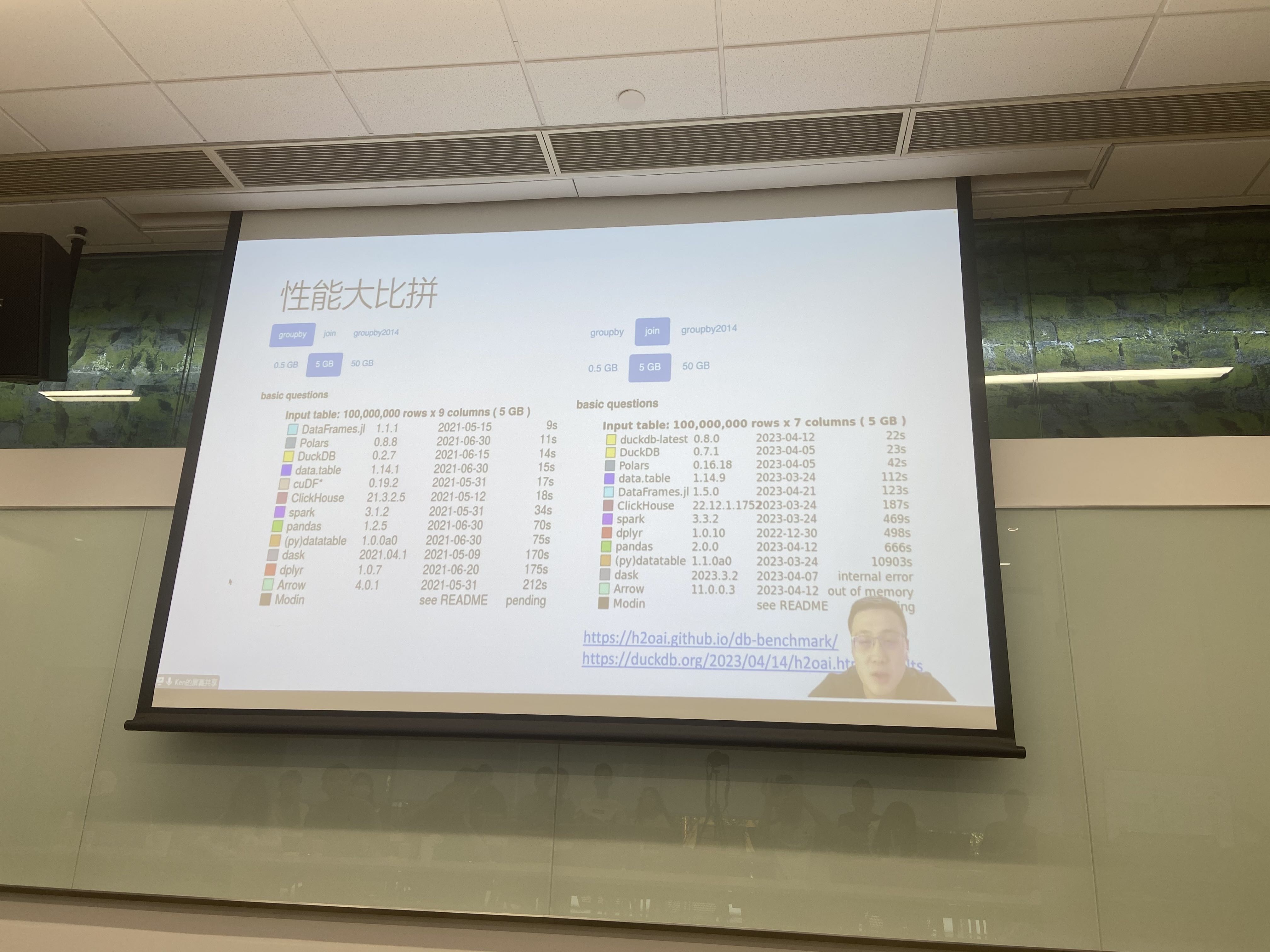
架构师的信仰系列文章,主要介绍我对系统架构的理解,从我的视角描述各种软件应用系统的架构设计思想和实现思路。
从程序员开始,到架构师一路走来,经历过太多的系统和应用。做过手机游戏,写过编程工具;做过大型Web应用系统,写过公司内部CRM;做过SOA的系统集成,写过基于Hadoop的大数据工具;做过外包,做过电商,做过团购,做过支付,做过SNS,也做过移动SNS。以前只用Java,然后学了PHP,现在用R和Javascript。最后跳出IT圈,进入金融圈,研发量化交易软件。
架构设计就是定义一套完整的程序规范,坚持架构师的信仰,做自己想做的东西。
关于作者:
转载请注明出处:
http://blog.fens.me/ai-sora

前言
2024年初,AIGC领域迎来跨时代技术大爆发,OpenAl发布Sora引领了新一轮的科技革命。我受邀请参加2024 Global AI Bootcamp,参加圆桌讨论:畅谈Sora新纪元下的行业变革与商业价值。会议页面:2024 Global AI Bootcamp: 畅谈Sora新纪元下的行业变革与商业价值。
我本身就处于数据分析行业,一直有关注于大模型的进展,特别是怕Sora(chatgpt) 的强大,很快会把我也进行替代,因此做了一些调研。观点不成熟,而且仅聚焦于我所处于的行业。
目录
- 我的背景
- Sora通用大模型目前还不完美
- 世界模拟器:想象空间很大
- 专业领域模型有自己的生成逻辑
- 数据分析,如何结合大语言模型
1. 我的行业背景
我是张丹,技术出身,擅长R语言,一直还处于一线做数据分析。公司是北京青萌数海科技有限公司,服务于政府客户,以数据分析、数据建模为主。
在大数据时代,各个政府部门也积累了大量的数据,但是还主要以专家经验为核心,我们通过AI模型,可以极大的提升监管的效率,提升命中的准确率。
像chatgpt,sora生成式的大模型,我们也很关注,一方面担心被替代,另一方面也在思考怎么能结合实际工作的特点,提升数据分析的效率。
2. Sora通用大模型目前还不完美
我的主要观点,目前来看Sora(chatgpt),为代表的通用大模型目前还不完美。
我们所从事的数据分析领域模型和生成式大模型底层逻辑是不同的,从感觉上chatgpt在数据分析领域落地,还是比较难的。这种“落地”是能够直接替代 数据分析师 的落地,而不是指为 数据分析师 提供工具,还是离不开大量人工的辅助工具化。
我认为通用大模型(chatgpt) 和 专业领域模型(机器学习、深度学习、强化学习),能力并一样。
