Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-mahout-roadmap/

前言
Mahout是Hadoop家族中与众不同的一个成员,是基于一个Hadoop的机器学习和数据挖掘的分布式计算框架。Mahout是一个跨学科产品,同时也是我认为Hadoop家族中,最有竞争力,最难掌握,最值得学习的一个项目之一。
Mahout为数据分析人员,解决了大数据的门槛;为算法工程师,提供基础的算法库;为Hadoop开发人员,提供了数据建模的标准;为运维人员,打通了和Hadoop连接。
Mahout就是训象人,在Hadoop上创造新的智慧!
目录
- Mahout介绍
- Mahout学习路线图
- 我的学习经历
- Mahout的使用案例
1. Mahout介绍
Mahout 是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
根据”Mahout In Action”书中的介绍,Mahout实现3大类算法, 推荐(Recommendation),聚类(Clustering),分类(Classification)。
下文介绍的学习路线图,将以”Mahout In Action”书中思路展张。
2. Mahout学习路线图
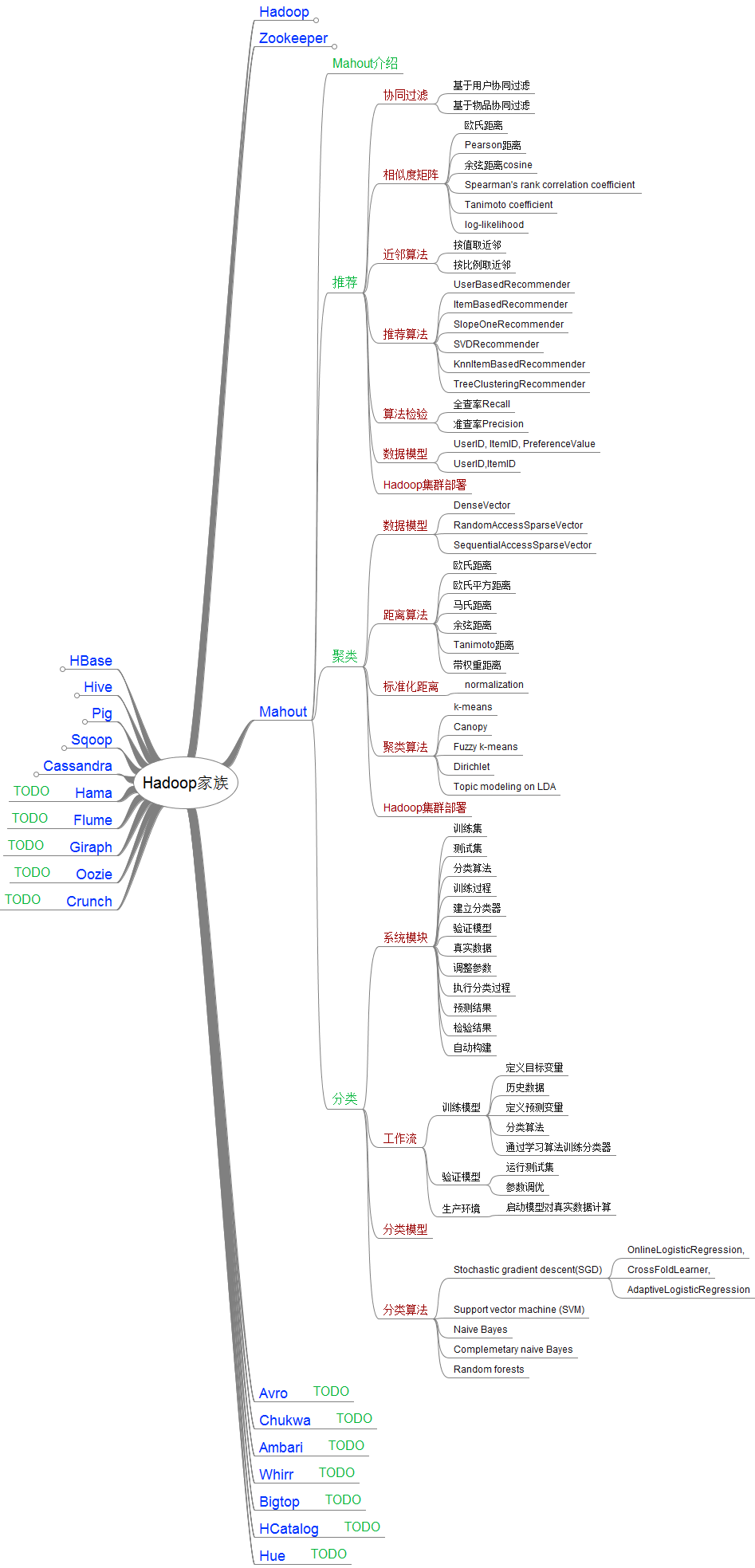
Mahout知识点,我已经列在图中,希望帮助其他人更好的了解Mahout。
接下来,是我的学习经历,谁都没有捷径。把心踏实下来,就不那么难了。
3. 我的学习经历
之前,大概花了半年的时间,专门研究过Mahout,当时Mahout的资料非常少,中文资料更是仅仅几篇。直到发现了“Mahout In Action”如获至宝,开始反复地读。先不着急上手去做什么,一遍一遍地读。直到读完3遍,心理才有了一点把握。
从“推荐”算法开始,UserCF, ItemCF。 记得第一次在公司给小组讲的时候,还设计了一份问卷,我列出了10个网站,(其中6个IT大站,2个个人blog,2个社交类社区),分别让大家去投票,0-5分,0为不知道,1-5为对网站喜爱程序。
问卷结果格式:
user1, website1, 5
user1, website2, 2
user1, website3, 4
user2, website3, 2
user3, website3, 5
user4, website3, 0
…..
