R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-cosine-similarity/
前言
在文字处理时,我们经常需要判断两段文字是否相似,如果这两段文字的用词越相似,它们的内容就应该越相似。这个场景下,我们就可以考虑先把文字转换成词频向量,然后用余弦相似度来判断是否相似。
目录
- 余弦相似度介绍
- R语言实现余弦相似度
- 计算2个文本的相似度
1. 余弦相似度介绍
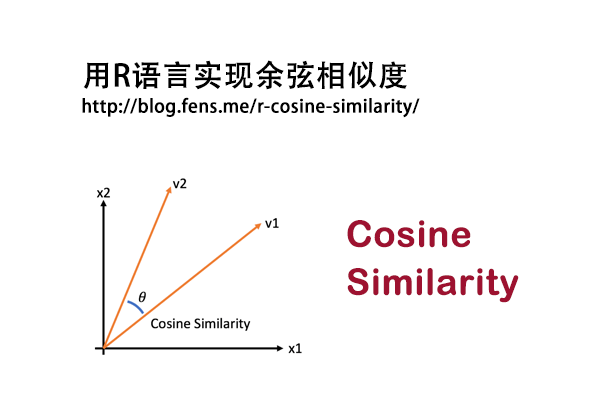
余弦相似度,通过测量两个向量的夹角的余弦值来度量它们之间的相似性。例如,将两篇文章向量化,余弦距离可以避免因为文章的长度不同而导致距离偏大,余弦距离只考虑两篇文章生成的向量的夹角。
余弦相似度被大量用于对比:如人脸对比、声音对比,来快速判断两个图片或者两段声音的相似度,进而判断是不是来自同一个人。当一个图像或者声音样本具有n维的特征,我们就可以把他认为是n维向量,两个样本使用余弦相似度比对时,就是对两个n维向量的夹角余弦值,其大小进行衡量。
余弦相似度的取值范围是[-1,1],相同两个向量的之间的相似度为1。余弦距离的取值范围是[0,2]。
- 当夹角为0,两个向量同向,相当于相似度最高,余弦值为1,表示完全正相关。
- 当夹角90°,两个向量垂直,余弦为0,表示不相关。
- 当夹角180°,两个向量反向,余弦为-1,表示完全负相关。
计算公式:
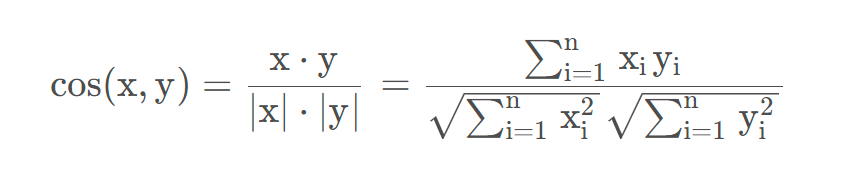
相比其他的距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
欧式距离与余弦距离的对比:
- 欧式距离的数值受到维度的影响,余弦相似度在高维的情况下也依然保持低维完全相同时相似度为1等性质。
- 欧式距离体现的是距离上的绝对差异,余弦距离体现的是方向上的相对差异。
不同情况不同选择:
- 两个人分别取了蓝球(1,0)与红球(0,1),这两个向量的欧式距离较小,可是事实是这两个球是不同的,而余弦距离为2表示的是完全不同的意思。所以在这种情况下选择余弦距离更具合理性。
- 两个人对APP的使用次数与使用时长分别表示为(1,10),(10,100),可知余弦相似度较小,说明这两个人的行为时相同的,可是,事实是不同的,两个人的活跃度有着极大的差异,第二个人的活跃度更高。
2. R语言实现余弦相似度
我们可以安装lsa包,使用cosine()函数,计算2个向量的余弦相似度。
lsa(Latent Semantic Analysis 潜在语义分析)包基本思想是,文本确实具有高阶(=潜在语义)结构,但这种结构会被词语用法(如通过使用同义词或多义词)所掩盖。通过对给定的文档-术语矩阵进行截断奇异值分解(双模式因子分析),以统计方式得出概念指数,从而克服了这一可变性问题。
lsa包的安装过程比较简单。
> install.packages(lsa)
> library(lsa>
计算2个向量的余弦相似度。
> vec1 = c( 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 )
> vec2 = c( 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0 )
> cosine(vec1,vec2)
[,1]
[1,] 0.2357023
3. 计算2个文本的相似度
有了计算余弦相似度的工具后,那么接下来,我们就可以尝试计算文本的相似度了。
使用余弦相似度,计算文本相似的具体步骤:
- 定义两个文本内容
- 对两个文本内容进行分词
- 列出所有的词,并计算词频
- 整理词频为词向量
- 用余弦相似度计算词向量
第一步,我们定义两段文本内容,分别是
- 句子1:”我买了一个手机,又配了一个手机壳”
- 句子2:”我有3年没有换新手机了,还是原来的手机壳”
> txt1<-"我买了一个手机,又配了一个手机壳"
> txt2<-"我有3年没有换新手机了,还是原来的手机壳"
第二步,对上面2个句子进行分词,这里我们使用jiebaR包进行分词,关于jiebaR包的具体用法,请参考文章R语言中文分词包jiebaR
