算法为王系列文章,涵盖了计算机算法,数据挖掘(机器学习)算法,统计算法,金融算法等的多种跨学科算法组合。在大数据时代的背景下,算法已经成为了金字塔顶的明星。一个好的算法可以创造一个伟大帝国,就像Google。
算法为王的时代正式到来….
关于作者:
- 张丹(Conan), 程序员/Quant: Java,R,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-lsm-regression
前言
很多经典的机器学习模型都是在最小二乘法的基础上发展起来的,理解最小二乘法的原理,对于我们掌握机器学习的高级算法是非常重要的,尤其是回归模型中。最小二乘法是主要是用来做函数拟合,或者求函数极值等问题。
本文以回归模型为例,介绍在最小二乘法在线性和非线性模型中的应用。
目录
- 最小二乘法介绍
- 最小二乘求解
- 线性最小二乘回归
- 非线性最小二乘回归
1. 最小二乘法介绍
最小二乘法(Least Squares Method,简记为LSE),源于天文学和测地学上的应用需要,是勒让德( A. M. Legendre)于1805年在其著作《计算慧星轨道的新方法》中提出的,它的主要思想是通过计算理论值与观测值之差的平方和最小,求解未知的参数。
最小二乘法的公式为:
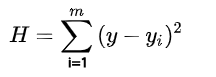

公式解读:
- H, 目标值,观测值与理论值之差的平方和
- H’, 最小化的H值
- y, 观测值
- yi, 理论值
- argmin, 最小化函数
我们先了把术语进行统一定义,观测值通常说的是我们的样本数据,理论值就是假设拟合函数产生的预测数据,目标函数是判断一个模型的好不好的标准,进行最小二乘法建立目标函数,让目标函数最小化。
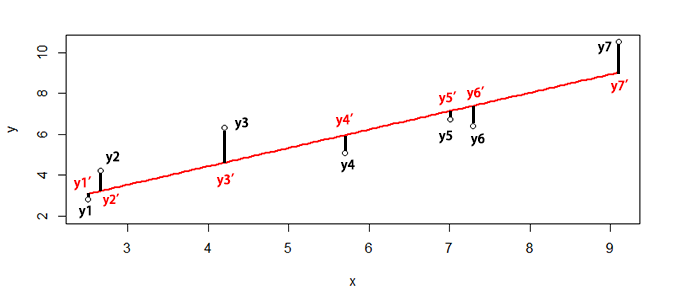
以上图为线性拟合为例,观测值为y1,y2,…,y7,理论值为y1′,y2′,….,y7’,是线上的点并与观测值的x相同,红色线就是我们要做的拟合直线,我们可以画出无数条这样的直线,判断标准是让这条线上的点的理论值与观测值的误差平方和最小,即最小二乘法。
SSE=sum((y1-y1')^2+(y2-y2')^2+(y3-y3')^2+(y4-y4')^2+(y5-y5')^2+(y6-y6')^2+(y7-y7')^2)利用最小二乘法,可以对数据进行线性和非线性拟合,使误差平方和(SSE)或残差平方和最小。如果观测到的误差近似正态分布时,这种方法是非常有效的。我们在线性回归模型中,要进行残差的正态分布检验,就是基于这个目的的,可以参考文章R语言解读一元线性回归模型
2. 最小二乘求解
在线性方程的求解或是数据曲线拟合中,利用最小二乘法求得的解则被称为最小二乘解。最小二乘法(又称最小平方法)是一种数学优化技术,它通过最小化误差的平方和寻找数据的最佳函数匹配。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
定义数据集x和y,两个变量。
> x<-c(6.19,2.51,7.29,7.01,5.7,2.66,3.98,2.5,9.1,4.2)
> y<-c(5.25,2.83,6.41,6.71,5.1,4.23,5.05,1.98,10.5,6.3)可视化,画出x,y变量的散点图。
> plot(x,y)
对数据进行最小二乘求解,找到最小二乘解。
