用IT技术玩金融系列文章,将介绍如何使用IT技术,处理金融大数据。在互联网混迹多年,已经熟练掌握一些IT技术。单纯地在互联网做开发,总觉得使劲的方式不对。要想靠技术养活自己,就要把技术变现。通过“跨界”可以寻找新的机会,创造技术的壁垒。
金融是离钱最近的市场,也是变现的好渠道!今天就开始踏上“用IT技术玩金融”之旅!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/finance-index/

前言
对于刚进股市的新手,一般都是比较盲目的选股。而中国大妈型的股民,一般都是听电视的财经节目,推荐的股票来选股的。不清楚基本面,是最容易被套死股市里的。
如果能简单地了解一下股指,从“沪深300”中选股,也许能够稍微弥补一下对基本面的知识的不足。
注:本人金融入门级,如果文章描述不对或者不准确的地方,还请专家指点。
目录
- 股指是什么?
- 中国证券市场的股指
- 沪深300指数
- 沪深300指数统计分析
1. 股指是什么?
股指是股票价格指数简称,股票价格指数即股票指数。是由证券交易所或金融服务机构编制的表明股票行市变动的一种供参考的指示数字。由于股票价格起伏无常,投资者必然面临市场价格风险。对于具体某一种股票的价格变化,投资者容易了解,而对于多种股票的价格变化,要逐一了解,既不容易,也不胜其烦。为了适应这种情况和需要,一些金融服务机构就利用自己的业务知识和熟悉市场的优势,编制出股票价格指数,公开发布,作为市场价格变动的指标。投资者据此就可以检验自己投资的效果,并用以预测股票市场的动向。
计算股票指数,要考虑三个因素:
- 抽样,即在众多股票中抽取少数具有代表性的成份股
- 加权,按单价或总值加权平均,或不加权平均
- 计算程序,计算算术平均数、几何平均数,或兼顾价格与总值
股价平均数的计算
1). 简单算术股价平均数
简单算术股价平均数是将样本股票每日收盘价之和除以样本数得出的,即:
简单算术股价平均数=(P1+P2+P3+…+ Pn)/n
世界上第一个股票价格平均──道·琼斯股价平均数在1928年10月1日前就是使用简单算术平均法计算的。
现假设从某一股市采样的股票为A、B、C、D四种,在某一交易日的收盘价分别为10元、16元、24元和30元,计算该市场股价平均数。将上述数置入公式中,即得:
股价平均数=(P1+P2+P3+P4)/n=(10+16+24+30)/4=20(元)
有两个缺点:
- 未考虑各种样本股票的权数,从而不能区分重要性不同的样本股票对股价平均数的不同影响
- 当样本股票发生股票分割派发红股、增资等情况时,股价平均数会产生断层而失去连续性,使时间序列前后的比较发生困难。例如,上述D股票发生以1股分割为3股时,股价势必从30元下调为10元, 这时平均数就不是按上面计算得出的20元,而是(10+16+24+10)/4=15(元)。这就是说,由于D股分割技术上的变化,导致股价平均数从20元下跌为15元(这还未考虑其他影响股价变动的因素),显然不符合平均数作为反映股价变动指标的要求。
2). 修正的股份平均数
修正的股价平均数有两种:
- 除数修正法,又称道式修正法。这是美国道·琼斯在1928年创造的一种计算股价平均数的方法。该法的核心是求出一个常数除数,以修正因股票分割、增资、发放红股等因素造成股价平均数的变化,以保持股份平均数的连续性和可比性。具体作法是以新股价总额除以旧股价平均数,求出新的除数,再以计算期的股价总额除以新除数,这就得出修正的股价平均数。即:
新除数=变动后的新股价总额/旧的股价平均数
修正的股价平均数=报告期股价总额/新除数在前面的例子除数是4,经调整后的新的除数应是:
新的除数=(10+16+24+10)/20=3,将新的除数代入下列式中,则:
修正的股价平均数=(10+16+24+10)/3=20(元)得出的平均数与未分割时计算的一样,股价水平也不会因股票分割而变动。
- 股价修正法。股价修正法就是将股票分割等,变动后的股价还原为变动前的股价,使股价平均数不会因此变动。美国《纽约时报》编制的500种股价平均数就采用股价修正法来计算股价平均数
3). 加权股价平均数
加权股价平均数是根据各种样本股票的相对重要性进行加权平均计算的股价平均数,其权数(Q) 可以是成交股数、股票总市值、股票发行量等。
股票指数
1). 道·琼斯股票指数
道·琼斯股票指数是世界上历史最为悠久的股票指数,它的全称为股票价格平均数。它是在1884年由道·琼斯公司的创始人查理斯·道开始编制的。其最初的道·琼斯股票价格平均指数是根据11种具有代表性的铁路公司的股票,采用算术平均法进行计算编制而成,发表在查理斯·道自己编辑出版的《每日通讯》上。
其计算公式为:
股票价格平均数=入选股票的价格之和/入选股票的数量。
自1897年起,道·琼斯股票价格平均指数开始分成工业与运输业两大类,其中工业股票价格平均指数包括12种股票,运输业平均指数则包括20种股票,并且开始在道·琼斯公司出版的《华尔街日报》上公布。在1929年,道·琼斯股票价格平均指数又增加了公用事业类股票,使其所包含的股票达到65种,并一直延续至今。
道·琼斯股票价格平均指数是以1928年10月1日为基期,因为这一天收盘时的道·琼斯股票价格平均数恰好约为100美元,所以就将其定为基准日。而以后股票价格同基期相比计算出的百分数,就成为各期的投票价格指数,所以股票指数普遍用点来做单位,而股票指数每一点的涨跌就是相对于基准日的涨跌百分数。
2). 标准·普尔股票价格指数
