架构师的信仰系列文章,主要介绍我对系统架构的理解,从我的视角描述各种软件应用系统的架构设计思想和实现思路。
从程序员开始,到架构师一路走来,经历过太多的系统和应用。做过手机游戏,写过编程工具;做过大型Web应用系统,写过公司内部CRM;做过SOA的系统集成,写过基于Hadoop的大数据工具;做过外包,做过电商,做过团购,做过支付,做过SNS,也做过移动SNS。以前只用Java,然后学了PHP,现在用R和Javascript。最后跳出IT圈,进入金融圈,研发量化交易软件。
架构设计就是定义一套完整的程序规范,坚持架构师的信仰,做自己想做的东西。
关于作者:
- 张丹,数据分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/data-analysis-factor-top9/
前言
现在我们正处于大数据时代,处处都产生数据,大部分数据已经不在稀缺,分析方法和算法模型都也写在了教课书中,如何挖掘出数据的价值,让数据分析落地,把数据价值转换为业务价值,是数据分析师核心要考虑的。数据分析要解决实际业务场景问题,伪需求、不清晰的目标,都会造成项目失败。
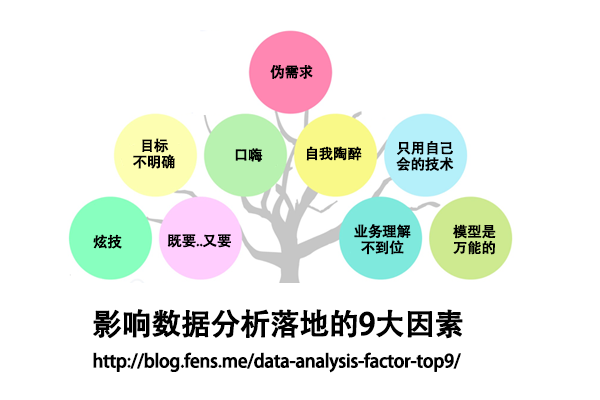
本文总结了影响数据分析落地的9大影响因素。
目录
- 影响数据分析的因素
- 无处不在的伪需求
- 目标不明确
- 口嗨
- 自我陶醉
- 业务理解不到位
- 炫技
- 只用自己会的技术
- 模型是万能的
- 既要..又要..也要..还要
1. 影响数据分析的因素
影响数据落地的因素有很多,可能数据分析做着做着,就会偏离原先既定的目标。
做数据分析项目,通常在开始时,第一步,我们都要先设定分析目标是什么,要解决一个怎样的问题。第二步,要思考如何用数据来解决,能产生什么结果,这个结果对于我们目标有什么样的促进作用。第三步,方法路径是什么,用什么技术,用什么模型,怎么做数据,怎么进行训练。第四步,是对模型结果进行验证,是否结果是有效的,是否正确,又是否准确的。
一个目标明确的数据分析项目,我们通常把具体做什么,提前设计技术框架,来保证数据分析的稳定执行。
但是,在执行过程中,会遇到各样的问题。可能有我们自身思路的限制的影响,也有外界市场变化,甲方领导带来的影响,导致我们在做分析时,会有各种各样的偏差。
2. 无处不在的伪需求
伪需求是指那些表面上看起来像是需求,实际上并不是真正必需的需求,通常是由于外部压力、误解或者不合理的预期所产生的。简单来说,伪需求并非真正影响项目目标的关键需求,它可能会浪费时间和资源,导致不必要的复杂性。在一些领域,特别是在产品开发或项目管理中,伪需求可能会引发团队的误方向。比如客户可能要求一些看似有用但实际无关紧要的功能,而这些功能最终并没有为项目带来实际价值。
很多人都不能分辨,什么是真正的需求和伪需求。以为自己需要的,自己想到的,就是真正需求,而并不关心,客户想要什么。这样提出的需求,就很有局限性,通常就不是一个共性问题。
在数据分析领域,伪需求通常表现为对数据的误解或不必要的分析,导致资源浪费和效率低下。以下是一个具体的例子:
案例:缺陷状态数据分析
某公司要求数据分析师对产品缺陷的状态进行详细分析,包括每个缺陷的当前状态、历史状态变化等。然而,深入分析后发现,这些状态数据并未对产品质量改进提供实质性帮助。真正有价值的指标是缺陷的严重程度、发生频率以及修复时间等。对缺陷状态的过度分析反而分散了团队对关键问题的关注,导致资源浪费。
在上述案例中,对缺陷状态的详细分析被认为是必要的,但实际上并未对产品改进带来实际价值。这类伪需求可能源于对数据价值的误解,或是未能准确识别业务需求。为了避免陷入伪需求的陷阱,数据分析师应与业务部门密切沟通,明确分析目标,聚焦于能为决策提供支持的关键指标。
通过识别和避免伪需求,数据分析团队可以更有效地利用资源,专注于真正能推动业务发展的分析工作。
3. 目标不明确
数据分析的核心,是就数据思路解决实际的业务问题。在不了解业务的时候,可能提不出来明确的目标。另一方面,在做数据分析的过程中,可能一会儿想一个,一会儿又想一个,造成目标很多。一直就不能定位到核心目标是什么。比如,我们的目标是从期货市场赚到钱。首先,要研究期货数据,然后研究策略,然后进行交易,最后赚到钱。
但目标不明确,导致分析方向不明确,难以得出有价值的结论。
如果甲方没思路,让你来提供思路,恭喜你,你不做出10个版本,甲方是不会放过你的。如果传达不准确,领导开会一句话,你为了这句话,绞尽脑汁,也不可能想到他的心理去。如果多个决策人,A处说一,B处说二,C处说三,都对,都是领导,后面就可以自行脑补了。
4. 口嗨
口嗨:大厂的人都说了能实现,所以这个技术一点也不难。
由于现在的短视频很发达,我们经常会刷到各种神乎其神的技术,解决了人类一大痛点问题。现在可能只是一个很小的突破,未来真的有可能解决。也被自媒体放大或者错误解读,让大家就真的感受到未来已来的幻觉。
