Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/

前言
Mahout是Hadoop家族一员,从血缘就继承了Hadoop程序的特点,支持HDFS访问和MapReduce分步式算法。随着Mahout的发展,从0.7版本开始,Mahout做了重大的升级。移除了部分算法的单机内存计算,只支持基于Hadoop的MapReduce平行计算。
从这点上,我们能看出Mahout走向大数据,坚持并行化的决心!相信在Hadoop的大框架下,Mahout最终能成为一个大数据的明星产品!
目录
- Mahout开发环境介绍
- Mahout基于Hadoop的分步环境介绍
- 用Mahout实现协同过滤ItemCF
- 模板项目上传github
1. Mahout开发环境介绍
在 用Maven构建Mahout项目 文章中,我们已经配置好了基于Maven的Mahout的开发环境,我们将继续完成Mahout的分步式的程序开发。
本文的mahout版本为0.8。
开发环境:
- Win7 64bit
- Java 1.6.0_45
- Maven 3
- Eclipse Juno Service Release 2
- Mahout 0.8
- Hadoop 1.1.2
找到pom.xml,修改mahout版本为0.8
<mahout.version>0.8</mahout.version>然后,下载依赖库。
~ mvn clean install由于 org.conan.mymahout.cluster06.Kmeans.java 类代码,是基于mahout-0.6的,所以会报错。我们可以先注释这个文件。
2. Mahout基于Hadoop的分步环境介绍
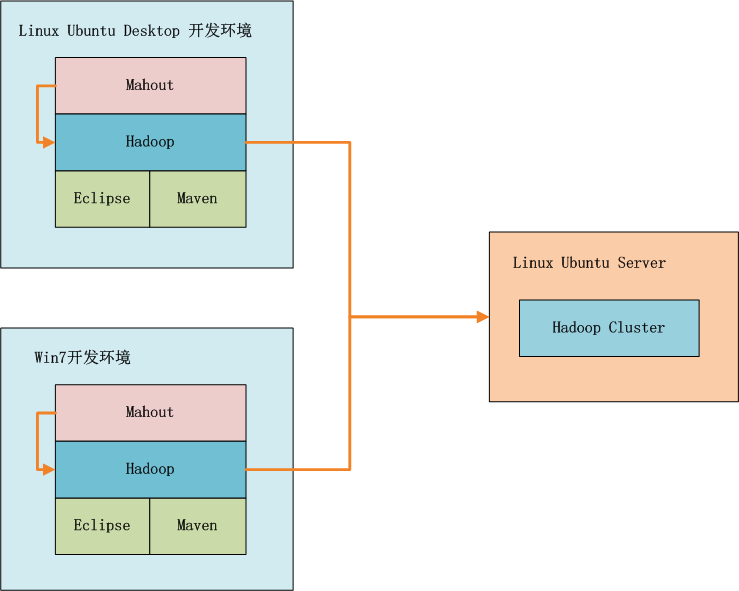
如上图所示,我们可以选择在win7中开发,也可以在linux中开发,开发过程我们可以在本地环境进行调试,标配的工具都是Maven和Eclipse。
Mahout在运行过程中,会把MapReduce的算法程序包,自动发布的Hadoop的集群环境中,这种开发和运行模式,就和真正的生产环境差不多了。
3. 用Mahout实现协同过滤ItemCF
实现步骤:
- 1. 准备数据文件: item.csv
- 2. Java程序:HdfsDAO.java
- 3. Java程序:ItemCFHadoop.java
- 4. 运行程序
- 5. 推荐结果解读
1). 准备数据文件: item.csv
上传测试数据到HDFS,单机内存实验请参考文章:用Maven构建Mahout项目
~ hadoop fs -mkdir /user/hdfs/userCF
~ hadoop fs -copyFromLocal /home/conan/datafiles/item.csv /user/hdfs/userCF
~ hadoop fs -cat /user/hdfs/userCF/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
2). Java程序:HdfsDAO.java
HdfsDAO.java,是一个HDFS操作的工具,用API实现Hadoop的各种HDFS命令,请参考文章:Hadoop编程调用HDFS
我们这里会用到HdfsDAO.java类中的一些方法:
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
hdfs.cat(inFile);
3). Java程序:ItemCFHadoop.java
用Mahout实现分步式算法,我们看到Mahout in Action中的解释。
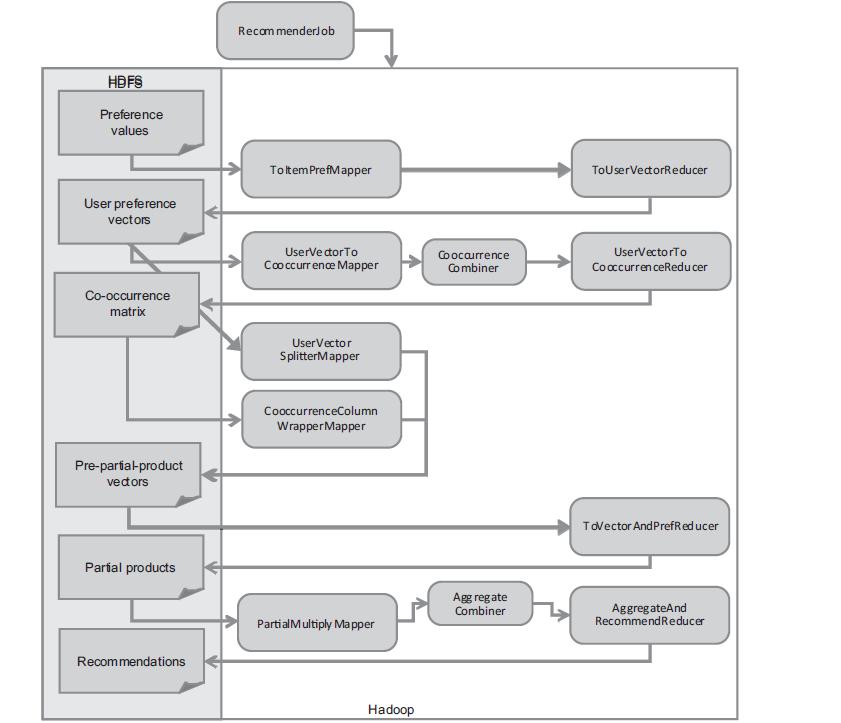
实现程序:
package org.conan.mymahout.recommendation;
import org.apache.hadoop.mapred.JobConf;
import org.apache.mahout.cf.taste.hadoop.item.RecommenderJob;
import org.conan.mymahout.hdfs.HdfsDAO;
public class ItemCFHadoop {
private static final String HDFS = "hdfs://192.168.1.210:9000";
public static void main(String[] args) throws Exception {
String localFile = "datafile/item.csv";
String inPath = HDFS + "/user/hdfs/userCF";
String inFile = inPath + "/item.csv";
String outPath = HDFS + "/user/hdfs/userCF/result/";
String outFile = outPath + "/part-r-00000";
String tmpPath = HDFS + "/tmp/" + System.currentTimeMillis();
JobConf conf = config();
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
hdfs.cat(inFile);
StringBuilder sb = new StringBuilder();
sb.append("--input ").append(inPath);
sb.append(" --output ").append(outPath);
sb.append(" --booleanData true");