除了道·琼斯股票价格指数外,标准·普尔股票价格指数在美国也很有影响,它是美国最大的证券研究机构即标准·普尔公司编制的股票价格指数。该公司于1923年开始编制发表股票价格指数。最初采选了230种股票,编制两种股票价格指数。到1957年,这一股票价格指数的范围扩大到500种股票,分成95种组合。其中最重要的四种组合是工业股票组、铁路股票组、公用事业股票组和500种股票混合组。从1976年7月1日开始,改为 400种工业股票,20种运输业股票,40种公用事业股票和40种金融业股票。几十年来,虽然有股票更迭,但始终保持为500种。标准·普尔公司股票价格指数以1941年至1943年抽样股票的平均市价为基期,以上市股票数为权数,按基期进行加权计算,其基点数为10。以股票市场价格乘以股票市场上发行的股票数量为分子,用基期的股票市场价格乘以基期股票数为分母,相除之数再乘以10就是股票价格指数。
3). 纽约证券交易所股票价格指数
纽约证券交易所股票价格指数。这是由纽约证券交易所编制的股票价格指数。它起自1966年6月,先是普通股股票价格指数,后来改为混合指数,包括着在纽约证券交易所上市的1500家公司的1570种股票。具体计算方法是将这些股票按价格高低分开排列,分别计算工业股票、金融业股票、公用事业股票、运输业股票的价格指数,最大和最广泛的是工业股票价格指数,由1093种股票组成;金融业股票价格指数包括投资公司、储蓄贷款协会、分期付款融资公司、商业银行、保险公司和不动产公司的223种股票;运输业股票价格指数包括铁路、航空、轮船、汽车等公司的65种股票;公用事业股票价格指数则有电话电报公司、煤气公司、电力公司和邮电公司的189种股票。
纽约股票价格指数是以1965年12月31日确定的50点为基数,采用的是综合指数形式。纽约证券交易所每半个小时公布一次指数的变动情况。虽然纽约证券交易所编制股票价格指数的时间不长,因它可以全面及时地反映其股票市场活动的综合状况,较为受投资者欢迎。
4). 日经道·琼斯股价指数(日经平均股价)
系由日本经济新闻社编制并公布的反映日本股票市场价格变动的股票价格平均数。该指数从1950年9月开始编制。
日经道·琼斯股价指数指数分为:
- 日经225股指指数(日经225)。因此种指数延续时间较长,具有很好的可比性,成为考察日本股票市场股价长期演变及最新变动最常用和最可靠的指标,传媒日常引用的日经指数就是指这个指数。
- 日经300股指指数(日经300)此指数是以发行量加重平均方式来计算
- 日经综合股指指数(日经综合)此指数是以发行量加重平均方式来计算
- 日经店头平均股票价格指数。
5). 香港恒生指数
香港恒生指数是香港股票市场上历史最久、影响最大的股票价格指数,由香港恒生银行于1969年11月24日开始发表。
这些股票占香港股票市值的63.8%,因该股票指数涉及到香港的各个行业,具有较强的代表性。
恒生股票价格指数的编制是以1964年7月31日为基期,因为这一天香港股市运行正常,成交值均匀,可反映整个香港股市的基本情况,基点确定为100点。其计算方法是将33种股票按每天的收盘价乘以各自的发行股数为计算日的市值,再与基期的市值相比较,乘以100就得出当天的股票价格指数。
由于恒生股票价格指数所选择的基期适当,因此,不论股票市场狂升或猛跌,还是处于正常交易水平,恒生股票价格指数基本上能反映整个股市的活动情况。
6). 我国内地的股票指数
上证股票指数系由上海证券交易所编制的股票指数,1990年12月19日正式开始发布。该股票指数的样本为所有在上海证券交易所挂牌上市的股票,其中新上市的股票在挂牌的第二天纳入股票指数的计算范围。
该股票指数的权数为上市公司的总股本。由于我国上市公司的股票有流通股和非流通股之分,其流通量与总股本并不一致,所以总股本较大的股票对股票指数的影响就较大,上证指数常常就成为机构大户造市的工具,使股票指数的走势与大部分股票的涨跌相背离。
深圳综合股票指数系由深圳证券交易所编制的股票指数,1991年4月3日为基期。该股票指数的计算方法基本与上证指数相同,其样本为所有在深圳证券交易所挂牌上市的股票,权数为股票的总股本。由于以所有挂牌的上市公司为样本,其代表性非常广泛,且它与深圳股市的行情同步发布,它是股民和证券从业人员研判深圳股市股票价格变化趋势必不可少的参考依据。在前些年,由于深圳证交所的股票交投不如上海证交所那么活跃,深圳证券交易所现已改变了股票指数的编制方法,采用成分股指数,其中只有40只股票入选并于1995年5月开始发布。
文字介绍,摘自:http://baike.baidu.com/view/897308.htm
2. 中国证券市场的股指
- 上证180指数
- 上证综指
- 上证A股
- 上证B股
- 上证ADL指标
- 上证多空指标
- 上证50指数
- 上证基金指数
- 上证红利指数
- 深证100指数
- 深证成份
- 深证综指
- 深证A股
- 深证B股
- 深证ADL指标
- 深证多空指标
- 创业板指数
- 中小企业指数
- 沪深300指数
上证180指数
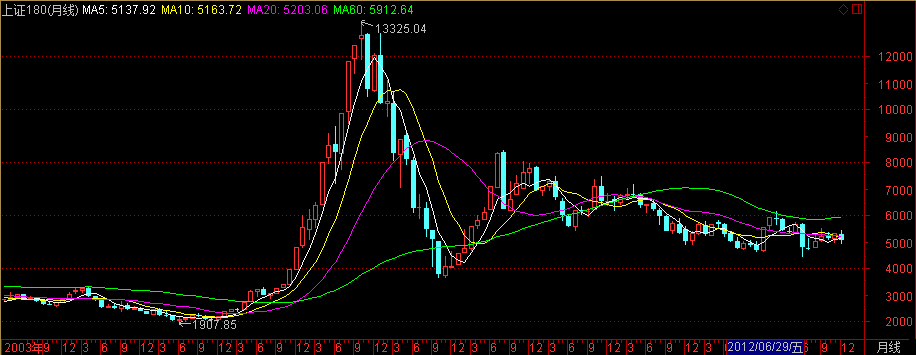
- 指数代码:000010
- 指数名称:上证成份指数(简称上证180指数)
- 指数类别:股票类
- 创建人 :上海证券交易所
- 指数基期:2002-06-28
- 指数基点:3299.0600
- 计算价格:收盘价
- 加权方式:派许加权方法
- 指数简介:上证成份指数(简称上证180指数)是上海证券交易所对原上证30指数进行了调整并更名而成的,其样本股是在所有A股股票中抽取最具市场代表性的180种样本股票,自2002年7月1日起正式发布.作为上证指数系列核心的上证180指数的编制方案,目的在于建立一个反映上海证券市场的概貌和运行状况,具有可操作性和投资性,能够作为投资评价尺度及金融衍生产品基础的基准指数.
