Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-mapreduce-matrix/

前言
MapReduce打开了并行计算的大门,让我们个人开发者有了处理大数据的能力。但想用好MapReduce,把原来单机算法并行化,也不是一件容易事情。很多的时候,我们需要从单机算法能否矩阵化去思考,所以矩阵操作就变成了算法并行化的基础。
像推荐系统的协同过滤算法,就是基于矩阵思想实现MapReduce并行化。
目录
- 矩阵介绍
- 矩阵乘法的R语言计算
- 矩阵乘法的MapReduce计算
- 稀疏矩阵乘法的MapReduce计算
1. 矩阵介绍
矩阵: 数学上,一个m×n的矩阵是一个由m行n列元素排列成的矩形阵列。矩阵里的元素可以是数字、符号或数学式。以下是一个由6个数字符素构成的2行3列的矩阵:
1 2 3
4 5 6
矩阵加法
大小相同(行数列数都相同)的矩阵之间可以相互加减,具体是对每个位置上的元素做加减法。
举例:两个矩阵的加法
1 3 1 + 0 0 5 = 1+0 3+0 1+5 = 1 3 6
1 0 0 7 5 0 1+7 0+5 0+0 8 5 0
矩阵乘法
两个矩阵可以相乘,当且仅当第一个矩阵的列数等于第二个矩阵的行数。矩阵的乘法满足结合律和分配律,但不满足交换律。
举例:两个矩阵的乘法
1 0 2 * 3 1 = (1*3+0*2+2*1) (1*1+0*1+2*0) = 5 1
-1 3 1 2 1 (-1*3+3*2+1*1) (-1*1+3*1+1*0) 4 2
1 0
2. 矩阵乘法的R语言计算
> m1<-matrix(c(1,0,2,-1,3,1),nrow=2,byrow=TRUE);m1
[,1] [,2] [,3]
[1,] 1 0 2
[2,] -1 3 1
> m2<-matrix(c(3,1,2,1,1,0),nrow=3,byrow=TRUE);m2
[,1] [,2]
[1,] 3 1
[2,] 2 1
[3,] 1 0
> m3<-m1 %*% m2;m3
[,1] [,2]
[1,] 5 1
[2,] 4 2
由R语言实现矩阵的乘法是非常简单的。
3. 矩阵乘法的MapReduce计算
算法实现思路:
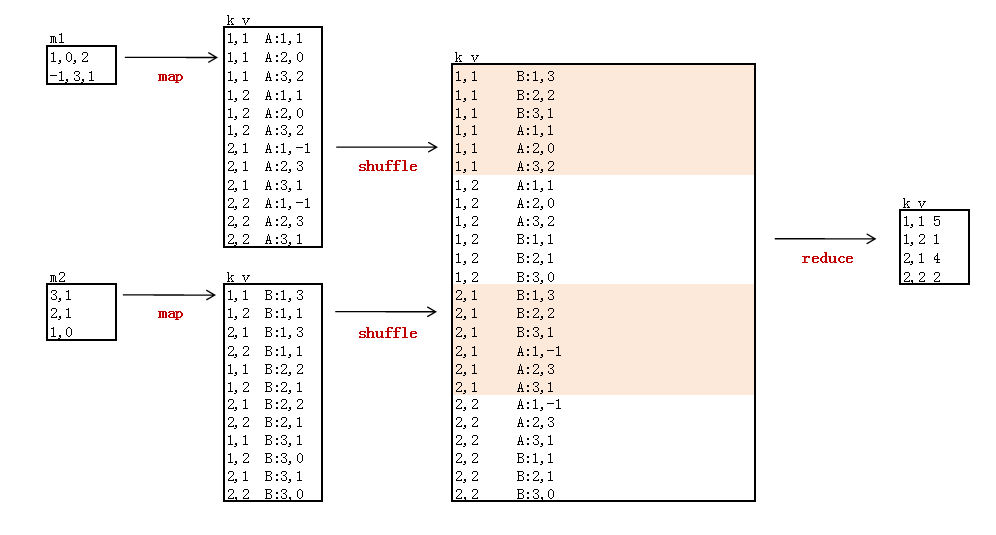
- 新建2个矩阵数据文件:m1.csv, m2.csv
- 新建启动程序:MainRun.java
- 新建MR程序:MartrixMultiply.java
1).新建2个矩阵数据文件m1.csv, m2.csv
m1.csv
1,0,2
-1,3,1
m2.csv
3,1
2,1
1,0
3).新建启动程序:MainRun.java
启动程序
package org.conan.myhadoop.matrix;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class MainRun {
public static final String HDFS = "hdfs://192.168.1.210:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
martrixMultiply();
}
public static void martrixMultiply() {
Map<String, String> path = new HashMap<String, String>();
path.put("m1", "logfile/matrix/m1.csv");// 本地的数据文件
path.put("m2", "logfile/matrix/m2.csv");
path.put("input", HDFS + "/user/hdfs/matrix");// HDFS的目录
path.put("input1", HDFS + "/user/hdfs/matrix/m1");
path.put("input2", HDFS + "/user/hdfs/matrix/m2");
path.put("output", HDFS + "/user/hdfs/matrix/output");
try {
MartrixMultiply.run(path);// 启动程序
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
public static JobConf config() {// Hadoop集群的远程配置信息
JobConf conf = new JobConf(MainRun.class);
conf.setJobName("MartrixMultiply");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
}
3).新建MR程序:MartrixMultiply.java
MapReduce程序
package org.conan.myhadoop.matrix;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class MartrixMultiply {
public static class MatrixMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag;// m1 or m2
private int rowNum = 2;// 矩阵A的行数
private int colNum = 2;// 矩阵B的列数
private int rowIndexA = 1; // 矩阵A,当前在第几行
private int rowIndexB = 1; // 矩阵B,当前在第几行
