R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-version-3-1/

前言
R语言在不断的发展和进步,从R语言3.0.0版本开始,R语言开始了具有里程碑似的的发展。R内核在不断更新,越多越多的纯计算机技术指标在增加,向着企业级商用语言在靠近,R一定会大红大紫的走完2014年的,并且持续壮大和发展。
本文将介绍R的最新版本3.1.x的新特性及使用。
目录
- R 3.1版本
- R 3.1.0新特性及代码描述
- R 3.1.1新特性及代码描述
1. R 3.1版本
R语言3.1.0版本于2014年4月10日发布,有64项新特性发布,修复了16个bug,是一次很大规则的升级。目前的最新版本的R语言3.1.1版本发布于2014年7月10日,有17项新特性的发布,并解决了35个bug。
一般软件产品版本发布,都用3个维度来衡量 X.Y.Z,如R语言的3.1.1版本。
- X代表最大的版本号,表示有重大的更新或者里程碑的功能点发布,大版本号新产品发布建议大家升级,使用最新的软件,比如Java5, Java6, Java7, Java8 每次升级都对Java性能及特性有重大的提升及改进。当然,大版本的升级,也可能会向前不兼容,以致于很多原来开发的应用都不能运行了,如Python 2.7.x 和 Python 3.x就是语法不兼容的,现在只能两套版本并行。
- Y代表中版本号,主要表现在功能上,每一次Y的版本升级,都会对当前版本补充很多小功能,这些小功能一般是不太会引起大家的注意,也不会影响使用,可以想起来再升级,差1-2个Y的版本没什么关系。
- Z代表小版本号,主要表现在解决bug上,每个X和Y版本的升级都可能会引起bug,这些bug需要及时修复,所以Z的版本会经常性的发布,有时候是1-2个月也可能3-5天。我们可以把Z的版本号,理解为给系统打补丁,只有你遇到这个bug才需要打补丁,如果没有遇到bug,对于Z的版本,我们可以不升级,等下个Y版本发布再统一升级。
R语言的快速更新,其实代表了市场迫切的声音。如果R语言能支持并发,如果R语言能支持异步,如果R语言能构建独立的应用服务器,如果R语言能并方便的处理socket、http协议,如果R语言能处理大数等…,已经有无数的功能需求被提交到了R的核心团队。我也希望R的技术小组能早日攻克这些技术难题,让R在企业级的应用中大放异彩。
从R语言版本平均每4个月一次新发布,就能看出大家都在努力着。我们可通过官方的软件镜像下载到R语言最新版本软件包http://cran.rstudio.com/,并查看版本更新的详细描述。
下面我就全面解释一下R语言3.1.0和3.1.1两个版本的新特性,并做代码的描述。
2. R 3.1.0新特性及代码描述
R语言3.1.0版本的别名是Spring Dance,下载R3.1.0版本后,你可以通过version来查看版本信息。
~ R # 启动R程序
> version # 查看版本信息
platform x86_64-w64-mingw32
arch x86_64
os mingw32
system x86_64, mingw32
status
major 3
minor 1.0
year 2014
month 04
day 10
svn rev 65387
language R
version.string R version 3.1.0 (2014-04-10)
nickname Spring Dance
新特性
1. type.convert()函数主要用在read.table()函数中,返回向量和因子类型,当输入为double型时会丢失精度。
> type.convert(c('abc','bcd')) # 返回因子类型
[1] abc bcd
Levels: abc bcd
> type.convert(c(as.double(1.12121221111),'1.121')) # double型丢失精度
[1] 1.121212 1.121000
2. 如果一个文件包含有小数位的数据,通过read.table()函数读取时,会指定为numeric类型。
新建一个文件num.csv包括小数
1,2,1.11
2.1,3,4.5
用read.table读取文件,并查看列的类型。
> num<-read.table(file="num.csv",sep=",") # 读文件
> num
V1 V2 V3
1 1.0 2 1.11
2 2.1 3 4.50
> class(num)
[1] "data.frame"
> class(num$V1) # 查看列的类型为numeric
[1] "numeric"
3. tools包用Rdiff()函数的参数useDiff为FALSE时,与POSIX系统的diff -b命令类似。
新建文件num2.csv
3,2,1.11
2.1,3,4.5
用Rdiff()比较两个文件num.csv和num2.csv。
> Rdiff('num.csv','num2.csv',useDiff = FALSE)
1c1
< 1,2,1.11
---
> 3,2,1.11
[1] 1
4. 新函数anyNA(),结果与 any(is.na(.))一致,性能更好。
> is.na(c(1, NA))
[1] FALSE TRUE
> any(is.na(c(1, NA)))
