算法为王系列文章,涵盖了计算机算法,数据挖掘(机器学习)算法,统计算法,金融算法等的多种跨学科算法组合。在大数据时代的背景下,算法已经成为了金字塔顶的明星。一个好的算法可以创造一个伟大帝国,就像Google。
算法为王的时代正式到来….
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/algorithm-pagerank-mapreduce/

前言
Google通过PageRank算法模型,实现了对全互联网网页的打分。但对于海量数据的处理,在单机下是不可能实现,所以如何将PageRank并行计算,将是本文的重点。
本文将继续上一篇文章 PageRank算法R语言实现,把PageRank单机实现,改成并行实现,利用MapReduce计算框架,在集群中跑起来。
目录
- PageRank算法并行化原理
- MapReduce分步式编程
1. PageRank算法分步式原理
单机算法原理请参考文章:PageRank算法R语言实现
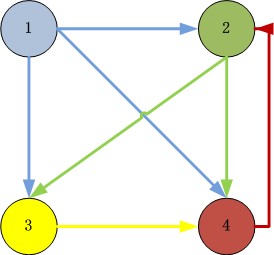
PageRank的分步式算法原理,简单来讲,就是通过矩阵计算实现并行化。
1). 把邻接矩阵的列,按数据行存储
邻接矩阵
[,1] [,2] [,3] [,4]
[1,] 0.0375000 0.0375 0.0375 0.0375
[2,] 0.3208333 0.0375 0.0375 0.8875
[3,] 0.3208333 0.4625 0.0375 0.0375
[4,] 0.3208333 0.4625 0.8875 0.0375
按行存储HDFS
1 0.037499994,0.32083333,0.32083333,0.32083333
2 0.037499994,0.037499994,0.4625,0.4625
3 0.037499994,0.037499994,0.037499994,0.88750005
4 0.037499994,0.88750005,0.037499994,0.037499994
2). 迭代:求矩阵特征值
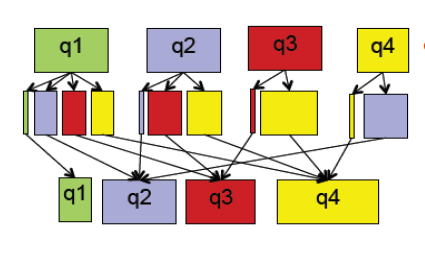
map过程:
- input: 邻接矩阵, pr值
- output: key为pr的行号,value为邻接矩阵和pr值的乘法求和公式
reduce过程:
- input: key为pr的行号,value为邻接矩阵和pr值的乘法求和公式
- output: key为pr的行号, value为计算的结果,即pr值
第1次迭代
0.0375000 0.0375 0.0375 0.0375 1 0.150000
0.3208333 0.0375 0.0375 0.8875 * 1 = 1.283333
0.3208333 0.4625 0.0375 0.0375 1 0.858333
0.3208333 0.4625 0.8875 0.0375 1 1.708333
第2次迭代
0.0375000 0.0375 0.0375 0.0375 0.150000 0.150000
0.3208333 0.0375 0.0375 0.8875 * 1.283333 = 1.6445833
0.3208333 0.4625 0.0375 0.0375 0.858333 0.7379167
0.3208333 0.4625 0.8875 0.0375 1.708333 1.4675000
… 10次迭代
特征值
0.1500000
1.4955721
0.8255034
1.5289245
3). 标准化PR值
0.150000 0.0375000
1.4955721 / (0.15+1.4955721+0.8255034+1.5289245) = 0.3738930
0.8255034 0.2063759
1.5289245 0.3822311
2. MapReduce分步式编程
MapReduce流程分解
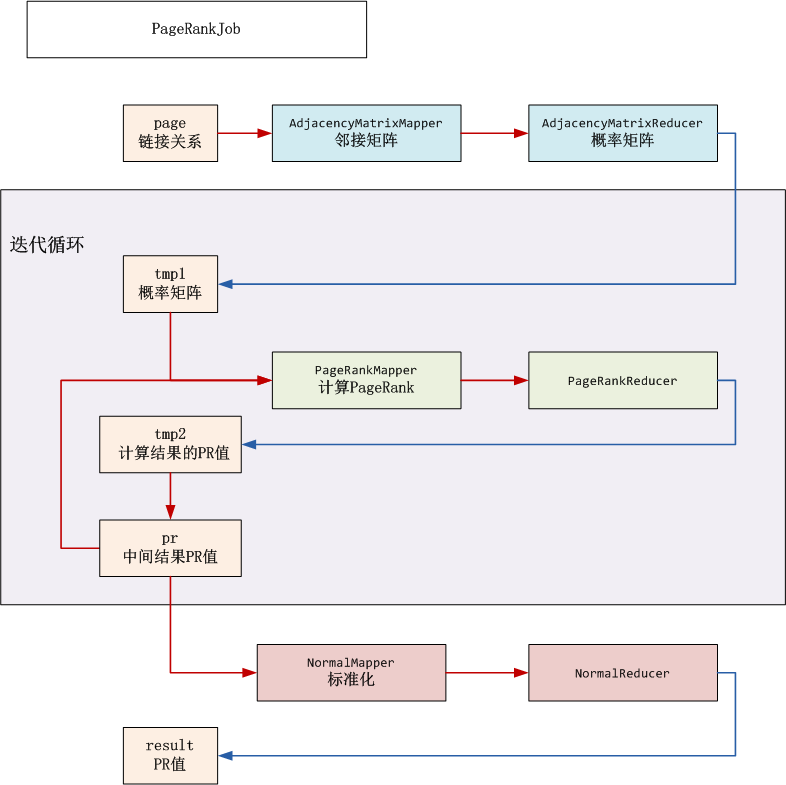
HDFS目录
- input(/user/hdfs/pagerank): HDFS的根目录
- input_pr(/user/hdfs/pagerank/pr): 临时目录,存储中间结果PR值
- tmp1(/user/hdfs/pagerank/tmp1):临时目录,存储邻接矩阵
- tmp2(/user/hdfs/pagerank/tmp2):临时目录,迭代计算PR值,然后保存到input_pr
- result(/user/hdfs/pagerank/result): PR值输出结果
开发步骤:
- 网页链接关系数据: page.csv
- 出始的PR数据:pr.csv
- 邻接矩阵: AdjacencyMatrix.java
- PageRank计算: PageRank.java
- PR标准化: Normal.java
- 启动程序: PageRankJob.java
1). 网页链接关系数据: page.csv
新建文件:page.csv
1,2
1,3
1,4
2,3
2,4
3,4
4,2
2). 出始的PR数据:pr.csv
设置网页的初始值都是1
新建文件:pr.csv
1,1
2,1
3,1
4,1
3). 邻接矩阵: AdjacencyMatrix.java

矩阵解释:
- 阻尼系数为0.85
- 页面数为4
- reduce以行输出矩阵的列,输出列主要用于分步式存储,下一步需要转成行