特别是从评价的角度,通用大模型,现在都是一种“感觉”的评价,比如大模型chatgpt 写的文字不错,Sora生成画面很舒服,感觉很真实。而专业领域模型需要有明确的目标,要求准确、高效。比如,我们需要明确找到 在100万笔电商的订单中,哪笔订单有问题,是否可能为走私、逃税的违法操作。
各个行业其实都有自己的法律、规范、要求等明确的依据条文,业务人员根据这些条文的要求设定规则,专业领域模型(机器学习)通过泛化能力,以概率的方式转化对规则边界定义,但依然保持着对目标的方向的锁定。而chatgpt大模型,似乎又近一步做了泛化,将导致对于目标的清晰度近一步丢失。
我个人感觉,大模型能落地的部分,还是面向toC的娱乐领域,在toB/toG领域还有一段路要走。就好比 短视频 和 电影,一个是消遣和娱乐,一个是高质量和深度。领域不同,要求不同。
2. 世界模拟器:想象空间很大
OpenAI 提出Sora是世界模拟器,而不是简单的文生视频的工具,这无疑是增加了大家对Sora的未来的想象力,为了更高的估值,获得更多的资金。
当然,Sora的能力确实能给我们眼前一亮的感觉,大幅领先于同时期的模型,可以把原来做不到的进行实现。
再科幻一点的想象,Sora生成的视频,不是一个纯计算机的数字化计算。而是创造一个平行世界,把平行世界中的内容展示出来,就像神创造了人类,人类就是sora世界中的神。不仅可以对未来做预测,也可以重现历史上任何事情的发生。所以,OpenAI要做万亿美元的融资,增加算力。那么,可能就到了人类的末日了(科幻领域)。
但现在Chatgpt大模型公布的生成机理上,还到不了智慧化的水平,可能一种探索的方向。
不管是chatgpt,还是sora,都是基于Transformer框架,用到的计算机数字计算的一种方式。 chatgpt的训练,是把所有收集的文档内容,通过遮盖文档的一部分,进行预测,来建立所有文字之间的上下文关系。当我们输入一个问题,chatgpt把他已知的文字向量关系输出给我们。对于sora的训练,是把所有收集的图片,通过打马赛克的方式进行遮挡,再反向通过全马赛克开始进行预测,从而输出一幅高质量图片,再加上时间轴连成视频。
3. 专业领域模型有自己的生成逻辑
专业领域模型通常有自己的计算逻辑,专业领域模型,一种是科学领域,一种是应用领域。
在科学领域:
- 央视报道:AI 仅用6周时间破解了移民火星的生存之谜,模拟243次实验,从数百万的方法中,找到了产生氧气的黄金配方,15小时,暴力穷举,足够人类生存的氧气。
