从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可以帮助我们迅速建立web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站,个性化网站,我们自己的Geek网站!!
关于作者
- 张丹(Conan), 创业者,程序员(Java,R,Javascript/Nodejs)
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/nodejs-buffer/

前言
Javascript是为浏览器而设计的,能很好的处理unicode编码的字符串,但对于二进制或非unicode编码的数据就显得无能为力。Node.js继承Javascript的语言特性,同时又扩展了Javascript语言,为二进制的数据处理提供了Buffer类,让Node.js可以像其他程序语言一样,能处理各种类型的数据了。
网上有很多讲Buffer的文章,大都讲的是原理,怎么使用几乎找不到,文章将重点介绍Buffer的使用。
目录
- Buffer介绍
- Buffer的基本使用
- Buffer的性能测试
1. Buffer介绍
在Node.js中,Buffer类是随Node内核一起发布的核心库。Buffer库为Node.js带来了一种存储原始数据的方法,可以让Nodejs处理二进制数据,每当需要在Nodejs中处理I/O操作中移动的数据时,就有可能使用Buffer库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
Buffer 和 Javascript 字符串对象之间的转换需要显式地调用编码方法来完成。以下是几种不同的字符串编码:
- ‘ascii’ – 仅用于 7 位 ASCII 字符。这种编码方法非常快,并且会丢弃高位数据。
- ‘utf8’ – 多字节编码的 Unicode 字符。许多网页和其他文件格式使用 UTF-8。
- ‘ucs2’ – 两个字节,以小尾字节序(little-endian)编码的 Unicode 字符。它只能对 BMP(基本多文种平面,U+0000 – U+FFFF) 范围内的字符编码。
- ‘base64’ – Base64 字符串编码。
- ‘binary’ – 一种将原始二进制数据转换成字符串的编码方式,仅使用每个字符的前 8 位。这种编码方法已经过时,应当尽可能地使用 Buffer 对象。Node 的后续版本将会删除这种编码。
Buffer官方文档:http://nodejs.org/api/buffer.html
2. Buffer的基本使用
Buffer的基本使用,主要就是API所提供的操作,主要包括3个部分 创建Buffer类、读Buffer、写Buffer。由于基本操作在官方文档中详细的使用介绍,我只是简单列举一下。
系统环境
- Win7 64bit
- Nodejs:v0.10.31
- Npm:1.4.23
创建项目
~ cd D:\workspace\javascript>
~ D:\workspace\javascript>mkdir nodejs-buffer && cd nodejs-buffer
2.1 创建Buffer类
要创建一个Buffer的实例,我们要通过new Buffer来创建。新建文件buffer_new.js。
~ vi buffer_new.js
// 长度为0的Buffer实例
var a = new Buffer(0);
console.log(a);
> <Buffer >
// 长度为0的Buffer实例相同,a1,a2是一个实例
var a2 = new Buffer(0);
console.log(a2);
> <Buffer >
// 长度为10的Buffer实例
var a10 = new Buffer(10);
console.log(a10);
> <Buffer 22 37 02 00 00 00 00 04 00 00>
// 数组
var b = new Buffer(['a','b',12])
console.log(b);
> <Buffer 00 00 0c>
// 字符编码
var b2 = new Buffer('你好','utf-8');
console.log(b2);
> <Buffer e4 bd a0 e5 a5 bd>
Buffer类有5个类方法,用于Buffer类的辅助操作。
1) 编码检查,上文中提到Buffer和Javascript字符串转换时,需要显式的设置编码,那么这几种编码类型是Buffer所支持的。像中文处理只能使用utf-8编码,对于几年前常用的gbk,gb2312等编码是无法解析的。
// 支持的编码
console.log(Buffer.isEncoding('utf-8'))
console.log(Buffer.isEncoding('binary'))
console.log(Buffer.isEncoding('ascii'))
console.log(Buffer.isEncoding('ucs2'))
console.log(Buffer.isEncoding('base64'))
console.log(Buffer.isEncoding('hex')) # 16制进
