R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员R,Nodejs,Java
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-linear-regression/
前言
在我们的日常生活中,存在大量的具有相关性的事件,比如大气压和海拔高度,海拔越高大气压强越小;人的身高和体重,普遍来看越高的人体重也越重。还有一些可能存在相关性的事件,比如知识水平越高的人,收入水平越高;市场化的国家经济越好,则货币越强势,反而全球经济危机,黄金等避险资产越走强。
如果我们要研究这些事件,找到不同变量之间的关系,我们就会用到回归分析。一元线性回归分析是处理两个变量之间关系的最简单模型,是两个变量之间的线性相关关系。让我们一起发现生活中的规律吧。
由于本文为非统计的专业文章,所以当出现与教课书不符的描述,请以教课书为准。本文力求用简化的语言,来介绍一元线性回归的知识,同时配合R语言的实现。
目录
- 一元线性回归介绍
- 数据集和数学模型
- 回归参数估计
- 回归方程的显著性检验
- 残差分析和异常点检测
- 模型预测
1. 一元线性回归介绍
回归分析(Regression Analysis)是用来确定2个或2个以上变量间关系的一种统计分析方法。如果回归分析中,只包括一个自变量X和一个因变量Y时,且它们的关系是线性的,那么这种回归分析称为一元线性回归分析。
回归分析属于统计学的基本模型,涉及统计学基础,就会有一大堆的名词和知识点需要介绍。
在回归分析中,变量有2类:因变量 和 自变量。因变量通常是指实际问题中所关心的指标,用Y表示。而自变量是影响因变量取值的一个变量,用X表示,如果有多个自变量则表示为X1, X2, …, Xn。
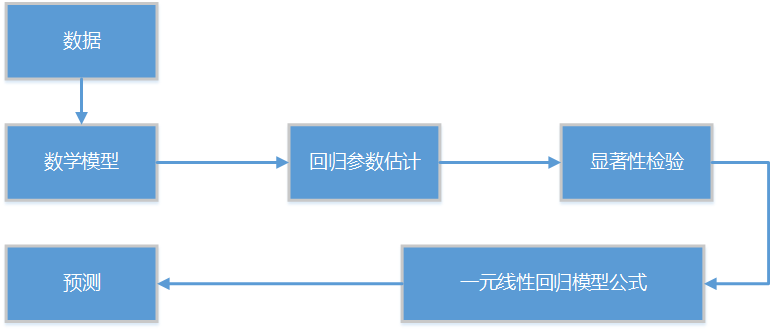
回归分析研究的主要步骤:
- 确定因变量Y 与 自变量X1, X2, …, Xn 之间的定量关系表达式,即回归方程。
- 对回归方程的置信度检查。
- 判断自变量Xn(n=1,2,…,m)对因变量的影响。
- 利用回归方程进行预测。
本文会根据回归分析的的主要步骤,进行结构梳理,介绍一元线性回归模型的使用方法。
2. 数据集和数学模型
先让我们通过一个例子开始吧,用一组简单的数据来说明一元线性回归分析的数学模型的原理和公式。找出下面数据集中Y与X的定量关系。
数据集为2016年3月1日,白天开盘的交易数据,为锌的2个期货合约的分钟线的价格数据。数据集包括有3列,索引列为时间,zn1.Close为ZN1604合约的1分钟线的报价数据,zn2.Close为ZN1605合约的1分钟线的报价数据。
数据集如下:
zn1.Close zn2.Close
2016-03-01 09:01:00 14075 14145
2016-03-01 09:02:00 14095 14160
2016-03-01 09:03:00 14095 14160
2016-03-01 09:04:00 14095 14165
2016-03-01 09:05:00 14120 14190
2016-03-01 09:06:00 14115 14180
2016-03-01 09:07:00 14110 14170
2016-03-01 09:08:00 14110 14175
2016-03-01 09:09:00 14105 14170