> fit<-lsfit(x,y);fit
$coefficients
Intercept X
0.8310557 0.9004584
$residuals
[1] -1.1548933 -0.2612063 -0.9853975 -0.4332692 -0.8636686 1.0037250 0.6351198 -1.1022017
[9] 1.4747728 1.6870190
$intercept
[1] TRUE
$qr
$qt
[1] -17.1901414 6.2044421 -0.7047339 -0.1530724 -0.5856560 1.2766692 0.9102648
[8] -0.8295242 1.7584540 1.9625308
$qr
Intercept X
[1,] -3.1622777 -16.1718880
[2,] 0.3162278 6.8903149
[3,] 0.3162278 -0.2782874
[4,] 0.3162278 -0.2376506
[5,] 0.3162278 -0.0475287
[6,] 0.3162278 0.3936703
[7,] 0.3162278 0.2020970
[8,] 0.3162278 0.4168913
[9,] 0.3162278 -0.5409749
[10,] 0.3162278 0.1701682
$qraux
[1] 1.316228 1.415440
$rank
[1] 2
$pivot
[1] 1 2
$tol
[1] 1e-07
attr(,"class")
[1] "qr"
结果解读:
- coefficients, 系数的最小二乘估计,包括截距Intercept和自变量X
- residuals, 残差
- intercept, 有截距
- qt, 矩阵QR分解。QR分解法是将矩阵分解成一个正规正交矩阵与上三角形矩阵。关于矩阵的详细操作,请参考文章R语言中的矩阵计算
我们看到lsfit()函数使用矩阵的QR分解的方法,计算得出了最小二乘估计的截距Intercept和自变量系数。
目标:y=a*x+b,用最小二乘法估计出参数a和b。
根据最小二乘法的矩阵计算公式,我直接跳过了推到过程,得出结论。
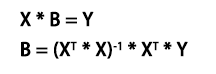
公式解释:
- X,为自变量矩阵
- Y,为因变量矩阵
- B,为参数,需要求解
- XT,X的转置矩阵
- *, 矩阵乘法
- -1, 计算逆矩阵
手动计算过程:
# 因变量矩阵
> y1<-matrix(y,ncol=1)
# 自变量矩阵,增加截距列
> x1<-matrix(c(x,rep(1,length(x))),ncol=2)
# 求解最小二乘解
> solve(t(x1)%*%x1) %*% t(x1) %*% y1
[,1]
[1,] 0.9004584
[2,] 0.8310557
对应到一元线性回归方程中,y = 0.9004584 * x + 0.8310557,与lsfit()的结果一致。
3. 线性最小二乘回归
接下来,我们先进行线性回归分析,以上面的数据集作为样本,只包含x和y。以普通最小二乘法进行线性回归,计算出预测值并和观测值进行比较,计算预测值和观测值的误差平方和,使得误差函数最小。线性回归模型的详细介绍,可以参考文章R语言解读一元线性回归模型, R语言解读多元线性回归模型
建立线性回归模型
