R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-text-ngram/

前言
大语言模型的文字表达能力,让我们所惊叹算法的魅力。语言能力并不是AI与生俱来的,而且通过底层的各种算法像拼接积木似的组装出来的。我们需要有一个高质量的预料库,然后通过模型训练,你也能拥有文字表达能力。
ngram就给了我们,让惊叹变成现实的这种能力。
目录
- ngram算法介绍
- 用R语言实现ngram
- 生成式算法:用ngram生成一段文字
1. ngram算法介绍
n-gram是一种基于统计语言模型的算法,它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。N就是将句子做切割,N个单词为一组。每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
如:A B A C A B B,可以切分为
P(A B A C A B B) = P(A)*P(B|A)*P(A|A,B)*P(C|A,B,A)…*P(B|A B A C A B)
为了简化问题,我们可以假设当前的字出现只跟前一个字有关,这样就形成了二元的模型。
P(A B A C A B B) = P(A)*P(B|A)*P(A|B)*…*P(B|B)
ngram模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的,一元为unigram,是二元的bi-gram,三元的tri-gram。
- 一元表示:P(A B A C A B B) = P(A)*P(B)*P(A)*P(C)*P(A)*P(B)*P(B)
- 二元表示:P(A B A C A B B) = P(A)*P(B|A)*P(A|A)*P(C|A)…*P(B|B)
- 三元表示:P(A B A C A B B) = P(A)*P(B|A)*P(A|A,B)*P(C|B,A)…*P(B|A,B)
当N值增大时:对单词的约束性更高,具有更高的辨识力,复杂度也随之增大。当N值减小时:词文本出现的次数概率更可靠,统计结果更可靠,但对词文本的约束性减小
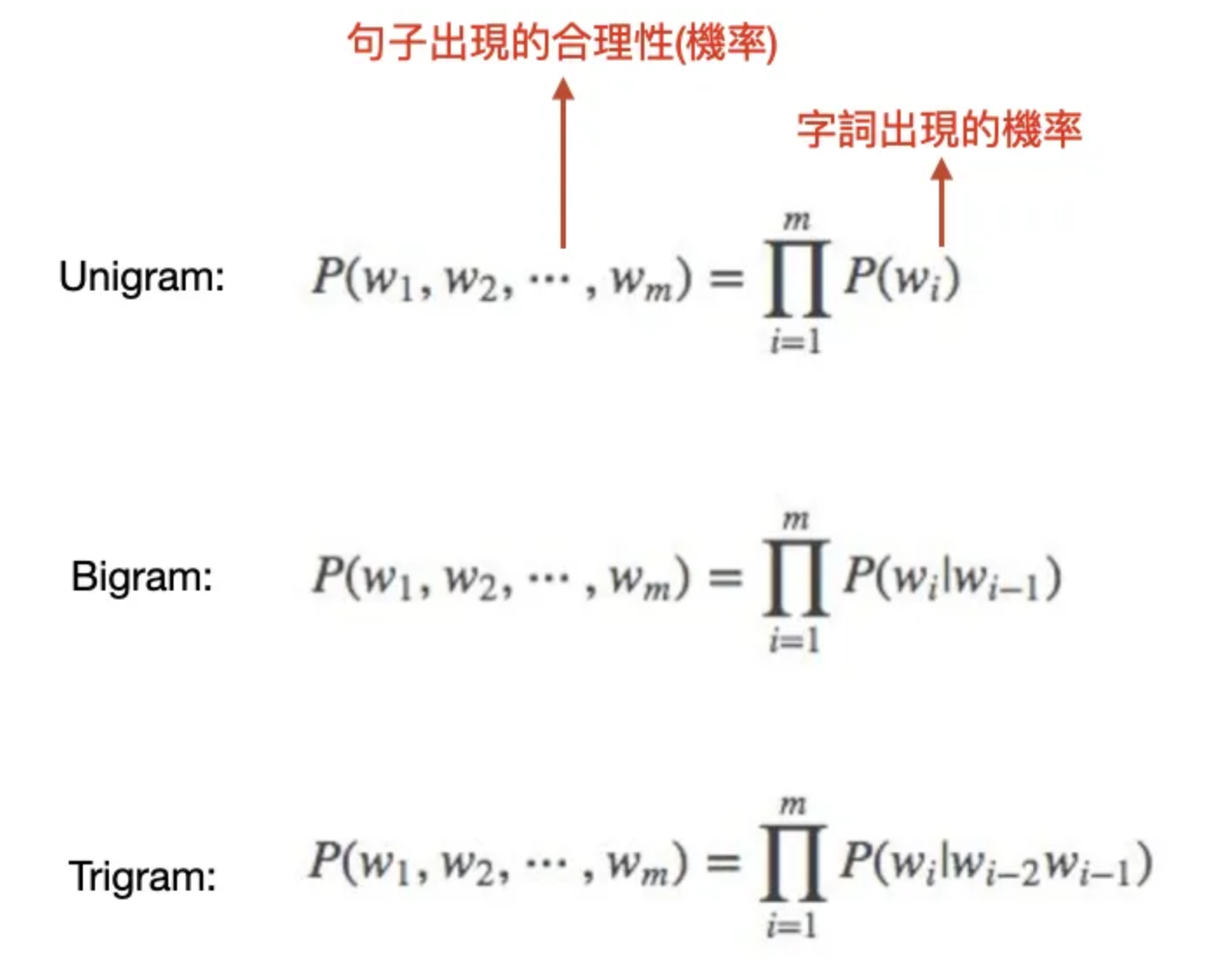
为了考虑字词在开头和结尾的位置,可以在文本中加入 start 的 token 和 end 的 token。
P(A B A C A B B) = P(A|<start>)*P(B|A)*P(A|B)*…*P(B|B)*P(<end>|B)
N-gram 的使用方法:
- 文本预处理:
首先,对原始文本进行分词、去除停用词、词干提取等预处理操作,以便得到适合进行N-gram 统计的词序列。 - 生成N-grams:
根据设定的N 值,将预处理后的词序列拆分成若干个N-gram。 - 统计频率:
统计每个N-gram 在文本中出现的次数,并计算其频率。 - 构建语言模型:
利用统计得到的N-gram 频率信息,构建一个语言模型,用于预测下一个词的概率。 - 使用语言模型:
在实际应用中,可以使用构建好的语言模型来预测下一个词的出现概率,从而实现诸如文本生成、语音识别、机器翻译等任务。
2. 用R语言实现ngram
ngram是一个 R 包,用于构建 n-gram(即“分词”),以及根据给定文本输入的 n-gram 结构生成新文本(即“胡言乱语”)。该包可用于进行严肃的分析,或创建说些有趣话语的“机器人”。ngram包旨在以极快的速度对已标记的语料库进行标记化、汇总和汇总。由于其架构设计,我们还能够处理海量文本,并且性能扩展性非常好。基准测试和示例用法可在软件包简介中找到。
ngram包安装和加载
# 安装
> install.packages("ngram")
# 加载
> library(ngram)
创建文本变量x
# 创建变量
> x <- "A B A C A B B"
# 查看字符串属性
> string.summary(x)
Chars: 13
Letters: 7
Whitespace: 6
Punctuation: 0
Digits: 0
Words: 7
Sentences: 0
Lines: 1
Wordlens: 0 7
9 1
Senlens: 0
10
Syllens: 0 3
9 1
进行ngram二元分词n=2,并预测下一个出现的词。
# ngram二元分词
> ng <- ngram (x , n =2)
> ng
An ngram object with 5 2-grams
查看ngram的分词预测,可以设置output=”full”时是打印所有的结果。使用output=”truncated”,只会显示前 5 个 n-gram。
# 查看分词结果
> print (ng , output ="full")
C A | 1
B {1} |
B A | 1
C {1} |
B B | 1
NULL {1} |
A C | 1
A {1} |
A B | 2
B {1} | A {1} |
我们可以看到每个 3-gram 及其下一个可能的 “词”,以及每个词在给定 n-gram 之后的出现频率。
- 第一组C A 的下一个可能词是 B,因为在输入的字符串中,序列 C A 的后面只有 B。
- 第五组A B 的后面有一次 A 和一次 B。
- 第三组B B 是终结符,即后面什么也没有。
生成短语表,文本的 ngram 表示一旦生成,就可以非常简单地获取一些有趣的摘要信息。函数 get.phrasetable() 生成了一个 n-grams 表,以及它们在文本中的频率和比例。
> get.phrasetable ( ng )
ngrams freq prop
1 A B 2 0.3333333
2 C A 1 0.1666667
3 B A 1 0.1666667
4 B B 1 0.1666667
5 A C 1 0.1666667
AB,出现过2次,概率是0.33。其他组合,都只出现过一次,概率是0.16.