> true
//不支持的编码
console.log(Buffer.isEncoding('gbk'))
console.log(Buffer.isEncoding('gb2312'))
> false
2) Buffer检查,很多时候我们需要判断数据的类型,对应后续的操作。
// 是Buffer类
console.log(Buffer.isBuffer(new Buffer('a')))
> true
// 不是Buffer
console.log(Buffer.isBuffer('adfd'))
console.log(Buffer.isBuffer('\u00bd\u00bd'))
> false
3) 字符串的字节长度,由于字符串编码不同,所以字符串长度和字节长度有时是不一样的。比如,1个中文字符是3个字节,通过utf-8编码输出就是4个中文字符,占12个字节。
var str2 = '粉丝日志';
console.log(str2 + ": " + str2.length + " characters, " + Buffer.byteLength(str2, 'utf8') + " bytes");
> 粉丝日志: 4 characters, 12 bytes
console.log(str2 + ": " + str2.length + " characters, " + Buffer.byteLength(str2, 'ascii') + " bytes");
> 粉丝日志: 4 characters, 4 bytes
4) Buffer的连接,用于连接Buffer的数组。我们可以手动分配Buffer对象合并后的Buffer空间大小,如果Buffer空间不够了,则数据会被截断。
var b1 = new Buffer("abcd");
var b2 = new Buffer("1234");
var b3 = Buffer.concat([b1,b2],8);
console.log(b3.toString());
> abcd1234
var b4 = Buffer.concat([b1,b2],32);
console.log(b4.toString());
console.log(b4.toString('hex'));//16进制输出
> abcd1234 乱码....
> 616263643132333404000000000000000000000000000000082a330200000000
var b5 = Buffer.concat([b1,b2],4);
console.log(b5.toString());
> abcd
程序运行的截图

5) Buffer的比较,用于Buffer的内容排序,按字符串的顺序。
var a1 = new Buffer('10');
var a2 = new Buffer('50');
var a3 = new Buffer('123');
// a1小于a2
console.log(Buffer.compare(a1,a2));
> -1
// a2小于a3
console.log(Buffer.compare(a2,a3));
> 1
// a1,a2,a3排序输出
console.log([a1,a2,a3].sort(Buffer.compare));
> [ <Buffer 31 30>, <Buffer 31 32 33>, <Buffer 35 30> ]
// a1,a2,a3排序输出,以utf-8的编码输出
console.log([a1,a2,a3].sort(Buffer.compare).toString());
> 10,123,50
2.2 写入Buffer
把数据写入到Buffer的操作,新建文件buffer_write.js。
~ vi buffer_write.js
//////////////////////////////
// Buffer写入
//////////////////////////////
// 创建空间大小为64字节的Buffer
var buf = new Buffer(64);
// 从开始写入Buffer,偏移0
var len1 = buf.write('从开始写入');
// 打印数据的长度,打印Buffer的0到len1位置的数据
console.log(len1 + " bytes: " + buf.toString('utf8', 0, len1));
// 重新写入Buffer,偏移0,将覆盖之前的Buffer内存
len1 = buf.write('重新写入');
console.log(len1 + " bytes: " + buf.toString('utf8', 0, len1));
// 继续写入Buffer,偏移len1,写入unicode的字符串
var len2 = buf.write('\u00bd + \u00bc = \u00be',len1);
console.log(len2 + " bytes: " + buf.toString('utf8', 0, len1+len2));
// 继续写入Buffer,偏移30
var len3 = buf.write('从第30位写入', 30);