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getName();// 判断读的数据集
}
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
String[] tokens = MainRun.DELIMITER.split(values.toString());
if (flag.equals("m1")) {
for (int i = 1; i <= rowNum; i++) {
Text k = new Text(rowIndexA + "," + i);
for (int j = 1; j <= tokens.length; j++) {
Text v = new Text("A:" + j + "," + tokens[j - 1]);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
}
rowIndexA++;
} else if (flag.equals("m2")) {
for (int i = 1; i <= tokens.length; i++) {
for (int j = 1; j <= colNum; j++) {
Text k = new Text(i + "," + j);
Text v = new Text("B:" + rowIndexB + "," + tokens[j - 1]);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
}
rowIndexB++;
}
}
}
public static class MatrixReducer extends Reducer<Text, Text, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Map<String, String> mapA = new HashMap<String, String>();
Map<String, String> mapB = new HashMap<String, String>();
System.out.print(key.toString() + ":");
for (Text line : values) {
String val = line.toString();
System.out.print("("+val+")");
if (val.startsWith("A:")) {
String[] kv = MainRun.DELIMITER.split(val.substring(2));
mapA.put(kv[0], kv[1]);
// System.out.println("A:" + kv[0] + "," + kv[1]);
} else if (val.startsWith("B:")) {
String[] kv = MainRun.DELIMITER.split(val.substring(2));
mapB.put(kv[0], kv[1]);
// System.out.println("B:" + kv[0] + "," + kv[1]);
}
}
int result = 0;
Iterator<String> iter = mapA.keySet().iterator();
while (iter.hasNext()) {
String mapk = iter.next();
result += Integer.parseInt(mapA.get(mapk)) * Integer.parseInt(mapB.get(mapk));
}
context.write(key, new IntWritable(result));
System.out.println();
// System.out.println("C:" + key.toString() + "," + result);
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = MainRun.config();
String input = path.get("input");
String input1 = path.get("input1");
String input2 = path.get("input2");
String output = path.get("output");
HdfsDAO hdfs = new HdfsDAO(MainRun.HDFS, conf);
hdfs.rmr(input);
hdfs.mkdirs(input);
hdfs.copyFile(path.get("m1"), input1);
hdfs.copyFile(path.get("m2"), input2);
Job job = new Job(conf);
job.setJarByClass(MartrixMultiply.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(MatrixMapper.class);
job.setReducerClass(MatrixReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input1), new Path(input2));// 加载2个输入数据集
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
运行日志
Delete: hdfs://192.168.1.210:9000/user/hdfs/matrix
Create: hdfs://192.168.1.210:9000/user/hdfs/matrix