2016-03-01 09:10:00 14105 14170
2016-03-01 09:11:00 14120 14180
2016-03-01 09:12:00 14105 14170
2016-03-01 09:13:00 14105 14170
2016-03-01 09:14:00 14110 14175
2016-03-01 09:15:00 14105 14175
2016-03-01 09:16:00 14120 14185
2016-03-01 09:17:00 14125 14190
2016-03-01 09:18:00 14115 14185
2016-03-01 09:19:00 14135 14195
2016-03-01 09:20:00 14125 14190
2016-03-01 09:21:00 14135 14205
2016-03-01 09:22:00 14140 14210
2016-03-01 09:23:00 14140 14200
2016-03-01 09:24:00 14135 14205
2016-03-01 09:25:00 14140 14205
2016-03-01 09:26:00 14135 14205
2016-03-01 09:27:00 14130 14205
我们以zn1.Close列的价格为X,zn2.Close列的价格为Y,那么试试找到自变量X和因变量Y的关系的表达式。
为了直观起见,我们可以先画出一张散点图,以X为横坐标,Y为纵坐标,每个点对应一个X和一个Y。
# 数据集已存在df变量中
> head(df)
zn1.Close zn2.Close
2016-03-01 09:01:00 14075 14145
2016-03-01 09:02:00 14095 14160
2016-03-01 09:03:00 14095 14160
2016-03-01 09:04:00 14095 14165
2016-03-01 09:05:00 14120 14190
2016-03-01 09:06:00 14115 14180
# 分别给x,y赋值
> x<-as.numeric(df[,1])
> y<-as.numeric(df[,2])
# 画图
> plot(y~x+1)
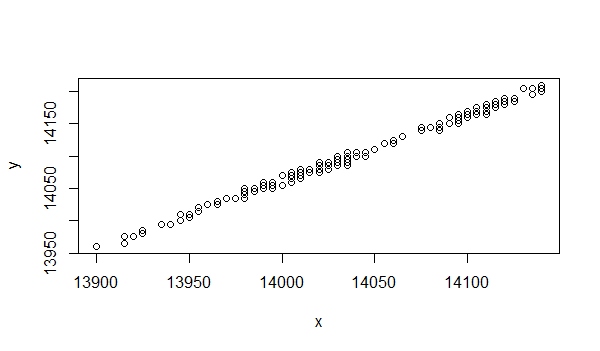
从散点图上发现 X和Y 的排列基本是在一条直线附近,那么我们可以假设X和Y的关系是线性,可以用公式表式为。
Y = a + b * X + c- Y,为因变量
- X,为自变量
- a,为截距
- b,为自变量系数
- a+b*X, 表示Y随X的变化而线性变化的部分
- c, 为残差或随机误差,是其他一切不确定因素影响的总和,其值不可观测。假定c是符合均值为0方差为σ^2的正态分布 ,记作c~N(0,σ^2)
对于上面的公式,称函数f(X) = a + b * X 为一元线性回归函数,a为回归常数,b为回归系数,统称回归参数。X 为回归自变量或回归因子,Y 为回归因变量或响应变量。如果(X1,Y1),(X2,Y2)…(Xn,Yn)是(X,Y)的一组观测值,则一元线性回归模型可表示为
Yi = a + b * X + ci, i= 1,2,...n
其中E(ci)=0, var(ci)=σ^2, i=1,2,...n
通过对一元线性回归模型的数学定义,接下来让我们利用数据集做回归模型的参数估计。
