R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-text-tf-idf/

前言
在互联网的今天,我们每天都会生产和消费大量的文本信息,如报告、文档、新闻、聊天、图书、小说、语音转化的文字等。海量的文本信息,不仅提供扩宽的研究对象和研究领域,也为商业使用带来了巨大的机会。
TF-IDF是一种通过计算词频,进行文本信息检索的一种方式,常用对文本数据进行向量化特征的描述。
目录
- 什么是TF-IDF介绍
- tidytext包计算TF-IDF
- quanteda包计算TF-IDF
1. 什么是TF-IDF介绍
TF-IDF (词频-逆文档频率) 是一种在信息检索和文本挖掘中常用的加权技术。它衡量一个词语对于一个文档的重要性,通过结合词频(TF) 和逆文档频率(IDF) 来计算。
TF (词频): 表示词语在特定文档中出现的次数。一个词语在文档中出现的次数越多,通常认为它在该文档中越重要。
IDF (逆文档频率): 表示词语在整个语料库中的普遍程度。如果一个词语在很多文档中都出现,说明它比较常见,对区分文档的贡献就越小;反之,如果一个词语只出现在少数文档中,说明它对区分这些文档越重要。
TF-IDF 的计算: TF-IDF 值是TF 值和IDF 值的乘积。
公式:
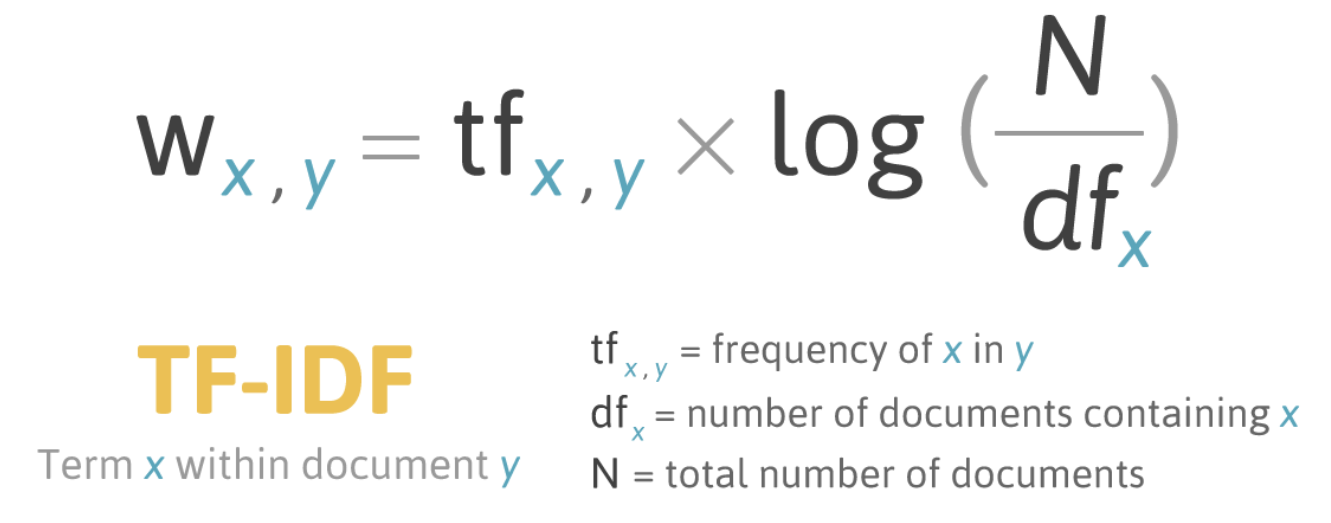
TF (词频) = (词语在文档中出现的次数) / (文档中的总词数)
IDF (逆文档频率) = log(总文档数/ 包含该词语的文档数+ 1) (加1 是为了避免除以零的情况)
TF-IDF = TF * IDF
作用: TF-IDF 通过综合考虑词语在文档内的频率和在语料库中的普遍程度,能够有效地识别出对文档具有区分度的关键词。在搜索引擎中,TF-IDF 常被用于计算文档与用户查询的相关性,从而对搜索结果进行排序。
总结: TF-IDF 是一种简单而有效的文本特征提取方法,通过对词语的权重计算,可以帮助我们更好地理解和利用文本数据.