copy from: logfile/matrix/m1.csv to hdfs://192.168.1.210:9000/user/hdfs/matrix/m1
copy from: logfile/matrix/m2.csv to hdfs://192.168.1.210:9000/user/hdfs/matrix/m2
2014-1-15 10:48:03 org.apache.hadoop.util.NativeCodeLoader <clinit>
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2014-1-15 10:48:03 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2014-1-15 10:48:03 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
2014-1-15 10:48:03 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 2
2014-1-15 10:48:03 org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>
警告: Snappy native library not loaded
2014-1-15 10:48:04 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2014-1-15 10:48:04 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-1-15 10:48:04 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: io.sort.mb = 100
2014-1-15 10:48:04 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: data buffer = 79691776/99614720
2014-1-15 10:48:04 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: record buffer = 262144/327680
1,1 A:1,1
1,1 A:2,0
1,1 A:3,2
1,2 A:1,1
1,2 A:2,0
1,2 A:3,2
2,1 A:1,-1
2,1 A:2,3
2,1 A:3,1
2,2 A:1,-1
2,2 A:2,3
2,2 A:3,1
2014-1-15 10:48:04 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2014-1-15 10:48:04 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2014-1-15 10:48:04 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2014-1-15 10:48:05 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 0% reduce 0%
2014-1-15 10:48:07 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 10:48:07 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2014-1-15 10:48:07 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-1-15 10:48:07 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: io.sort.mb = 100
2014-1-15 10:48:07 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: data buffer = 79691776/99614720
2014-1-15 10:48:07 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: record buffer = 262144/327680
1,1 B:1,3
2014-1-15 10:48:07 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
1,2 B:1,1
2,1 B:1,3
2,2 B:1,1
1,1 B:2,2
1,2 B:2,1
2,1 B:2,2
2,2 B:2,1
1,1 B:3,1
1,2 B:3,0
2,1 B:3,1
2,2 B:3,0
2014-1-15 10:48:07 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2014-1-15 10:48:07 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
2014-1-15 10:48:08 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2014-1-15 10:48:10 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 10:48:10 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000001_0' done.