再分别生成n=1和n=3的短语表。
> get.phrasetable ( ngram (x , n =1) )
ngrams freq prop
1 A 3 0.4285714
2 B 3 0.4285714
3 C 1 0.1428571
> get.phrasetable ( ngram (x , n =3) )
ngrams freq prop
1 C A B 1 0.2
2 A B A 1 0.2
3 A B B 1 0.2
4 B A C 1 0.2
5 A C A 1 0.2
另外还有2个工具函数
# 提取组合
> get.ngrams(ng)
[1] "C A" "B A" "B B" "A C" "A B"
# 查看原始的数据
> get.string(ng)
[1] "A B A C A B B"
使用babble()函数,通过ngrams来生成与输入字符串具有相同统计属性的新字符串。
随机生成3组字符。
> babble (ng , 10)
[1] "A C A B B B B A B B "
> babble (ng , 10)
[1] "C A B B C A B B A C "
> babble (ng , 20)
[1] "B A C A B B B A C A B B A B B B A C A B "
我们也可以指定种子生成相同的内容。
> babble (ng , 10 , seed =10)
[1] "A C A B B B B A B B "
> babble (ng , 10 , seed =10)
[1] "A C A B B B B A B B "
3. 生成式算法:用ngram生成一段文字
通过babble(),是不是看到生成式大模型的影子了,为什么模型能生成出来说法通顺的文字呢。
我们多给一些语言描述,让ngram进行算法识别。
生成语言文字。
x<-c(
+ "how are you",
+ "I like you",
+ "I love you",
+ "I think you're the best for me",
+ "We re good friends",
+ "We're all good"
+ )
# 拼接成一个句子
> x<-str_c(x,collapse = " ")
> x
[1] "how are you I like you I love you I think you're the best for me We re good friends We're all good"
构建ngram模型
> ng <- ngram (x , n=2)
> ng
An ngram object with 20 2-grams
# 查看语言序列
> print (ng , output ="truncated")
the best | 1
for {1} |
for me | 1
We {1} |
friends We're | 1
all {1} |
are you | 1
I {1} |
I think | 1
you're {1} |
[[ ... results truncated ... ]]
查看短语概率表
> get.phrasetable ( ng )
ngrams freq prop
1 you I 3 0.13636364
2 the best 1 0.04545455
3 for me 1 0.04545455
4 friends We're 1 0.04545455
5 are you 1 0.04545455
6 I think 1 0.04545455
7 good friends 1 0.04545455
8 I like 1 0.04545455
9 think you're 1 0.04545455
10 like you 1 0.04545455
11 all good 1 0.04545455
12 I love 1 0.04545455
13 me We 1 0.04545455
14 love you 1 0.04545455
15 We re 1 0.04545455
16 how are 1 0.04545455
17 re good 1 0.04545455
18 you're the 1 0.04545455
19 best for 1 0.04545455
20 We're all 1 0.04545455
接下来就是神奇的时刻,自动生成10个短语。
> babble (ng , 10)
[1] "me We re good friends We're all good I love "
> babble (ng , 10)
[1] "for me We re good friends We're all good I "
> babble (ng , 10)
[1] "you're the best for me We re good friends We're "
> babble (ng , 10)
[1] "think you're the best for me We re good friends "
> babble (ng , 10)
[1] "We're all good I think you're the best for me "
> babble (ng , 10)
[1] "like you I like you I think you're the best "
看上去,很符合预期。虽然比不是现在的大语言模型,能生成完整的语句,但是已经有了生成式模型的影子了。
本文的代码已上传到github:https://github.com/bsspirit/r-string-match/blob/main/ngram.r
转载请注明出处:
http://blog.fens.me/r-text-ngram/