[1] TRUE
> anyNA(c(1, NA))
[1] TRUE
5. arrayInd()和which()函数增加useNames参数,用于列名的匹配。我在测试过程,不太理解这个参数的意义。
> which
function (x, arr.ind = FALSE, useNames = TRUE)
6. is.unsorted()函数支持处理原始数据的向量。
> is.unsorted(1:10) # 排序的向量
[1] FALSE
> is.unsorted(sample(1:10)) # 无序的向量
[1] TRUE
7. 用于处理table的as.data.frame()函数和as.data.frame.table()函数,支持向provideDimnames(sep,base)函数传参数。我在测试过程中,也不理解具体是什么更新。
8. uniroot()函数增加新的可选参数extendInt,允许自动扩展取值范围,并增加返回对象参数init.it。
> f1 <- function(x) (121 - x^2)/(x^2+1) # 函数f1
> f2 <- function(x) exp(-x)*(x - 12) # 函数f2
> try(uniroot(f1, c(0,10))) # 在(0,10)的区间求f1函数的根
Error in uniroot(f1, c(0, 10)) :
f() values at end points not of opposite sign
> try(uniroot(f2, c(0, 2))) # 在(0,2)的区间求f2函数的根
Error in uniroot(f2, c(0, 2)) :
f() values at end points not of opposite sign
> str(uniroot(f1, c(0,10),extendInt="yes")) # 通过extendInt参数扩大取值搜索范围
List of 5
$ root : num 11
$ f.root : num -3.63e-06
$ iter : int 12
$ init.it : int 4
$ estim.prec: num 6.1e-05
> str(uniroot(f2, c(0,2), extendInt="yes")) # 通过extendInt参数扩大取值搜索范围
List of 5
$ root : num 12
$ f.root : num 4.18e-11
$ iter : int 23
$ init.it : int 9
$ estim.prec: num 6.1e-05
9. switch(f,)函数,当参数f是因子类型时,会出警告提示,需要转换字符串参数。
> switch(ff[1], A = "I am A", B="Bb..", C=" is C")# -> "A" # 警告提示
[1] "I am A"
Warning message:
In switch(ff[1], A = "I am A", B = "Bb..", C = " is C") :
EXPR is a "factor", treated as integer.
Consider using 'switch(as.character( * ), ...)' instead.
> switch(as.character(ff[1]), A = "I am A", B="Bb..", C=" is C") # 转型为字符串处理
[1] " is C"
10. 解析器已经更新,使用更少的内存。
11. 一无运算符 “+ – !” 对属性值操作时,会做一份拷贝计算,但names、dims和dimnames是例外的。
> x<-1:12;x # 创建变量x
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> x+5 # 拷贝计算,不影响原变量x的值
[1] 6 7 8 9 10 11 12 13 14 15 16 17
> !x
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> dim(x) <- c(3,4);x # 直接修改原变量x的值
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
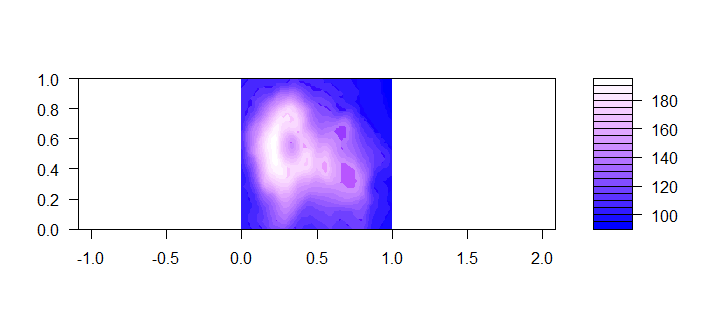
12. colorRamp()和colorRampPalette()支持透明色,让alpha参数为TRUE。
> cols<-colorRampPalette(c(rgb(0,0,1,1), rgb(1,0,1,0)), alpha = TRUE) # 取色的函数句柄
> filled.contour(volcano,color.palette =cols,asp = 1) # 画图
13. grid.show.layout()函数 和 grid.show.viewport()函数,都增加一个可选的参数vp.ex,用于布局缩放。
> library(grid) # 加载gird包
> grid.show.layout # 查看函数定义
function (l, newpage = TRUE, vp.ex = 0.8, bg = "light grey",