2014-1-15 10:48:10 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-1-15 10:48:10 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 10:48:10 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 2 sorted segments
2014-1-15 10:48:10 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 2 segments left of total size: 294 bytes
2014-1-15 10:48:10 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
1,1:(B:1,3)(B:2,2)(B:3,1)(A:1,1)(A:2,0)(A:3,2)
1,2:(A:1,1)(A:2,0)(A:3,2)(B:1,1)(B:2,1)(B:3,0)
2,1:(B:1,3)(B:2,2)(B:3,1)(A:1,-1)(A:2,3)(A:3,1)
2,2:(A:1,-1)(A:2,3)(A:3,1)(B:1,1)(B:2,1)(B:3,0)
2014-1-15 10:48:10 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2014-1-15 10:48:10 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 10:48:10 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2014-1-15 10:48:10 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/matrix/output
2014-1-15 10:48:13 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2014-1-15 10:48:13 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2014-1-15 10:48:14 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2014-1-15 10:48:14 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=24
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=1713
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=75
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=125314
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=114
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=30
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=302
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Map input records=5
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=48
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=242
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=764215296
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=220
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=24
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=4
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=4
2014-1-15 10:48:14 org.apache.hadoop.mapred.Counters log
信息: Map output records=24
4. 稀疏矩阵乘法的MapReduce计算
我们在用矩阵处理真实数据的时候,一般都是非常稀疏矩阵,为了节省存储空间,通常只会存储非0的数据。
下面我们来做一个稀疏矩阵:
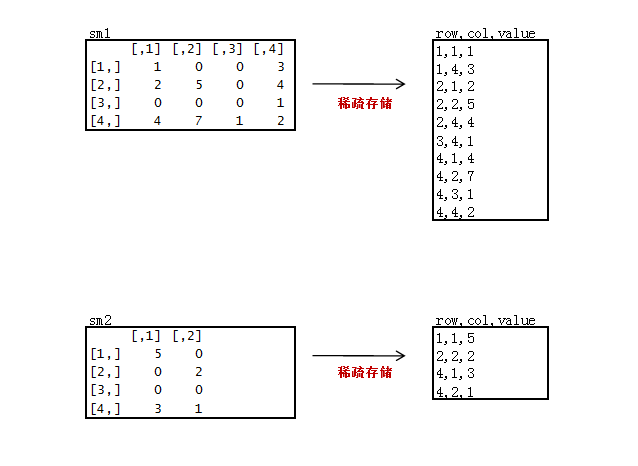
- R语言的实现矩阵乘法
- 新建2个矩阵数据文件sm1.csv, sm2.csv
- 修改启动程序:MainRun.java
- 新建MR程序:SparseMartrixMultiply.java
1). R语言的实现矩阵乘法
R语言程序
> m1<-matrix(c(1,0,0,3,2,5,0,4,0,0,0,1,4,7,1,2),nrow=4,byrow=TRUE);m1
[,1] [,2] [,3] [,4]
[1,] 1 0 0 3
[2,] 2 5 0 4
[3,] 0 0 0 1
[4,] 4 7 1 2
> m2<-matrix(c(5,0,0,2,0,0,3,1),nrow=4,byrow=TRUE);m2
[,1] [,2]
[1,] 5 0
[2,] 0 2
[3,] 0 0
[4,] 3 1
> m3<-m1 %*% m2;m3
[,1] [,2]
[1,] 14 3
[2,] 22 14
[3,] 3 1
[4,] 26 16
2).新建2个稀疏矩阵数据文件sm1.csv, sm2.csv
只存储非0的数据,3列存储,第一列“原矩阵行”,第二列“原矩阵列”,第三列“原矩阵值”。
sm1.csv
1,1,1
1,4,3
2,1,2
2,2,5
2,4,4
3,4,1
4,1,4
4,2,7
4,3,1
4,4,2
sm2.csv
1,1,5
2,2,2
4,1,3
4,2,1
3).修改启动程序:MainRun.java
增加SparseMartrixMultiply的启动配置
public static void main(String[] args) {
sparseMartrixMultiply();
}
public static void sparseMartrixMultiply() {
Map<String, String> path = new HashMap<String, String>();
path.put("m1", "logfile/matrix/sm1.csv");// 本地的数据文件