通过这个问卷来模拟尝试Mahout的推荐模型!计算的结果对大家来说,都是比较奇怪。为什么会有这样的推荐呢。 然后,深入Mahout源代码,看算法的实现,知道了相似度矩阵,距离算法,推荐算法,模型验证等,不同业务要求,不同的算法调用,对结果都是有影响的。把书中所有的的概念,关键词都整理过(可惜当时没写博客)。整整花了3个月,每天12个小时的强度,把推荐部分完整地学下来了。
然后,应用到实际业务中。我的任务是做“职位推荐”,我只有用户浏览职位,收藏职位,申请职位的行为数据。
第一次尝试,直接套用推荐模型,但结果非常之差。
出现问题的原因是有2点:
- 1. 职位是有时效性的,每个职位可能3个月就会过期:推荐结果包含了很多的过期职位。
- 2. 大量的用户行为都是历史的,甚至是2-3年前的:推荐结果不符合用户的预期。我估计每半年用户的职位都可能有上升,所以历史行为是不能直接用于当前用户的计算。
修改方案:
1. 对用户行为数据集进行过滤,只计算最近半年内的用户行为。
2. 对结果集进行过滤,排除过期的职位。
3. 分别用不同的算法模型计算(我记得Tanimoto的Item Base结果最好)
对于推荐结果有了大幅度的提升。故事到此就结束了!虽然我还做了更多的事情,不过这个产品由于公司结构性调整,最终没有上线。(程序员的悲哀!)
聚类模型,我把这个算法 应用在网站用户的活跃度分析。假设一个网站,注册用户1000W,每天登陆的1W。我们想了解一下,未登陆的999W用户有什么特点!!用到Mahout的k-means和Canopy做聚类,假设1000W的用户可能可以划分为5个大的群体。最后我们得到了一个结果,分享到了团队。故事又到此结束了。(实现就是这么悲哀!)
分类模型,我尝试着用Native Bayes对我的个人邮件进行垃圾分类。按机器学习的操作流程,历史数据健分词后,训练分类器,每天时时的数据通过分类器进行判断。整个自动化过程都已经完成。故事又结束了!(接受现实吧。)
其实还有一些,我争取都整理出来。
Mahout是有一定的学习门槛,而且需要跨学科的知识。只要坚持学习,没有跨不过的鸿沟!乐观努力!
4. Mahout的使用案例
已经整理成文章的案例
- 用R解析Mahout用户推荐协同过滤算法(UserCF)
- RHadoop实践系列之三 R实现MapReduce的协同过滤算法
- 用Maven构建Mahout项目
- Mahout推荐算法API详解
- 从源代码剖析Mahout推荐引擎
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
- Mahout分步式程序开发 聚类Kmeans
- 用Mahout构建职位推荐引擎
正在准备更多的案例…..
相关文章:
Hadoop家族产品学习路线图
转载请注明出处:
http://blog.fens.me/hadoop-mahout-roadmap/

[…] Mahout学习路线图 […]
博主究竟有没有用Mahout完成过一个项目啊……每个项目都是不了了之,好可惜啊
当然有啦,非公司的项目嘛。
机会可以自己创造,产品也可以自己做。
机会可以自己创造,产品也可以自己做。 是啊 支持
您好,看了你的文章感觉受益匪浅,最近在学习mahout,不知道您对iForest算法可否有了解,是否可以通过mahout做并行设计呢?
mahout提供了一套机器学习的框架,但如果mahout本身没有对iForest支持,就不要考虑基于mahout做了,二次开发很难。
请问有没有关于分类算法的案例分析,网上资料和API不系统。
我还没有写分类算法的文章!
请教如何实现 Mahout 的分布式计算?
分步试计算的文章:
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/
http://blog.fens.me/hadoop-mahout-kmeans/
Thanks.
请问是否涉猎 oryx?
oryx是什么?
https://github.com/cloudera/oryx
没有研究过,等有时间了学学!!:-)
请问学Mahout In Action之前要先学习hadoop家族的哪些东西当基础?
先读一遍书,不懂的就是你需要学的基础。
这本书真的好难。看了前几章,没有任何头绪。
需要基础知识,我当初也看了好几遍。加油!
张老师,mahout的聚类结果如果想要把所有结果属于哪个簇的节点保存起来应该怎么用啊,另外节点如果想和标签绑定,能实现吗?
1. 聚类结果,每个点属于哪个中心,这篇文章有讲,http://blog.fens.me/hadoop-mahout-kmeans
2. 标签绑定,这是你自己定义的功能,要自己实现了。
请问这个mindmap可以共享或者发给我嘛? 希望能整体看到一个知识体系的结构, 麻烦你了, wilsoncui.gz@gmail.com
Hadoop的体系结构网上有很多的文章,由于我画图并不完整,难免会对读者产生误导,等我整理后再发布出来。
请问mahout0.7以上版本怎么分类不含标签数据
Mahout算法是基于特定模型,如果不含标签数据,你可以考虑二次开发。
问一下,mahout有userbase的推荐算法实现吗
有,但usercf是单机的
我想实现一个usercf的hadoop版本,还有基于内容推荐的hadoop版本。能给我点意见不?
可以,不过性能会很差的。你可以先看懂原理,用R做个原型,再改用Hadoop自己实现。
http://blog.fens.me/r-mahout-usercf/
mahout有提供神经网络的算法吗?貌似没有找到
没有
好像是有的吧,在网上看到mahout有实现多层感知器的算法。
官方上没有列出神经网络的算法
http://mahout.apache.org/
有的,算法列表上有Multilayer Perceptron
我没有用过Mahout的这个算法 ,用R写神经网络就比较容易了。