sb.append(" --similarityClassname org.apache.mahout.math.hadoop.similarity.cooccurrence.measures.EuclideanDistanceSimilarity");
sb.append(" --tempDir ").append(tmpPath);
args = sb.toString().split(" ");
RecommenderJob job = new RecommenderJob();
job.setConf(conf);
job.run(args);
hdfs.cat(outFile);
}
public static JobConf config() {
JobConf conf = new JobConf(ItemCFHadoop.class);
conf.setJobName("ItemCFHadoop");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
}
RecommenderJob.java,实际上就是封装了,上面整个图的分步式并行算法的执行过程!如果没有这层封装,我们需要自己去实现图中8个步骤MapReduce算法。
关于上面算法的深度剖析,请参考文章:R实现MapReduce的协同过滤算法
4). 运行程序
控制台输出:
Delete: hdfs://192.168.1.210:9000/user/hdfs/userCF
Create: hdfs://192.168.1.210:9000/user/hdfs/userCF
copy from: datafile/item.csv to hdfs://192.168.1.210:9000/user/hdfs/userCF
ls: hdfs://192.168.1.210:9000/user/hdfs/userCF
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv, folder: false, size: 229
==========================================================
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
2013-10-14 10:26:35 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-10-14 10:26:35 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:35 org.apache.hadoop.io.compress.snappy.LoadSnappy
警告: Snappy native library not loaded
2013-10-14 10:26:36 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:36 org.apache.hadoop.io.compress.CodecPool getCompressor
信息: Got brand-new compressor
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:36 org.apache.hadoop.io.compress.CodecPool getDecompressor
信息: Got brand-new decompressor
2013-10-14 10:26:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 42 bytes
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2013-10-14 10:26:36 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/itemIDIndex
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=187
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=3287330
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=916
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=3443292
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=645
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=229
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=46
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map input records=21
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=84
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=376569856
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=116
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:37 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0002
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_m_000000_0' done.