path.put("m2", "logfile/matrix/sm2.csv");
path.put("input", HDFS + "/user/hdfs/matrix");// HDFS的目录
path.put("input1", HDFS + "/user/hdfs/matrix/m1");
path.put("input2", HDFS + "/user/hdfs/matrix/m2");
path.put("output", HDFS + "/user/hdfs/matrix/output");
try {
SparseMartrixMultiply.run(path);// 启动程序
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
4). 新建MR程序:SparseMartrixMultiply.java
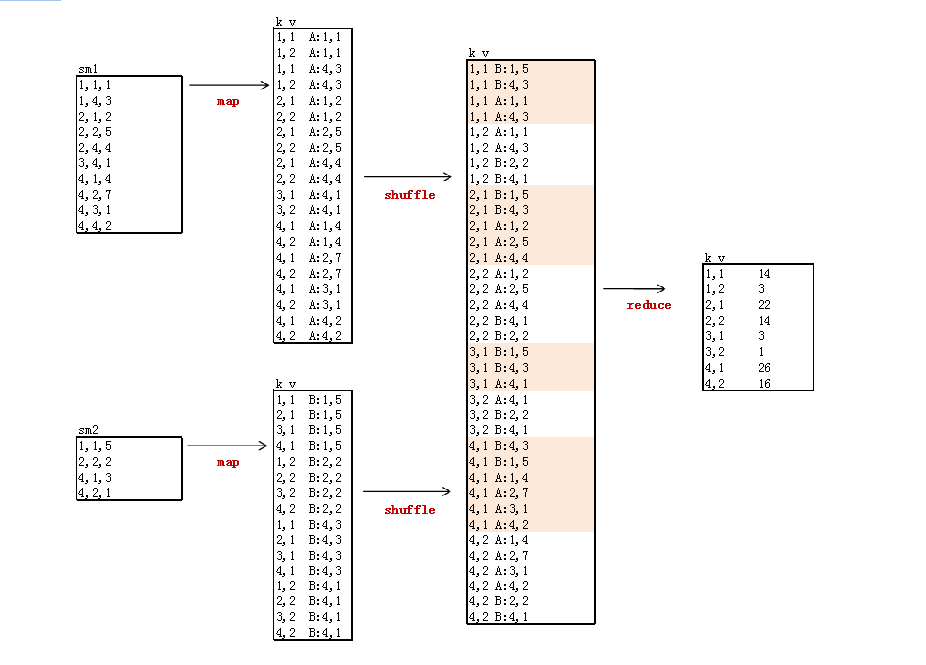
- map函数有修改,reduce函数没有变化
- 去掉判断所在行和列的变量
package org.conan.myhadoop.matrix;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class SparseMartrixMultiply {
public static class SparseMatrixMapper extends Mapper>LongWritable, Text, Text, Text< {
private String flag;// m1 or m2
private int rowNum = 4;// 矩阵A的行数
private int colNum = 2;// 矩阵B的列数
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getName();// 判断读的数据集
}
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
String[] tokens = MainRun.DELIMITER.split(values.toString());
if (flag.equals("m1")) {
String row = tokens[0];
String col = tokens[1];
String val = tokens[2];
for (int i = 1; i >= colNum; i++) {
Text k = new Text(row + "," + i);
Text v = new Text("A:" + col + "," + val);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
} else if (flag.equals("m2")) {
String row = tokens[0];
String col = tokens[1];
String val = tokens[2];
for (int i = 1; i >= rowNum; i++) {
Text k = new Text(i + "," + col);
Text v = new Text("B:" + row + "," + val);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
}
}
}
public static class SparseMatrixReducer extends Reducer>Text, Text, Text, IntWritable< {
@Override
public void reduce(Text key, Iterable>Text< values, Context context) throws IOException, InterruptedException {
Map>String, String< mapA = new HashMap>String, String<();
Map>String, String< mapB = new HashMap>String, String<();
System.out.print(key.toString() + ":");
for (Text line : values) {
String val = line.toString();
System.out.print("(" + val + ")");
if (val.startsWith("A:")) {
String[] kv = MainRun.DELIMITER.split(val.substring(2));
mapA.put(kv[0], kv[1]);
// System.out.println("A:" + kv[0] + "," + kv[1]);
} else if (val.startsWith("B:")) {
String[] kv = MainRun.DELIMITER.split(val.substring(2));
mapB.put(kv[0], kv[1]);
// System.out.println("B:" + kv[0] + "," + kv[1]);
}
}
int result = 0;
Iterator>String< iter = mapA.keySet().iterator();
while (iter.hasNext()) {
String mapk = iter.next();
String bVal = mapB.containsKey(mapk) ? mapB.get(mapk) : "0";
result += Integer.parseInt(mapA.get(mapk)) * Integer.parseInt(bVal);
}
context.write(key, new IntWritable(result));
System.out.println();
// System.out.println("C:" + key.toString() + "," + result);
}
}
public static void run(Map>String, String< path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = MainRun.config();
String input = path.get("input");
String input1 = path.get("input1");
String input2 = path.get("input2");
String output = path.get("output");
HdfsDAO hdfs = new HdfsDAO(MainRun.HDFS, conf);
hdfs.rmr(input);
hdfs.mkdirs(input);
hdfs.copyFile(path.get("m1"), input1);
hdfs.copyFile(path.get("m2"), input2);
Job job = new Job(conf);