2. tidytext包计算TF-IDF
R语言中,有多个包都支持TF-IDF的计算。首先,我们先使用tidytext包。
安装tidytext包
# 安装tidytext包
> install.packages("tidytext")
# 加载tidytext包
> library(tidytext)
# 加载其他工具包
> library(dplyr)
> library(tibble)
定义10段文本数据,并进行编号。
# 定义文本数据
> ss <- c(
+ "R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大",
+ "R语言作为统计学一门语言,一直在小众领域闪耀着光芒。",
+ "现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。",
+ "直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。",
+ "随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。",
+ "TF-IDF (词频-逆文档频率) 是一种在信息检索和文本挖掘中常用的加权技术。",
+ "它衡量一个词语对于一个文档的重要性,通过结合词频(TF) 和逆文档频率(IDF) 来计算。",
+ "TF (词频): 表示词语在特定文档中出现的次数。一个词语在文档中出现的次数越多,通常认为它在该文档中越重要。",
+ "IDF (逆文档频率): 表示词语在整个语料库中的普遍程度。如果一个词语在很多文档中都出现,说明它比较常见,对区分文档的贡献就越小;反之,如果一个词语只出现在少数文档中,说明它对区分这些文档越重要。",
+ "TF-IDF 的计算: TF-IDF 值是TF 值和IDF 值的乘积。"
+ )
# 转成tibble类型,并增加列编号
> s1<- ss %>% as_tibble() %>% rowid_to_column("ID")
# 查看s1变量
> s1
# A tibble: 10 × 2
ID value
<int> <chr>
1 1 R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的…
2 2 R语言作为统计学一门语言,一直在小众领域闪耀着光芒。……
3 3 现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。……
4 4 直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。……
5 5 随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。……
6 6 TF-IDF (词频-逆文档频率) 是一种在信息检索和文本挖掘中常用的加权技术。…
7 7 它衡量一个词语对于一个文档的重要性,通过结合词频(TF) 和逆文档频率(IDF)…
8 8 TF (词频): 表示词语在特定文档中出现的次数。一个词语在文档中出现的次数越多…
9 9 IDF (逆文档频率): 表示词语在整个语料库中的普遍程度。如果一个词语在很多文…
10 10 TF-IDF 的计算: TF-IDF 值是TF 值和IDF 值的乘积。……
计算每个文档中的词频,用于计算tf-idf
# 计算文档中的词频
> ss_words <- s1 %>%
+ unnest_tokens(words, value) %>%
+ count(ID, words, sort = TRUE);ss_words
# A tibble: 191 × 3
ID words n
<int> <chr> <int>
1 1 的 5
2 9 文 5
3 9 档 5
4 1 r 3
5 4 的 3
6 5 的 3
7 8 在 3
8 8 文 3
9 8 档 3
10 9 在 3
# 181 more rows
# Use `print(n = ...)` to see more rows
使用bind_tf_idf()函数,计算每个词的tf,idf,tf-idf。
tf-idf 的思想是通过减少常用词的权重并增加在文档集合或语料库中不经常使用的词的权重,在这种情况下,我们找到每个文档内容的重要词。计算 tf-idf 会尝试查找文本中重要(即常见)但不太常见的单词。
# 计算tf-idf
> ss_tfidf <- ss_words %>%
+ bind_tf_idf(ID, words, n)
> ss_tfidf
# A tibble: 191 × 6
ID words n tf idf tf_idf
<int> <chr> <int> <dbl> <dbl> <dbl>
1 1 的 5 0.278 1.68 0.466