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 68 bytes
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0002_r_000000_0 is allowed to commit now
2013-10-14 10:26:37 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0002_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/userVectors
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_r_000000_0' done.
2013-10-14 10:26:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0002
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Counters: 20
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.cf.taste.hadoop.item.ToUserVectorsReducer$Counters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: USERS=5
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=288
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=6574274
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=1374
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=6887592
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=1120
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=229
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=72
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map input records=21
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=42
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=63
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=575930368
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=116
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=21
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=5
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=5
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:38 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0003
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0003_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0003_m_000000_0' done.
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:38 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 89 bytes
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0003_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0003_r_000000_0 is allowed to commit now
2013-10-14 10:26:38 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0003_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/ratingMatrix
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0003_r_000000_0' done.
2013-10-14 10:26:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0003
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Counters: 21
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=335
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.cf.taste.hadoop.preparation.ToItemVectorsMapper$Elements
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: USER_RATINGS_NEGLECTED=0
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: USER_RATINGS_USED=21
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=9861349
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=1950
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=10331958
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=1751
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=288
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=93
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map input records=5
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=336
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=775290880
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=157
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:39 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0004
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0004_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0004_m_000000_0' done.
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:39 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 118 bytes
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0004_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0004_r_000000_0 is allowed to commit now
2013-10-14 10:26:39 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0004_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/weights
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0004_r_000000_0' done.
2013-10-14 10:26:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0004
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Counters: 20
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=381
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=13148476
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=2628
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=13780408
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=2551
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=335
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$Counters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: ROWS=7
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=122
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map input records=7
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=16
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=516
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=974651392
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=158
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Combine input records=24
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=8
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=8
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Combine output records=8
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=5
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map output records=24
2013-10-14 10:26:40 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0005
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0005_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0005_m_000000_0' done.
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 121 bytes
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0005_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0005_r_000000_0 is allowed to commit now
2013-10-14 10:26:40 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0005_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/pairwiseSimilarity
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0005_r_000000_0' done.
2013-10-14 10:26:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0005
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Counters: 21
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=392
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=16435577
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=3488
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=17230010
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=3408
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=381
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$Counters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: PRUNED_COOCCURRENCES=0
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: COOCCURRENCES=57
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=125
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map input records=5
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=744
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1174011904
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=129
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:41 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0006
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0006_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0006_m_000000_0' done.
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:41 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 158 bytes
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0006_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0006_r_000000_0 is allowed to commit now
2013-10-14 10:26:41 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0006_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/similarityMatrix
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0006_r_000000_0' done.
2013-10-14 10:26:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0006
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=554
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=19722740
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=4342
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=20674772
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=4354
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=392
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=162
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map input records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=599
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1373372416
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=140
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Combine input records=25
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map output records=25
2013-10-14 10:26:42 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:42 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0007
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_m_000000_0' done.
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_m_000001_0 is done. And is in the process of commiting
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_m_000001_0' done.
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 2 sorted segments
2013-10-14 10:26:42 org.apache.hadoop.io.compress.CodecPool getDecompressor
信息: Got brand-new decompressor
2013-10-14 10:26:42 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 2 segments left of total size: 233 bytes
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0007_r_000000_0 is allowed to commit now
2013-10-14 10:26:42 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0007_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/partialMultiply
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_r_000000_0' done.
2013-10-14 10:26:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0007
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=572
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=34517913
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=8751
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=36182630
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=7934
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=241
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map input records=12
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=56
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=453
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=2558459904
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=665
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=28
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map output records=28
2013-10-14 10:26:43 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0008
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0008_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0008_m_000000_0' done.
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:43 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 206 bytes
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0008_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0008_r_000000_0 is allowed to commit now
2013-10-14 10:26:43 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0008_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/userCF/result
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0008_r_000000_0' done.