- 用AI进行科学研究,找到抗生素Halicin,能够杀灭对已知抗生素产生耐药性的细菌菌株。研究小组找到包含2000种已知特性分子数据库,标记是否能组织细菌生长,进行模型训练,自动识别哪些分子能进行抗菌。最后用来审查FDA批准的药物,和天然产品库的6万多种不同的分子结构。
- Google推出的 GraphCast 产品预测天气预报,1 分钟内预测未来 10 天的天气,GraphCast 是一种基于机器学习和图神经网络 (GNN) 的天气预报系统,比传统方法便宜 1000 倍。
在应用领域:
- 量化交易模型,根据金融市场交易的数据、信息、规则等,设计模型构建交易策略,实现基金的盈利。
- 风险甄别模型,根据进出口货物贸易的法规、报关单数据、国际形势变化等,发现走私、逃税、洗钱等风险。
在专业领域中,我们都是从目标出发,到底要解决什么问题。那么,我们在培养一个专业的数据分析师时,一般会按照专家路线,从业务入手,边做边理解。但反观大模型的生成式的训练过程,其实与培养人的过程是不同的。
因此,大模型在短期内,应该还不能把我们替代。
4. 数据分析,如何结合大语言模型
如果不能替代,那么就考虑怎么结合。
让大模型结合专业领域模型,是一种可行的路径。以大模型为主线,打通各个孤立的专业领域模型。比如:天气+粮食+进出口贸易+国际形势 = ? 是否会有粮食危机。药品 + 疾病 + 基因 + 政策 = ?会出现什么。
从而找到市场的空白点,帮助数据分析师找到新的思路。
数据分析领域,我们也有一些痛点:
痛点一,随着chatgpt在生活中的普及,同时提升了大家的认知水平。做数据分析的从业者,又开始要面对领导提出问题,现在AI这么牛了,把数据给了模型,结果就出来了,应该要想什么就有什么,为什么你们做不到。说技术听不懂,说成本预算有限。所以,toG 的项目,也是挺难干的。
痛点二,整个的数据分析过程,对于大部分没有一线参与建模的人来说,还是不理解的,就像我们也不理解chatgpt,sora的一样,只是根据效果、论文、别人的解释,进行理解。如果通用人工智能,如果可以把整个的数据处理、加工、建模过程,可视化、解释性,进行解释出来,就是把专业的知识简单化,就可以大幅提升数据分析行业效率。
最后,说说我理解的 大模型toG落地。从技术上来讲,建模过程主要是训练和推理。训练:通过海量的高质量数据进行训练,特别是结合内网数据,结合知识图谱数据,可以大幅提升行业模型的适配度,让AI懂行业。推理:结合专业领域模型,进行推理的模拟,进行目标导向,提升准确率。
如果有一天实现了 适用于各个行业通用的推理引擎,专业领域模型就真的可以被替代了,也许世界模拟器,也就能真正实现了。
观点不成熟,而且仅聚焦于我所处于的行业。
转载请注明出处:
http://blog.fens.me/ai-sora