R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-magrittr/

前言
使用R语言进行数据处理是非常方便的,几行代码就可以完成很复杂的操作。但是,对于数据的连续处理,还是有人觉得代码不好看,要么是长长的函数嵌套调用,有点像Lisp感觉,括号包一切;要么就是每次操作赋值一个临时变量,啰嗦。为什么就不能像Linux的管道一样优雅呢?
magrittr包在这样场景中被开发出来,通过管道的方式让连续复杂数据的处理操作,代码更短,更容易读,甚至一行代码可以搞定原来10行代码的事情。
目录
- magrittr介绍
- magrittr安装
- magrittr包的基本使用
- magrittr包的扩展功能
1. magrittr介绍
magrittr包被定义为一个高效的管道操作工具包,通过管道的连接方式,让数据或表达式的传递更高效,使用操作符%>%,可以直接把数据传递给下一个函数调用或表达式。magrittr包的主要目标有2个,第一是减少代码开发时间,提高代码的可读性和维护性;第二是让你的代码更短,再短,短短短…
magrittr包,主要定义了4个管道操作符,分另是%>%, %T>%, %$% 和 %<>%。其中,操作符%>%是最常用的,其他3个操作符,与%>%类似,在特殊的使用场景会起到更好的作用。当正确掌握这几个操作符后,你一定会爱不释手的,快去把所有的代码都重构吧,砍掉原来大段冗长的代码是一件多么令人激动的事情啊。
magrittr的项目主页:https://github.com/smbache/magrittr
2. magrittr安装
本文所使用的系统环境
- Win10 64bit
- R: 3.2.3 x86_64-w64-mingw32/x64 b4bit
magrittr是在CRAN发布的标准库,安装起来非常简单,2条命令就可以了。
~ R
> install.packages('magrittr')
> library(magrittr)
3. magrittr包的使用
对于magrittr包的使用,其实就是掌握这4个操作符的用法,向右操作符%>%, 向左操作符%T>%, 解释操作符%$% 和 复合赋值操作符%<>%。
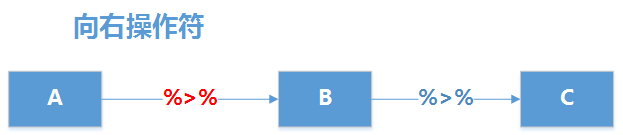
3.1 %>% 向右操作符(forward-pipe operator)
%>%是最常用的一个操作符,就是把左侧准备的数据或表达式,传递给右侧的函数调用或表达式进行运行,可以连续操作就像一个链条一样。
现实原理如下图所示,使用%>%把左侧的程序的数据集A传递右侧程序的B函数,B函数的结果数据集再向右侧传递给C函数,最后完成数据计算。
比如,我们要做下面的事情。(这是一个YY的需求。)
- 取10000个随机数符合,符合正态分布。
- 求这个10000个数的绝对值,同时乘以50。
- 把结果组成一个100*100列的方阵。
- 计算方阵中每行的均值,并四舍五入保留到整数。
- 把结果除以7求余数,并话出余数的直方图。
我们发现上面的5个过程是连续的,正常的代码我要怎么实现呢。
# 设置随机种子
> set.seed(1)
# 开始
> n1<-rnorm(10000) # 第1步
> n2<-abs(n1)*50 # 第2步
> n3<-matrix(n2,ncol = 100) # 第3步
> n4<-round(rowMeans(n3)) # 第4步
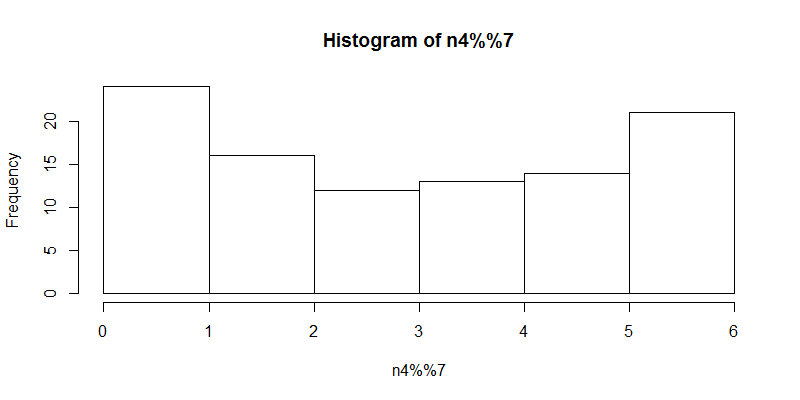
> hist(n4%%7) # 第5步
输出的直方图:
上面的代码写法是,每一行实现一个条件,但中间多了不少的临时变量。再看另外一种的写法,括号包一切。
# 设置随机种子
> set.seed(1)
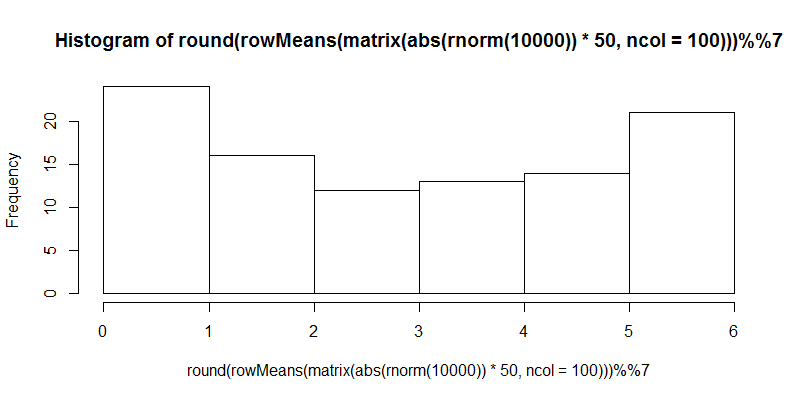
> hist(round(rowMeans(matrix(abs(rnorm(10000))*50,ncol=100)))%%7)
输出的直方图:
我分别用两种常见的代码风格,实现了我们的需求。再看看%>%的方式,有多么的不一样。
# 设置随机种子
> set.seed(1)
# 开始
> rnorm(10000) %>%
+ abs %>% `*` (50) %>%
+ matrix(ncol=100) %>%
+ rowMeans %>% round %>%
+ `%%`(7) %>% hist
输出的直方图:
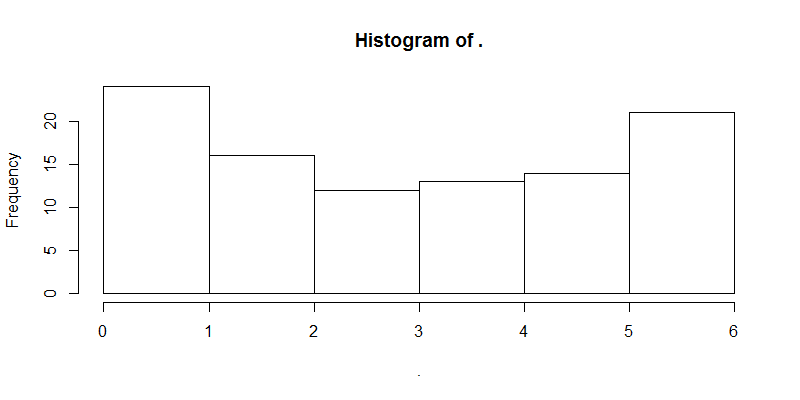
一行代码,不仅搞定所有的事情,而且结构清楚,可读性非常强。这就是管道代码风格,带来的优雅和简约。
3.2 %T>% 向左操作符(tee operator)
%T>%向左操作符,其实功能和 %>% 基本是一样的,只不过它是把左边的值做为传递的值,而不是右边的值。这种情况的使用场景也是很多的,比如,你在数据处理的中间过程,需要打印输出或图片输出,这时整个过程就会被中断,用向左操作符,就可以解决这样的问题。
现实原理如下图所示,使用%T>%把左侧的程序的数据集A传递右侧程序的B函数,,B函数的结果数据集不再向右侧传递,而是把B左侧的A数据集再次向右传递给C函数,最后完成数据计算。
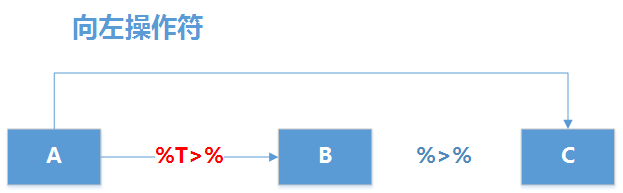
我们把上面的需求稍微进行调整,在最后增加一个要求,就会用到向左操作符。
- 取10000个随机数符合,符合正态分布。
- 求这个10000个数的绝对值,同时乘以50。
- 把结果组成一个100*100列的方阵。
- 计算方阵中每行的均值,并四舍五入保留到整数。
- 把结果除以7求余数,并话出余数的直方图。
- 对余数求和
由于输出直方图后,返回值为空,那么再继续管道,就会把空值向右进行传递,这样计算最后一步时就会出错。这时我们需求的是,把除以7的余数向右传递给最后一步求和,那么就可以用到 %T>% 了
直接使用%>%向右传值,出现异常。
> set.seed(1)
> rnorm(10000) %>%
+ abs %>% `*` (50) %>%
+ matrix(ncol=100) %>%
+ rowMeans %>% round %>%
+ `%%`(7) %>% hist %>% sum
Error in sum(.) : invalid 'type' (list) of argument
使用 %T>% 把左边的值,再向右传值,则结果正确。
> rnorm(10000) %>%
+ abs %>% `*` (50) %>%
+ matrix(ncol=100) %>%
+ rowMeans %>% round %>%
+ `%%`(7) %T>% hist %>% sum
[1] 328
3.3 %$% 解释操作符(exposition pipe-operator)
%$% 的作用是把左侧数据的属性名传给右侧,让右侧的调用函数直接通过名字,就可以获取左侧的数据。比如,我们获得一个data.frame类型的数据集,通过使用 %$%,在右侧的函数中可以直接使用列名操作数据。
现实原理如下图所示,使用%$%把左侧的程序的数据集A传递右侧程序的B函数,同时传递数据集A的属性名,作为B函数的内部变量方便对A数据集进行处理,最后完成数据计算。

下面定义一个3列10行的data.frame,列名分别为x,y,z,或缺x列大于5的数据集。使用 %$% 把列名x直接传到右侧进行判断。这里.代表左侧的完整数据对象。一行代码就实现了需求,而且这里不需要显示的定义中间变量。
> set.seed(1)
> data.frame(x=1:10,y=rnorm(10),z=letters[1:10]) %$% .[which(x>5),]
x y z
6 6 -0.8204684 f
7 7 0.4874291 g
8 8 0.7383247 h
9 9 0.5757814 i
10 10 -0.3053884 j
如果不使用%$%,我们通常的代码写法为:
> set.seed(1)
> df<-data.frame(x=1:10,y=rnorm(10),z=letters[1:10])
