection(host1);
initQueue(zk);
produce(zk, 1);
break;
case 2:
zk = connection(host2);
initQueue(zk);
produce(zk, 2);
break;
case 3:
zk = connection(host3);
initQueue(zk);
cosume(zk);
cosume(zk);
cosume(zk);
break;
}
}
// 创建一个与服务器的连接
public static ZooKeeper connection(String host) throws IOException {
return new ZooKeeper(host, 60000, new Watcher() {
public void process(WatchedEvent event) {
}
});
}
public static void initQueue(ZooKeeper zk) throws KeeperException, InterruptedException {
if (zk.exists("/queue-fifo", false) == null) {
System.out.println("create /queue-fifo task-queue-fifo");
zk.create("/queue-fifo", "task-queue-fifo".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} else {
System.out.println("/queue-fifo is exist!");
}
}
public static void produce(ZooKeeper zk, int x) throws KeeperException, InterruptedException {
System.out.println("create /queue-fifo/x" + x + " x" + x);
zk.create("/queue-fifo/x" + x, ("x" + x).getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
public static void cosume(ZooKeeper zk) throws KeeperException, InterruptedException {
List list = zk.getChildren("/queue-fifo", true);
if (list.size() > 0) {
long min = Long.MAX_VALUE;
for (String num : list) {
if (min > Long.parseLong(num.substring(1))) {
min = Long.parseLong(num.substring(1));
}
}
System.out.println("delete /queue/x" + min);
zk.delete("/queue-fifo/x" + min, 0);
} else {
System.out.println("No node to cosume");
}
}
}
转载请注明出处:
http://blog.fens.me/zookeeper-queue-fifo

[…] ZooKeeper实现分布式FIFO队列 […]
请问你的/queue-info是建立在HDFS上么?如果不是,怎么保证分布环境中对该目录的访问?如果是,那么这种创建和消费应该是依赖于HDFS的分布式访问机制,如何体现ZooKeeper的分布式协调作用呢?
1. 不是。
2. zk单独维护一套分布式文件系统。
3. zk原理看官方文档。
你这里序号都是自己分配的.现实中,app很难知道应该输入哪个号码.需要有一个序列号产生器.你文章中最好提下.
最好是利用zookeeper来实现递增.并且保证不同app入列的同步性.
文章只是一种业务模拟的情况,不能解决所有的问题。
ID的问题很常见,找个地方存一下就行了,和文章没什么关系。
扯蛋的设计,只有一个消费者
这是一个ZK的原型场景,produce和cosume在原型上都可以任意增加数量。不要匿名就乱喷,注册一个真实的姓名,说点实际的问题。
问一个问题哈, zk已经集群了,我看你实例代码中只有一个消费者,如果这个消费的zk down 了的话 其他 zk是否可以充当消费者的角色
你可以多注册几个消费者,用于backup。
让hadoop运行在VPS上,你知道hadoop的应用场景不,让hadoop跑在运端就是一种错误的思路
不要以“今天”的观点,点评1年前文章的各种不对,已经意义不大了。
只能说是toy式的设计,无法用于实际生产环境
好奇怪的想法,有没有考虑过节点数量很多,消息更多的情况?光是取最小值就翘翘了
本文仅是一个原型。
楼主的的确只是个原形,想法挺好,但是实际应用场景估计有限。