cell.border = "blue", cell.fill = "light blue", cell.label = TRUE,
label.col = "blue", unit.col = "red", vp = NULL)
14. 新的函数find_gs_cmd()在tools包中,用来定位GhostScript的可执行文件。
15. object.size() 函数增加format()方法定义,用于格式显示。
> letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" "t"
[21] "u" "v" "w" "x" "y" "z"
> object.size(letters) # 查看letters对象大小
1496 bytes
> format(object.size(letters), units = "auto") # 格式化显示
[1] "1.5 Kb"
16. 增加新字体ArialMT,用于pdf()和postscript()设备输出。
17. R软件的NEWS和NEWS.2文件,及新生成的文本和PDF文件,被移到doc目录存储。
> dir("C:/Program Files/R/R-3.1.0/doc") # 查看doc目录,包括NEWS和NEWS.2文件
[1] "AUTHORS" "CHANGES" "CHANGES.rds" "COPYING"
[5] "COPYRIGHTS" "CRAN_mirrors.csv" "FAQ" "html"
[9] "KEYWORDS" "KEYWORDS.db" "manual" "NEWS"
[13] "NEWS.0" "NEWS.1" "NEWS.2" "NEWS.pdf"
[17] "NEWS.rds" "README.packages" "README.Rterm" "RESOURCES"
[21] "rw-FAQ" "THANKS"
18. combn(x)函数支持参数x为因子类型,并返回因子类型。
> combn(letters[1:4], 2) # 字符串类型
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] "a" "a" "a" "b" "b" "c"
[2,] "b" "c" "d" "c" "d" "d"
> combn(factor(letters[1:4]), 2) # 因子类型
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] a a a b b c
[2,] b c d c d d
Levels: a b c d
19. 在utils包增加fileSnapshot()函数和changedFiles()函数,用于产生目录的文件快照和比较目录的快照文件。
> snapshot<-fileSnapshot() # 产生快照
> snapshot
File snapshot:
path = D:\workspace\R\basic\r311
timestamp =
file.info = TRUE
md5sum = FALSE
digest = NULL
full.names = FALSE
args = list()
9 files recorded.
> writeBin(3L:4L,"a.txt") # 在当目录中增加一个文件a.txt
> changedFiles(snapshot) # 比较目录快照
Files added:
a.txt
20. make.names()可以处理不合法的变量命名,当unique参数为TRUE时,新生成的变量名不重复。
> make.names(c("a b","a.b", "a-b")) # 处理不正确的变量名
[1] "a.b" "a.b" "a.b"
> make.names(c("a b","a.b", "a-b"), unique = TRUE) # 会生成3个不同的变量名
[1] "a.b.1" "a.b" "a.b.2"
21. 增加新函数cospi(x), sinpi(x) 和 tanpi(x),用于精确计算cos(pi*x),被lgamma(),besselI()等函数底层调用。
> x<-1222222222222221.323232
> cospi(x) # 当x变量值过大时,解决cos(pi*x)计算误差的问题
[1] -0.7071068
> cos(pi*x)
[1] -0.7175645
22. print.table(x)函数,支持x为小数。
> t1 <- round(abs(rt(10, df = 1.8)),1)
> t2 <- round(abs(rt(10, df = 1.4)),1)
> print.table(table(t1,t2),zero.print = ".")
t2
t1 0 0.1 0.4 0.5 1 1.2 1.3 1.7 8.2
0.1 . . . . . . . . 1
0.2 . . 1 . . . 1 . .
0.4 . . . . 1 . . . .
0.7 . 1 . . . . . . .
0.8 1 . . . . . . . .
1.2 . . . 1 . 1 . . .
1.4 . . 1 . . . . . .
2.2 . . . . . . . 1 .