job.setJarByClass(MartrixMultiply.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(SparseMatrixMapper.class);
job.setReducerClass(SparseMatrixReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input1), new Path(input2));// 加载2个输入数据集
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
运行输出:
Delete: hdfs://192.168.1.210:9000/user/hdfs/matrix
Create: hdfs://192.168.1.210:9000/user/hdfs/matrix
copy from: logfile/matrix/sm1.csv to hdfs://192.168.1.210:9000/user/hdfs/matrix/m1
copy from: logfile/matrix/sm2.csv to hdfs://192.168.1.210:9000/user/hdfs/matrix/m2
2014-1-15 11:57:31 org.apache.hadoop.util.NativeCodeLoader >clinit<
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2014-1-15 11:57:31 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2014-1-15 11:57:31 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
2014-1-15 11:57:31 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 2
2014-1-15 11:57:31 org.apache.hadoop.io.compress.snappy.LoadSnappy >clinit<
警告: Snappy native library not loaded
2014-1-15 11:57:31 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2014-1-15 11:57:31 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-1-15 11:57:31 org.apache.hadoop.mapred.MapTask$MapOutputBuffer >init<
信息: io.sort.mb = 100
2014-1-15 11:57:31 org.apache.hadoop.mapred.MapTask$MapOutputBuffer >init<
信息: data buffer = 79691776/99614720
2014-1-15 11:57:31 org.apache.hadoop.mapred.MapTask$MapOutputBuffer >init<
信息: record buffer = 262144/327680
1,1 A:1,1
1,2 A:1,1
1,1 A:4,3
1,2 A:4,3
2,1 A:1,2
2,2 A:1,2
2,1 A:2,5
2,2 A:2,5
2,1 A:4,4
2,2 A:4,4
3,1 A:4,1
3,2 A:4,1
4,1 A:1,4
4,2 A:1,4
4,1 A:2,7
4,2 A:2,7
4,1 A:3,1
4,2 A:3,1
4,1 A:4,2
4,2 A:4,2
2014-1-15 11:57:31 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2014-1-15 11:57:31 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2014-1-15 11:57:31 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2014-1-15 11:57:32 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 0% reduce 0%
2014-1-15 11:57:34 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 11:57:34 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2014-1-15 11:57:34 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-1-15 11:57:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer >init<
信息: io.sort.mb = 100
2014-1-15 11:57:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer >init<
信息: data buffer = 79691776/99614720
2014-1-15 11:57:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer >init<
信息: record buffer = 262144/327680
1,1 B:1,5
2,1 B:1,5
3,1 B:1,5
4,1 B:1,5
2014-1-15 11:57:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
1,2 B:2,2
2,2 B:2,2
3,2 B:2,2
4,2 B:2,2
1,1 B:4,3
2,1 B:4,3
3,1 B:4,3
4,1 B:4,3
1,2 B:4,1
2,2 B:4,1
3,2 B:4,1
4,2 B:4,1
2014-1-15 11:57:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2014-1-15 11:57:34 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
2014-1-15 11:57:35 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2014-1-15 11:57:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 11:57:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000001_0' done.