2013-10-14 10:26:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0008
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=217
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=26299802
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=7357
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=27566408
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=6269
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=572
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=210
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map input records=7
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=42
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=927
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1971453952
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=137
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=21
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=5
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=5
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/result//part-r-00000
1 [104:1.280239,106:1.1462644,105:1.0653841,107:0.33333334]
2 [106:1.560478,105:1.4795978,107:0.69935876]
3 [103:1.2475469,106:1.1944525,102:1.1462644]
4 [102:1.6462644,105:1.5277859,107:0.69935876]
5 [107:1.1993587]
5). 推荐结果解读
我们可以把上面的日志分解析成3个部分解读
- a. 初始化环境
- b. 算法执行
- c. 打印推荐结果
a. 初始化环境
出初HDFS的数据目录和工作目录,并上传数据文件。
Delete: hdfs://192.168.1.210:9000/user/hdfs/userCF
Create: hdfs://192.168.1.210:9000/user/hdfs/userCF
copy from: datafile/item.csv to hdfs://192.168.1.210:9000/user/hdfs/userCF
ls: hdfs://192.168.1.210:9000/user/hdfs/userCF
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv, folder: false, size: 229
==========================================================
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv
b. 算法执行
分别执行,上图中对应的8种MapReduce算法。
Job complete: job_local_0001
Job complete: job_local_0002
Job complete: job_local_0003
Job complete: job_local_0004
Job complete: job_local_0005
Job complete: job_local_0006
Job complete: job_local_0007
Job complete: job_local_0008
c. 打印推荐结果
方便我们看到计算后的推荐结果
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/result//part-r-00000
1 [104:1.280239,106:1.1462644,105:1.0653841,107:0.33333334]
2 [106:1.560478,105:1.4795978,107:0.69935876]
3 [103:1.2475469,106:1.1944525,102:1.1462644]
4 [102:1.6462644,105:1.5277859,107:0.69935876]
5 [107:1.1993587]
4. 模板项目上传github
https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8
大家可以下载这个项目,做为开发的起点。
~ git clone https://github.com/bsspirit/maven_mahout_template
~ git checkout mahout-0.8
我们完成了基于物品的协同过滤分步式算法实现,下面将继续介绍Mahout的Kmeans的分步式算法实现,请参考文章:Mahout分步式程序开发 聚类Kmeans
转载请注明出处:
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/

[…] 下一篇:Mahout分步式程序开发 基于物品的协同过滤ItemCF […]
[…] 接上一篇文章:Mahout分步式程序开发 基于物品的协同过滤ItemCF […]
写的非常好,还有一些地方我不太明白:
开发环境必须是集群的一个节点么?如果不是开发环境是怎么知道hadoop集群的相关信息的?是不是将集群master主机的hadoop文件夹复制到开发机本地,然后再conifg()里面调用它的xml文件?maven项目编译之后生成的jar,是需要手动提交job到hadoop集群上,还是通过eclipse的某个插件?怎么在ide上调试运行在hadoop集群上的mahout程序?
Thank you!
1. 开发环境与集群没有关系
2. 把master的配置文件复制到开发环境
3. 我没有通过maven编译,在eclipse里编译,JobConf类,会完成打包上传的工作。
4. 没有用到eclipse的插件
5. 我有在IDE里debug远程hadoop,这个习惯不太好。
6. 似乎你对于hadoop开发还不是太熟悉,先不要考虑mahout的事情。
7. 看这篇文章,先把hadoop学会。
http://blog.fens.me/hadoop-maven-eclipse/
请问该算法的推荐质量如何评价呢?有计算mae的方法吗,谢谢
1. mae 是什么?
2. 推荐质量如何评价
http://blog.fens.me/mahout-recommendation-api
这个评价是单机上的吧,有分布式的评价方法吗
我也是同样的问题,请问你现在解决了嘛?
[…] Mahout的实现方案,请参考文章:Mahout分步式程序开发 基于物品的协同过滤ItemCF […]
[…] 开发环境mahout版本为0.8。 ,请参考文章:用Maven构建Mahout项目 […]
请教Mahout的taste算法如何实现分布式计算?其中DataModel的数据源是读取Mongodb的数据库。
把MongoDB的数据,导入到HDFS
您好,我用mahout的taste方法做了电影的推荐算法,数据是从mongodb读取生成datamodule。现想用mapreduce实现分布式运算,请您指教该如何做?