# 建立回归模型
> line<-lm(y~x)
# 查看回归模型
> summary(line)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-1.1549 -0.9550 -0.3472 0.9116 1.6870
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.8311 0.9440 0.880 0.404338
x 0.9005 0.1698 5.302 0.000726 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.17 on 8 degrees of freedom
Multiple R-squared: 0.7785, Adjusted R-squared: 0.7508
F-statistic: 28.12 on 1 and 8 DF, p-value: 0.0007263
# 残差平方和
> sum(line$residuals^2)
[1] 10.95334
通过查看模型的结果数据,我们可以发现通过T检验自变量x是非常显著,但截距Intercept不显著。通过F检验判断出整个模型的自变量方差是非常显著。通过R^2的相关系数检验可以判断自变量和因变量是不是高度相关的,残差平方和(residual sum-of-squares)为10.95334,效果不好。
接下来,使用模型进行预测,生成预测值。
# 设置x的取值区间
> new <- data.frame(x = seq(min(x),max(x),len = 100))
# 预测结果
> pred<-predict(line,newdata=new)
进行可视化,把观测值与预测值进行展示,以散点表现观测值,以线表示预测值。
> plot(x,y)
> lines(new$x,pred,col="red",lwd=2)
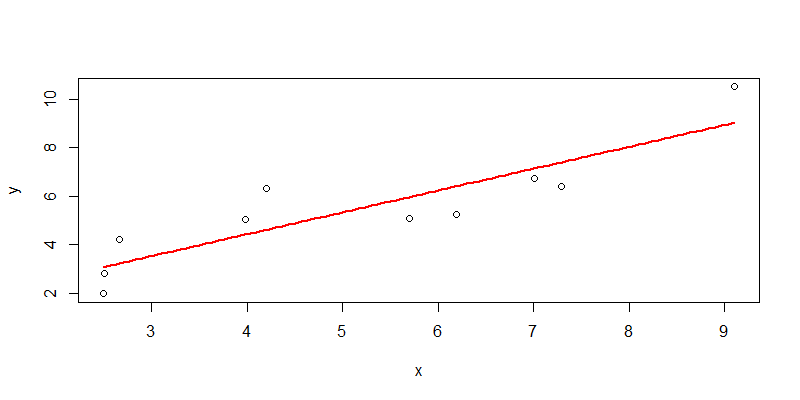
从图中我们可以很容易看出,拟合的效果并不好,与R^2检验不通过是一致的。那么,如果线性模型表现不好,我们可以试试非线性的模型,还是用最小二乘法进行非线性的回归。
4. 非线性最小二乘回归
由于散点的分布并不是线性的,我们再尝试用非线性的函数,进行最小二乘回归的拟合,包括一元二次函数,一元三次函数,指数函数,倒数函数。在R语言中,我们可以使用nls()函数,进行非线性最小二乘回归。
4.1 一元二次函数非线性拟合
定义公式 y ~ a*x+b*x^2+c ,其中x, x^2是一次函数和二次函数,a,b,c分别是参数,我们需要给定参数的初始值。
# 建立回归模型
> nline1 <- nls(y ~ a*x+b*x^2+c, start = list(a = 1,b = 1,c=2))
# 查看模型结果
> nline1
Nonlinear regression model
model: y ~ a * x + b * x^2 + c
data: parent.frame()
a b c
0.008987 0.082188 2.850389
residual sum-of-squares: 9.758
Number of iterations to convergence: 1
Achieved convergence tolerance: 3.024e-06