23. 支持更多的时间,通过OlsonNames()函数查看时区列表,用Sys.timezone()函数查看当前系统环境绑定的时区。
> head(OlsonNames()) # 时区列表
[1] "Africa/Abidjan" "Africa/Accra"
[3] "Africa/Addis_Ababa" "Africa/Algiers"
[5] "Africa/Asmara" "Africa/Asmera"
> Sys.timezone() # 我的系统绑定的时区
[1] "Asia/Taipei"
24. 系统支持64位的time_t类型,从而可以方便的处理超出32位的时间部分,如(1902年以前,和2038以后的时间),目前还不支持OS X系统。
25. 目前time_t类型被用于部分的类Unit的64位系统上和Window的64位系统上。
26. 增加新的环境设置,save.defaults选项包括compression_level的配置。
27. colSums()函数,支持数组和数据框在2^31个元素以上的计算。
28. 优化as.factor()函数性能,加速非integer类型的向量转换。
> a<-rnorm(1000000,-100,100000)
> head(a)
[1] 9856.935 154567.963 -200041.134 43363.338 -74436.650
[6] -178322.313
> system.time(as.factor(a))
用户 系统 流逝
9.50 0.03 9.64
29. 快速傅立叶变换fft()函数支持大数据量计算,从原来的1200万个增加到2亿个。
> x <- 1:100000000 # 对1亿个数字进行傅立叶变换
> system.time(fft(x))
用户 系统 流逝
32.96 0.22 33.32
30. svd()函数用LAPACK软件的子程序ZGESDD实现,在真实的环境下进行复杂的模拟计算。
31. 如果让Sweave输出的.tex文件为UTF-8编码,你需要在LaTex文件中增加%\SweaveUTF8的设置。
32. 文件操作file.copy()函数,增加copy.date()的参数,让复制的文件与原文件有相同的修改时间。
> file.copy("a.txt","b.txt",copy.date=TRUE) # 创建文件b.txt
[1] TRUE
> file.copy("a.txt","c.txt",copy.date=FALSE) # 创建文件c.txt
[1] TRUE
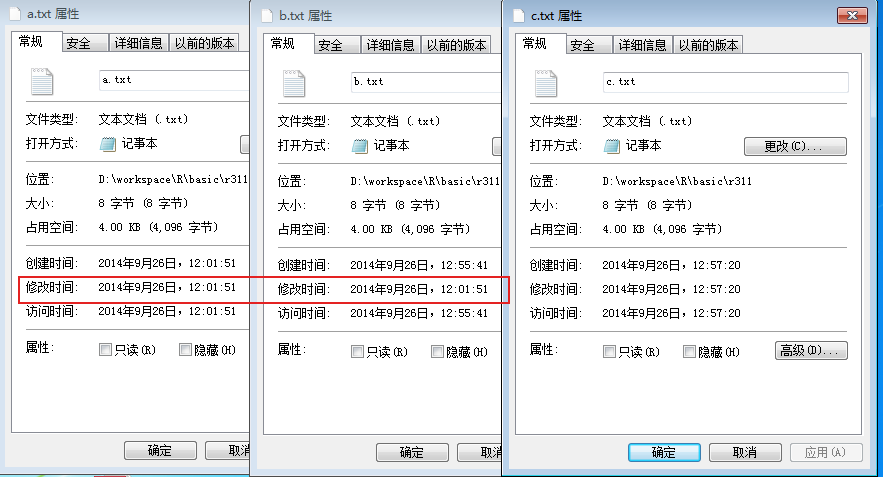
a.txt 和 b.txt有相同的文件修改时间,c.txt完成是全新创建的。
33. 用缩写字母表示时区中的时间日期,在POSIXlt类中设置可选的参数zone,如巴黎1940之前,缩写为 LMT, PMT WET 或 WEST。
34. gmtoff组件可以用于记录GMT的偏移量,在支持的平台上。
35. C语言实现的strftime()函数被更新到POSIX 2008标准,用于Window, OS X等系统。
36. dnorm(x)函数计算结果更准备,当|x|>5的时候,但性能下降。
> dnorm(rnorm(10,0,100)) # 执行dnorm()函数
[1] 1.151100e-271 0.000000e+00 2.403071e-198 0.000000e+00
[5] 0.000000e+00 3.358647e-208 0.000000e+00 0.000000e+00
[9] 0.000000e+00 1.136764e-154
37. tiff()函数增加压缩选项compression参数。
> tiff
function (filename = "Rplot%03d.tif", width = 480, height = 480, units = "px", pointsize = 12, compression = c("none", "rle","lzw", "jpeg", "zip", "lzw+p", "zip+p"), bg = "white", res = NA, family = "sans", restoreConsole = TRUE, type = c("windows","cairo"), antialias = c("default", "none", "cleartype", "grey", "subpixel"))
38. read.table(), readLines() 和 scan() 函数,读取数据时增加新参数skipNul,用于跳过空值。
> readLines
function (con = stdin(), n = -1L, ok = TRUE, warn = TRUE, encoding = "unknown", skipNul = FALSE)
39. 赋值时,避免右侧重复值的复杂计算,将减少替换值的拷贝。
40. 同时,一些其他的变化,也将减少对象的拷贝。
41. KalmanLike(), KalmanRun() 和 KalmanForecast() 函数的fast参数被mod参数替换,用于返回更新后的模型。
> fit3 <- arima(presidents, c(3, 0, 0))
> mod <- fit3$model # 模型
> pr <- KalmanForecast(4, mod, TRUE) # 执行卡尔曼预测函数
> mod <- attr(pr, "mod") # 更新后的模型,保存在mod属性中
42. arima()和makeARIMA()增加新的参数SSinit,计算的状态空间的初始化的似然函数。
> arima
function (x, order = c(0L, 0L, 0L), seasonal = list(order = c(0L, 0L, 0L), period = NA), xreg = NULL, include.mean = TRUE, transform.pars = TRUE, fixed = NULL, init = NULL, method = c("CSS-ML", "ML", "CSS"), n.cond, SSinit = c("Gardner1980", "Rossignol2011"), optim.method = "BFGS", optim.control = list(), kappa = 1e+06)