请问如何用mahout读取mongodb
通过java的mongodb的API就可以访问了。
http://docs.mongodb.org/ecosystem/drivers/java/
请教:在 cdh 5 的环境中运行程序,出现以下的exception,请问帮助分析问题的原因和解决方法,谢谢。
[hdfs@hadoop140 mahout]$ hadoop jar /home/mahout/myMahout.jar
mahout in hadoop cluster running…
14/04/25 17:21:16 INFO common.AbstractJob: Command line arguments: {–booleanData=[true], –endPhase=[2147483647], –input=[hdfs://192.168.1.140:9000/user/hdfs/userCF], –maxPrefsPerUser=[10], –maxPrefsPerUserInItemSimilarity=[1000], –maxSimilaritiesPerItem=[100], –minPrefsPerUser=[1], –numRecommendations=[10], –output=[hdfs://192.168.1.140:9000/user/hdfs/userCF/result/], –similarityClassname=[org.apache.mahout.math.hadoop.similarity.cooccurrence.measures.EuclideanDistanceSimilarity], –startPhase=[0], –tempDir=[hdfs://192.168.1.140:9000/tmp/1398417675558]}
14/04/25 17:21:16 INFO common.AbstractJob: Command line arguments: {–booleanData=[true], –endPhase=[2147483647], –input=[hdfs://192.168.1.140:9000/user/hdfs/userCF], –maxPrefsPerUser=[1000], –minPrefsPerUser=[1], –output=[hdfs://192.168.1.140:9000/tmp/1398417675558/preparePreferenceMatrix], –ratingShift=[0.0], –startPhase=[0], –tempDir=[hdfs://192.168.1.140:9000/tmp/1398417675558]}
14/04/25 17:21:17 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
14/04/25 17:21:17 INFO Configuration.deprecation: mapred.compress.map.output is deprecated. Instead, use mapreduce.map.output.compress
14/04/25 17:21:17 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
Exception in thread “main” java.lang.IncompatibleClassChangeError: Found interface org.apache.hadoop.mapreduce.JobContext, but class was expected
at org.apache.mahout.common.HadoopUtil.getCustomJobName(HadoopUtil.java:174)
at org.apache.mahout.common.AbstractJob.prepareJob(AbstractJob.java:614)
at org.apache.mahout.cf.taste.hadoop.preparation.PreparePreferenceMatrixJob.run(PreparePreferenceMatrixJob.java:75)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.mahout.cf.taste.hadoop.item.RecommenderJob.run(RecommenderJob.java:158)
at org.conan.mymahout.recommendation.ItemCFHadoop.main(ItemCFHadoop.java:40)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
错误已经提示了IncompatibleClassChangeError, 你的版本不兼容。
执行的是此文中的代码,能具体讲讲是哪方面不兼容吗?
你为什么不用文章中指定版本的Hadoop呢?
好吧,我的当前的开发环境以及未来的生产环境都将为CDH5。在项目中修改所依赖的CDH5的0.8 distribution of Mahout,我想应该可行。
你既然已经选择了版本,是否与mahout 0.8兼容的问题,就要自己解决了。应该没有人能回答你遇到的问题。
你好,请教下,我按你的方式搭建了这样一个mahout分布式平台,并运行程序,出现以下异常:
Delete: hdfs://localhost:9000/user/hadoop/input
Create: hdfs://localhost:9000/user/hadoop/input
copy from: datafile/item.csv to hdfs://localhost:9000/user/hadoop/input
ls: hdfs://localhost:9000/user/hadoop/input
==========================================================
name: hdfs://localhost:9000/user/hadoop/input/item.csv, folder: false, size: 211
==========================================================
cat: hdfs://localhost:9000/user/hadoop/input/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
SLF4J: Failed to load class “org.slf4j.impl.StaticLoggerBinder”.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
六月 08, 2014 10:07:14 上午 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
六月 08, 2014 10:07:14 上午 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
六月 08, 2014 10:07:14 上午 org.apache.hadoop.io.compress.snappy.LoadSnappy
警告: Snappy native library not loaded
六月 08, 2014 10:07:14 上午 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