# 分析模型
> summary(nline1)
Formula: y ~ a * x + b * x^2 + c
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 0.008987 0.977890 0.009 0.993
b 0.082188 0.088760 0.926 0.385
c 2.850389 2.379763 1.198 0.270
Residual standard error: 1.181 on 7 degrees of freedom
Number of iterations to convergence: 1
Achieved convergence tolerance: 3.024e-06
通过查看模型的结果数据,我们可以发现通过T检验相关系数a,b,c都不显著,残差平方和(residual sum-of-squares)为9.758,数值过大,效果不好。
把观测值与预测值进行可视化展示,以散点表现观测值,以线表示预测值。
# 模型预测
> npred1<-predict(nline1,newdata=new)
# 可视化
> plot(x,y)
> lines(new$x,npred1,col="blue",lwd=2)
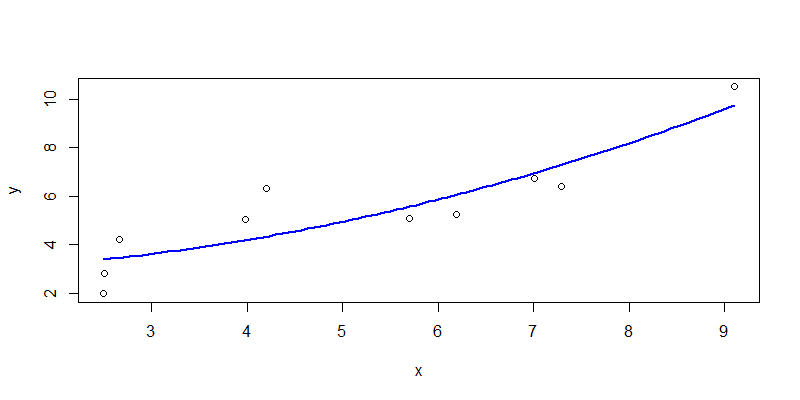
从图中我们可以看出,拟合的是一条曲线,效果不太好。接下来,我们再试试一元三次函数。
4.2 一元三次函数非线性拟合
定义公式 y ~ a*x+b*x^2+c*x^3+d ,其中x, x^2, x^3是一次函数,二次函数和三次函数,a,b,c,d分别是参数,我们需要给定参数的初始值。
使用一元三次函数,进行非线性拟合。
> nline2 <- nls(y ~ a*x+b*x^2+c*x^3+d, start = list(a = 1,b = 1,c=2,d=1))
# 查看模型结果
> nline2
Nonlinear regression model
model: y ~ a * x + b * x^2 + c * x^3 + d
data: parent.frame()
a b c d
10.011 -1.822 0.110 -12.516
residual sum-of-squares: 3.453
Number of iterations to convergence: 2
Achieved convergence tolerance: 3.983e-08
# 分析模型
> summary(nline2)
Formula: y ~ a * x + b * x^2 + c * x^3 + d
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 10.01051 3.08630 3.244 0.0176 *
b -1.82152 0.57797 -3.152 0.0198 *
c 0.10998 0.03323 3.310 0.0162 *
d -12.51586 4.88778 -2.561 0.0429 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.7586 on 6 degrees of freedom
Number of iterations to convergence: 2