3. 回归参数估计
对于上面的公式,回归参数a,b是我们不知道的,我们需要用参数估计的方法来计算出a,b的值,而从得到数据集的X和Y的定量关系。我们的目标是要计算出一条直线,使直接线上每个点的Y值和实际数据的Y值之差的平方和最小,即(Y1实际-Y1预测)^2+(Y2实际-Y2预测)^2+ …… +(Yn实际-Yn预测)^2 的值最小。参数估计时,我们只考虑Y随X的线性变化的部分,而残差c是不可观测的,参数估计法并不需要考虑残差,对于残差的分析在后文中介绍。
令公式变形为a和b的函数Q(a,b), 即 (Y实际-Y测试)的平方和,变成到(Y实际 – (a+b*X))的平方和。
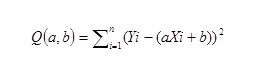
公式一 回归参数变形公式
通过最小二乘估计推导出a和b的求解公式,详细的推导过程请参考文章一元线性回归的细节
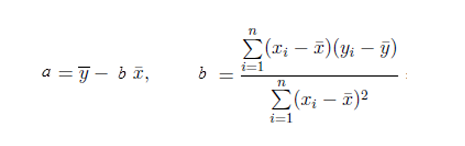
公式二 回归参数计算公式
其中 x和y的均值,计算方法如下
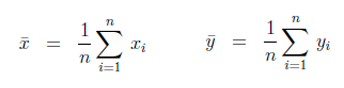
公式三 均值计算公式
有了这个公式,我们就可以求出a和b两个的回归参数的解了。
接下来,我们用R语言来实现对上面数据的回归模型的参数估计,R语言中可以用lm()函数来实现一元线性回归的建模过程。
# 建立线性回归模型
> lm.ab<-lm(y ~ 1+x)
# 打印参数估计的结果
> lm.ab
Call:
lm(formula = y ~ 1 + x)
Coefficients:
(Intercept) x
-349.493 1.029
如果你想动手来计算也可以自己实现公式。
# x均值
> Xm<-mean(x);Xm
[1] 14034.82
# y均值
> Ym<-mean(y);Ym
[1] 14096.76
# 计算回归系数
> b <- sum((x-Xm)*(y-Ym)) / sum((x-Xm)^2) ;b
[1] 1.029315
# 计算回归常数
> a <- Ym - b * Xm;a
[1] -349.493
回归参数a和b的计算结果,与lm()函数的计算结果是相同的。有了a和b的值,我们就可以画出这条近似的直接线。
计算公式为:
Y= a + b * X = -349.493 + 1.029315 * X 画出回归线。
> plot(y~x+1)
> abline(lm.ab)
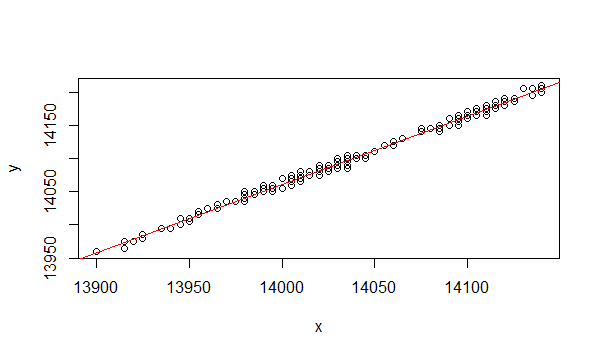
这条直线是我们用数据拟合出来的,是一个近似的值。我们看到有些点在线上,有些点不在线上。那么要评价这条回归线拟合的好坏,我们就需要对回归模型进行显著性检验。
4. 回归方程的显著性检验
从回归参数的公式二可知,在计算过程中并不一定要知道Y和X是否有线性相关的关系。如果不存相关关系,那么回归方程就没有任何意义了,如果Y和X是有相关关系的,即Y会随着X的变化而线性变化,这个时候一元线性回归方程才有意义。所以,我们需要用假设检验的方法,来验证相关性的有效性。
通常会采用三种显著性检验的方法。
- T检验法:T检验是检验模型某个自变量Xi对于Y的显著性,通常用P-value判断显著性,小于0.01更小时说明这个自变量Xi与Y相关关系显著。
- F检验法:F检验用于对所有的自变量X在整体上看对于Y的线性显著性,也是用P-value判断显著性,小于0.01更小时说明整体上自变量与Y相关关系显著。