2 9 文 5 0.455 1.29 0.585
3 9 档 5 0.455 1.29 0.585
4 1 r 3 0.429 1.68 0.720
5 4 的 3 0.167 2.13 0.354
6 5 的 3 0.167 2.19 0.365
7 8 在 3 0.375 1.85 0.695
8 8 文 3 0.273 1.85 0.505
9 8 档 3 0.273 1.85 0.505
10 9 在 3 0.375 1.29 0.483
# 181 more rows
# Use `print(n = ...)` to see more rows
# 以tf_idf列分值高倒序排序
> ss_tfidf %>%
+ arrange(desc(tf_idf))
# A tibble: 191 × 6
ID words n tf idf tf_idf
<int> <chr> <int> <dbl> <dbl> <dbl>
1 10 值 3 1 2.70 2.70
2 10 乘 1 1 2.70 2.70
3 10 积 1 1 2.70 2.70
4 2 一 1 1 2.41 2.41
5 2 一直在 1 1 2.41 2.41
6 2 作为 1 1 2.41 2.41
7 2 光芒 1 1 2.41 2.41
8 2 学 1 1 2.41 2.41
9 2 小众 1 1 2.41 2.41
10 2 闪耀着 1 1 2.41 2.41
# 181 more rows
# Use `print(n = ...)` to see more rows
通过tf-idf判断2个文本的相似性
# 加载widyr包
> library(widyr)
# 判断2段文本的相似性
> ss_tfidf %>%
+ pairwise_similarity(ID, words, tf_idf, sort = TRUE)
# A tibble: 70 × 3
item1 item2 similarity
<int> <int> <dbl>
1 8 9 0.135
2 9 8 0.135
3 7 10 0.0907
4 10 7 0.0907
5 6 10 0.0769
6 10 6 0.0769
7 3 2 0.0620
8 2 3 0.0620
9 7 9 0.0596
10 9 7 0.0596
# 60 more rows
# Use `print(n = ...)` to see more rows
程序提示第8段和第9段文本最相似,查看第8段和第9段文本。
> ss[8]
[1] "TF (词频): 表示词语在特定文档中出现的次数。一个词语在文档中出现的次数越多,通常认为它在该文档中越重要。"
> ss[9]
[1] "IDF (逆文档频率): 表示词语在整个语料库中的普遍程度。如果一个词语在很多文档中都出现,说明它比较常见,对区分文档的贡献就越小;反之,如果一个词语只出现在少数文档中,说明它对区分这些文档越重要。"
3. quanteda包计算TF-IDF
我们再换另一个包quanteda来计算TF-IDF。quanteda包,是一个能力非常强大的文本处理包,详细内容请参考文章用R语言进行量化文本分析quanteda
安装和加载quanteda
# 安装
> install.pacakges("quanteda")
> install.pacakges("quanteda.textstats")
# 加载
> library("quanteda")
> library("quanteda.textstats")
使用上文中已建立的ss文档对象,提取关键词,形成词频矩阵。
> ssdfm
Document-feature matrix of: 10 documents, 144 features (84.51% sparse) and 0 docvars.
features
docs r 的 极 客 理想 系列 文章 , 涵 盖了
text1 3 5 1 1 1 1 1 5 1 1
text2 1 0 0 0 0 0 0 1 0 0
text3 1 0 0 0 0 0 0 4 0 0
text4 1 3 0 0 0 0 0 1 0 0
text5 1 3 0 0 0 0 0 1 0 0
text6 0 1 0 0 0 0 0 0 0 0
[ reached max_ndoc ... 4 more documents, reached max_nfeat ... 134 more features ]
使用dfm_tfidf()函数,对词频矩阵计算tfidf值,形成tfidf矩阵。
> ssidf<-dfm_tfidf(ssdfm)
> ssidf
Document-feature matrix of: 10 documents, 144 features (84.51% sparse) and 0 docvars.