- 成份股的选择:在确定样本空间的基础上,上证180指数根据以下四个步骤进行选样. 据总市值,流通市值,成交金额和换手率对股票进行综合排名.具体方法是:第i行业样本配额=第i行业所有候选股票流通市值之和/上海市场所以候选股票流通市值之和*180
- 指数计算:报告期指数=报告期成份股的调整市值/基日成份股的调整市值*1000
上证综指
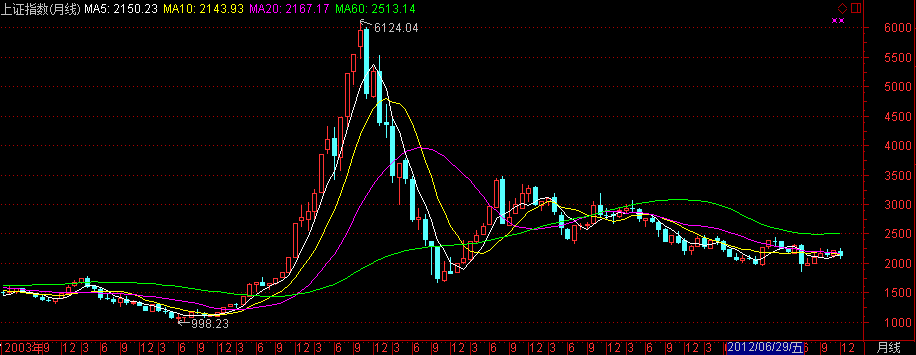
上证综指即“上证综合指数”-(上海证券综合指数),英文是:Shanghai(securities)composite index. 通常简称:“Shanghai composite index”(上证综指) 。“上海证券综合指数”它是上海证券交易所编制的,以上海证券交易所挂牌上市的全部股票为计算范围,以发行量为权数综合。上证综指反映了上海证券交易市场的总体走势。指数代码:999999。
上证综合指数是最早发布的指数,是以上证所挂牌上市的全部股票为计算范围,以发行量为权数的加权综合股价指数。这一指数自1991年7月15日起开始实时发布,基日定为1990年12月19日,基日指数定为100点。
新上证综指发布以2005年12月30日为基日,以当日所有样本股票的市价总值为基期,基点为1000点。新上证综指简称“新综指”,指数代码为000017。
文字介绍,摘自:http://baike.baidu.com/view/1283709.htm
上证A股
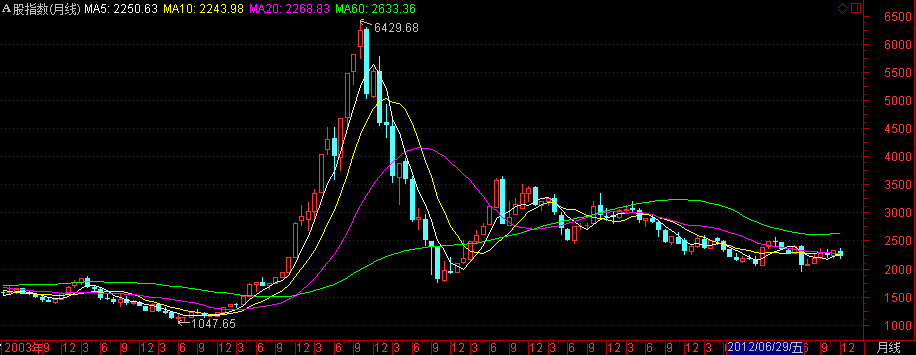
- 指数代码:000002
- 指数名称:上证A股指数
- 指数类别:股票类
- 创建人 :上海证券交易所
- 指数基期:1990-12-19
- 指数基点:100
- 计算价格:收盘价
- 加权方式:派许加权方法
- 指数简介:上证A股指数的样本股是全部上市A股,反映了A股的股价整体变动状况,自1992年2月21日起正式发布.
- 成份股的选择:上证A股指数的样本股是全部上市A股股票
- 指数计算:报告期指数=报告期成份股的总市值 / 基期 * 基期指数
上证B股
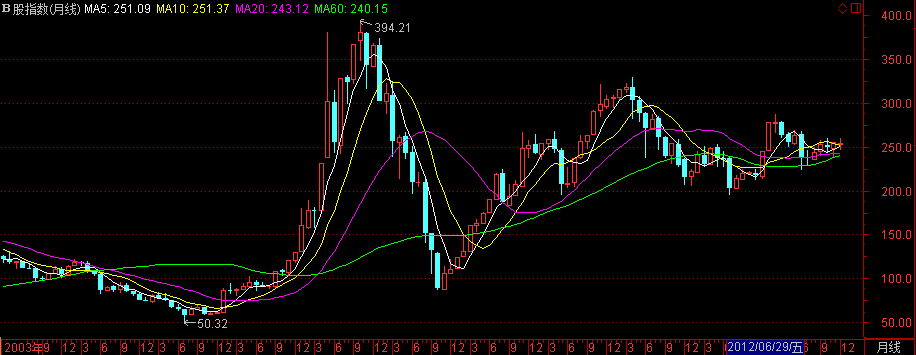
- 指数代码:000003
- 指数名称:上证B股指数
- 指数类别:股票类
- 创建人 :上海证券交易所
- 指数基期:1990-12-19
- 指数基点:100
- 计算价格:收盘价
- 加权方式:派许加权方法
- 指数简介:上证B股指数的样本股是全部上市B股,反映了B股的股价整体变动状况,自1992年2月21日起正式发布.
- 成份股的选择:上证B股指数的样本股是全部上市B股
- 指数计算:报告期指数 =报告期成份股的总市值 / 基 期 * 基期指数
上证ADL指标
2013年12月31日截图
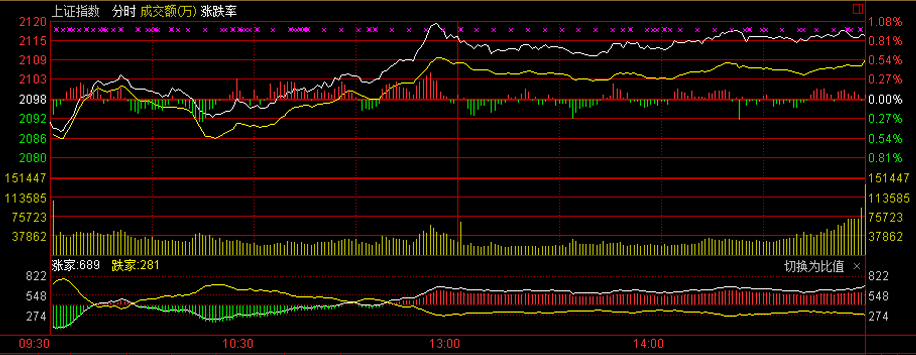
上证ADL指标是指上海证券交易所的股票腾落指数。ADL(Advance Decline Line)中文名称为腾落指数,其实就是上升下降曲线的意思。ADL是分析趋势的。以股票市场为例,ADL利用简单的加减法,计算每天股票上涨公司数量和下降公司数量的累计结果,与综合指数相对比,对大势的未来进行预测。
ADL的计算公式为:
今日ADL=昨日ADL+Na-Nd
推出:今日ADL=∑Na-∑Nd。
- ∑Na—从开始交易的第一天算起,每一个交易日的上涨家数的总和。