console.log(len3 + " bytes: " + buf.toString('utf8', 0, 30+len3));
// Buffer总长度和数据
console.log(buf.length + " bytes: " + buf.toString('utf8', 0, buf.length));
// 继续写入Buffer,偏移30+len3
var len4 = buf.write('写入的数据长度超过Buffer的总长度!',30+len3);
// 超过Buffer空间的数据,没有被写入到Buffer中
console.log(buf.length + " bytes: " + buf.toString('utf8', 0, buf.length));
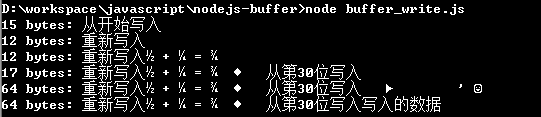
Node.js的节点的缓冲区,根据读写整数的范围,提供了不同宽度的支持,使从1到8个字节(8位、16位、32位)的整数、浮点数(float)、双精度浮点数(double)可以被访问,分别对应不同的writeXXX()函数,使用方法与buf.write()类似。
buf.write(string[, offset][, length][, encoding])
buf.writeUIntLE(value, offset, byteLength[, noAssert])
buf.writeUIntBE(value, offset, byteLength[, noAssert])
buf.writeIntLE(value, offset, byteLength[, noAssert])
buf.writeIntBE(value, offset, byteLength[, noAssert])
buf.writeUInt8(value, offset[, noAssert])
buf.writeUInt16LE(value, offset[, noAssert])
buf.writeUInt16BE(value, offset[, noAssert])
buf.writeUInt32LE(value, offset[, noAssert])
buf.writeUInt32BE(value, offset[, noAssert])
buf.writeInt8(value, offset[, noAssert])
buf.writeInt16LE(value, offset[, noAssert])
buf.writeInt16BE(value, offset[, noAssert])
buf.writeInt32LE(value, offset[, noAssert])
buf.writeInt32BE(value, offset[, noAssert])
buf.writeFloatLE(value, offset[, noAssert])
buf.writeFloatBE(value, offset[, noAssert])
buf.writeDoubleLE(value, offset[, noAssert])
buf.writeDoubleBE(value, offset[, noAssert])
另外,关于Buffer写入操作,还有一些Buffer类的原型函数可以操作。
Buffer复制函数 buf.copy(targetBuffer[, targetStart][, sourceStart][, sourceEnd])。
// 新建两个Buffer实例
var buf1 = new Buffer(26);
var buf2 = new Buffer(26);
// 分别向2个实例中写入数据
for (var i = 0 ; i < 26 ; i++) {
buf1[i] = i + 97; // 97是ASCII的a
buf2[i] = 50; // 50是ASCII的2
}
// 把buf1的内存复制给buf2
buf1.copy(buf2, 5, 0, 10); // 从buf2的第5个字节位置开始插入,复制buf1的从0-10字节的数据到buf2中
console.log(buf2.toString('ascii', 0, 25)); // 输入buf2的0-25字节
> 22222abcdefghij2222222222
Buffer填充函数 buf.fill(value[, offset][, end])。
// 新建Buffer实例,长度20节节
var buf = new Buffer(20);
// 向Buffer中填充数据
buf.fill("h");
console.log(buf)
> <Buffer 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68>
console.log("buf:"+buf.toString())
> buf:hhhhhhhhhhhhhhhhhhhh
// 清空Buffer中的数据
buf.fill();
console.log("buf:"+buf.toString())
> buf:
Buffer裁剪,buf.slice([start][, end])。返回一个新的缓冲区,它和旧缓冲区指向同一块内存,但是从索引 start 到 end 的位置剪裁。
