跨界知识聚会系列文章,“知识是用来分享和传承的”,各种会议、论坛、沙龙都是分享知识的绝佳场所。我也有幸作为演讲嘉宾参加了一些国内的大型会议,向大家展示我所做的一些成果。从听众到演讲感觉是不一样的,把知识分享出来,你才能收获更多。
关于作者
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/meeting-ms-ignite-20210318

前言
由于疫情在全球肆虐,原来线下的各种会议都改成了线上的模式,微软一年一度的Ignite大会如期举行。本次大会增加了一个嘉宾脱口秀的环节,由众多的微软MVP组成的嘉宾团,给大家说说微软黑科技。
目录
- 圆桌主题:Azure上的AI+机器学习
- 会议体验和照片分享
1. 圆桌主题:Azure上的AI+机器学习
我参与的圆桌部分,主题是怎么看微软在人工智能和大数据领域的技术革新。我从最擅长的数据分析进行介绍,针对于Azure上的Data和AI的主题,谈谈微软产品如何带动整个行业的发展。
我从2个方面来介绍微软数据产品线设计。

我主要为分2个部分进行介绍:
- Azure上的 AutoML 自动机器学习平台
- Azure认知服务体系
数据分析,作为大数据和人工智能的一个分支,正在各领域中发挥着作用。Azure上是最早推出AutoML的SaaS服务平台之一,现在已经做的非常完善和成熟了。在AutoML的过程中,不仅集成了众多优秀的产品,同时提供了强大的计算能力,和认知服务能力。让小团队可以直接跨过底层的复杂技术架构的搭建过程,从而直接面向应用层去做开发。
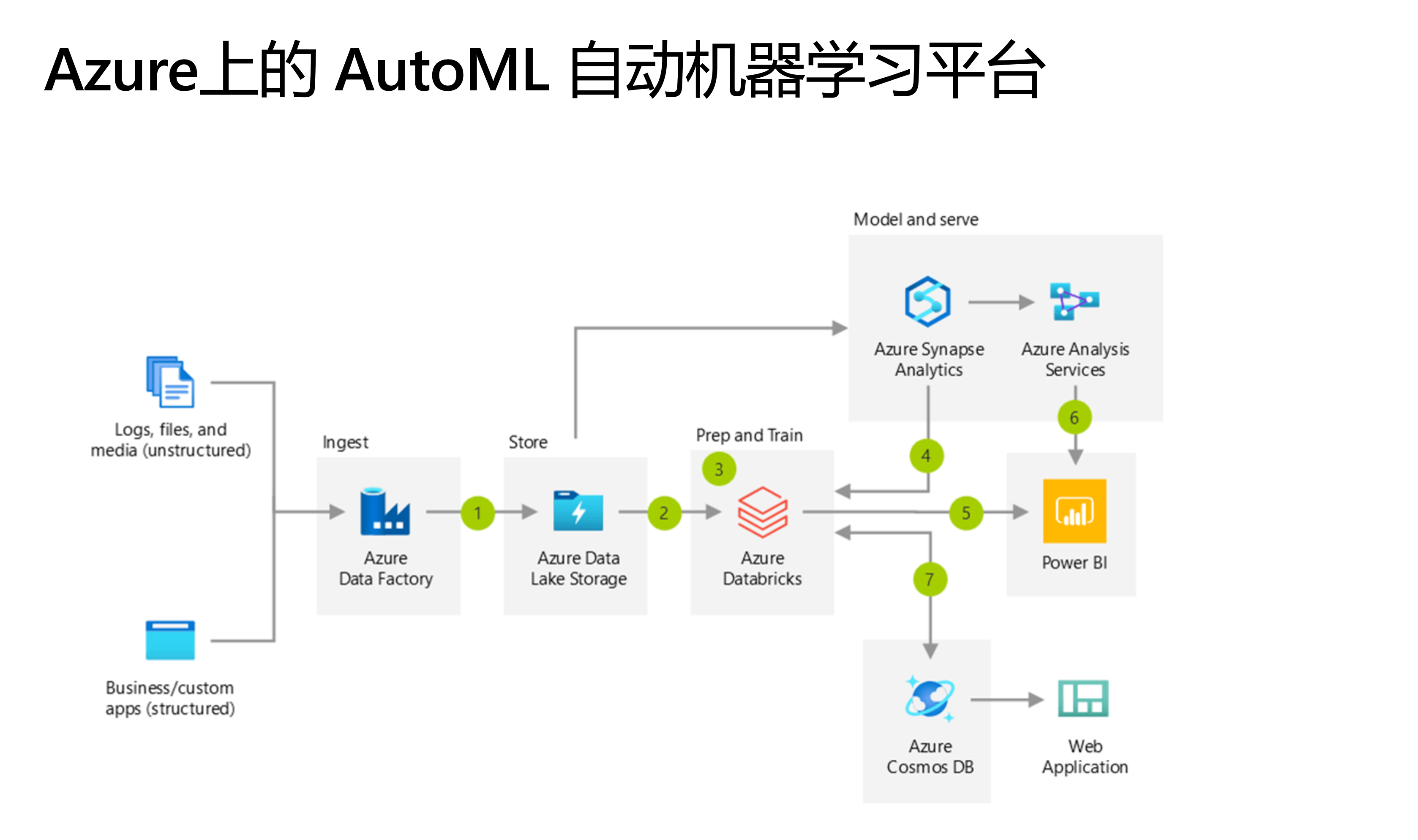
Azure上的产品组件:
- Azure Data Factory,数据工厂被描述为一项数据集成服务。 Azure 数据工厂的用途是从一个或多个数据源中检索数据,并将其转换为你可处理的格式。 数据源可能以不同的方式呈现数据,并且包含需要筛选掉的干扰词。Azure 数据工厂使你可以提取感兴趣的数据,并放弃其余数据。
- Azure Data Lake Storage, 数据湖是用于存储大量原始数据的存储库。 由于数据原始且未经处理,因此其加载和更新速度非常快,但数据并未采用适合高效分析的结构。
- Azure Databrick, 是在 Azure 上运行的 Apache Spark 环境,可提供大数据处理、流式传输和机器学习功能。 Apache Spark 是一个高效的数据处理引擎,可以非常快速地使用和处理大量数据。
