算法为王系列文章,涵盖了计算机算法,数据挖掘(机器学习)算法,统计算法,金融算法等的多种跨学科算法组合。在大数据时代的背景下,算法已经成为了金字塔顶的明星。一个好的算法可以创造一个伟大帝国,就像Google。
算法为王的时代正式到来….
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/algorithm-ga-r/

前言
人类总是在生活中摸索规律,把规律总结为经验,再把经验传给后人,让后人发现更多的规规律,每一次知识的传递都是一次进化的过程,最终会形成了人类的智慧。自然界规律,让人类适者生存地活了下来,聪明的科学家又把生物进化的规律,总结成遗传算法,扩展到了更广的领域中。
本文将带你走进遗传算法的世界。
目录
- 遗传算法介绍
- 遗传算法原理
- 遗传算法R语言实现
1. 遗传算法介绍
遗传算法是一种解决最优化的搜索算法,是进化算法的一种。进化算法最初借鉴了达尔文的进化论和孟德尔的遗传学说,从生物进化的一些现象发展起来,这些现象包括遗传、基因突变、自然选择和杂交等。遗传算法通过模仿自然界生物进化机制,发展出了随机全局搜索和优化的方法。遗传算法其本质是一种高效、并行、全局搜索的方法,它能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应的控制搜索过程,计算出全局最优解。
遗传算法的操作使用适者生存的原则,在潜在的种群中逐次产生一个近似最优解的方案,在每一代中,根据个体在问题域中的适应度值和从自然遗传学中借鉴来的再造方法进行个体选择,产生一个新的近似解。这个过程会导致种群中个体的进化,得到的新个体比原来个体更能适应环境,就像自然界中的改造一样。
如果从生物进化的角度,我们可以这样理解。在一个种群中,个体数量已经有一定规模,为了进化发展,通过选择和繁殖产生下一代的个体,其中繁殖过程包括交配和突变。根据适者生存的原则,选择过程会根据新个体的适应度进行保留或淘汰,但也不是完全以适应度高低作为导向,如果单纯选择适应度高的个体可能会产生局部最优的种群,而非全局最优,这个种群将不会再进化,称为早熟。之后,通过繁殖过程,让个体两两交配产生下一代新个体,上一代个体中优秀的基因会保留给下一代,而劣制的基因将被个体另一半的基因所代替。最后,通过小概率事件发生基因突变,通过突变产生新的下一代个体,实现种群的变异进化。
经过这一系列的选择、交配和突变的过程,产生的新一代个体将不同于初始的一代,并一代一代向增加整体适应度的方向发展,因为最好的个体总是更多的被选择去产生下一代,而适应度低的个体逐渐被淘汰掉。这样的过程不断的重复:每个个体被评价,计算出适应度,两个个体交配,然后突变,产生第三代。周而复始,直到终止条件满足为止。
遗传算法需要注意的问题:
- 遗传算法在适应度函数选择不当的情况下有可能收敛于局部最优,而不能达到全局最优。
- 初始种群的数量很重要,如果初始种群数量过多,算法会占用大量系统资源;如果初始种群数量过少,算法很可能忽略掉最优解。
- 对于每个解,一般根据实际情况进行编码,这样有利于编写变异函数和适应度函数。
- 在编码过的遗传算法中,每次变异的编码长度也影响到遗传算法的效率。如果变异代码长度过长,变异的多样性会受到限制;如果变异代码过短,变异的效率会非常低下,选择适当的变异长度是提高效率的关键。
- 变异率是一个重要的参数。
- 对于动态数据,用遗传算法求最优解比较困难,因为染色体种群很可能过早地收敛,而对以后变化了的数据不再产生变化。对于这个问题,研究者提出了一些方法增加基因的多样性,从而防止过早的收敛。其中一种是所谓触發式超级变异,就是当染色体群体的质量下降(彼此的区别减少)时增加变异概率;另一种叫随机外来染色体,是偶尔加入一些全新的随机生成的染色体个体,从而增加染色体多样性。
- 选择过程很重要,但交叉和变异的重要性存在争议。一种观点认为交叉比变异更重要,因为变异仅仅是保证不丢失某些可能的解;而另一种观点则认为交叉过程的作用只不过是在种群中推广变异过程所造成的更新,对于初期的种群来说,交叉几乎等效于一个非常大的变异率,而这么大的变异很可能影响进化过程。