六月 08, 2014 10:07:15 上午 org.apache.hadoop.util.ProcessTree isSetsidSupported
信息: setsid exited with exit code 0
六月 08, 2014 10:07:15 上午 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@1d69103
六月 08, 2014 10:07:15 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
六月 08, 2014 10:07:15 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
六月 08, 2014 10:07:15 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
六月 08, 2014 10:07:15 上午 org.apache.hadoop.mapred.LocalJobRunner$Job run
警告: job_local_0001
java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.mahout.cf.taste.hadoop.item.ItemIDIndexMapper.map(ItemIDIndexMapper.java:50)
at org.apache.mahout.cf.taste.hadoop.item.ItemIDIndexMapper.map(ItemIDIndexMapper.java:31)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:214)
六月 08, 2014 10:07:15 上午 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 0% reduce 0%
六月 08, 2014 10:07:16 上午 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
六月 08, 2014 10:07:16 上午 org.apache.hadoop.mapred.Counters log
信息: Counters: 0
Exception in thread “main” java.io.FileNotFoundException: File does not exist: /tmp/1402193231582/preparePreferenceMatrix/numUsers.bin
at org.apache.hadoop.hdfs.DFSClient$DFSInputStream.fetchLocatedBlocks(DFSClient.java:1975)
at org.apache.hadoop.hdfs.DFSClient$DFSInputStream.openInfo(DFSClient.java:1944)
at org.apache.hadoop.hdfs.DFSClient$DFSInputStream.(DFSClient.java:1936)
at org.apache.hadoop.hdfs.DFSClient.open(DFSClient.java:731)
at org.apache.hadoop.hdfs.DistributedFileSystem.open(DistributedFileSystem.java:165)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:427)
at org.apache.mahout.common.HadoopUtil.readInt(HadoopUtil.java:339)
at org.apache.mahout.cf.taste.hadoop.item.RecommenderJob.run(RecommenderJob.java:167)
at org.conan.mymahout.ItemCFHadoop.main(ItemCFHadoop.java:37)
我觉得第二个异常的出现是非常相关于第一个异常的,
第一个异常 数组越界,并且下标为1就越界了,表示数组长度只有1。并且是在job.run方法进去后 触发的。另外我搭建了你博文的用maven搭建mahout项目是运行成功的,那么问题可能出现在hadoop上了??
Hadoop, Mahout, Java的版本,是否与文章中一致?
你好,有没有朋友问你File does not exist: /tmp/1402193231582/preparePreferenceMatrix/numUsers.bin这个问题的,我现在修改之后第一个job成功,执行第二个job的时候报错。
同学,这个问题是那个copyFromLocal函数出了问题,其中local指的是win7系统里面的路径,并非是linux下的文件路径,我的也出现这个问题,改了就好了
请问你的问题解决了吗?我没有出现数组越界,但是也报File does not exist: /tmp/1402193231582/preparePreferenceMatrix/numUsers.bin,恳请指教。
你好,请问在程序中如何设置map 和 reduce的个数呢?
conf.setNumMapTasks(10);
conf.setNumReduceTasks(10);
这样设置了貌似没有效果
开发环境不能设置map 和 reduce的个数,打包到部署环境,通过命令行启动时,可以指定map,reduce个数。
再请问下,我将上述程序打成jar包后怎么运行不了
我的命令是: hadoop jar ***.jar
1. 普通java程序,用java -jar xxx.jar
2. hadoop程序,用hadoop jar xx.jar
3. mahout程序,如果封装mahout的启动器,用了mahout xx.jar,如果没封装mahout启动器,用1或2.
你好!我是新手,正在研读学习博主的这篇研究文章,受益匪浅。
有一个疑问能否请教一下博主:
请问“–booleanData true”这一项参数中,这里的booleanData原本是控制数据文件中是否有评分项。请问如果对于没有评分项的数据,例如只有userID,itemID两列数据的文件,这里到底是设置为true还是false呢?自己试下了下,设置为false后,推荐结果里也是有评分,只是全部都是1.0,而设置为true,则推荐结果里也还都有各自的评分(但都不是1.0)。但是比如博主这里的数据设置为false后的结果反而是:
1 [104:3.5838122,106:3.4916115,105:3.473163]
2 [106:2.8146582,105:2.7573717,107:2.0]
3 [106:3.694073,102:3.657834,103:3.5656683]
4 [107:4.716343,105:4.1627345,102:4.0136285]
5 [107:3.7592773]
对于这个参数的设置有些搞不清,不知能否请博主解释一下?万分感谢。
1. 参数解释:–booleanData (boolean): Treat input data as having no pref values (false),设置true表示有pref,false表无pref。
2. 样本数据是有pref value的,这个参数True/False都会执行,但算法是不一样的,结果是不一样的。
遇到问题,去查查API或源代码,不要只停留在问题表面。
谢谢!
