R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-rsqlite/
前言
RSQLite包支持在R中的非常方便地创建和使用sqlite数据库,sqlite是单文件数据库,不需要预先安装,可内嵌在程序代码中。RSQLite的主要数据库操作依赖于DBI包,DBI是R语言中关系型数据库的底层接口包,除了支持RSQLite, 还支持 RMySQL, RPostgreSQL等连接其他数据库的包。
RSQLite的使用,是不需要本地提前装好SQLite的。本文阅读时,可以跳过第1,2节直接看RSQLite安装和使用。
目录
- SQLite数据库介绍
- 在 Windows 上安装 SQLite
- RSQLite 安装和使用
1. SQLite数据库介绍
SQLite 是一个开源的、轻量级的单进程数据库,通过单文件实现数据库存储。SQLite 数据库无服务器端、零配置的、支持事务性的 SQL 数据库引擎,应用程序可以进行静态或动态连接,直接访问其存储文件。SQLite 源代码不受版权限制。
SQLite官方网站:https://www.sqlite.org/index.html
2. 在 Windows 上安装 SQLite
如果单独使用 SQLite 时,我们可以从官方网站下载页面,从 Windows 区下载预编译的二进制文件和命令行工具文件。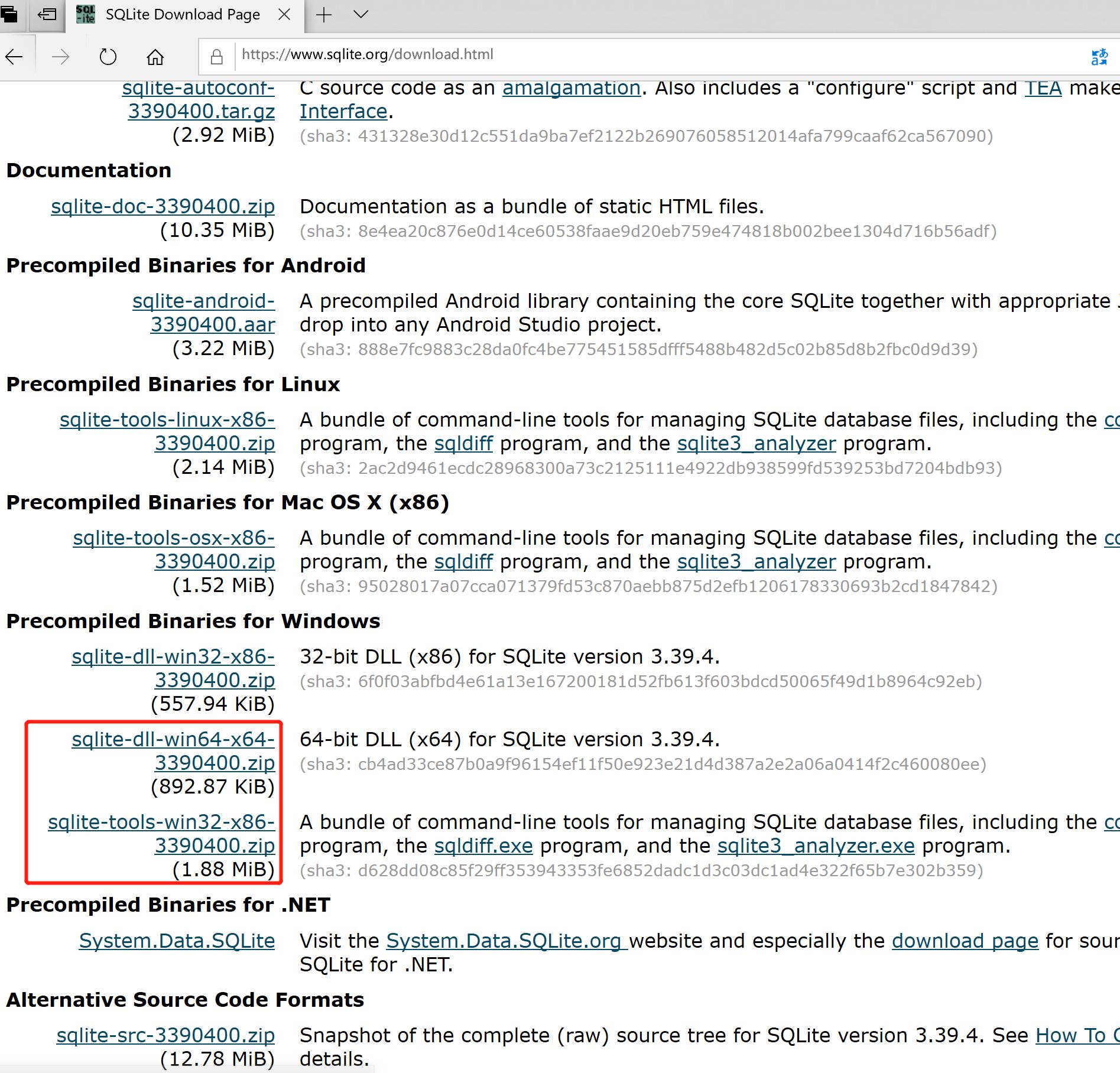
把上面2个目录的文件,进行解压,统一放到一个目录下面,我放到了D:/sqlite目录。
双击sqlite3.exe文件,用来启动命令行工具。
最后,添加 D:\sqlite 到 PATH 环境变量,就可以直接在命令提示符下,使用 sqlite3 命令,可以在任意目录启动sqlite数据库。
我们也可以安装sqlite可视化工具,进行操作,如免费的sqlitestudio工具https://www.sqlitestudio.pl/。
3. RSQLite安装和使用
在R语言中,我们也可以非常方便地使用RSQLite数据库,本地多个文件,也不用再单独装个MySQL之类的,对于数据量不太大的应用来说,是非常方便的,特别是结合shiny的原型小应用。RSQLite的使用,不需求本地提前装好RSQLite的程序。
RSQLite 大部分功能都是依赖于DBI包的,在DBI之外,RSQLite包支持事务,数据库拷贝,修改配置等功能。话说RSQLite 也是Hadley Wickham开发的。RSQLite 包的 API列表:https://rsqlite.r-dbi.org/reference/index.html
4.1 RSQLite安装
首先,我们安装RSQLite是非常简单的,就一条语句
# 安装RSQLite包
> install.packages("RSQLite")
# 加载RSQLite包
> library(RSQLite)
RSQLite 数据库就是一个文件,所以我们首先要,先设置一个工作路径,然后给定义一个文件名。在目录中,会多出一个文件 C:\work\R\db\my-db.sqlite,这样我们的数据库就算是建立好了。
> setwd("C:\\work\\R\\db")
> conn <- dbConnect(SQLite(), "my-db.sqlite")
> dbGetInfo(conn)
$db.version
[1] "3.39.4"
$dbname
[1] "C:\\work\\R\\db\\my-db.sqlite"
$username
[1] NA
$host
[1] NA
$port
[1] NA
建立连接后,数据库的所有操作,都在内存中进行,并不会实时同步到文件,只有在执行关闭数据库连接的时候,才会一次性写入本地数据库的文件中。
4.2 整表操作
接下来,我们用RSQLite来创建数据表,通过整个表的方式,创建表 mtcars,并把数据集mtcars整体写入表,读取表。
# 查看数据集
> head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# 创建表 mtcars,数据整表写入
> dbWriteTable(conn, "mtcars", head(mtcars))
# 查看当前数据库中的表
> dbListTables(conn)
[1] "mtcars"
# 数据整表读取
> dbReadTable(conn,"mtcars")
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# 用SQL读取数据
> dbGetQuery(conn, 'SELECT * FROM mtcars where cyl < 6')
mpg cyl disp hp drat wt qsec vs am gear carb
1 22.8 4 108 93 3.85 2.32 18.61 1 1 4 1
# 用预定义变量的SQL读取数据
> dbGetQuery(conn, 'SELECT * FROM mtcars WHERE mpg < :x',
+ params = list(x = 20))
mpg cyl disp hp drat wt qsec vs am gear carb