- 遗传算法很快就能找到良好的解,即使是在很复杂的解空间中。
- 遗传算法并不一定总是最好的优化策略,优化问题要具体情况具体分析。所以在使用遗传算法的同时,也可以尝试其他算法,互相补充,甚至根本不用遗传算法。
- 遗传算法不能解决那些“大海捞针”的问题,所谓“大海捞针”问题就是没有一个确切的适应度函数表征个体好坏的问题,使得算法的进化失去导向。
- 对于任何一个具体的优化问题,调节遗传算法的参数可能会有利于更好的更快的收敛,这些参数包括个体数目、交叉率和变异率。例如太大的变异率会导致丢失最优解,而过小的变异率会导致算法过早的收敛于局部最优点。对于这些参数的选择,现在还没有实用的上下限。
- 适应度函数对于算法的速度和效果也很重要。
遗传算法的应用领域包括计算机自动设计、生产调度、电路设计、游戏设计、机器人学习、模糊控制、时间表安排,神经网络训练等。然而,我准备把遗传算法到金融领域,比如回测系统的参数寻优方案,我会在以后的文章中,介绍有关金融解决方案。
2. 遗传算法原理
在遗传算法里,优化问题的解是被称为个体,它表示为一个变量序列,叫做染色体或者基因串。染色体一般被表达为简单的字符串或数字串,也有其他表示法,这一过程称为编码。首先要创建种群,算法随机生成一定数量的个体,有时候也可以人工干预这个过程进行,以提高初始种群的质量。在每一代中,每一个个体都被评价,并通过计算适应度函数得到一个适应度数值。种群中的个体被按照适应度排序,适应度高的在前面。
接下来,是产生下一代个体的种群,通过选择过程和繁殖过程完成。
选择过程,是根据新个体的适应度进行的,但同时并不意味着完全的以适应度高低作为导向,因为单纯选择适应度高的个体将可能导致算法快速收敛到局部最优解而非全局最优解,我们称之为早熟。作为折中,遗传算法依据原则:适应度越高,被选择的机会越高,而适应度低的,被选择的机会就低。初始的数据可以通过这样的选择过程组成一个相对优化的群体。
繁殖过程,表示被选择的个体进入交配过程,包括交配(crossover)和突变(mutation),交配对应算法中的交叉操作。一般的遗传算法都有一个交配概率,范围一般是0.6~1,这个交配概率反映两个被选中的个体进行交配的概率。
例如,交配概率为0.8,则80%的“夫妻”个体会生育后代。每两个个体通过交配产生两个新个体,代替原来的“老”个体,而不交配的个体则保持不变。交配过程,父母的染色体相互交換,从而产生两个新的染色体,第一个个体前半段是父亲的染色体,后半段是母亲的,第二个个体则正好相反。不过这里指的半段並不是真正的一半,这个位置叫做交配点,也是随机产生的,可以是染色体的任意位置。
突变过程,表示通过突变产生新的下一代个体。一般遗传算法都有一个固定的突变常数,又称为变异概率,通常是0.1或者更小,这代表变异发生的概率。根据这个概率,新个体的染色体随机的突变,通常就是改变染色体的一个字节(0变到1,或者1变到0)。
遗传算法实现将不断的重复这个过程:每个个体被评价,计算出适应度,两个个体交配,然后突变,产生下一代,直到终止条件满足为止。一般终止条件有以下几种:
- 进化次数限制
- 计算耗费的资源限制,如计算时间、计算占用的CPU,内存等
- 个体已经满足最优值的条件,即最优值已经找到
- 当适应度已经达到饱和,继续进化不会产生适应度更好的个体
- 人为干预
算法实现原理:
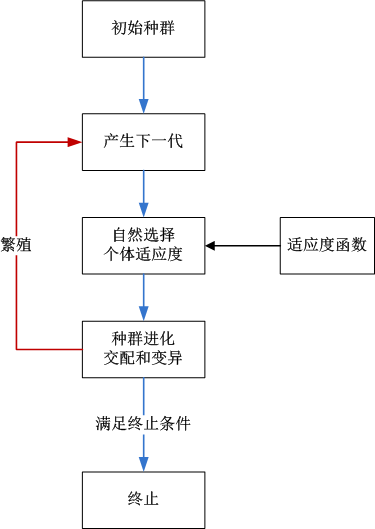
- 1. 创建初始种群
- 2. 循环:产生下一代
- 3. 评价种群中的个体适应度
- 4. 定义选择的适应度函数
- 5. 改变该种群(交配和变异)
- 6. 返回第二步
- 7. 满足终止条件结束
3. 遗传算法R语言实现
本节的系统环境
- Win7 64bit
- R: 3.1.1 x86_64-w64-mingw32/x64 (64-bit)
一个典型的遗传算法要求:一个基因表示的求解域, 一个适应度函数来评价解决方案。
遗传算法的参数通常包括以下几个:
- 种群规模(Population),即种群中染色体个体的数目。
- 染色体的基因个数(Size),即变量的数目。
- 交配概率(Crossover),用于控制交叉计算的使用频率。交叉操作可以加快收敛,使解达到最有希望的最优解区域,因此一般取较大的交叉概率,但交叉概率太高也可能导致过早收敛。
- 变异概率(Mutation),用于控制变异计算的使用频率,决定了遗传算法的局部搜索能力。
- 中止条件(Termination),结束的标志。
在R语言中,有一些现成的第三方包已经实现的遗传算法,我们可以直接进行使用。
- mcga包,多变量的遗传算法,用于求解多维函数的最小值。
- genalg包,多变量的遗传算法,用于求解多维函数的最小值。
- rgenoud包,复杂的遗传算法,将遗传算法和衍生的拟牛顿算法结合起来,可以求解复杂函数的最优化化问题。
- gafit包,利用遗传算法求解一维函数的最小值。不支持R 3.1.1的版本。
- GALGO包,利用遗传算法求解多维函数的最优化解。不支持R 3.1.1的版本。
本文将介绍mcga包和genalg包的遗传算法的使用。
3.1 mcga包
我们使用mcga包的mcga()函数,可以实现多变量的遗传算法。
mcga包是一个遗传算法快速的工具包,主要解决实值优化的问题。它使用的变量值表示基因序列,而不是字节码,因此不需要编解码的处理。mcga实现了遗传算法的交配和突变的操作,并且可以进行大范围和高精度的搜索空间的计算,算法的主要缺点是使用了256位的一元字母表。
首先,安装mcga包。
> install.packages("mcga")
> library(mcga)
查看一下mcga()函数的定义。
> mcga
function (popsize, chsize, crossprob = 1, mutateprob = 0.01, elitism = 1, minval, maxval, maxiter = 10, evalFunc)
参数说明:
- popsize,个体数量,即染色体数目
- chsize,基因数量,限参数的数量
- crossprob,交配概率,默认为1.0
- mutateprob,突变概率,默认为0.01
- elitism,精英数量,直接复制到下一代的染色体数目,默认为1
- minval,随机生成初始种群的下边界值
- maxval,随机生成初始种群的上边界值
- maxiter,繁殖次数,即循环次数,默认为10
- evalFunc,适应度函数,用于给个体进行评价
接下来,我们给定一个优化的问题,通过mcga()函数,计算最优化的解。
题目1:设fx=(x1-5)^2 + (x2-55)^2 +(x3-555)^2 +(x4-5555)^2 +(x5-55555)^2,计算fx的最小值,其中x1,x2,x3,x4,x5为5个不同的变量。
从直观上看,如果想得到fx的最小值,其实当x1=5,x2=55,x3=555,x4=5555,x5=55555时,fx=0为最小值。如果使用穷举法,通过循环的方法找到这5个变量,估计会很费时的,我就不做测试了。下面我们看一下遗传算法的运行情况。
# 定义适应度函数
> f<-function(x){} # 代码省略
# 运行遗传算法
> m <- mcga( popsize=200,
+ chsize=5,
+ minval=0.0,
+ maxval=999999,
+ maxiter=2500,
+ crossprob=1.0,
+ mutateprob=0.01,
+ evalFunc=f)
# 最优化的个体结果
> print(m$population[1,])
[1] 5.000317 54.997099 554.999873 5555.003120 55554.218695
# 执行时间
> m$costs[1]
[1] 3.6104556