新建程序:AdjacencyMatrix.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.Arrays;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class AdjacencyMatrix {
private static int nums = 4;// 页面数
private static float d = 0.85f;// 阻尼系数
public static class AdjacencyMatrixMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
String[] tokens = PageRankJob.DELIMITER.split(values.toString());
Text k = new Text(tokens[0]);
Text v = new Text(tokens[1]);
context.write(k, v);
}
}
public static class AdjacencyMatrixReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
float[] G = new float[nums];// 概率矩阵列
Arrays.fill(G, (float) (1 - d) / G.length);
float[] A = new float[nums];// 近邻矩阵列
int sum = 0;// 链出数量
for (Text val : values) {
int idx = Integer.parseInt(val.toString());
A[idx - 1] = 1;
sum++;
}
if (sum == 0) {// 分母不能为0
sum = 1;
}
StringBuilder sb = new StringBuilder();
for (int i = 0; i < A.length; i++) {
sb.append("," + (float) (G[i] + d * A[i] / sum));
}
Text v = new Text(sb.toString().substring(1));
System.out.println(key + ":" + v.toString());
context.write(key, v);
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("input");
String input_pr = path.get("input_pr");
String output = path.get("tmp1");
String page = path.get("page");
String pr = path.get("pr");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(input);
hdfs.mkdirs(input);
hdfs.mkdirs(input_pr);
hdfs.copyFile(page, input);
hdfs.copyFile(pr, input_pr);
Job job = new Job(conf);
job.setJarByClass(AdjacencyMatrix.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(AdjacencyMatrixMapper.class);
job.setReducerClass(AdjacencyMatrixReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(page));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
4). PageRank计算: PageRank.java
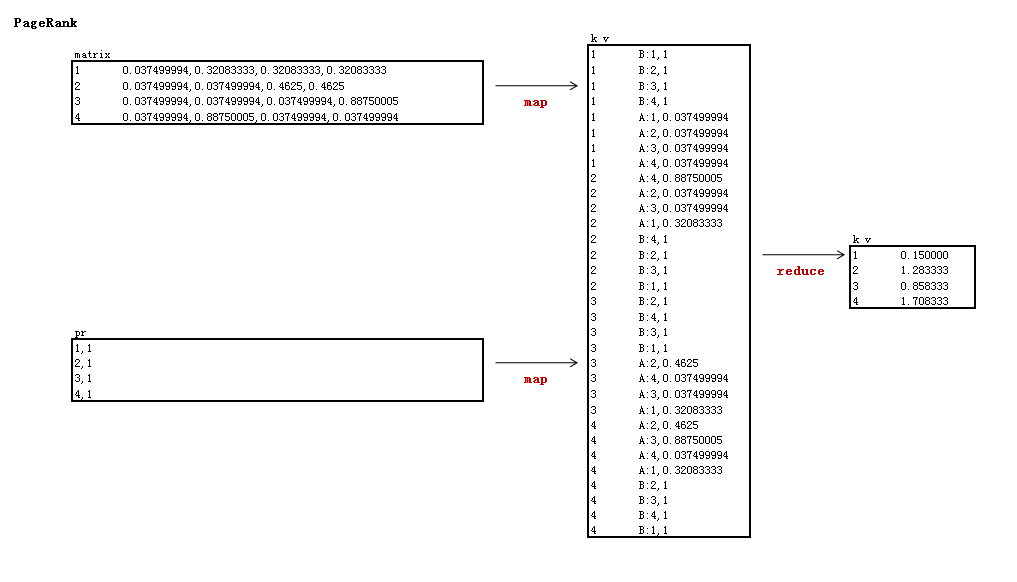
矩阵解释:
- 实现邻接与PR矩阵的乘法
- map以邻接矩阵的行号为key,由于上一步是输出的是列,所以这里需要转成行
- reduce计算得到未标准化的特征值
新建文件: PageRank.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class PageRank {
public static class PageRankMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag;// tmp1 or result
private static int nums = 4;// 页面数
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// 判断读的数据集
}
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
String[] tokens = PageRankJob.DELIMITER.split(values.toString());
if (flag.equals("tmp1")) {
String row = values.toString().substring(0,1);
String[] vals = PageRankJob.DELIMITER.split(values.toString().substring(2));// 矩阵转置
for (int i = 0; i < vals.length; i++) {
Text k = new Text(String.valueOf(i + 1));