43. warning()函数增加新的参数noBreaks,用于简化输出处理。
> warning
function (..., call. = TRUE, immediate. = FALSE, noBreaks. = FALSE, domain = NULL)
44. pushBack()函数增加新的参数encoding,支持scan(),read.table()等函数读取UTF-8编码的文件。
> pushBack # 检查pushBack函数定义
function (data, connection, newLine = TRUE, encoding = c("", "bytes", "UTF-8"))
> zz <- textConnection(LETTERS) # 建个一个文本通道
> readLines(zz, 2)
[1] "A" "B"
> pushBack(c("aa", "bb"), zz) # 把aa,bb写入在zz对象中
> pushBackLength(zz)
[1] 2
> readLines(zz, 1)
[1] "aa"
> pushBackLength(zz)
[1] 1
> readLines(zz, 1)
[1] "bb"
> readLines(zz, 1)
[1] "C"
> close(zz)
45. all.equal.list() 函数增加新参数use.names,通过名字取代索引值来判断对象是否相等。
> a<-list(a=1,b=2)
> b<-list()
> b[['a']]<-1
> b[['b']]<-2
> all.equal.list(a,b) # 相等
[1] TRUE
> b[['a']]<-4
> all.equal.list(a,b, use.names=TRUE) # 不相等
[1] "Component “a”: Mean relative difference: 3"
46. all.equal() 和 attr.all.equal()增加新参数check.attributes,用于比较列名。
47. all.equal() 函数增加了检查,解决了之前未检查的空参数引入的错误。
48. 把check.attributes参数用于显示检查,允许NULL和numeric类型,会发现意想不到的错误。
49. all.equal.numeric()函数,当遇到比较的对象长度不一致时,会出现“规模差异” 的提示,但不是错误。
> all.equal.numeric(1:10,1:5)
[1] "Numeric: lengths (10, 5) differ"
50. all.equal()函数用POSIXt方法代替POSIXct方法。
51. 用seq()函数生成Date和POSIXt类型的序列时,允许使用by=quarter的分隔法。
> seq(today,today+365,by="quarter") # 按季度
[1] "2014-09-26" "2014-12-26" "2015-03-26" "2015-06-26" "2015-09-26"
> seq(today,today+365,by="2 months") # 按2个月
[1] "2014-09-26" "2014-11-26" "2015-01-26" "2015-03-26" "2015-05-26"
[6] "2015-07-26" "2015-09-26"
52. file.path()函数用于适配路径分隔符,这个函数在我测试过程中完成没有作用。
> file.path(c("c://abc\\000\\llj/jkh","c:/abc/a","d:\\bcd")) # 没有转换路径
[1] "c://abc\\000\\llj/jkh" "c:/abc/a"
[3] "d:\\bcd"
53. 增加新函数agrepl(),用于模糊匹配。
> agrepl("laysy", c("1 lazy", "1", "1 LAZY"), max = 2)
[1] TRUE FALSE FALSE
54. 让fifo()函数支持Window系统。
> capabilities("fifo") # 检查系统是否支持
fifo
TRUE
55. sort.list(method="radix")函数,支持基数排序,用于数据量很大,但值域个数很少的情况,比比较类的排序快很多。
> x<-sample(1:650,1e7,replace=TRUE)
> system.time(o1<-sort.list(x)) # 普通排序
用户 系统 流逝
7.13 0.02 7.14
> system.time(o2<-sort.list(x,method="radix")) # 基数排序
用户 系统 流逝
0.08 0.00 0.07
> all.equal(o1,o2) # 计算结果是一致的
[1] TRUE
56. print.ts()方法增加.preformat.ts()函数。
> sunsp.1 <- window(sunspot.month, end=c(1752, 12))
> m <- .preformat.ts(sunsp.1)
> print(m)
Jan Feb Mar Apr May Jun Jul Aug
1749 " 58.0" " 62.6" " 70.0" " 55.7" " 85.0" " 83.5" " 94.8" " 66.3"
1750 " 73.3" " 75.9" " 89.2" " 88.3" " 90.0" "100.0" " 85.4" "103.0"
1751 " 70.0" " 43.5" " 45.3" " 56.4" " 60.7" " 50.7" " 66.3" " 59.8"
1752 " 35.0" " 50.0" " 71.0" " 59.3" " 59.7" " 39.6" " 78.4" " 29.3"
Sep Oct Nov Dec
1749 " 75.9" " 75.5" "158.6" " 85.2"
1750 " 91.2" " 65.7" " 63.3" " 75.4"