- ∑Nd—从开始交易的第一天算起,每一个交易日的下跌家数的总和。
腾落指数与股价指数比较类似,两者均为反映大势的动向与趋势,不对个股的涨跌提供讯号,但由于股价指数在一定情况下受制于权值大的股只,当这些股只发生暴涨与暴跌时,股价指数有可能反应过度,从而给投资者提供不实的信息,腾落指数则可以弥补这一类一缺点。由于腾落指数与股价指数的关系比较密切,观图时应将两者联系起来。一般情况下,股价指数上和或,腾落指数亦上升,或两者皆跌,则可以对升势或跌势进行确认。如若股价指数大动而腾落指数横行,或两者反方面波动,不可互相印证,说明大势不稳,不可贸然入市。
具体来说有以下六种情况:
- 股价指数持续上涨,腾落指数亦上升,股价可能仍将继续上升。
- 股价指数持续下跌,腾落指数亦下降,股价可能仍将继续下跌。
- 股价指数上涨,而腾落指数下降,股价可能回跌。
- 股价指数下跌,而腾落指数上升,股价可能回升。
- 股市处于多头市场时,腾落指数呈上升趋势,其间如果突然出现急速下跌现象,接着又立即扭头向上,创下新高点,则表示引情可能再创新高。
- 股市处于空头市场时,ADL呈现下降趋势,其间如果突然出现上升现象,接着又回头,下跌突破原先所创低点,则表示另一段新的下跌趋势产生
文字介绍,摘自:http://baike.baidu.com/view/8321995.htm
上证多空指标
2013年12月31日截图
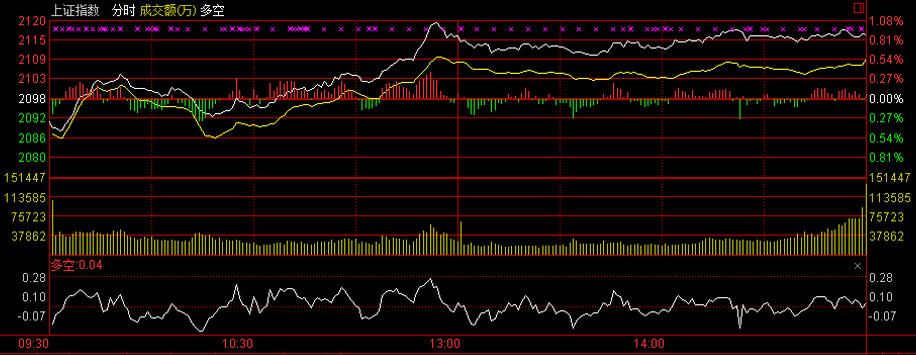
多空指标英文全名为“BullAndBearIndex”,简称BBI,是一种将不同日数移动平均线加权平均之后的综合指标,属于均线型指标。
在使用移动平均线时,投资者往往对参数值选择有不同的偏好,而多空指标恰好解决了中短期移动平均线的期间长短合理性问题
在钱龙分析系统中,多空指标的原始参数值是3、6、12、24,将3日、6日、12日、24日四个平均股价(或指数)相加后除以4得出多空指标的数值,
计算公式:
BBI=(3日MA+6日MA+12日MA+24日MA)/4
文字介绍,摘自:http://baike.baidu.com/view/658748.htm
上证50指数
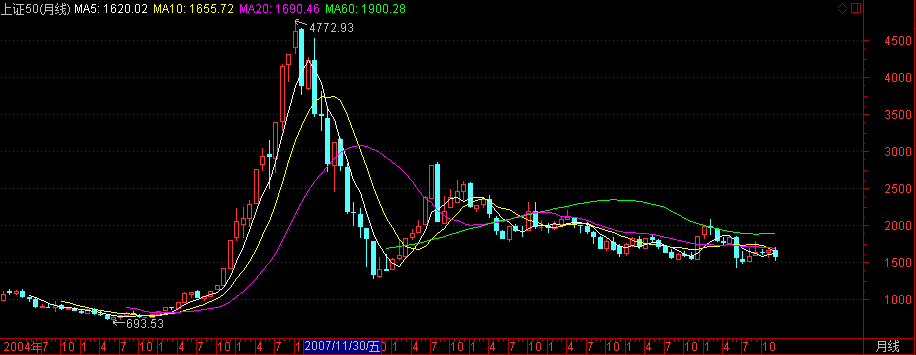
- 指数代码:000016
- 指数名称:上证50指数
- 指数类别:股票类
- 创建人 :上海证券交易所
- 指数基期:2003-12-31
- 指数基点:1000
- 计算价格:收盘价
- 加权方式:派许加权方法
- 指数简介:上证50指数是根据科学客观的方法,挑选上海证券市场规模大,流动性好的最具代表性的50只股票组成样本股,以便综合反映上海证券市场最具市场影响力的一批龙头企业的整体状况.
- 成份股的选择:根据流通市值,成交金额对股票进行综合排名,原则上挑选排名前50位的股票组成样本,但市场表现异常并经专家委员会认定不宜作为样本的股票除外
- 指数计算:报告期指数 =报告期成份股的调整市值 / 基 期 * 基期指数
上证基金指数
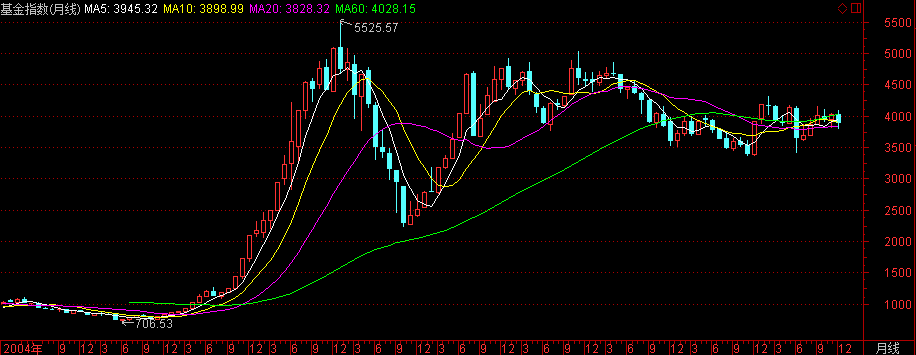
- 指数代码:000011
- 指数名称:上证基金指数
- 指数类别:基金类
- 创建人 :上海证券交易所
- 指数基期:2000-05-08
- 指数基点:1000
- 计算价格:收盘价
- 加权方式:派许加权方法
- 指数简介:基金指数的成份股是所有在上海证券交易所上市的证券投资基金,反映了基金的价格整体变动状况.