我们得到的最优化的结果为x1=5.000317, x2=54.997099, x3=554.999873, x4=5555.003120, x5=55554.218695,和我们预期的结果非常接近,而且耗时只有3.6秒。这个结果是非常令人满意地,不是么!如果使用穷举法,时间复杂度为O(n^5),估计没有5分钟肯定算不出来。
当然,算法执行时间和精度,都是通过参数进行配置的。如果增大个体数目或循环次数,一方面会增加算法的计算时间,另一方面结果也可能变得更精准。所以,在实际的使用过程中,需要根据一定的经验调整这几个参数。
3.2 genalg包
我们使用genalg包的rbga()函数,也可以实现多变量的遗传算法。
genalg包不仅实现了遗传算法,还提供了遗传算法的数据可视化,给用户更直观的角度理解算法。默认图显示的最小和平均评价值,表示遗传算法的计算进度。直方图显出了基因选择的频率,即基因在当前个体中被选择的次数。参数图表示评价函数和变量值,非常方便地看到评价函数和变量值的相关关系。
首先,安装genalg包。
> install.packages("genalg")
> library(genalg)
查看一下rbga()函数的定义。
> rbga(stringMin=c(), stringMax=c(),
suggestions=NULL,
popSize=200, iters=100,
mutationChance=NA,
elitism=NA,
monitorFunc=NULL, evalFunc=NULL,
showSettings=FALSE, verbose=FALSE)
参数说明:
- stringMin,设置每个基因的最小值
- stringMax,设置每个基因的最大值
- suggestions,建议染色体的可选列表
- popSize,个体数量,即染色体数目,默认为200
- iters,迭代次数,默认为100
- mutationChance,突变机会,默认为1/(size+1),它影响收敛速度和搜索空间的探测,低机率导致更快收敛,高机率增加了搜索空间的跨度。
- elitism,精英数量,默认为20%,直接复制到下一代的染色体数目
- monitorFunc,监控函数,每产生一代后运行
- evalFunc,适应度函数,用于给个体进行评价
- showSettings,打印设置,默认为false
- verbose,打印算法运行日志,默认为false
接下来,我们给定一个优化的问题,通过rbga()函数,计算最优化的解。
题目2:设fx=abs(x1-sqrt(exp(1)))+abs(x2-log(pi)),计算fx的最小值,其中x1,x2为2个不同的变量。
从直观上看,如果想得到fx的最小值,其实当x1=sqrt(exp(1))=1.648721, x2=log(pi)=1.14473时,fx=0为最小值。同样地,如果使用穷举法,通过循环的方法找到这2个变量,估计会很费时的,我也不做测试了。下面我们看一下rbga()函数的遗传算法的运行情况。
# 定义适应度函数
> f<-function(x){} #代码省略
# 定义监控函数
> monitor <- function(obj){} #代码省略
# 运行遗传算法
> m2 = rbga(c(1,1),
+ c(3,3),
+ popSize=100,
+ iters=1000,
+ evalFunc=f,
+ mutationChance=0.01,
+ verbose=TRUE,
+ monitorFunc=monitor
+ )
Testing the sanity of parameters...
Not showing GA settings...
Starting with random values in the given domains...
Starting iteration 1
Calucating evaluation values... ....................................................... done.
Sending current state to rgba.monitor()...