1751 " 23.5" " 23.2" " 28.5" " 44.0"
1752 " 27.1" " 46.6" " 37.6" " 40.0"
57. mcparallel()函数增加一个参数detach,可以执行代码独立于当前的会话。它底层调用mcfork()函数设置参数estranged=TRUE,从而启动一个子进程独立于父进程运行。
58. pdf()函数输出时,将省略非常小的尺寸圆和文字,很多用户没有这样的文件。
59. hist.POSIXlt() 函数在用months,quarters和years分隔时了,右边将多加一天。
60. data.frame类型,支持索引为0,不报错。
> df<-data.frame(1:5)
> df[0,]
integer(0)
> df[1,]
[1] 1
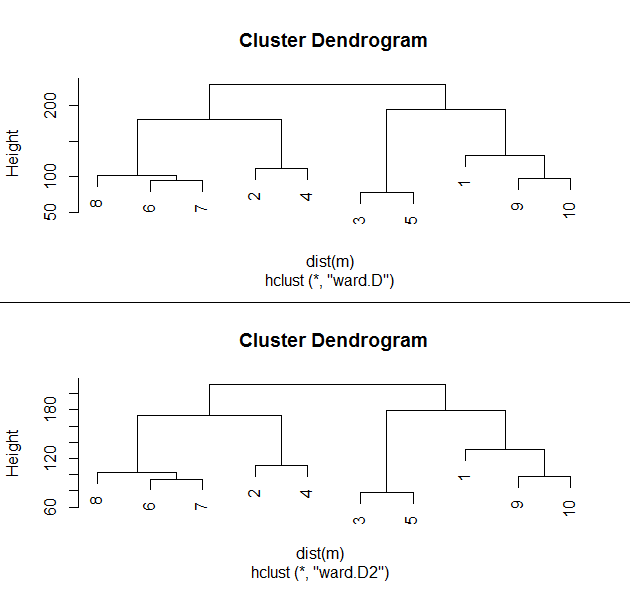
61. hclust()函数增加ward.D2的算法实现,之前的ward算法改名为ward.D。
> m<-matrix(sample(100,100,replace=TRUE),10);m
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 8 21 93 10 4 40 61 26 55 22
[2,] 100 85 24 98 94 1 75 70 34 85
[3,] 12 59 12 13 28 72 76 81 94 12
[4,] 97 34 21 50 98 26 14 37 72 62
[5,] 27 98 14 22 16 90 57 36 60 29
[6,] 24 87 22 6 61 68 17 13 27 93
[7,] 94 87 64 5 89 81 27 1 18 61
[8,] 98 89 5 5 40 26 45 4 36 53
[9,] 34 10 32 31 100 31 64 20 25 85
[10,] 19 38 71 72 35 40 75 13 54 94
> hc1<-hclust(dist(m), method="ward.D");hc1
Call:
hclust(d = dist(m), method = "ward.D")
Cluster method : ward.D
Distance : euclidean
Number of objects: 10
> hc2<-hclust(dist(m), method="ward.D2");hc2
Call:
hclust(d = dist(m), method = "ward.D2")
Cluster method : ward.D2
Distance : euclidean
Number of objects: 10
> plot(hc1)
> plot(hc2)
62. sunspot.month数据集更新,sunspot.year数据集保持不变。
> head(sunspot.month)
[1] 58.0 62.6 70.0 55.7 85.0 83.5
> head(sunspot.year)
[1] 5 11 16 23 36 58
63. summary()函数对于lm()一元线性回归的拟合会出发警告,因为有时候计算会不准备,这与平台相关。我在Window中测试时,没有发现警告。
> ctl <- c(4.17,5.58,5.18,6.11,4.50,4.61,5.17,4.53,5.33,5.14)
> trt <- c(4.81,4.17,4.41,3.59,5.87,3.83,6.03,4.89,4.32,4.69)
> group <- gl(2, 10, 20, labels = c("Ctl","Trt"))
> weight <- c(ctl, trt)
> lm.D9 <- lm(weight ~ group)
> summary(lm.D9)
Call:
lm(formula = weight ~ group)
Residuals:
Min 1Q Median 3Q Max
-1.0710 -0.4938 0.0685 0.2462 1.3690
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.0320 0.2202 22.850 9.55e-15 ***
groupTrt -0.3710 0.3114 -1.191 0.249
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.6964 on 18 degrees of freedom
Multiple R-squared: 0.07308, Adjusted R-squared: 0.02158
F-statistic: 1.419 on 1 and 18 DF, p-value: 0.249
64. 在编程中,提取summary()函数计算出数据时,最好封装在suppressWarnings()函数中。
> suppressWarnings(summary(lm.D9)$cov.unscaled)
(Intercept) groupTrt
(Intercept) 0.1 -0.1
groupTrt -0.1 0.2
终于把这54项更新都整理完了,这些更新很多都与性能相关,另外一块是语法上的优化,看得出R语言工作的重点方向。
3. R 3.1.1新特性及代码描述
R语言3.1.1版本的别名是Sock it to Me,很有意思。下载R3.1.1版本后,你可以通过version来查看版本信息。
~ R # 启动R程序
> version # 查看版本信息
platform x86_64-w64-mingw32
arch x86_64
os mingw32
system x86_64, mingw32
status
major 3
minor 1.1
year 2014
month 07
day 10
svn rev 66115
language R
version.string R version 3.1.1 (2014-07-10)
nickname Sock it to Me
新特性
1. attach()函数的冲突提示,与library()函数信息提示是相似的,都使用message()函数来实现。
> w<-women # 把women赋值给w