Text v = new Text(String.valueOf("A:" + (row) + "," + vals[i]));
context.write(k, v);
}
} else if (flag.equals("pr")) {
for (int i = 1; i <= nums; i++) {
Text k = new Text(String.valueOf(i));
Text v = new Text("B:" + tokens[0] + "," + tokens[1]);
context.write(k, v);
}
}
}
}
public static class PageRankReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
Map<Integer, Float> mapA = new HashMap<Integer, Float>();
Map<Integer, Float> mapB = new HashMap<Integer, Float>();
float pr = 0f;
for (Text line : values) {
System.out.println(line);
String vals = line.toString();
if (vals.startsWith("A:")) {
String[] tokenA = PageRankJob.DELIMITER.split(vals.substring(2));
mapA.put(Integer.parseInt(tokenA[0]), Float.parseFloat(tokenA[1]));
}
if (vals.startsWith("B:")) {
String[] tokenB = PageRankJob.DELIMITER.split(vals.substring(2));
mapB.put(Integer.parseInt(tokenB[0]), Float.parseFloat(tokenB[1]));
}
}
Iterator iterA = mapA.keySet().iterator();
while(iterA.hasNext()){
int idx = iterA.next();
float A = mapA.get(idx);
float B = mapB.get(idx);
pr += A * B;
}
context.write(key, new Text(PageRankJob.scaleFloat(pr)));
// System.out.println(key + ":" + PageRankJob.scaleFloat(pr));
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("tmp1");
String output = path.get("tmp2");
String pr = path.get("input_pr");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(PageRank.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input), new Path(pr));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
hdfs.rmr(pr);
hdfs.rename(output, pr);
}
}
5). PR标准化: Normal.java

矩阵解释:
- 对PR的计算结果标准化,让所以PR值落在(0,1)区间
新建文件:Normal.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Normal {
public static class NormalMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text("1");
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
context.write(k, values);
}
}
public static class NormalReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
List vList = new ArrayList();
float sum = 0f;
for (Text line : values) {
vList.add(line.toString());
String[] vals = PageRankJob.DELIMITER.split(line.toString());
float f = Float.parseFloat(vals[1]);
sum += f;
}
for (String line : vList) {
String[] vals = PageRankJob.DELIMITER.split(line.toString());
Text k = new Text(vals[0]);
float f = Float.parseFloat(vals[1]);
Text v = new Text(PageRankJob.scaleFloat((float) (f / sum)));
context.write(k, v);
System.out.println(k + ":" + v);
}
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("input_pr");