- R^2(R平方)相关系统检验法:用来判断回归方程的拟合程度,R^2的取值在0,1之间,越接近1说明拟合程度越好。
在R语言中,上面列出的三种检验的方法都已被实现,我们只需要把结果解读。上文中,我们已经通过lm()函数构建一元线性回归模型,然后可以summary()函数来提取模型的计算结果。
> summary(lm.ab) # 计算结果
Call:
lm(formula = y ~ 1 + x)
Residuals:
Min 1Q Median 3Q Max
-11.9385 -2.2317 -0.1797 3.3546 10.2766
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.495e+02 7.173e+01 -4.872 2.09e-06 ***
x 1.029e+00 5.111e-03 201.390 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.232 on 223 degrees of freedom
Multiple R-squared: 0.9945, Adjusted R-squared: 0.9945
F-statistic: 4.056e+04 on 1 and 223 DF, p-value: < 2.2e-16
模型解读:
- Call,列出了回归模型的公式。
- Residuals,列出了残差的最小值点,1/4分位点,中位数点,3/4分位点,最大值点。
- Coefficients,表示参数估计的计算结果。
- Estimate,为参数估计列。Intercept行表示常数参数a的估计值 ,x行表示自变量x的参数b的估计值。
- Std. Error,为参数的标准差,sd(a), sd(b)
- t value,为t值,为T检验的值
- Pr(>|t|) ,表示P-value值,用于T检验判定,匹配显著性标记
- 显著性标记,***为非常显著,**为高度显著, **为显著,·为不太显著,没有记号为不显著。
- Residual standard error,表示残差的标准差,自由度为n-2。
- Multiple R-squared,为相关系数R^2的检验,越接近1则越显著。
- Adjusted R-squared,为相关系数的修正系数,解决多元回归自变量越多,判定系数R^2越大的问题。
- F-statistic,表示F统计量,自由度为(1,n-2),p-value:用于F检验判定,匹配显著性标记。
通过查看模型的结果数据,我们可以发现通过T检验的截距和自变量x都是非常显著,通过F检验判断出整个模型的自变量是非常显著,同时R^2的相关系数检验可以判断自变量和因变量是高度相关的。
最后,我们通过的回归参数的检验与回归方程的检验,得到最后一元线性回归方程为:
Y = -349.493 + 1.029315 * X 5. 残差分析和异常点检测
在得到的回归模型进行显著性检验后,还要在做残差分析(预测值和实际值之间的差),检验模型的正确性,残差必须服从正态分布N(0,σ^2)。
我们可以自己计算数据残差,并进行正态分布检验。
# 残差
> y.res<-residuals(lm.ab)
# 打印前6条数据
> head(y.res)
1 2 3 4 5 6