Achieved convergence tolerance: 3.983e-08
通过查看模型的结果数据,我们可以发现通过T检验相关系数a,b,c,d在0.01的置信区间显著,残差平方和(residual sum-of-squares)为3.453,数值较小,效果应该算是还可以的,能够表达拟合的特征。
把观测值与预测值进行可视化展示,以散点表现观测值,以线表示预测值。
> npred2<-predict(nline2,newdata=new)
> plot(x,y)
> lines(new$x,npred2,col="green",lwd=2)
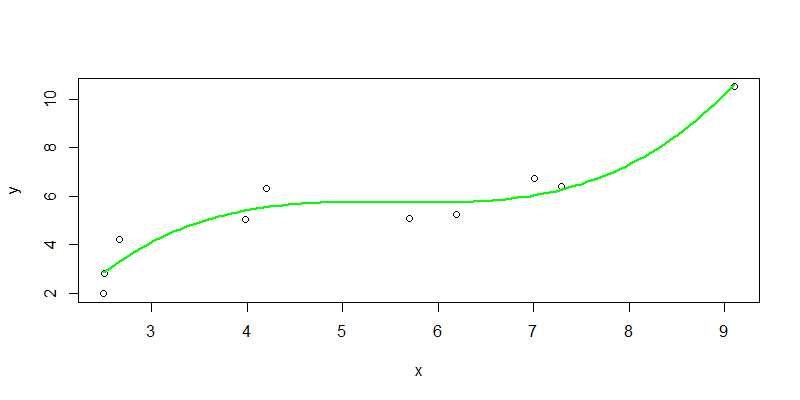
从图中我们可以看出,拟合的曲线基本穿过观测值的区域,直观上说明效果还不错,与数据检验给出的结论是一致的。
4.3 指数函数非线性拟合
定义公式 y ~ a*exp(b*x)+c ,其中exp(x)是指数函数,a,b,c分别是参数,我们需要给定参数的初始值。
> nline3 <- nls(y ~ a*exp(b*x)+c, start = list(a = 1,b = 1,c=2))
> nline3
Nonlinear regression model
model: y ~ a * exp(b * x) + c
data: parent.frame()
a b c
0.6720 0.2718 2.2087
residual sum-of-squares: 8.966
Number of iterations to convergence: 17
Achieved convergence tolerance: 7.136e-06
> summary(nline3)
Formula: y ~ a * exp(b * x) + c
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 0.6720 1.2127 0.554 0.597
b 0.2718 0.1764 1.541 0.167
c 2.2087 2.2447 0.984 0.358
Residual standard error: 1.132 on 7 degrees of freedom
Number of iterations to convergence: 17
Achieved convergence tolerance: 7.136e-06
通过查看模型的结果数据,我们可以发现通过T检验相关系数a,b,c都不显著,残差平方和(residual sum-of-squares)为8.966,数值过大,效果不好。
> npred3<-predict(nline3,newdata=new)
> plot(x,y)
> lines(new$x,npred3,col="yellow",lwd=2)
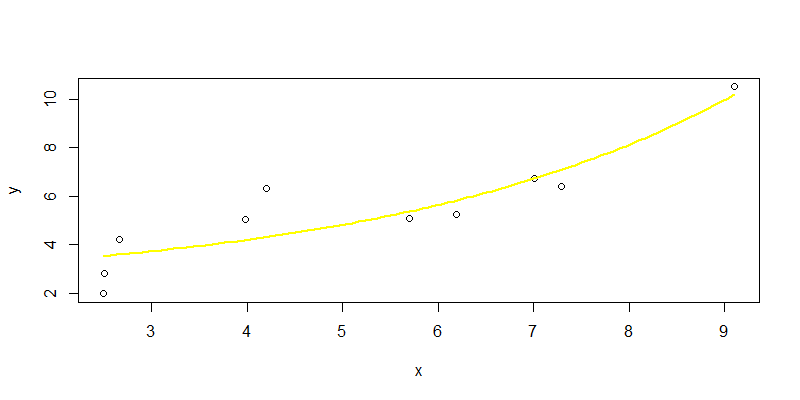
从图中我们可以看出,指数函数的拟合曲线,和二次函数表现差不多,效果不太好。
4.4 倒数函数非线性拟合
定义公式 y ~ y ~ b/x+c ,其中1/x是倒数函数,b,c分别是参数,我们需要给定参数的初始值。
使用倒数函数,进行拟合。
> nline4 <- nls(y ~ b/x+c, start = list(b = 1,c=2))
# 查看模型结果
> nline4
Nonlinear regression model