var buf1 = new Buffer(26);
for (var i = 0 ; i < 26 ; i++) {
buf1[i] = i + 97;
}
// 从剪切buf1中的0-3的位置的字节,新生成的buf2是buf1的一个切片。
var buf2 = buf1.slice(0, 3);
console.log(buf2.toString('ascii', 0, buf2.length));
> abc
// 当修改buf1时,buf2同时也会发生改变
buf1[0] = 33;
console.log(buf2.toString('ascii', 0, buf2.length));
> !bc
2.3 读取Buffer
我们把数据写入Buffer后,我们还需要把数据从Buffer中读出来,新建文件buffer_read.js。我们可以通过readXXX()函数获得对应该写入时编码的索引值,再转换原始值取出,有这种方法操作中文字符就会变得麻烦,最常用的读取Buffer的方法,其实就是toString()。
~ vi buffer_read.js
//////////////////////////////
// Buffer 读取
//////////////////////////////
var buf = new Buffer(10);
for (var i = 0 ; i < 10 ; i++) {
buf[i] = i + 97;
}
console.log(buf.length + " bytes: " + buf.toString('utf-8'));
> 10 bytes: abcdefghij
// 读取数据
for (ii = 0; ii < buf.length; ii++) {
var ch = buf.readUInt8(ii); // 获得ASCII索引
console.log(ch + ":"+ String.fromCharCode(ch));
}
> 97:a
98:b
99:c
100:d
101:e
102:f
103:g
104:h
105:i
106:j
写入中文数据,以readXXX进行读取,会3个字节来表示一个中文字。
var buf = new Buffer(10);
buf.write('abcd')
buf.write('数据',4)
for (var i = 0; i < buf.length; i++) {
console.log(buf.readUInt8(i));
}
>97
98
99
100
230 // 230,149,176 代表“数”
149
176
230 // 230,141,174 代表“据”
141
174
如果想输出正确的中文,那么我们可以用toString(‘utf-8’)的函数来操作。
console.log("buffer :"+buf); // 默认调用了toString()的函数
> buffer :abcd数据
console.log("utf-8 :"+buf.toString('utf-8'));
> utf-8 :abcd数据
console.log("ascii :"+buf.toString('ascii'));//有乱码,中文不能被正确解析
> ascii :abcdf0f
.
console.log("hex :"+buf.toString('hex')); //16进制
> hex :61626364e695b0e68dae
对于Buffer的输出,我们用的最多的操作就是toString(),按照存入的编码进行读取。除了toString()函数,还可以用toJSON()直接Buffer解析成JSON对象。
var buf = new Buffer('test');
console.log(buf.toJSON());
> { type: 'Buffer', data: [ 116, 101, 115, 116 ] }
3. Buffer的性能测试
通过上文中对Buffer的介绍,我们已经了解了Buffer的基本使用,接下来,我们要开始做Buffer做一些测试。
3.1 8K的创建测试
每次我们创建一个新的Buffer实例时,都会检查当前Buffer的内存池是否已经满,当前内存池对于新建的Buffer实例是共享的,内存池的大小为8K。
如果新创建的Buffer实例大于8K时,就把Buffer交给SlowBuffer实例存储;如果新创建的Buffer实例小于8K,同时小于当前内存池的剩余空间,那么这个Buffer存入当前的内存池;如果Buffer实例不大0,则统一返回默认的zerobuffer实例。
下面我们创建2个Buffer实例,第一个是以4k为空间,第二个以4.001k为空间,循环创建10万次。
var num = 100*1000;
console.time("test1");
for(var i=0;i<num;i++){
new Buffer(1024*4);
}
console.timeEnd("test1");
> test1: 132ms
console.time("test2");
for(var j=0;j<num;j++){
new Buffer(1024*4+1);
}
console.timeEnd("test2");