# 加载jiabaR包
> library(jiebaR)
# 定义分词引擎
> wk<-worker()
# 分别对两个文本进行分词
> w1<-wk[txt1]
> w2<-wk[txt2]
第三步,进出所有的词,并查看词频
> w1
[1] "我" "买" "了" "一个" "手机" "又" "配" "了" "一个" "手机" "壳"
> w2
[1] "我" "有" "3" "年" "没有" "换" "新手机" "了" "还是" "原来" "的"
[12] "手机" "壳"
# 查看词频
> table(w1)
w1
壳 了 买 配 手机 我 一个 又
1 2 1 1 2 1 2 1
> table(w2)
w2
3 的 还是 换 壳 了 没有 年 手机 我 新手机 有 原来
1 1 1 1 1 1 1 1 1 1 1 1 1
第四步,整理词频为词向量,这里我把生成词向量过程,封装成一个函数叫dfm(),形成单词矩阵。
# 加载工具包
> library(plyr)
> library(magrittr)
# 封装词向量函数
> dfm<-function(w1,w2){
+ t1<-table(w1) %>% ldply
+ t2<-table(w2) %>% ldply
+ names(t1)<-c("seg","cnt1")
+ names(t2)<-c("seg","cnt2")
+ mm<-merge(t1,t2,by="seg",all=TRUE)
+ mm$cnt1[which(is.na(mm$cnt1))]<-0
+ mm$cnt2[which(is.na(mm$cnt2))]<-0
+ list(dat=t(mm[,-1]),seg=mm$seg)
+ }
# 查看词向量的输出结果
> m<-dfm(w1,w2);m
$dat
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
cnt1 0 0 0 0 1 2 1 0 0 1 2 1 0 2 0 1 0
cnt2 1 1 1 1 1 1 0 1 1 0 1 1 1 0 1 0 1
$seg
[1] "3" "的" "还是" "换" "壳" "了" "买" "没有" "年" "配" "手机"
[12] "我" "新手机" "一个" "有" "又" "原来"
第五步,用余弦相似度计算词向量的相似度,即两段文本的余弦相似度。结果是0.4,表示不是太相似。
> library(lsa)
> cosine(m$dat[1,],m$dat[2,])
[,1]
[1,] 0.4036037
那我们换一组句子再试试,比如
- 句子1:如果这两句话的用词越相似,它们的内容就应该越相似。
- 句子2:如果这两句话的内容越相似,它们的用词也应该越相似。
用R语言计算上面2个句子的余弦相似度,得0.95,表示非常相似了。
> txt1<-"如果这两句话的用词越相似,它们的内容就应该越相似"
> txt2<-"如果这两句话的内容越相似,它们的用词也应该越相似"
> w1<-wk[txt1]
> w2<-wk[txt2]
> m<-dfm(w1,w2);m
$dat
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
cnt1 2 1 1 1 1 1 2 0 1 1 2 1
cnt2 2 0 1 1 1 1 2 1 1 1 2 1
$seg
[1] "的" "就" "两句话" "内容" "如果" "它们" "相似" "也" "应该" "用词" "越"
[12] "这"
> cosine(m$dat[1,],m$dat[2,])
[,1]
[1,] 0.95
本文我们了解余弦相似度的原理和实现,并且应用了余弦相似度计算,从而可以判断两个文本之间的相似程度,让我们进行文本匹配时又多了一种方法。本文代码:https://github.com/bsspirit/r-string-match/blob/main/cosine.r
转载请注明出处:
http://blog.fens.me/r-cosine-similarity/