- 指数计算:报告期指数 = 报告期基金的总市值 / 基 期 * 基期指数
上证红利指数
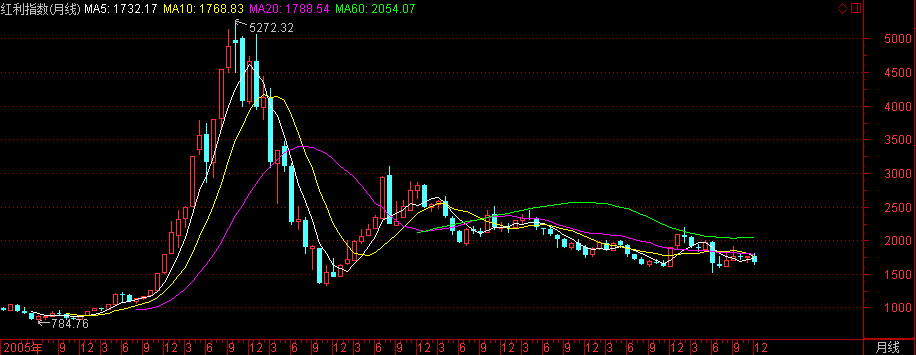
- 指数代码:000015
- 指数名称:上证红利指数
- 指数类别:股票类
- 创建人 :上海证券交易所
- 指数基期:2004-12-31
- 指数基点:1000
- 计算价格:收盘价
- 加权方式:派许加权方法
- 指数简介:上证红利指数挑选在上证所上市的现金股息率高,分红比较稳定,具有一定规模及流动性的50只股票作为样本,以反映上海证券市场高红利股票的整体状况和走势.
- 成份股的选择:对样本空间的股票,按照过去两年的平均现金股息率(税后)进行排名,挑选排名最前的50只股票组成样本股,但市场表现异常并经专家委员会认定不宜作为样本的股票除外
- 指数计算:报告期指数 =报告期成份股的调整市值 / 基 期 * 基期指数
深证100指数
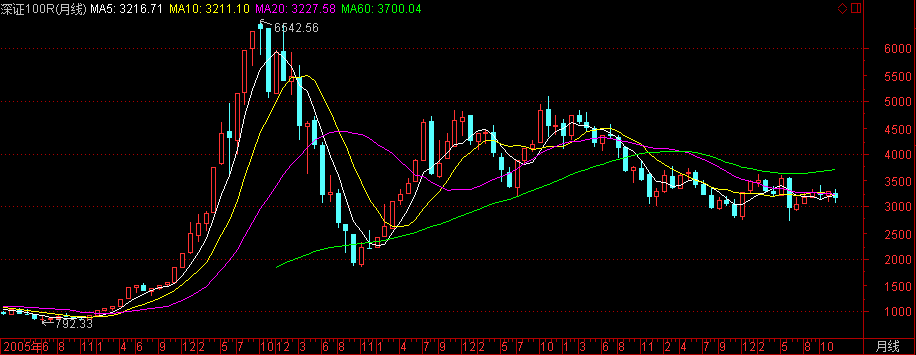
- 指数代码:399004
- 指数名称:深证100全收益指数
- 指数类别:股票类
- 创建人 :深圳证券信息公司
- 指数基期:2002-12-31
- 指数基点:1000
- 计算价格:收盘价
- 指数简介:深证100指数由深圳市场选取100只A股作为样本编制而成,为深市多层次市场指数体系的核心指数之一,包括全收益指数(深证100R)和价格指数(深证100P).
- 成份股的选择:计算入围个股在考察期(6 个月)的平均流通市值及平均成交金额所占市场比重,将上述指标按2:1 权重加权计算,再将结果从高到低排序,选取排名前100 名股票构成指数成份股
深证成份指数
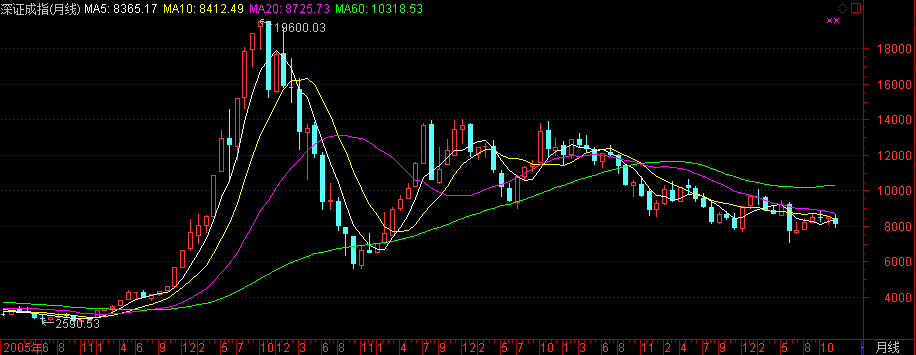
深证成份股指数,是深圳证券交易所编制的一种成份股指数,是从上市的所有股票中抽取具有市场代表性的40家上市公司的股票作为计算对象,并以流通股为权数计算得出的加权股价指数,综合反映深交所上市A、B股的股价走势。
深圳成份股指数(399001)的内容与发布编码。深圳交易所从于1995年1月23日正式发布,1995年5月5日正式启用。以新证券挂牌方式从行情中实时发布成份股指数,成份股指数(不含分类指数)发布名称、编码见下表:
文字介绍,摘自:http://baike.baidu.com/view/658748.htm
深证综指
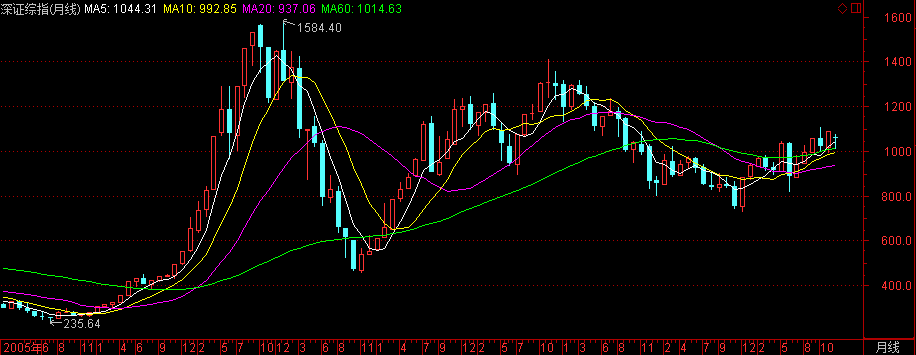
深证综合指数是深圳证券交易所编制的,以深圳证券交易所挂牌上市的全部股票为计算范围,以发行量为权数的加权综合股价指数。
深证综合指数是深圳证券交易所从1991年4月3日开始编制并公开发表的一种股价指数,该指数规定1991年4月3日为基期,基期指数为100点。综合指数以所有在深圳证交所上市的所有股票为计算范围,以发行量为权数的加权综合股价指数,其基本计算公式为:即日综合指数=(即日指数股总市值/基日指数股总市值×基日指数),每当发行新股上市时,从第二天纳入成份股计算,这时上式中的分母下式调整。
新股上市后,计算公式:
基日指数总市值=原来的基日指数股总市值+新股发行数量×上市第十个交易日收盘价
文字介绍,摘自:http://baike.baidu.com/view/21880.htm
深证A股
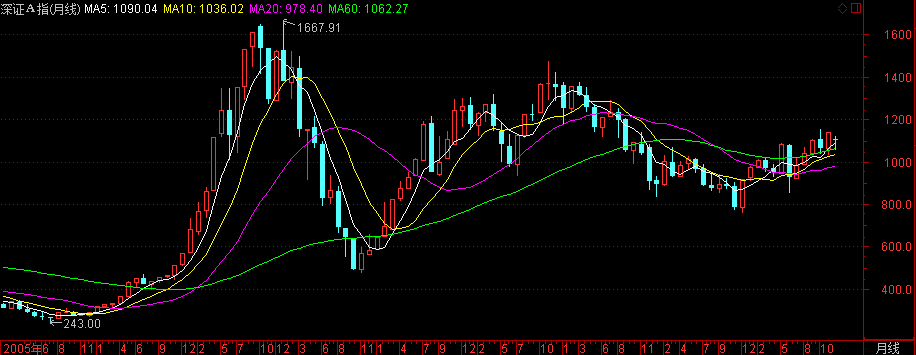
- 指数代码:399107
- 指数名称:深证A股指数
- 指数类别:股票类
- 创建人 :深圳证券信息公司
- 指数基期:1991-04-03
- 指数基点:100
- 成份股的选择:在深圳证券交易所主板、中小板、创业板上市的全部A股/li>
- 指数计算:实时指数=上一交易日收市指数×[Σ(样本股实时成交价×样本股总股本)] / [Σ(样本股上一交易日收市价×样本股总股本)]