> test2: 163ms
第二个以4.001k为空间的耗时多23%,这就意味着第二个,每二次循环就要重新申请一次内存池的空间。这是需要我们非常注意的。
3.2 多Buffer还是单一Buffer
当我们需要对数据进行缓存时,创建多个小的Buffer实例好,还是创建一个大的Buffer实例好?比如我们要创建1万个长度在1-2048之间不等的字符串。
var max = 2048; //最大长度
var time = 10*1000; //循环1万次
// 根据长度创建字符串
function getString(size){
var ret = ""
for(var i=0;i<size;i++) ret += "a";
return ret;
}
// 生成字符串数组,1万条记录
var arr1=[];
for(var i=0;i<time;i++){
var size = Math.ceil(Math.random()*max)
arr1.push(getString(size));
}
//console.log(arr1);
// 创建1万个小Buffer实例
console.time('test3');
var arr_3 = [];
for(var i=0;i<time;i++){
arr_3.push(new Buffer(arr1[i]));
}
console.timeEnd('test3');
> test3: 217ms
// 创建一个大实例,和一个offset数组用于读取数据。
console.time('test4');
var buf = new Buffer(time*max);
var offset=0;
var arr_4=[];
for(var i=0;i<time;i++){
arr_4[i]=offset;
buf.write(arr1[i],offset,arr1[i].length);
offset=offset+arr1[i].length;
}
console.timeEnd('test4');
> test4: 12ms
读取索引为2的数据。
console.log("src:[2]="+arr1[2]);
console.log("test3:[2]="+arr_3[2].toString());
console.log("test4:[2]="+buf.toString('utf-8',arr_4[2],arr_4[3]));
运行结果如图所示。
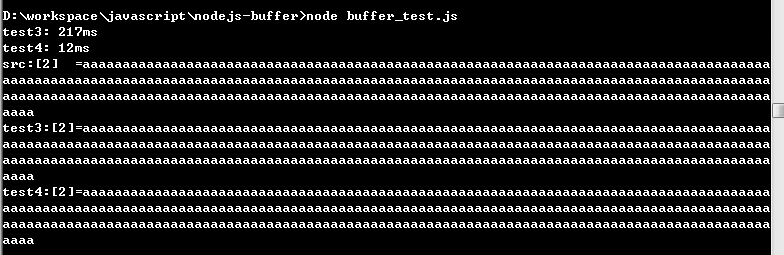
对于这类的需求来说,提前生成一个大的Buffer实例进行存储,要比每次生成小的Buffer实例高效的多,能提升一个数量级的计算效率。所以,理解并用好Buffer是非常重要的!!
3.3 string VS Buffer
有了Buffer我们是否需求把所有String的连接,都换成Buffer的连接?那么我们就需要测试一下,String和Buffer做字符串连接时,哪个更快一点?
下面我们进行字符串连接,循环30万次。
//测试三,Buffer VS string
var time = 300*1000;
var txt = "aaa"
var str = "";
console.time('test5')
for(var i=0;i<time;i++){
str += txt;
}
console.timeEnd('test5')
> test5: 24ms
console.time('test6')
var buf = new Buffer(time * txt.length)
var offset = 0;
for(var i=0;i<time;i++){
var end = offset + txt.length;
buf.write(txt,offset,end);
offset=end;
}
console.timeEnd('test6')
> test6: 85ms
从测试结果,我们可以明显的看到,String对字符串的连接操作,要远快于Buffer的连接操作。所以我们在保存字符串的时候,该用string还是要用string。那么只有在保存非utf-8的字符串以及二进制数据的情况,我们才用Buffer。
6. 程序代码
本文的程序代码,可以直接从Github上面下载本文项目中的源代码,按照片文章中的介绍学习buffer,下载地址:https://github.com/bsspirit/nodejs-buffer
也可以直接用github命令行来下载:
~ git clone git@github.com:bsspirit/nodejs-buffer.git # 下载github项目
~ cd nodejs-buffer # 进入下载目录
关于Node.js的底层,本人接触并不多,未能从V8(C++)的做更深入的研究,仅仅在使用层次上,写出我的总结。对于文中的错误或描述不清楚的地方,还请大牛予以指正!!
参考文章:
转载请注明出处:
http://blog.fens.me/nodejs-buffer/

请问如何把一个数字如21.生成一个4个byte的小尾段buffer。如把21 变成Buffer
buf.writeUInt32LE(value, offset[, noAssert])
找到方法了,谢谢
🙂