- Azure Synapse Analytics, 是一个分析引擎,基于数据仓库的分析服务
- Cosmos DB,是完全托管的NoSQL数据库服务。
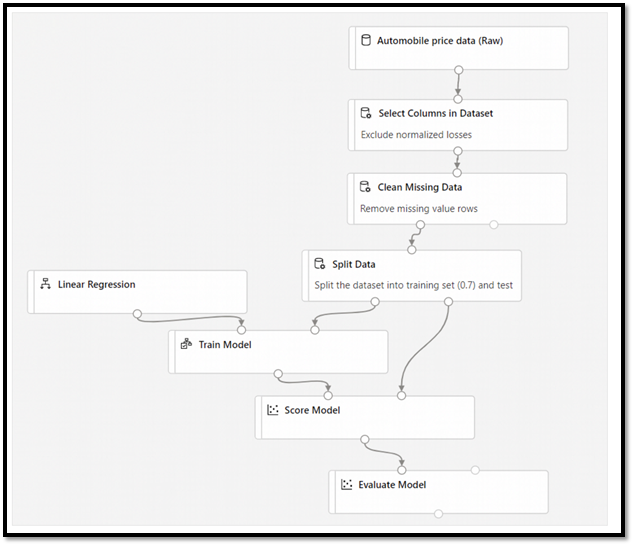
在Azure上,我们不担心产品试用过程中的复杂度,因为通过“服务编排”的方式,建立Pipeline流程,用拖拽就可以完成复杂的产品对接的,和数据流控制,数据处理过程。Azure把流程进行了标准化的定义,产品可以自由组装,数据流关系可以进行服务编排,通过服务接口进行调用,形成了 AutoML 完成的数据产品闭环。
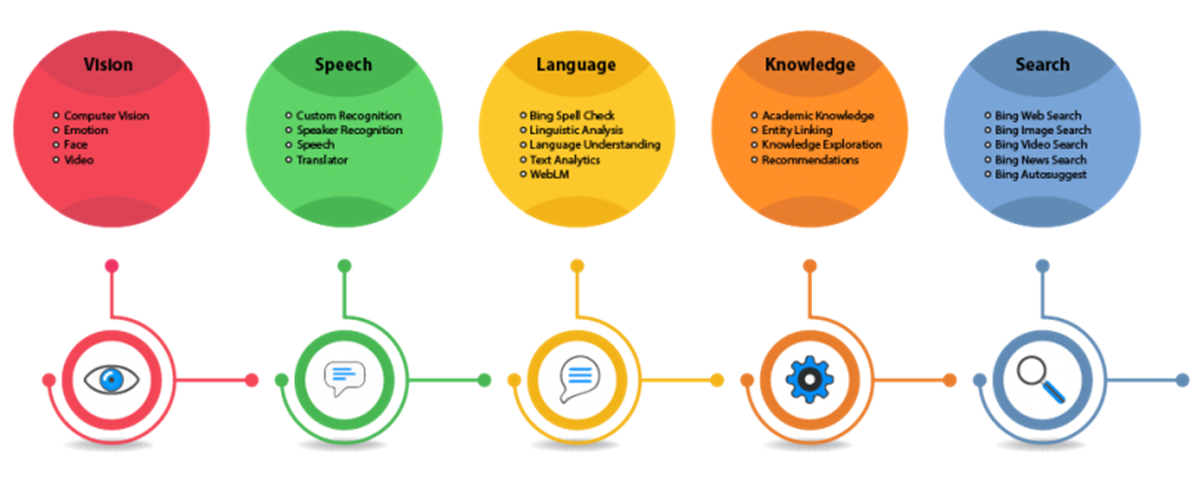
认知服务几乎覆盖了完整的深度学习的应用领域,同样我们可以通过服务接口的方式,调用这个认知服务,而不只自己在重新搭建底层平台。
- 影像:人脸,图像提取文本,图像分类准确识别画作,视频索引
- 语音: 文字转语音,语音转文字,语音翻译
- 语言:文字翻译,语言理解(LUIS),情绪分析
- 知识:异常检测器,个性化推荐,内容审查
- 搜索:bing