> df[which(df$x>5),]
x y z
6 6 -0.8204684 f
7 7 0.4874291 g
8 8 0.7383247 h
9 9 0.5757814 i
10 10 -0.3053884 j
从代码中可以发现,通常的写法是需要定义变量df的,df一共要被显示的使用3次,就是这一点点的改进,会让代码看起来更干净。
3.4 %<>% 复合赋值操作符(compound assignment pipe-operator)
%<>%复合赋值操作符, 功能与 %>% 基本是一样的,对了一项额外的操作,就是把结果写到左侧对象。比如,我们需要对一个数据集进行排序,那么需要获得排序的结果,用%<>%就是非常方便的。
现实原理如下图所示,使用%<>%把左侧的程序的数据集A传递右侧程序的B函数,B函数的结果数据集再向右侧传递给C函数,C函数结果的数据集再重新赋值给A,完成整个过程。
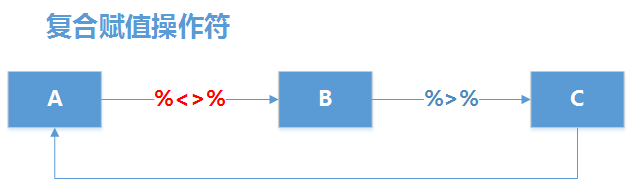
定义一个符合正态分布的100个随机数,计算绝对值,并按从小到大的顺序排序,获得并取前10个数字赋值给x。
> set.seed(1)
> x<-rnorm(100) %<>% abs %>% sort %>% head(10)
> x
[1] 0.001105352 0.016190263 0.028002159 0.039240003 0.044933609 0.053805041 0.056128740
[8] 0.059313397 0.074341324 0.074564983
是不是太方便了,一行就实现了一连串的操作。但是这里同时有一个陷阱,需要注意一下 %<>% 必须要用在第一个管道的对象处,才能完成赋值的操作,如果不是左侧第一个位置,那么赋值将不起作用。
> set.seed(1)
> x<-rnorm(100)
# 左侧第一个位置,赋值成功
> x %<>% abs %>% sort %>% head(10)
> x
[1] 0.001105352 0.016190263 0.028002159 0.039240003 0.044933609 0.053805041 0.056128740
[8] 0.059313397 0.074341324 0.074564983
# 左侧第二个位置,结果被直接打印出来,但是x的值没有变
> x %>% abs %<>% sort %>% head(10)
[1] 0.001105352 0.016190263 0.028002159 0.039240003 0.044933609 0.053805041 0.056128740
[8] 0.059313397 0.074341324 0.074564983
> length(x)
[1] 10
# 左侧第三个位置,结果被直接打印出来,但是x的值没有变
> x %>% abs %>% sort %<>% head(10)
[1] 0.001105352 0.016190263 0.028002159 0.039240003 0.044933609 0.053805041 0.056128740
[8] 0.059313397 0.074341324 0.074564983
> length(x)
[1] 10
4. magrittr包的扩展功能
我们已经了解了magrittr包的4个操作符的使用,除了操作符,我们再看一下magrittr还有哪些功能。
- 符号操作符定义
- %>%对代码块的传递
- %>%对函数的传递
4.1 符号操作符定义
为了让链条传递看起来更友好,magrittr对于常见的计算符号操作符进行的重新定义,让每个操作都对应用一个函数,这样所有的传递调用代码都是风格统一的。比如,add()函数和`+`是等价的。
下面列出对应的列表:
extract `[`
extract2 `[[`
inset `[<-`
inset2 `[[<-`
use_series `$`
add `+`
subtract `-`
multiply_by `*`