lz的一系列文章真的让我节省了很多学习成本。有一个问题想请教:
本文是基于itemCF的分布式开发,我想做基于userCF的hadoop分布式开发,请问mahou中有类似于代码中“RecommenderJob”这样封装好的类可以调用吗?
我查了下api没有找到,感觉基于userCF的开发可能会没这么容易。
Mahout没有提供分布式的userCF,只有单机版本的userCF。
参考这里 http://blog.fens.me/hadoop-mahout-maven-eclipse/
请问一下这个问题怎么解决
博主你好,后来我回去查了其他一些资料,也做了一些实验,发现原先对这里的booleanData这个参数的理解好像有差异。我认为这里并不是设置true表示有pref,false表无pref。这个booleanData的含义是指输入数据中的评分数据是否是布尔型的,即如果没有评分,应该设置为true,因为若输入数据只有userID、itemID,算法会自动给所有的评分赋值为1。
USER_VECTORS================
{
1={101:1.0,103:1.0,102:1.0},
2={102:1.0,103:1.0,101:1.0,104:1.0},
3={104:1.0,107:1.0,101:1.0,105:1.0},
4={106:1.0,101:1.0,103:1.0,104:1.0},
5={106:1.0,104:1.0,103:1.0,105:1.0,101:1.0,102:1.0}
}
在计算最后推荐项目得分的类AggregateAndRecommendReducer类中有这样一段:
if (booleanData) {
reduceBooleanData(userID, values, context);
} else {
reduceNonBooleanData(userID, values, context);
}
而在 reduceBooleanData方法中,有这样一段注释:
/* having boolean data, each estimated preference can only be 1,
* however we can’t use this to rank the recommended items,
* so we use the sum of similarities for that. */
所以我觉得应该是没有评分设置为true,有评分的设置为false。默认是false。
不知道我这样子理解是否正确。请博主指点。谢谢。
你好,请教个问题,今天重新搭建你用的版本跑这个例子,但是还是有错。java.lang.ClassNotFoundException: com.google.common.primitives.Longs请问遇见过吗?谢谢
我今天也遇到了这个问题,在win7中用eclipse中可以正常运行,放到hadoop集群下,执行mahout hadoop jar test.jar Test,然后就报这个错误,请问你解决了吗,博主能否也帮忙解答一下,3Q
看起来是少是jar包。
我原先也以为是缺少某个jar包,但后来发现这个类是在mahout的安装目录下是有包包含它的,我在Dataguru上发了一个求助帖,描述的比较详细些,能否前往帮忙看一下,谢谢
【求助】Error: java.lang.ClassNotFoundException: com.google.common.primitives…
http://f.dataguru.cn/forum.php?mod=viewthread&tid=453803&fromuid=231904
(出处: 炼数成金)
好,我找时间看一下
lz你好,请问mahout datamodel支持多个字段输入吗?不仅仅是UserID、ItemId和preference 这3个字段
默认的模型是不支持的,更多的维度,要自己去实现。
谢谢~
博主好,写的很详细,学到很多,有个疑问就是这样在eclipse中运行,虽然可以操作hdfs系统的文件,但貌似不是在hadoop集群里并行的计算的,好像还是在本机的单机运行,请博主帮忙解释一下下,3Q
远程调用是在本机单机计算的,这个方法,只适于用于算法开发,部署需要自己打包放到服务上运行。
[…] Mahout分步式程序开发 基于物品的协同过滤ItemCF […]
[…] 基于Hadoop的分步式算法实现:就是把单机内存算法并行化,把任务分散到多台计算机一起运行。Mahout提供了ItemCF基于Hadoop并行化算法实现。基于Hadoop的分步式算法实现,请参考文章: Mahout分步式程序开发 基于物品的协同过滤ItemCF […]
[…] 开发环境mahout版本为0.8。 请参考文章:用Maven构建Mahout项目 […]