6.8888680 1.3025744 1.3025744 6.3025744 5.5697074 0.7162808
# 正态分布检验
> shapiro.test(y.res)
Shapiro-Wilk normality test
data: y.res
W = 0.98987, p-value = 0.1164
# 画出残差散点图
> plot(y.res)
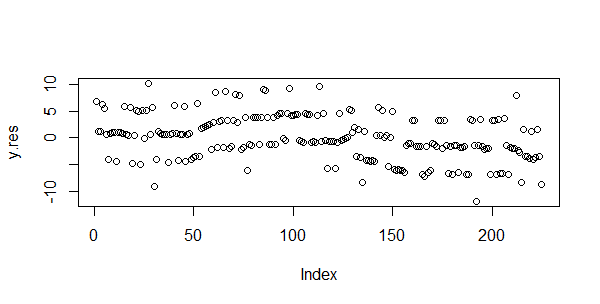
对残差进行Shapiro-Wilk正态分布检验,W接近1,p-value>0.05,证明数据集符合正态分布!关于正态分布的介绍,请参考文章常用连续型分布介绍及R语言实现。
同时,我们也可以用R语言的工具生成4种用于模型诊断的图形,简化自己写代码计算的操作。
# 画图,回车展示下一张
> plot(lm.ab)
Hit to see next plot: # 残差拟合图
Hit to see next plot: # 残差QQ图
Hit to see next plot: # 标准化的残差对拟合值
Hit to see next plot: # 标准化残差对杠杆值
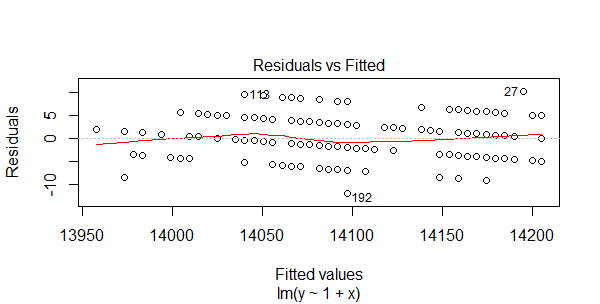
图1,残差和拟合值对比图
对残差和拟合值作图,横坐标是拟合值,纵坐标是残差。残差和拟合值之间,数据点均匀分布在y=0两侧,呈现出随机的分布,红色线呈现出一条平稳的曲线并没有明显的形状特征,说明残差数据表现非常好。
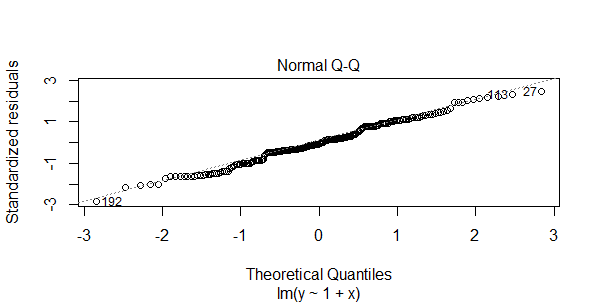
图2,残差QQ图
残差QQ图,用来描述残差是否符合正态分布。图中的数据点按对角直线排列,趋于一条直线,并被对角直接穿过,直观上符合正态分布。对于近似服从正态分布的标准化残差,应该有 95% 的样本点落在 [-2,2] 区间内。
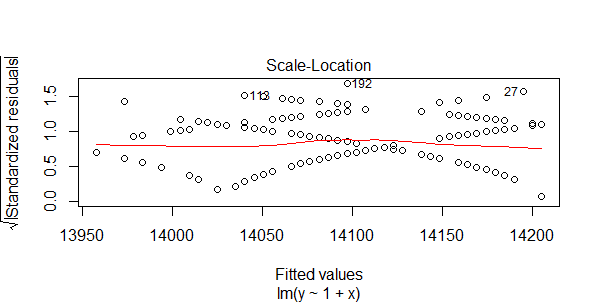
图3,标准化残差平方根和拟合值对比图
对标准化残差平方根和拟合值作图,横坐标是拟合值,纵坐标是标准化后的残差平方根。与残差和拟合值对比图(图1)的判断方法类似,数据随机分布,红色线呈现出一条平稳的曲线,无明显的形状特征。
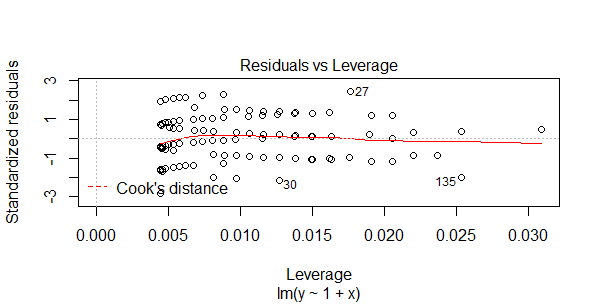
图4,标准残差和杠杆值对比图
对标准化残差和杠杆值作图,虚线表示的cooks距离等高线,通常用Cook距离度量的回归影响点。本图中没有出现红色的等高线,则说明数据中没有特别影响回归结果的异常点。
如果想把把4张图画在一起进行展示,可以改变画布布局。
> par(mfrow=c(2,2))
> plot(lm.ab)
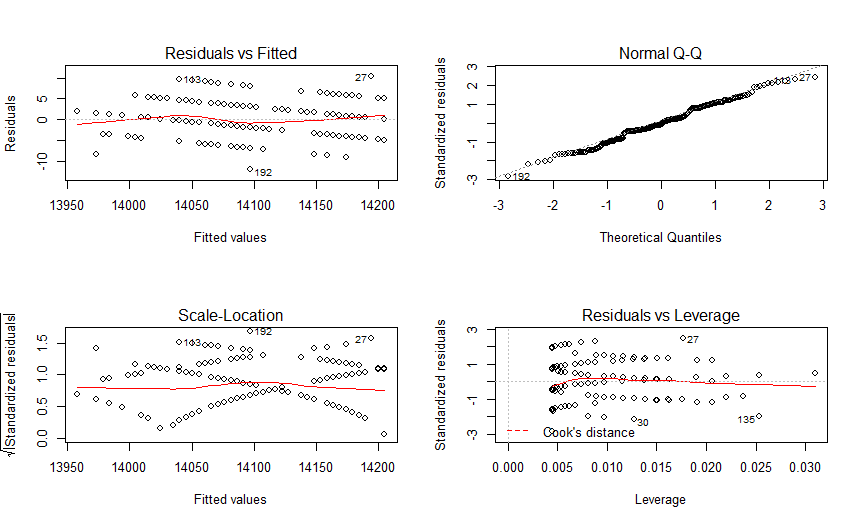
看到上面4幅中,每幅图上都有一些点被特别的标记出来了,这些点是可能存在的异常值点,如果要对模型进行优化,我们可以从这些来入手。但终于本次残差分析的结果已经很好了,所以对于异常点的优化,可能并不能明显的提升模型的效果。
从图中发现,索引编号为27和192的2个点在多幅图中出现。我们假设这2个点为异常点,从数据中去掉这2个点,再进行显著性检验和残差分析。
# 查看27和192
> df[c(27,192),]
zn1.Close zn2.Close
2016-03-01 09:27:00 14130 14205
2016-03-01 14:27:00 14035 14085