你可以直接使用由微软提供的,已训练好的通用模型,也可以根据自己的数据训练出符合自己业务场景的个性化模型。总之,既可以通用又可以专业,使用起来非常方便,可以大大解放人的工作,从而实现AI驱动。
2. 会议体验和照片分享
Micosoft Ignite 全球直播又来啦,本次大会的官方页面:https://ignitechina.microsoft.com/index.html, 微信公众号地址:https://mp.weixin.qq.com/s/utnigc2fIeCkZbfkPijHLQ
2.1 会议主题
MVP嘉宾代表团:分了五组进行对微软生态进行介绍。

2.2 相关照片
圆桌对话:我在北京主会场和主持人:杨娜,另外三个嘉宾在上海会场:王公子,彭爱华老师,胡浩。
在各种设备中看直播。
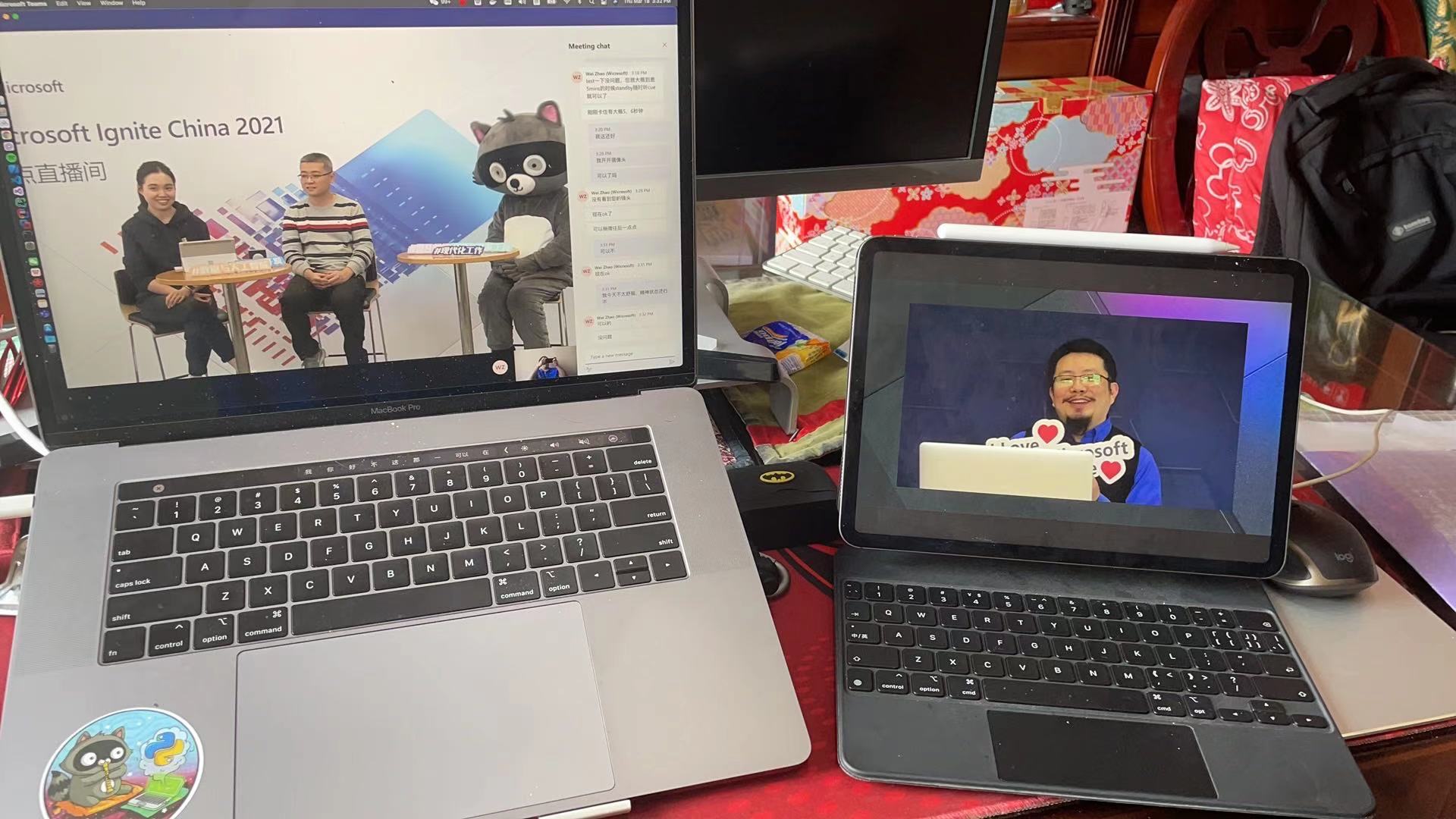
刘亮和杨威,低代码开发。

朱一婷,在做 Micriosoft Mesh 技术分享,混合现实领域。

负责专业录制节目的工作人员。

最后,整个分享结束,现场工人人员和各位嘉宾都辛苦啦。
微软在越来越放开,融合各种技术,并且自己也在支持多种技术的融合和创新。
转载请注明出处:
http://blog.fens.me/meeting-ms-ignite-20210318