raise_to_power `^`
multiply_by_matrix `%*%`
divide_by `/`
divide_by_int `%/%`
mod `%%`
is_in `%in%`
and `&`
or `|`
equals `==`
is_greater_than `>`
is_weakly_greater_than `>=`
is_less_than `<`
is_weakly_less_than `<=`
not (`n'est pas`) `!`
set_colnames `colnames<-`
set_rownames `rownames<-`
set_names `names<-`
我们来看一下使用的效果。对一个包括10个随机数的向量的先*5再+5。
# 使用符号的写法
> set.seed(1)
> rnorm(10) %>% `*`(5) %>% `+`(5)
[1] 1.8677309 5.9182166 0.8218569 12.9764040 6.6475389 0.8976581 7.4371453 8.6916235
[9] 7.8789068 3.4730581
# 使用函数的写法
> set.seed(1)
> rnorm(10) %>% multiply_by(5) %>% add(5)
[1] 1.8677309 5.9182166 0.8218569 12.9764040 6.6475389 0.8976581 7.4371453 8.6916235
[9] 7.8789068 3.4730581
上面计算结果是完全一样的,用函数替换了符号。其实,这种转换的操作在面向对象的封装时是非常有用的,像hibernate封装了所有的SQL,XFire封装了WebServices协议等。
4.2 %>%传递到代码块
有些时候,我们对同一个数据块的要进行次行的处理,一条语句是很难完成的,这些就需要一个代码块也进行处理。把数据集传递到{}代码块中,传入的数据集以.来表示,通过一段代码来完成操作,而不是一句话完成操作。
比如,对一个包括10个随机数的向量的先*5再+5,求出向量的均值和标准差,并从小到大排序后返回前5条。
> set.seed(1)
> rnorm(10) %>%
+ multiply_by(5) %>%
+ add(5) %>%
+ {
+ cat("Mean:", mean(.),
+ "Var:", var(.), "\n")
+ sort(.) %>% head
+ }
Mean: 5.661014 Var: 15.23286
[1] 0.8218569 0.8976581 1.8677309 3.4730581 5.9182166 6.6475389
通过{}包装的代码块,就可以很方便的完成多少处理的复杂操作。
4.3 %>%传递到函数
传递到函数和传递到代码块设计是类似的,是把一个数据集传给一个匿名函数,进行复杂的数据数据的操作。在这里,我们会显示的定义数据集的名字作为匿名函数的参数。
比如,对鸢尾花数据集进行处理,只保留第一行和最后一行作为结果。
> iris %>%
+ (function(x) {
+ if (nrow(x) > 2)
+ rbind(head(x, 1), tail(x, 1))
+ else x
+ })
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
150 5.9 3.0 5.1 1.8 virginica
这里x就是iris数据集,作为了函数的显示参数,被应用于后续的数据处理过程。
通过对magrittr的学习,我们掌握了一些特殊的R语言代码的编程技巧,用magrittr包写出的R语言程序,与传统的R语言代码是有区别,可以你的程序很简单、很高效。
天性“懒惰”的程序员总是会想各种办法,来减少自己的代码,让代码变得优雅,同时还能让程序更可靠。什么时候能把代码写得越来越少,那么你就越来越接近高手!
转载请注明出处:
http://blog.fens.me/r-magrittr/