深证B股
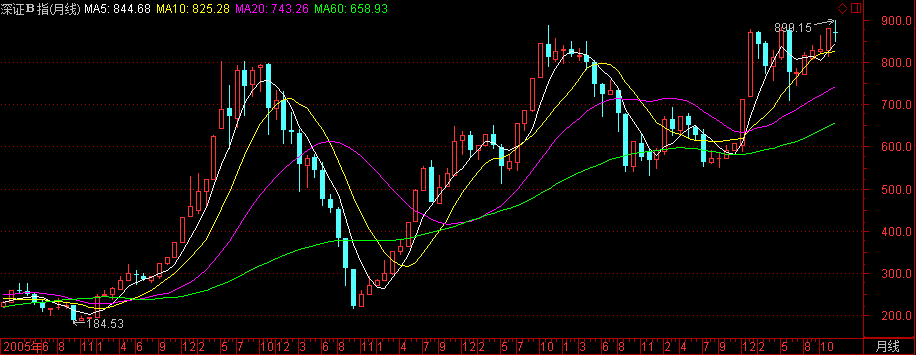
- 指数代码:399108
- 指数名称:深证B股指数
- 指数类别:股票类
- 创建人 :深圳证券信息公司
- 指数基期:1992-02-28
- 指数基点:100
- 成份股的选择:在深圳证券交易所上市的全部B股/li>
- 指数计算:实时指数=上一交易日收市指数×[Σ(样本股实时成交价×样本股总股本)] / [Σ(样本股上一交易日收市价×样本股总股本)]
深证ADL指标
2013年12月31日截图
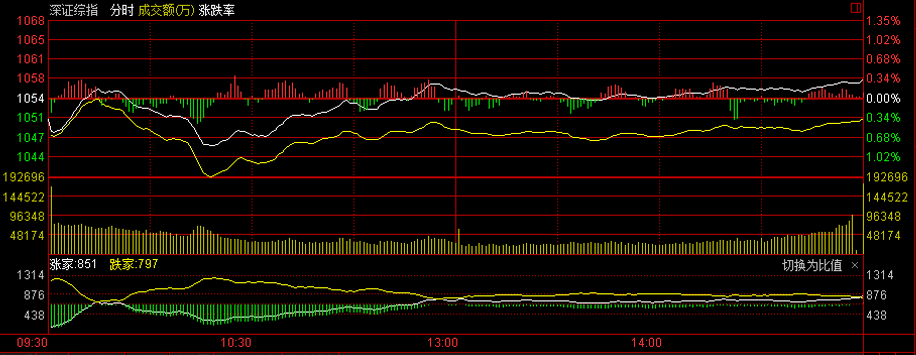
同上证ADL指标。
深证多空指标
2013年12月31日截图
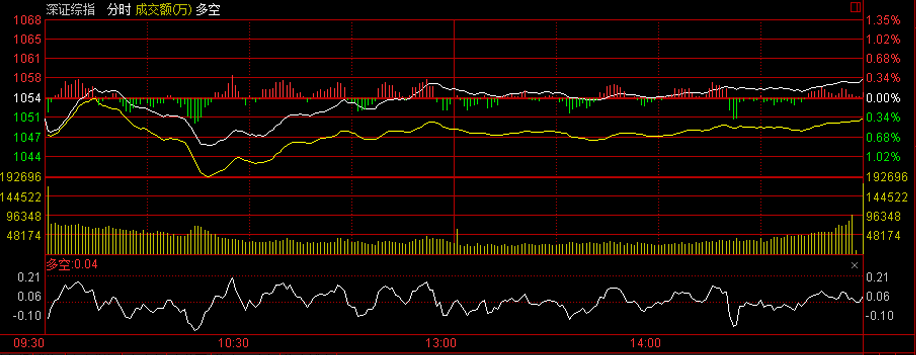
同上证多空指标。
创业板指数
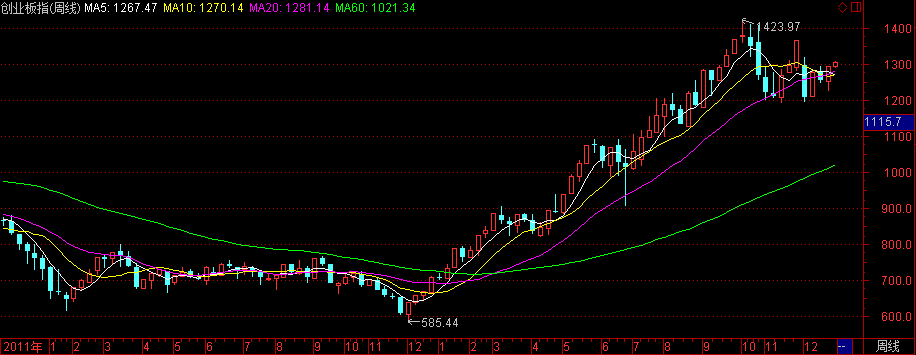
- 指数代码:399006
- 指数名称:创业板价格指数
- 指数类别:股票类
- 创建人 :深圳证券信息公司
- 指数基期:2010-05-31
- 指数基点:1000
- 指数简介:为了更全面地反映创业板市场情况,向市场各类投资者提供更多的跟踪投资目标指数,推进指数基金产品以及丰富证券市场产品品种,为了方便投资者参考,本次同步发布收益指数及价格指数,其中价格指数对样本股公司派息不作除权调整处理,任指数自然回落
- 成份股的选择:创业板指数的初始成份股为指数发布之日已纳入深证综合指数计算的全部创业板股票。在指数样本未满100只之前,新上市创业板股票在上市后第十一个交易日纳入指数计算;在指数样本数量满100只之后,样本数量锁定为100只,并依照定期调样规则实施样本股定期调样。
- 指数计算: 创业板指数以2010年5月31日为基日,基点为1000点。创业板指数的计算方法与深证系列其它指数相同,采用自由流通量加权,并按照派氏加权法进行计算。创业板指数调整计算方法与深证100指数等深证系列指数相同
中小企业指数
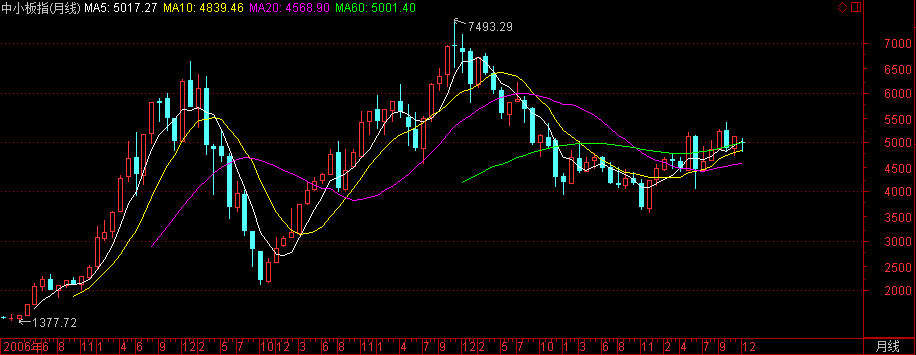
- 指数代码:399005
- 指数名称:中小板价格指数
- 指数类别:股票类
- 创建人 :深圳证券信息公司
- 指数基期:2005-06-07
- 指数基点:1000
- 指数简介:中小板指数是中国多层次证券市场的重要指数,由100家具有代表性的中小板公司组成.中小板指数包括价格指数(中小板指数P)和全收益指数(中小板指数R),价格指数于200
- 成份股的选择:计算入围个股在考察期的平均流通市值及平均成交金额所占市场比重,将上述指标按2:1 权重加权计算,再将结果从高到低排序,选取排名前100 名股票构成指数成份股.
沪深300指数
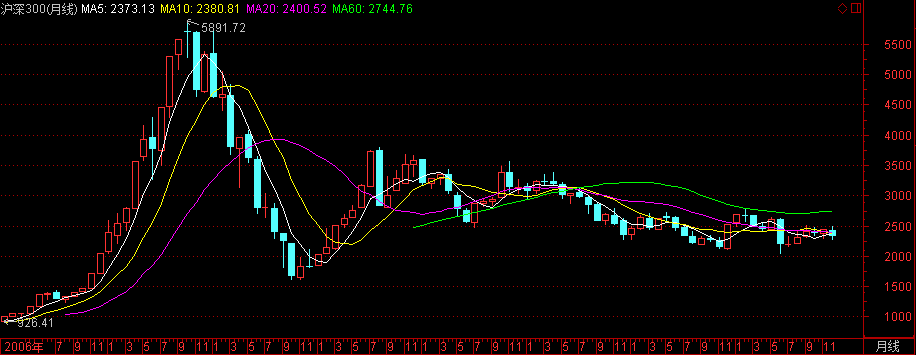
- 指数代码:399300
- 指数名称:沪深300指数
- 指数类别:股票类
- 创建人 :深圳证券信息公司
- 指数基期:2004-12-31
- 指数基点:1000
- 指数简介:沪深300指数是由上海和深圳证券市场中选取300只A股作为样本编制而成的成份股指数. 沪深300指数样本覆盖了沪深市场六成左右的市值,具有良好的市场代表性.
- 成份股的选择:对样本空间股票在最近一年(新股为上市以来)的日均成交金额由高到低排名,剔除排名后50%的股票,然后对剩余股票按照日均总市值由高到低进行排名,选取排名在前300名的股票作为样本股
3. 沪深300指数
沪深300指数是沪深证券交易所于2005年4月8日联合发布的反映A股市场整体走势的指数。沪深300指数编制目标是反映中国证券市场股票价格变动的概貌和运行状况,并能够作为投资业绩的评价标准,为指数化投资和指数衍生产品创新提供基础条件。