1 18.7 8 360 175 3.15 3.44 17.02 0 0 3 2
2 18.1 6 225 105 2.76 3.46 20.22 1 0 3 1
# 删除表
> dbRemoveTable(conn,"mtcars")
4.3 增删改查独立语句
按照每一步创建表,和执行CRUD操作的进行独立语句的执行。
创建表,用一个已知的data.frame数据集,进行表的创建,只会创建表结构,不会写入数据集的数据。
# 创建表
> dbCreateTable(conn,"table2",mtcars)
# 查看表的字段
> dbListFields(conn,"table2")
[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am"
[10] "gear" "carb"
# 读取表,没有数据
> dbReadTable(conn,"table2")
[1] mpg cyl disp hp drat wt qsec vs am gear carb
<0 行> (或0-长度的row.names)
用SQL的INSERT INTO语法插入数据。
# 拼接SQL
> sql1<-"INSERT INTO table2 VALUES ("
> sql2<-paste(table1[1,],collapse = ",")
> sql3<-")"
> sql<-paste0(sql1,sql2,sql3);
> sql<-paste0(sql1,sql2,sql3);
> sql
[1] "INSERT INTO table2 VALUES (21,6,160,110,3.9,2.62,16.46,0,1,4,4)"
# 执行插入
> dbExecute(conn,sql)
[1] 1
# 查看数据
> dbReadTable(conn,"table2")
mpg cyl disp hp drat wt qsec vs am gear carb
1 21 6 160 110 3.9 2.62 16.46 0 1 4 4
使用SQL的UPDATE语法修改数据
# 把cyl改成改成17
> dbExecute(conn,"UPDATE table2 SET cyl=17 WHERE mpg=21",immediate = TRUE)
[1] 1
# 查看数据
> dbReadTable(conn,"table2")
mpg cyl disp hp drat wt qsec vs am gear carb
1 21 17 160 110 3.9 2.62 16.46 0 1 4 4
用SQL的DELETE语法,删除数据。
# 再插入一条数据
> dbExecute(conn,sql)
[1] 1
> dbReadTable(conn,"table2")
mpg cyl disp hp drat wt qsec vs am gear carb
1 21 17 160 110 3.9 2.62 16.46 0 1 4 4
2 21 6 160 110 3.9 2.62 16.46 0 1 4 4
# 执行删除数据
> dbExecute(conn, 'DELETE FROM table2 WHERE cyl=17')
[1] 1
> dbReadTable(conn,"table2")
mpg cyl disp hp drat wt qsec vs am gear carb
1 21 6 160 110 3.9 2.62 16.46 0 1 4 4
4.4 执行完成
执行完成,关闭数据库连接。
> # 关闭连接
> dbDisconnect(conn)
这个时候,我们刚才的操作才会同步写入到 my-db.sqlite 文件中,之前一直都是在内存中执行的。
4.5 批量查询
RSQLite还提供了批量查询功能,对于数据量很大的时候,可以采用批量的方式,分步加载数据。
# 建立数据库连接
> conn <- dbConnect(SQLite(), "my-db.sqlite")
# 执行延迟查询,获得查询的句柄rs
> rs <- dbSendQuery(conn, 'SELECT * FROM mtcars')
# 以分页批次方式获取数据,每页为5条
> while (!dbHasCompleted(rs)) {
+ df <- dbFetch(rs, n = 5)
+ print(df)
+ }
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
mpg cyl disp hp drat wt qsec vs am gear carb
1 18.1 6 225.0 105 2.76 3.46 20.22 1 0 3 1
2 14.3 8 360.0 245 3.21 3.57 15.84 0 0 3 4
3 24.4 4 146.7 62 3.69 3.19 20.00 1 0 4 2
4 22.8 4 140.8 95 3.92 3.15 22.90 1 0 4 2
5 19.2 6 167.6 123 3.92 3.44 18.30 1 0 4 4
mpg cyl disp hp drat wt qsec vs am gear carb