model: y ~ b/x + c
data: parent.frame()
b c
-17.0 9.5
residual sum-of-squares: 15.74
Number of iterations to convergence: 1
Achieved convergence tolerance: 1.259e-07
> summary(nline4)
Formula: y ~ b/x + c
Parameters:
Estimate Std. Error t value Pr(>|t|)
b -17.003 4.108 -4.139 0.00326 **
c 9.500 1.077 8.817 2.15e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.403 on 8 degrees of freedom
Number of iterations to convergence: 1
Achieved convergence tolerance: 1.259e-07
通过查看模型的结果数据,我们可以发现通过T检验相关系数b,c非常显著,残差平方和(residual sum-of-squares)为15.74,数值较大,效果不好。
把观测值与预测值进行可视化展示,以散点表现观测值,以线表示预测值。
> npred4<-predict(nline4,newdata=new)
> plot(x,y)
> lines(new$x,npred4,col="gray",lwd=2)
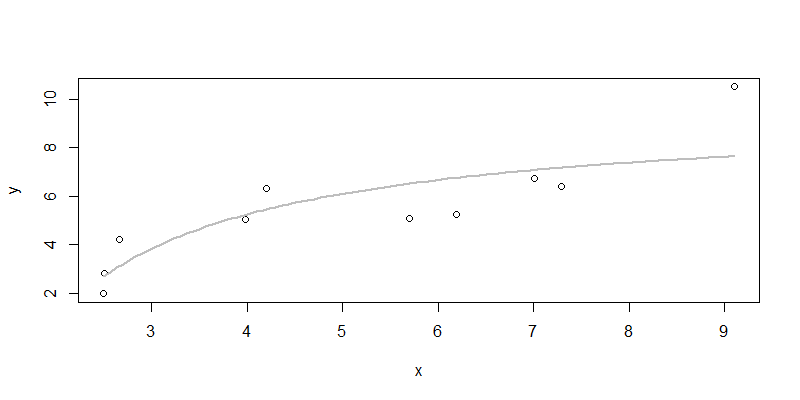
从图中我们可以看出,倒数函数的拟合曲线,确实也效果不太好,而且最后一个点有个想离群点,如果没有最后一个点这个效果应该是更好的。
4.5 模型优化
根据上面的几种模型验证的结果,我手动进行了优化,发现高次函数进行拟合效果会更好。定义公式 y ~ a*x^3+b*x^5+c*x^7+e*d^9+e*x^11 ,其中高次函数定义为11次,并去掉了截距。
> nline5 <- nls(y ~ a*x^3+b*x^5+c*x^7+d*x^9+e*x^11,
+ start = list(a=1,b=2,c=1,d=1,e=1))
# 查看模型结果
> nline5
Nonlinear regression model
model: y ~ a * x^3 + b * x^5 + c * x^7 + d * x^9 + e * x^11
data: parent.frame()
a b c d e
2.959e-01 -2.064e-02 5.837e-04 -7.324e-06 3.367e-08
residual sum-of-squares: 2.583
Number of iterations to convergence: 3
Achieved convergence tolerance: 2.343e-07
# 模型分析
> summary(nline5)
Formula: y ~ a * x^3 + b * x^5 + c * x^7 + d * x^9 + e * x^11
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 2.959e-01 5.132e-02 5.767 0.0022 **