> w
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
8 65 135
9 66 139
10 67 142
11 68 146
12 69 150
13 70 154
14 71 159
15 72 164
> attach(w) # 加载w数据集
> height # 直接使用数据集中的height列
[1] 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
> attach(women) # 加载women数据集,列名变量发生冲突
The following objects are masked from w:
height, weight
> library(xts) # library包加载冲突提示
载入需要的程辑包:zoo
载入程辑包:‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
2. R CMD Sweave命令,默认不再删除任何文件,并增加--clean参数设置,--clean=default和--clean=keepOuts。
~ C:\Users\Administrator>R CMD Sweave
Usage: R CMD Sweave [options] file
A front-end for Sweave and other vignette engines, via buildVignette()
Options:
-h, --help print this help message and exit
-v, --version print version info and exit
--driver=name use named Sweave driver
--engine=pkg::engine use named vignette engine
--encoding=enc default encoding 'enc' for file
--clean corresponds to --clean=default
--clean= remove some of the created files:
"default" removes those the same initial name;
"keepOuts" keeps e.g. *.tex even when PDF is produced
--options= comma-separated list of Sweave/engine options
--pdf convert to PDF document
--compact= try to compact PDF document:
"no" (default), "qpdf", "gs", "gs+qpdf", "both"
--compact same as --compact=qpdf
Report bugs at bugs.r-project.org .
3. tools包buildVignette()函数和buildVignettes()函数,当clean参数FALSE时,不再删除新创建的文件。
> library(tools)
> buildVignette
function (file, dir = ".", weave = TRUE, latex = TRUE, tangle = TRUE,
quiet = TRUE, clean = TRUE, keep = character(), engine = NULL,
buildPkg = NULL, ...)
4. 在Bioconductor版本中使用setRepositories()函数,可以通过环境变量R_BIOC_VERSION在运行时设置,原来只能在R软件安装时设置。(Bioconductor的版本将从2.14升级到3.0)
5. 嵌入在Sweave文件的Sexpr代码的bug的错误信息,会显示源代码错误位置。
6. type.convert()函数、read.table()函数或read.*()函数,都增加了一个新的参数numerals,可以在读数据的时候直接转型成double,并设置数字精度。
> type.convert
function (x, na.strings = "NA", as.is = FALSE, dec = ".", numerals = c("allow.loss", "warn.loss", "no.loss"))
.External2(C_typeconvert, x, na.strings, as.is, dec, match.arg(numerals))
<bytecode: 0x0000000008e1b948>
<environment: namespace:utils>
7. 增加R语言内部代码的健壮性,修正一些编译器,对于整理加法溢出无异常提示的问题。
> as.integer(2000000000)+as.integer(2000000000)
[1] NA
Warning message:
In as.integer(2e+09) + as.integer(2e+09) : NAs produced by integer overflow
8. smooth.spline()函数的knots参数默认值改为.nknots.smspl。
> smooth.spline
function (x, y = NULL, w = NULL, df, spar = NULL, cv = FALSE,
all.knots = FALSE, nknots = .nknots.smspl, keep.data = TRUE,
df.offset = 0, penalty = 1, control.spar = list(), tol = 1e-06 * IQR(x))
9. Beta分布函数dbeta(, a,b), pbeta(), qbeta() 和 rbeta() 的a,b参数默认值改为0,原来是NaN。a,b对应参数为shape1, shape2。
> dbeta
function (x, shape1, shape2, ncp = 0, log = FALSE)
{
if (missing(ncp))