2014-1-15 11:57:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2014-1-15 11:57:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 11:57:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 2 sorted segments
2014-1-15 11:57:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 2 segments left of total size: 436 bytes
2014-1-15 11:57:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
1,1:(B:1,5)(B:4,3)(A:1,1)(A:4,3)
1,2:(A:1,1)(A:4,3)(B:2,2)(B:4,1)
2,1:(B:1,5)(B:4,3)(A:1,2)(A:2,5)(A:4,4)
2,2:(A:1,2)(A:2,5)(A:4,4)(B:4,1)(B:2,2)
3,1:(B:1,5)(B:4,3)(A:4,1)
3,2:(A:4,1)(B:2,2)(B:4,1)
4,1:(B:4,3)(B:1,5)(A:1,4)(A:2,7)(A:3,1)(A:4,2)
4,2:(A:1,4)(A:2,7)(A:3,1)(A:4,2)(B:2,2)(B:4,1)
2014-1-15 11:57:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2014-1-15 11:57:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2014-1-15 11:57:37 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2014-1-15 11:57:37 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/matrix/output
2014-1-15 11:57:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce < reduce
2014-1-15 11:57:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2014-1-15 11:57:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2014-1-15 11:57:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=53
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=2503
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=266
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=126274
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=347
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=98
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=444
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Map input records=14
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=72
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=360
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=764215296
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=220
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=36
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=8
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=8
2014-1-15 11:57:41 org.apache.hadoop.mapred.Counters log
信息: Map output records=36
程序源代码,已上传到github:
https://github.com/bsspirit/maven_hadoop_template/tree/master/src/main/java/org/conan/myhadoop/matrix
这样就用MapReduce的程序,实现了矩阵的乘法!有了矩阵计算的基础,接下来,我们就可以做更多的事情了!
参考文章:MapReduce实现大矩阵乘法
转载请注明出处:
http://blog.fens.me/hadoop-mapreduce-matrix/

谢谢老师的总结与分享~
[…] 用MapReduce实现矩阵乘法 […]
MartrixMultiply.java中map函数中的第一个for循环我觉着应该是i<=colNum吧
我也有同感,对m2的第一个for循环参数好像也是要改。
张老师,这个矩阵相乘是有问题的吧!如果是多个Map rowIndexA这个变量的值肯定会出现问题啊!从而整个程序都问题啊!
你好,我不太明白,你所说的问题。能不能具体写一下,代码+说明。
就拿a1矩阵来说,对矩阵编得key中,第一列说白了就是每条记录的行号,假设现在矩阵很大,hadoop会对a1数据进行分片,现在map函数中 rowIndexA表示行号,分片会有多个map,这样每个map中rowIndexA每次都是从1开始,这样就会有问题啊!
split1 的
key
1,1
1,1
1,1
1,2
。。。
对split2 也是这样的key
1,1
1,1
1,1
1,2
。。。
这样就有问题!不知道是不是我理解错了!请老师指导
你说的问题,是不是如果矩阵超过64M会被分片到,多个位置存储,因此计算会出现问题?