Creating next generation...
sorting results...
applying elitism...
applying crossover...
applying mutations... 2 mutations applied
Starting iteration 2
Calucating evaluation values... ...................... done.
Sending current state to rgba.monitor()...
Creating next generation...
sorting results...
applying elitism...
applying crossover...
applying mutations... 4 mutations applied
Starting iteration 3
Calucating evaluation values... ....................... done.
# 省略输出...
程序运行截图
需要注意的是,程序在要命令行界面运行,如果在RStudio中运行,会出现下面的错误提示。
Creating next generation...
sorting results...
applying elitism...
applying crossover...
applying mutations... 1 mutations applied
Starting iteration 10
Calucating evaluation values... .......................... done.
Sending current state to rgba.monitor()...
Error in get(name, envir = asNamespace(pkg), inherits = FALSE) :
object 'rversion' not found
Graphics error: Error in get(name, envir = asNamespace(pkg), inherits = FALSE) :
object 'rversion' not found
我们迭代1000次后,查看计算结果。
# 计算结果
> m2$population[1,]
[1] 1.650571 1.145784
我们得到的最优化的结果为x1=1.650571, x2=1.145784,非常接近最终的结果。另外,我们可以通过genalg包的可视化功能,看到迭代过程的每次的计算结果。下面截图分为对应1次迭代,10次迭代,200次迭代和1000次迭代的计算结果。从图中可以看出,随着迭代次数的增加,优选出的结果集变得越来越少,而且越来越精准。
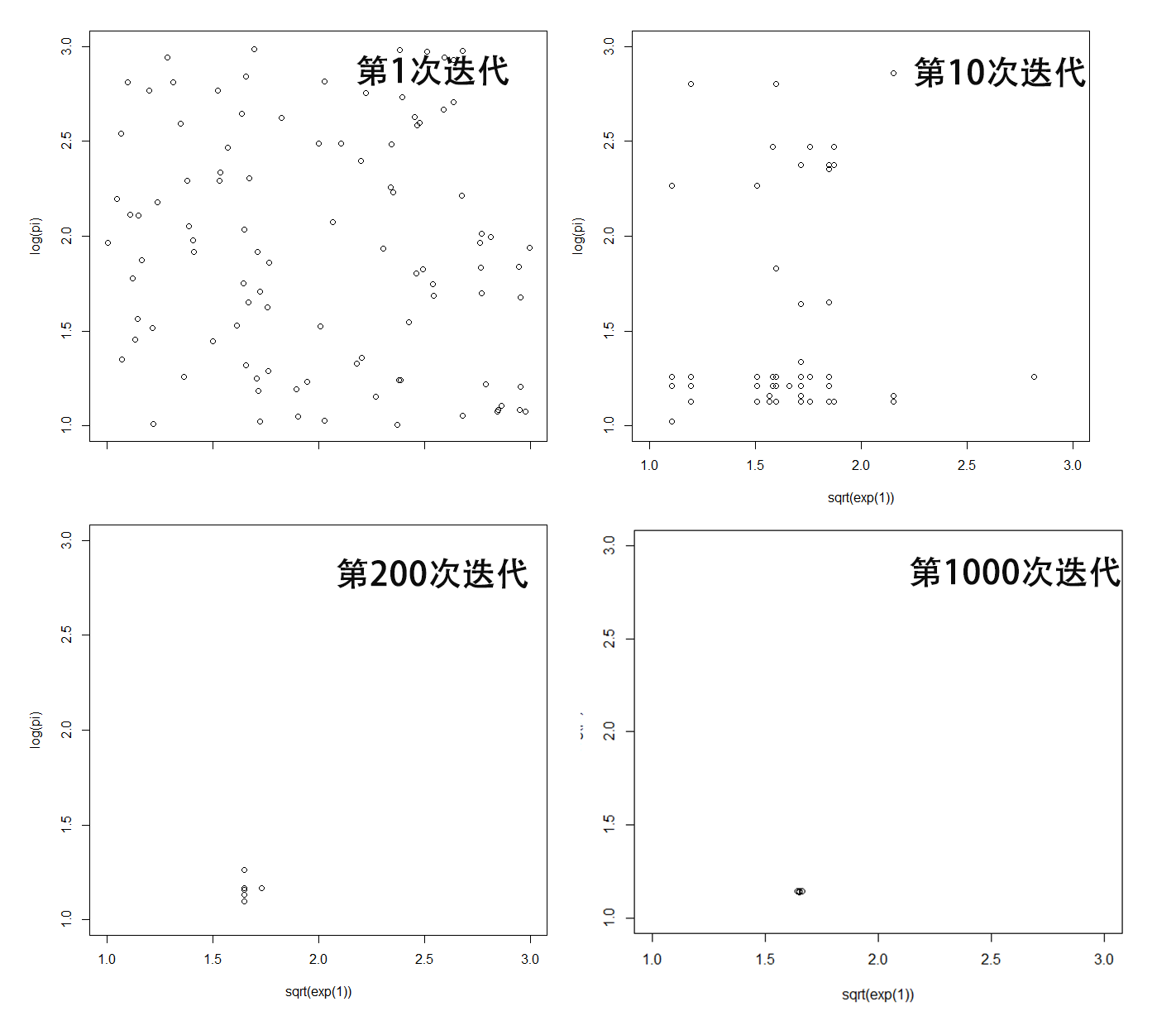
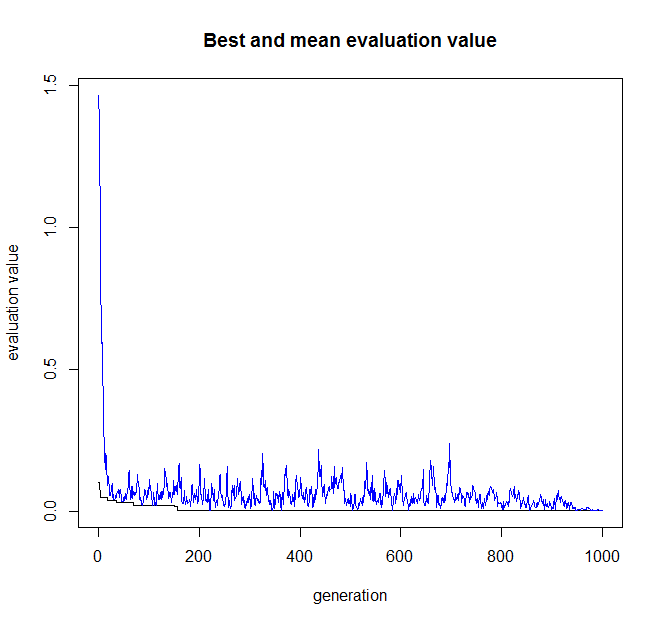
默认图输出,用于描述遗传过程的进展,X轴为迭代次数,Y轴评价值,评价值越接近于0越好。在1000迭代1000次后,基本找到了精确的结果。
> plot(m2)
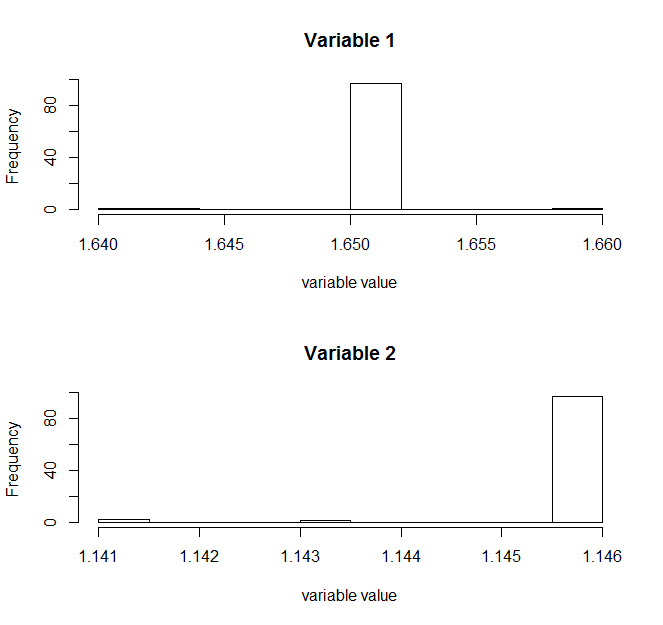
直方图输出,用于描述对染色体的基因选择频率,即一个基因在染色体中的当前人口被选择的次数。当x1在1.65区域时,被选择超过80次;当x2在1.146区域时,被选择超过了80次。通过直方图,我们可以理解为更优秀的基因被留给了后代。
> plot(m2,type='hist')
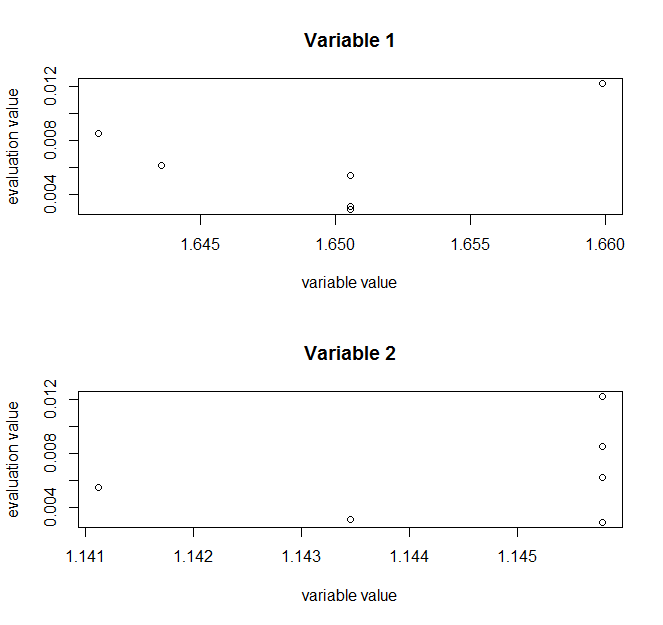
参数图输出,用于描述评价函数和变量的值的相关关系。对于x1,评价值越小,变量值越准确,但相关关系不明显。对于x2,看不出相关关系。
> plot(m2,type='vars')