- 沪市000300
- 深市399300
沪深300指数是由上海和深圳证券市场中选取300只A股作为样本,其中沪市有179只,深市121只。
样本选择标准为规模大、流动性好的股票。
沪深300指数样本覆盖了沪深市场六成左右的市值,具有良好的市场代表性。
主要特点:
- 严格的样本选择标准,定位于交易性成份指数
- 采用自由流通量为权数
- 采用分级靠档法确定成份股权重
- 样本股稳定性高,调整设置缓冲区
- 指数行业分布状况基本与市场行业分布比例一致
主要优势:
- 沪深300成分股的盈利能力突出
- 沪深300成分股具备较好的成长性
- 沪深300成分股的分红与股息收益高于市场平均水平
- 沪深300成分股估值水平低于市场平均水平
- 沪深300成分股代表了机构投资取向
从基本面来看,沪深300指数成分股在两年的运行中体现了较好的盈利性、成长性和分红收益能力,同时,相对于市场平均水平,其估值优势也较为明显,已经逐渐成为机构投资者乃至整个市场的投资取向标杆。那么,就股指期货而言,沪深300指数有利于得到更多机构的关注,从而更有益于形成以机构投资者为主的投资者结构。
沪深300指数发布,除了要真实反映A股市场状况,为市场提供一个投资标尺外,还有一个重要目的是为了股指期货提供一个标的。有业内人士就表示,推出沪深300指数,并在沪深300指数推出运行一段时间后,如果运行状况良好,就可以推出以该指数为标的的股指期货。
文字介绍,摘自:http://baike.baidu.com/view/539529.htm
4. 沪深300指数统计分析
数据来源于:招商证券智远理财服务平台 客户端
数据采集日期:2014-01-01
个股对指数贡献度:
股票代码,股票名称,贡献点数,涨幅(%),昨日收盘,参与计算股本(W),权重,名次
601398,工商银行,1.39,0.85,3.550,26377716.00,7.18,1
600036,招商银行,1.05,2.74,10.600,2062894.38,1.68,2
601288,农业银行,1.04,0.81,2.460,29405530.00,5.55,3
601166,兴业银行,0.87,2.63,9.880,1905233.63,1.44,4
600028,中国石化,0.80,1.13,4.430,9105184.00,3.09,5
601318,中国平安,0.78,2.25,40.810,478640.94,1.50,6
600000,浦发银行,0.76,2.50,9.200,1865347.13,1.32,7
600519,贵州茅台,0.72,3.15,124.460,103818.00,0.99,8
600030,中信证券,0.71,3.32,12.340,983858.13,0.93,9
002304,洋河股份,0.71,10.00,37.110,108000.00,0.31,10
600016,民生银行,0.60,1.98,7.570,2258819.25,1.31,11
601628,中国人寿,0.55,1.00,14.980,2082353.00,2.39,12
600010,包钢股份,0.55,9.95,3.920,800259.13,0.24,13
000001,平安银行,0.52,4.34,11.740,573815.25,0.52,14
601998,中信银行,0.51,2.38,3.780,3190516.25,0.92,15
000858,五 粮 液,0.50,5.03,14.910,379596.69,0.43,16
601006,大秦铁路,0.37,1.93,7.250,1486679.13,0.83,17
600383,金地集团,0.35,7.22,6.230,447150.84,0.21,18
....