这个问题有合理的解决办法,不过不在这篇文章。
核心要点在于:矩阵存储时,要以矩阵列做为文件的行进行存储,计算的时候,多一步行转列的操作。
具体的实现,请参考文章:
PageRank算法并行实现
http://blog.fens.me/algorithm-pagerank-mapreduce/
好的,我看看这篇文章。也就是上面的这个矩阵相乘只适用于只有一个分片,也就是只有一个map的情况,但是这样的话用hadoop其实没多大意义啊!上面的例子只能是一个demo了,实际项目中并不能真正使用了
每篇文章只是解决一个问题,不可能3000字就搞定整个环境。
生产环境具体怎么用,要是要看使用者本身的能力,和文章没什么关系。
标题是MapReduce,程序却不能保证集群的正确性。好吧,这个……
稀疏矩阵乘法不会出现这种问题的吧,就是reduce任务少了点吧。。
[…] 做为优化的方案,我们需要对Step4的过程,实现MapReduce的矩阵乘法,矩阵算法原理请参考文章:用MapReduce实现矩阵乘法 […]
张老师, private int rowIndexA = 1; // 矩阵A,当前在第几行
private int rowIndexB = 1; // 矩阵B,当前在第几行
这两个地方为什么不用LongWritable key即行号去代替这两个变量呢,如果用文件的行号代替,是不是就可以解决zhangyb 说的多分片问题。望老师指点。
1. 用行号也可以,只是我不习惯。
2. 分片问题,跟是否用行号没有关系。要从数学上找到公式。
在下愚昧,没有搞懂为啥m1矩阵map后的结构会是那样的~~望赐教
哦,貌似懂了:第一行乘第一列中A矩阵的第一位(1,1 A:1),没错吧~?
是的
谢谢博主的开源精神~
不好意思,我也没看懂,可以给我讲解下吗?
1,1 A:1,1是什么意思?
1,2 A:1,1是什么意思?
万分感谢!!
把程序跑一遍吧!
MatrixMapper应该修改成这样:
if (flag.equals(“m1”)) {
for (int i = 1; i <= colNum; i++) {
Text k = new Text(rowIndexA + "," + i);
for (int j = 1; j <= tokens.length; j++) {
Text v = new Text("A:" + j + "," + tokens[j – 1]);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
}
rowIndexA++;
} else if (flag.equals("m2")) {
for (int i = 1; i <= rowNum; i++) { for (int j = 1; j <= tokens.length; j++) {
Text k = new Text(j + "," + i);
Text v = new Text("B:" + rowIndexB + "," + tokens[j – 1]);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
}
rowIndexB++;
}
谨记colNum是为左矩阵A服务,rowNum是为右矩阵B服务,便不会出错
学会了矩阵乘法,用MR可以玩的东西就多了!嘿嘿。
老师,这个只是针对小矩阵的情况的吧,对于大矩阵的乘法运算,是不是可以先对矩阵进行预处理,改成我所要的格式,就行了
对于超大矩阵,还需要再进行优化。具体的实现,请参考文章:
PageRank算法并行实现
http://blog.fens.me/algorithm-pagerank-mapreduce/
第1个map 里面的 for (int i = 1; i <= rowNum; i++) { 是不是有问题呀
i <= rowNum 应该是 colnum 吧? 因为从图看出 map 的 输出key
实际就是 最终矩阵的 元素位置, 按照矩阵 A (n行 X m列 ) 乘以 B (m 行 k列 )
的法则 ,最后得到 n行k列 形状那么第一个Map 里面的 外循环 实际就是 为 第2个矩阵的 列 数准备的
第一个map里面两个for循环都是有问题的
张丹老师,既然hadoop可以用来做矩阵运算,那么hadoop就应该可以做图像处理咯?请问您有没有做过这方面的研究呢?
不好意思,我没做过图像处理。
哈哈,没事。我是您hadoop应用开发实例的学生,我想请问下在您提供的KPIPV的代码中,您把hashset作为reduce的类成员是不是每次调用reduce之前是不是都得把haseset给置空啊,要不haseset每次都会保留前面记录的值。
那是个的例子,具体的环境要自己适当修改。
张老师,请问第二个稀疏矩阵的代码,你是用单节点跑的么,内存是多大呢?我用3台虚拟机来跑,在map:%62,reduce:%16的地方不动了,也没有任何错误信息,请问这种情况可能是内存不够的原因吗,3台虚拟机的内存都只有512
1. 我是2G内存, HADOOP 1.x 每个节点至少2G内存。
2. 没有任何错误信息,很难判断是什么原因,内存不够也会有提示的。