# 新建数据集,去掉27和192
> df2<-df[-c(27,192),]
回归建模和显著性检验。
> x2<-as.numeric(df2[,1])
> y2<-as.numeric(df2[,2])
> lm.ab2<-lm(y2 ~ 1+x2)
> summary(lm.ab2)
Call:
lm(formula = y2 ~ 1 + x2)
Residuals:
Min 1Q Median 3Q Max
-9.0356 -2.1542 -0.2727 3.3336 9.5879
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.293e+02 7.024e+01 -4.688 4.83e-06 ***
x2 1.028e+00 5.004e-03 205.391 < 2e-16 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.117 on 221 degrees of freedom
Multiple R-squared: 0.9948, Adjusted R-squared: 0.9948
F-statistic: 4.219e+04 on 1 and 221 DF, p-value: < 2.2e-16
对比这次的显著性检验结果和之前结果,T检验,F检验 和 R^2检验,并没有明显的效果提升,结果和我预想的是一样的。所以,通过残差分析和异常点分析,我认为模型是有效的。
6. 模型预测
最后,我们获得了一元线性回归方程的公式,就可以对数据进行预测了。比如,对给定X=x0时,计算出y0=a+b*x0的值,并计算出置信度为1-α的预测区间。
当X=x0,Y=y0时,置信度为1-α的预测区间为
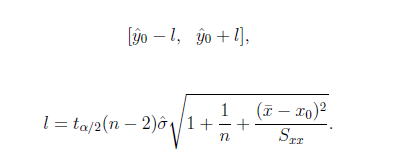
即
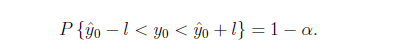
我们可以用R语言的predict()函数来计算预测值y0,和相应的预测区间。程序算法如下。
> new<-data.frame(x=14040)
> lm.pred<-predict(lm.sol,new,interval="prediction",level=0.95)
# 预测结果
> lm.pred
fit lwr upr
1 14102.09 14093.73 14110.44
当x0=14040时,在预测区间为0.95的概率时,y0的值为 14102,预测区间为[14093.73,14110.44]。
我们通过图形来表示。
> plot(y~x+1)
> abline(lm.ab,col='red')
> points(rep(newX$x,3),y=lm.pred,pch=19,col=c('red','blue','green'))
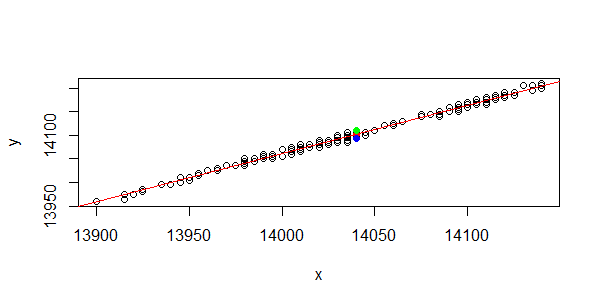
其中,红色点为y0的值,蓝色点为预测区间最小值,绿色点为预测区间最大值。
对于统计模型中最核心部分就在结果解读,本文介绍了一元回归模型的基本的建模过程和模型的详细解读方法。在我们掌握了这种方法以后,就可以更容易地理解和学习 多元回归,非线性回归 等更多的模型,并把这些模型应用到实际的工作中了。下一篇文章R语言解读多元线性回归模型,请继续阅读。
转载请注明出处:
http://blog.fens.me/r-linear-regression/