对比mcga包和genalg包,mcga包适合计算大范围取值空间的最优解,而用genalg包对于大范围取值空间的计算就表现就不太好了。从另一个方面讲,genalg包提供了可视化工具,可以让我们直观的看遗传算法的收敛过程,对于算法的理解和调优是非常有帮助的。
在掌握了遗传算法后,我们就可以快度地处理一些优化的问题了,比如接下来我会介绍的金融回测系统的参数寻优方案。让我们远离穷举法,珍惜CPU的每一秒时间。
参考文章
http://zh.wikipedia.org/zh/遗传算法
转载请注明出处:
http://blog.fens.me/algorithm-ga-r/

张总这一篇文章确实是遗传算法在R语言中应用的好文。遗传算法的很多思想在金融投资实战中也有很多应用。“截断亏损,让赢利奔跑”本身也可以看做是:让不适应市场环境的头寸灭亡;让顺应潮流的头寸充分做大。
你的回复速度太快了,文章才刚刚发布。其实,早就想写遗传算法的文章了,碰巧最近有个项目正要用到,就把R语言的强大,再次展示一下。
”让不适应市场环境的头寸灭亡;让顺应潮流的头寸充分做大“,你已经把算法应用到实盘的经验,我还要再磨练啊!多多交流。
Nice article! Another very robust genetic algorithm type global optimization is DE which has a R package DEoptim. http://www1.icsi.berkeley.edu/~storn/code.html
:-), Try later.
好文章,留着等用R做模型时再认真分析学习。
🙂
对于寻优参数方程,如何应用这个rbga? evalFunc如何定义,如图
mcga用到需要优化的地方。evalFunc,你不是已定义了。
这样定义,模型得不到好的结果,甚至大相径庭
优化目标函数,要根据业务的情况,自己来定义了;这就是有难度的地方。不然,一个模型早就一统天下了。