b -2.064e-02 6.176e-03 -3.341 0.0205 *
c 5.837e-04 2.468e-04 2.365 0.0644 .
d -7.324e-06 3.940e-06 -1.859 0.1222
e 3.367e-08 2.139e-08 1.574 0.1763
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.7187 on 5 degrees of freedom
Number of iterations to convergence: 3
Achieved convergence tolerance: 2.343e-07
通过查看模型的结果数据,我们可以发现通过T检验相关系数a,b,c是显著,残差的误差平方和(residual sum-of-squares)为2.583,数值是最小的,而且比三次函数增长了2上系数,效果应该算不错的,能够表达拟合的特征。
把观测值与预测值进行可视化展示,以散点表现观测值,以线表示预测值。
> npred5<-predict(nline5,newdata=new)
> plot(x,y)
> lines(new$x,npred5,col="purple3",lwd=2)
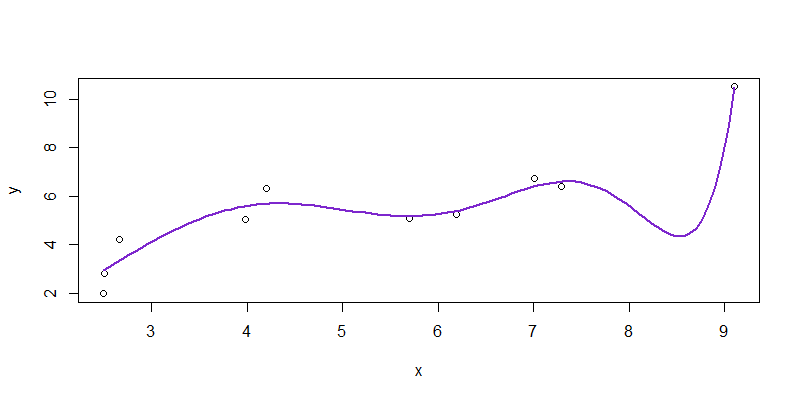
从图中我们可以看出,拟合的曲线穿过观测值的区域,并且非常贴近部分数据点,直观上说明效果很好,与数据检验给出的结论是一致的。
4.6 总结
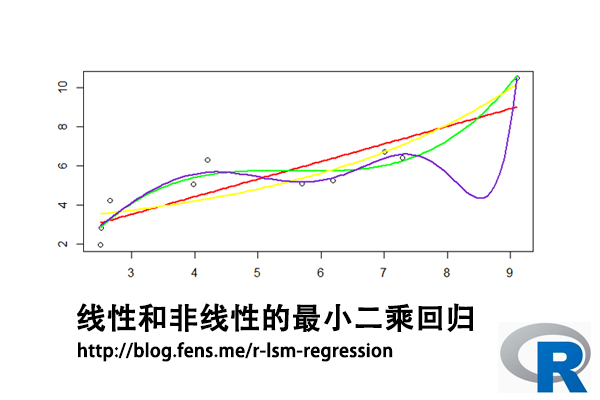
我们把上面的1种线性函数和5种非线性的拟合函数的模型评价指标,整理到一个表格中。其中,三次函数和高次函数的拟合效果是不错的,而其他的几种拟合效果,都是不太好的。判断好坏的标准,就是残差的误差平方和,同时参数的T检验显著,才是比较好的拟合模型。
| 拟合函数 | 残差平方和 | 参数T检验显著性 | 解释性 | 颜色 |
| 一次函数 | 10.95334 | 不显著 | 好 | 红色 |
| 二次函数 | 9.758 | 不显著 | 好 | 蓝色 |
| 三次函数 | 3.453 | 显著 | 不好 | 绿色 |
| 指数函数 | 8.966 | 不显著 | 不好 | 黄色 |
| 倒数函数 | 15.74 | 显著 | 好 | 灰色 |
| 高次函数 | 2.583 | 显著 | 无法解释 | 紫色 |
最后,合并所有拟合曲线,画到同一张图上,进行对比。绿色的三次函数拟合曲线,和紫色的高次函数拟合曲线效果最好。
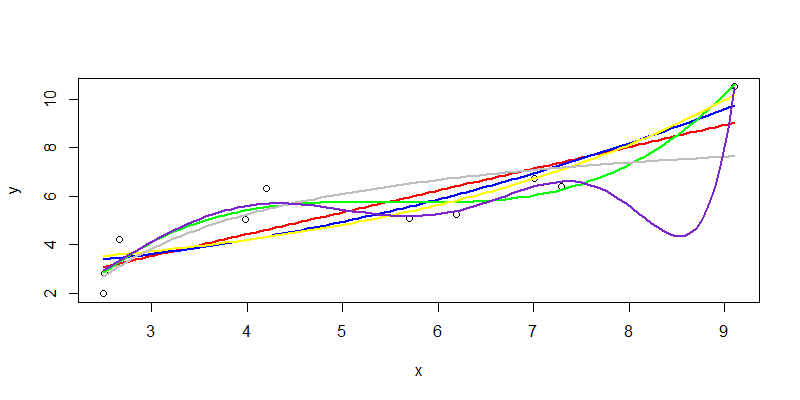
但是,高次函数也带来了的负面问题,一是过拟合,二是业务的可解释性非常差。如果x和y分别带入到业务场景,比如x是货物的重量和y是货物的单价,那么x的11次方,完全是无法理解的,等同于一个黑盒的模型。所以,真正落地项目在使用的时候,要根据业务场景的要求,在准确度,可解释性,复杂度等标准之下,进行权衡。
本文利用最小二乘法,用R语言进行了线性回归和非线性回归的实验。验证了最小二乘法在处理回归问题上是非常有效的,除了回归问题,最小二乘法还能解决分类的问题。最小二乘法作为机器学习的底层算法,是非常值得我们学习和掌握的,明白原理就能掌握一类的高级模型。
转载请注明出处:
http://blog.fens.me/r-lsm-regression