String output = path.get("result");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(Normal.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(NormalMapper.class);
job.setReducerClass(NormalReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
6). 启动程序: PageRankJob.java
新建文件:PageRankJob.java
package org.conan.myhadoop.pagerank;
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class PageRankJob {
public static final String HDFS = "hdfs://192.168.1.210:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
Map<String, String> path = new HashMap<String, String>();
path.put("page", "logfile/pagerank/page.csv");// 本地的数据文件
path.put("pr", "logfile/pagerank/pr.csv");// 本地的数据文件
path.put("input", HDFS + "/user/hdfs/pagerank");// HDFS的目录
path.put("input_pr", HDFS + "/user/hdfs/pagerank/pr");// pr存储目
path.put("tmp1", HDFS + "/user/hdfs/pagerank/tmp1");// 临时目录,存放邻接矩阵
path.put("tmp2", HDFS + "/user/hdfs/pagerank/tmp2");// 临时目录,计算到得PR,覆盖input_pr
path.put("result", HDFS + "/user/hdfs/pagerank/result");// 计算结果的PR
try {
AdjacencyMatrix.run(path);
int iter = 3;
for (int i = 0; i < iter; i++) {// 迭代执行
PageRank.run(path);
}
Normal.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
public static JobConf config() {// Hadoop集群的远程配置信息
JobConf conf = new JobConf(PageRankJob.class);
conf.setJobName("PageRank");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
public static String scaleFloat(float f) {// 保留6位小数
DecimalFormat df = new DecimalFormat("##0.000000");
return df.format(f);
}
}
程序代码已上传到github:
这样就实现了,PageRank的并行吧!接下来,我们就可以用PageRank做一些有意思的应用了。
转载请注明出处:
http://blog.fens.me/algorithm-pagerank-mapreduce/

[…] PageRank算法并行实现 […]
张老师,你好,对于Normal.java的过程,对于MapReduce过程,我想着是否可以定义一个计数器,在map过程中,读取一个记录就将读取的记录中向量分量值累加到计数器中,这样在map过程结束的时候,计数器的值就是向量的各分量的和,由于计数器是全局的,即使读取的数据文件很大,有多个map,最后的和也应该是对的,然后在reduce过程中用计数器的值,就不用遍历求和了,我之前做过一个类似的案例,按照这样的方法进行处理,结果发现在reduce过程中,读取不到这个计算器的值,读进来的是零,我在Dataguru上也发帖求助了,还是没有找到原因所在,帖子如下:
有关counter的使用方法的疑问
http://f.dataguru.cn/forum.php?mod=viewthread&tid=450064&fromuid=231904
(出处: 炼数成金)
请张老师帮忙查看一下,3Q
MR过程中,没有全局变量的概念,Map输出到Reduce都反映到了HDFS的文件上面了。
你如果想来构造全局变量,那么使用外部存储吧,比如,Map计数存到Redis里面,Reduce再从Redis读这个结果。但这是不符合MR设计思路的。
用enum定义的同一个计数器在Map和Reduce过程也是相互独立的,值保存在临时文件中,最后job完成,再进行合并的吗?
需要外部存储,自己写程序实现,这就和MR的过程,没什么关系了。
老师你好
我们看到pagerank的公式里面,第一部分是(1-d)/图顶点总数 ,把公式拆成矩阵形式,发现这第一部分并没有参与迭代,而是每一次迭代完成以后才加上去的。但是你的mr程序中,却是将这一部分加到了邻接矩阵中,然后再做迭代,我想知道这样做的依据是什么呢
详细的算法解释,还是找专门PageRank的资料看吧,本文只是算法应用。