.External(C_dbeta, x, shape1, shape2, log)
else .External(C_dnbeta, x, shape1, shape2, ncp, log)
}
<bytecode: 0x000000000d54c070>
<environment: namespace:stats>
10. RStudio的图形设备不能正常使用dev.new()函数,给dev.new()函数增加的新的参数noRStudioGD,替换原来的默认选择,从而实现在RStudio中图形设备的开发。
> dev.new() # 警告错误
NULL
Warning message:
In (function () : Only one RStudio graphics device is permitted
> dev.new(noRStudioGD=TRUE) # 弹出新窗口,运行正确
11. 增加readRDS()函数,用于读了rds的数据文件。
> d<-data.frame(a=1:10,b=10:1)
> saveRDS(d, "d.rds") # 把d数据框,以rds格式保存
> d2<-readRDS("d.rds") # 读取rds数据
> d2
a b
1 1 10
2 2 9
3 3 8
4 4 7
5 5 6
6 6 5
7 7 4
8 8 3
9 9 2
10 10 1
12. 当修改内部逻辑标量常数的时候,会提示错误,原来是警告。
> pi # 常数pi
[1] 3.141593
> pi<<-3.2 # 修改常数pi会出错
Error: cannot change value of locked binding for 'pi'
13. install.packages(repos = NULL)函数,支持http或ftp协议的下载并安装新包。
> install.packages("plyr", repos = "http://cran.rstudio.com/")
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.1/plyr_1.8.1.zip'
Content type 'application/zip' length 1151983 bytes (1.1 Mb)
opened URL
downloaded 1.1 Mb
package ‘plyr’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\Administrator\AppData\Local\Temp\RtmpWEXnOT\downloaded_packages
14. 当R环境变量options("warnPartialMatchDollar")为TRUE,数据框用$符号部分匹配为会出现警告。
> options("warnPartialMatchDollar") # 默认值
$warnPartialMatchDollar
NULL
> options(warnPartialMatchDollar = TRUE) # 赋值设为TRUE
> options("warnPartialMatchDollar")
$warnPartialMatchDollar
[1] TRUE
> df <- data.frame(ab=1:4,cd=1:4)
> rownames(df) <- paste0(letters[1:4],"a")
> df$a # 警告
[1] 1 2 3 4
Warning message:
In `$.data.frame`(df, a) : Partial match of 'a' to 'ab' in data frame
> df["a",] # 另一种调用方法
15. 通过package?foo的语法来查询包的信息,无论包是否被加载。
> search() # 当前环境已加载的包,不包括plyr
[1] ".GlobalEnv" "tools:rstudio" "package:stats"
[4] "package:graphics" "package:grDevices" "package:utils"
[7] "package:datasets" "package:methods" "Autoloads"
[10] "package:base"
> package?plyr # 可以直接打开plyr的包帮助
> package?pryr
Error in `?`(package, pryr) :
没有种类为‘package’和題目为‘pryr’的文件(或是在处理帮助文件时发生了错误)
16. 调用R的帮助,现在默认会尝试所有加载的包,而不仅仅是在搜索路径。
> help(package="zoo") # 查看未加载包的信息
> ??zoo # 查看未加载包中,所有名字匹配的函数
17. 增加promptImport()函数,用于从其他包导出一个帮助文件。
> promptImport(cat) # 导出cat函数的帮助文件
建立一名字叫‘cat.Rd’的文件。
修改文件再把它放到合适的目录中去。
查看生成cat.Rd文件。
\name{cat}
\alias{cat}
\docType{import}
\title{Import from package \pkg{base}}
\description{
The \code{cat} object is imported from package \pkg{base}.
Help is available here: \code{\link[base:cat]{base::cat}}.
}
对于R 3.1.1版本的更新,一部分增加新功能,另外有些更新其实是在给3.1.0版本修补bug。
对于想深入学习R语言的用户来说,每次更新升级都需要看一遍这个列表,很多是时候都可以解决我们实际遇到的问题。比如,R3.1.1版本第10个更新对RStudio图形输出的支持,就可以直接解决在我在RStudio中由于图形设备错误,不能开发游戏的问题。
补充说明,由于每个更新点官司仅有一句话描述,而我的知识水平有限,也并不是所有都能理解,文章中难免理解错误的地方,如果有同学发现还请指教。
转载请注明出处:
http://blog.fens.me/r-version-3-1/