1 17.8 6 167.6 123 3.92 3.44 18.90 1 0 4 4
2 16.4 8 275.8 180 3.07 4.07 17.40 0 0 3 3
3 17.3 8 275.8 180 3.07 3.73 17.60 0 0 3 3
4 15.2 8 275.8 180 3.07 3.78 18.00 0 0 3 3
5 10.4 8 472.0 205 2.93 5.25 17.98 0 0 3 4
mpg cyl disp hp drat wt qsec vs am gear carb
1 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
2 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
3 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
4 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
5 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
2 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
3 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
4 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
5 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
mpg cyl disp hp drat wt qsec vs am gear carb
1 27.3 4 79.0 66 4.08 1.935 18.9 1 1 4 1
2 26.0 4 120.3 91 4.43 2.140 16.7 0 1 5 2
3 30.4 4 95.1 113 3.77 1.513 16.9 1 1 5 2
4 15.8 8 351.0 264 4.22 3.170 14.5 0 1 5 4
5 19.7 6 145.0 175 3.62 2.770 15.5 0 1 5 6
mpg cyl disp hp drat wt qsec vs am gear carb
1 15.0 8 301 335 3.54 3.57 14.6 0 1 5 8
2 21.4 4 121 109 4.11 2.78 18.6 1 1 4 2
# 关闭查询句柄
> dbClearResult(rs)
4.6 预编译参数使用
通过dbBind可以使用预编译参数,防止SQL注入,也是需要用到dbSendQuery()的延迟查询,通过dbFetch()来获得数据。
> rs <- dbSendQuery(conn, 'SELECT * FROM mtcars WHERE mpg < :x')
> dbBind(rs, params = list(x = 15))
> dbFetch(rs)
mpg cyl disp hp drat wt qsec vs am gear carb
1 14.3 8 360 245 3.21 3.570 15.84 0 0 3 4
2 10.4 8 472 205 2.93 5.250 17.98 0 0 3 4
3 10.4 8 460 215 3.00 5.424 17.82 0 0 3 4
4 14.7 8 440 230 3.23 5.345 17.42 0 0 3 4
5 13.3 8 350 245 3.73 3.840 15.41 0 0 3 4
> dbClearResult(rs)
我们可以进行多参数绑定查询,查询mpg在20到30之间以0.2为间隔的数据。
> rs <- dbSendQuery(conn, 'SELECT * FROM mtcars WHERE mpg = :x')
> dbBind(rs, params = list(x = seq(20, 30, by = 0.2)))
> dbFetch(rs)
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
4 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
5 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
6 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
7 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
8 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
> dbClearResult(rs)
> dbDisconnect(conn)
RSQLite的使用起来是非常简单地,这样我们可以避免小应用每次都需要安装数据库,一个独立的数据库文件什么都能做,轻巧简单!
转载请注明出处:
http://blog.fens.me/r-rsqlite/