features
docs r 的 极 客 理想 系列 文章 , 涵 盖了
text1 0.90309 0.48455007 1 1 1 1 1 0.48455007 1 1
text2 0.30103 0 0 0 0 0 0 0.09691001 0 0
text3 0.30103 0 0 0 0 0 0 0.38764005 0 0
text4 0.30103 0.29073004 0 0 0 0 0 0.09691001 0 0
text5 0.30103 0.29073004 0 0 0 0 0 0.09691001 0 0
text6 0 0.09691001 0 0 0 0 0 0 0 0
[ reached max_ndoc ... 4 more documents, reached max_nfeat ... 134 more features ]
用词频矩阵计算2个文档的相似性
> ssdfm %>%
+ textstat_simil(method = "cosine") %>%
+ as.matrix()
text1 text2 text3 text4 text5 text6 text7 text8 text9 text10
text1 1.0000000 0.21426863 0.44799204 0.4716523 0.5079850 0.13525045 0.19705795 0.20087684 0.22392949 0.23823145
text2 0.2142686 1.00000000 0.40996003 0.2702264 0.2425356 0.04950738 0.07868895 0.08823529 0.11803342 0.04756515
text3 0.4479920 0.40996003 1.00000000 0.2197177 0.2366432 0.03450328 0.13710212 0.12298801 0.24678382 0.03314968
text4 0.4716523 0.27022641 0.21971769 1.0000000 0.4828079 0.15161961 0.15061881 0.20266981 0.13555693 0.25492496
text5 0.5079850 0.24253563 0.23664319 0.4828079 1.0000000 0.20412415 0.16222142 0.31529631 0.19466571 0.27456259
text6 0.1352504 0.04950738 0.03450328 0.1516196 0.2041241 1.00000000 0.46358632 0.44556639 0.36424640 0.28022427
text7 0.1970580 0.07868895 0.13710212 0.1506188 0.1622214 0.46358632 1.00000000 0.55082263 0.56578947 0.22269967
text8 0.2008768 0.08823529 0.12298801 0.2026698 0.3152963 0.44556639 0.55082263 1.00000000 0.72787276 0.19026060
text9 0.2239295 0.11803342 0.24678382 0.1355569 0.1946657 0.36424640 0.56578947 0.72787276 1.00000000 0.09544271
text10 0.2382314 0.04756515 0.03314968 0.2549250 0.2745626 0.28022427 0.22269967 0.19026060 0.09544271 1.00000000
用tfidf矩阵计算2个文档的相似性
> ssidf %>%
+ textstat_simil(method = "cosine") %>%
+ as.matrix()
text1 text2 text3 text4 text5 text6 text7 text8 text9 text10
text1 1.000000000 0.0219479864 0.0513556447 0.024124188 0.028953788 0.0118764224 0.015076777 0.0064026405 0.006519969 0.0136248773
text2 0.021947986 1.0000000000 0.1217612800 0.075175409 0.041645241 0.0001912012 0.001083631 0.0009743142 0.001830469 0.0001785203
text3 0.051355645 0.1217612800 1.0000000000 0.018812586 0.022578816 0.0001504185 0.002943756 0.0023568679 0.005326873 0.0001404424
text4 0.024124188 0.0751754091 0.0188125856 1.000000000 0.026150152 0.0021071189 0.002852493 0.0038248671 0.002336975 0.0037986508
text5 0.028953788 0.0416452412 0.0225788162 0.026150152 1.000000000 0.0157598001 0.003423554 0.0678499967 0.021859872 0.0045591308
text6 0.011876422 0.0001912012 0.0001504185 0.002107119 0.015759800 1.0000000000 0.178921295 0.1558538111 0.128284299 0.1178464227
text7 0.015076777 0.0010836308 0.0029437558 0.002852493 0.003423554 0.1789212950 1.000000000 0.2790485085 0.271452809 0.0899040023
text8 0.006402640 0.0009743142 0.0023568679 0.003824867 0.067849997 0.1558538111 0.279048509 1.0000000000 0.421606371 0.0331304236
text9 0.006519969 0.0018304690 0.0053268734 0.002336975 0.021859872 0.1282842988 0.271452809 0.4216063707 1.000000000 0.0195965092
text10 0.013624877 0.0001785203 0.0001404424 0.003798651 0.004559131 0.1178464227 0.089904002 0.0331304236 0.019596509 1.0000000000
从2个相似性矩阵返回的结果来看,都是第8段和第9段更相似。
本文从TF-IDF的实现的角度,介绍了TF-IDF怎么使用R语言程序进行计算。这些计算就是把文本转成向量化数据的方法。
本文的代码已上传到github:https://github.com/bsspirit/r-string-match/blob/main/tfidf.r
转载请注明出处:
http://blog.fens.me/r-text-tf-idf/