用R语言读入数据
library(ggplot2)
library(scale)
contrib<-read.table(file="contribution.csv",header=FALSE,sep=",",colClasses = "character",fileEncoding="utf-8", encoding = "utf-8")
names(contrib)<-c("股票代码","股票名称","贡献点数","涨幅","昨日收盘","参与计算股本(W)","权重","名次");
1). 选出权重>1的股票
contrib[which(as.numeric(contrib[,7])>1),]
股票代码 股票名称 贡献点数 涨幅 昨日收盘 参与计算股本(W) 权重 名次
1 601398 工商银行 1.39 0.85 3.550 26377716.00 7.18 1
2 600036 招商银行 1.05 2.74 10.600 2062894.38 1.68 2
3 601288 农业银行 1.04 0.81 2.460 29405530.00 5.55 3
4 601166 兴业银行 0.87 2.63 9.880 1905233.63 1.44 4
5 600028 中国石化 0.80 1.13 4.430 9105184.00 3.09 5
6 601318 中国平安 0.78 2.25 40.810 478640.94 1.50 6
7 600000 浦发银行 0.76 2.50 9.200 1865347.13 1.32 7
11 600016 民生银行 0.60 1.98 7.570 2258819.25 1.31 11
12 601628 中国人寿 0.55 1.00 14.980 2082353.00 2.39 12
19 601988 中国银行 0.34 0.38 2.610 19552620.00 3.91 19
24 600104 上汽集团 0.29 1.07 13.990 1102556.63 1.18 24
26 601857 中国石油 0.29 0.13 7.700 16192208.00 9.56 26
28 601328 交通银行 0.28 1.05 3.800 3925086.25 1.14 28
63 601088 中国神华 0.09 0.19 15.790 1649103.75 2.00 63
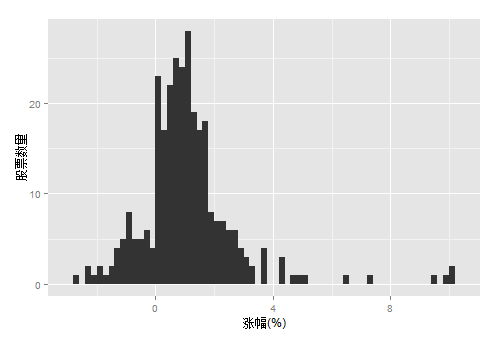
2). 画出“涨幅”的分布图
g<-ggplot(contrib, aes(x=as.numeric(contrib$涨幅)))
g<-g+geom_histogram(binwidth=0.2,position="identity")
g<-g+xlab("涨幅(%)")+ylab("股票数量")
g
3). 画出“权重”的分布图
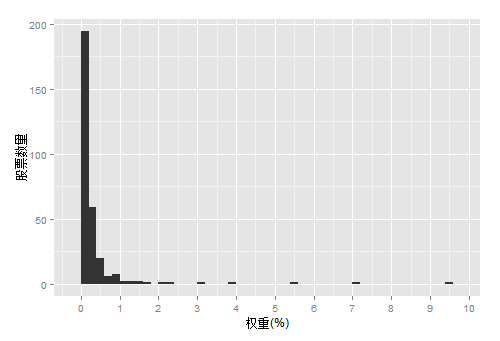
g<-ggplot(contrib, aes(x=as.numeric(contrib$权重)))
g<-g+geom_histogram(binwidth=0.2,position="identity")
g<-g+scale_x_continuous(breaks=-5:10)
g<-g+xlab("权重(%)")+ylab("股票数量")
g
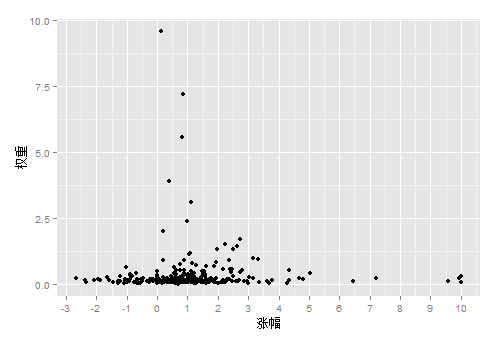
4). 画出“涨幅和权重”的关系
g<-ggplot(contrib, aes(x=as.numeric(contrib$涨幅),y=as.numeric(contrib$权重)))
g<-g+geom_point()
g<-g+scale_x_continuous(breaks=-5:10)
g<-g+xlab("涨幅")+ylab("权重")
g
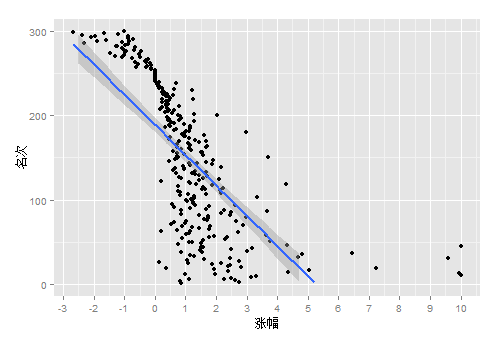
5). 画出“涨幅和名次”的关系,并做线性回归
g<-ggplot(contrib, aes(x=as.numeric(contrib$涨幅),y=as.numeric(contrib$名次)))
g<-g+geom_point()+geom_smooth(method = lm, size = 1)
g<-g+scale_x_continuous(breaks=-5:10)+ylim(0,300)
g<-g+xlab("涨幅")+ylab("名次")
g
转载请注明出处:
http://blog.fens.me/finance-index/