有了这种幻觉后,就感觉自己作为数据分析的从业者,也能做出和报道中一样的效果。
有些大公司团队,甚至把这种虚幻的内容,当成碾压小公司的亮点技术,在客户这边打散吹嘘。一旦甲方领导信了这些飘在天上的,就会对自己的下属,乃至其他的乙方团队提出相当大的质疑。
为什么大公司都说,这个实现起来很容易,你们就是不会做呢?最后领导找大公司来做了,并花费了不少的钱,搞几年烂尾了,终于知道当时那些大厂销售,是一时的口嗨。
这个故事在不断的重复。
5. 自我陶醉
自我陶醉:我做的模型非常好:查准率,查全率,F1,AUC/ROC,接近完美。
在面试做数据分析的小朋友,很多人都处于“自我陶醉”中。在完成了一些老师给的任务,或者参加kaggle的比赛,得到了一些鼓励,就觉得自己行了。
比如,基于给定的数据做分类训练,比如纽约出租车数据分析、xx地区犯罪案件分析、xx地区房屋租金分析、xx企业零售商品分析等。
当问道为什么会有这么好的结果时,回复通常是,“教课书就这么说的,我按步骤做的,就应该有这样的结果,难道不是么”。然后,一脸质疑地看着我。
只有陶醉,过于入戏了。
6. 业务理解不到位
业务理解不到位:我能找出异常点,具体对应什么问题,你们一看应该就知道。
很多从软件开发转型做数据分析的人,绝大部分精力都关注在技术实现,比如何做数据结构,如何如做ETL,如何调用某个模型等,但是对于业务逻辑,并没有清晰的认识。
他们特别擅长用神经网络一类的模型,把数据填入模型,根据技术指标做做调优。把结果成功的计算出来,认为这一定是业务需要的,他的工作就完成了。并不对结果进行解析,觉得你们一看应该就知道,这个结果怎么来的。
这将导致,结果在业务上不可用。因为业务人员也不能理解,这些结果有什么用,是什么逻辑产生的,有什么价值等。
7. 炫技
炫技:有一种新算法,这个项目一定要使用。
这可是最新的论文,能解决xx问题,在哪个杂志发表了,设计到几百个特征,几十的调参变量,50层以上的神经网络。
这种做法,会把项目带入无尽的复杂度。如果真是复杂度匹配的项目,那么这么做没问题。但如果是一个一般的项目,一个逻辑回归就能很好解决的问题,用上了复杂度过高的模型,不仅成本会大大超过,而且后期维护调优,更是噩梦。
就类似于糟糕的程序员10年攒下的屎山一样。
8. 只用自己会的技术
只用自己会的技术:我在学校里学过逻辑回归,所以我要用这个模型。
现在国内外的本科和研究生都开了数据科学的课程,在课程中会学到统计学、机器学习等的课程,大家也会掌握一些技术方法和代码的写法。
有些同学结合课堂练习,有可能掌握了1-2种的模型。后面遇到的问题,就全往这1-2个模型中套。有些问题是类似的直接套上直接能用,但是实现的问题,更具有多样性和特殊性,要因地制宜的思考解决办法,而不是套用。
在统计学领域中,有非常多的模型,不可能全在课堂上都学到,我们需要私下里努力从而掌握更多的知识。如果只用自己会的技术,就必然导致对于模型结果的偏差。
9. 模型是万能的
模型是万能的:训练一个模型,想让它干什么,它就能干什么。
说到模型,很多人就把模型直接和AI画上等号,以为AI应该是万能的。
当然chatgpt的横空出世,也进一步推升了这样的想法。现在,随着对chatgpt的熟悉,我们也发现了,在通用领域有大量的使用场景,但在专业领域还是需要专业模型。
因此,模型不是万能的,一个模型也只能解决一类的问题,如果想让他万能,就多种一些有效的专业模型,形成模型集群吧。
9. 模型应该是不花钱的
模型应该是不花钱的:既想马而跑得快,又想马儿不吃草。
训练一个模型有着巨大的成本开销,包括是高级人才的成本,服务器算力的成本,数据采集的成本,数据存储的成本,数据标记的成本等等。
人才是最宝贵,掌握核心技术的人才,可以真的让我们梦想成真。但奇葩的是,国内大部分信息化项目,人都按外包成本算,按岁数划分人头的成本,设备和数据都比人值钱。
如果要想在人把成本拉平,就需要多多的报人头。为啥科技含量这么高的项目,人这么不值钱呢。
10. 既要..又要..也要..还要
当一个模型被赋予了诸多的使命时,做出来是个四不像,谁都想用,谁都用不起来,那么这个项目必然会失败。
甲方客户,通常都有很多的需求。
- 既要模型准,又要速度快,也要使用简单,还要成本低。
- 既要解决业务问题,又要能模型自己能学业务逻辑,也要能说数据进行预警,还要对未来公司战略给出建议。
- 既要服务于一线工作人员解决业务落地,又要服务于公司运营能自己出完美绩效报表,也要智能设计公司宣传文案,还要自动生成给领导汇报的材料。
- …
一个做了数据分析多年的老兵,自我发出一些感慨!
数据分析是一件很有价值的事情,但是我们也有太多的枷锁需要去克服。希望2025年,数据分析师们,用专业创造未来。争取有点时间,写个数据分析的系列出来!
转载请注明出处:
http://blog.fens.me/data-analysis-factor-top9/