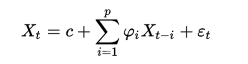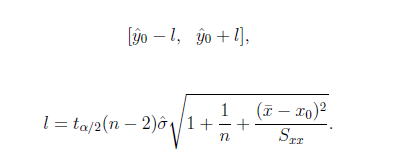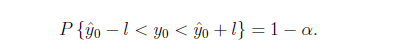架构师的信仰系列文章,主要介绍我对系统架构的理解,从我的视角描述各种软件应用系统的架构设计思想和实现思路。
从程序员开始,到架构师一路走来,经历过太多的系统和应用。做过手机游戏,写过编程工具;做过大型Web应用系统,写过公司内部CRM;做过SOA的系统集成,写过基于Hadoop的大数据工具;做过外包,做过电商,做过团购,做过支付,做过SNS,也做过移动SNS。以前只用Java,然后学了PHP,现在用R和Javascript。最后跳出IT圈,进入金融圈,研发量化交易软件。
架构设计就是定义一套完整的程序规范,坚持架构师的信仰,做自己想做的东西。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/certificate-ai900/

前言
刚考完AZ-900的考试,还在感叹Azure生态的强大,不管是架构上和还是功能上的。本来想休息一下,现在又有了新的契机,可以继续完成AI-900的认证课程。虽然AI-900的课程还是属于入门级的,却能让我更多的了解微软的产品体系和产品规划的思路,我觉得比实际做具体的代码开发,或者功能实现更有意义。关于AZ-900的考试详细介绍,请参考文章AZ-900认证考试攻略。
坚持学习,顺利通过考试。
目录
- 考试契机
- 学习路径
- 复习准备
1. 考试契机
为了参加智子学院的“MCP导师认证计划”,以微软认证专家的身份,为企业提供技术咨询服务。智子学院要求参与者必须在1个自然月内完成AI-900 Azure AI Fundamentals的认证考试,同时智子学陆院免费提供考试券。有了这样的一个要求,自然地就开始了学习的过程。
客观地说,微软的Azure相关技术体系确实庞大,如果没有深入去学习这些知识,真的无从下手用微软产品。而且更难得的是,微软的docs文档条理清楚,每个技术点都有详细的介绍,不仅有技术细节,架构的描述,还有从社会意义角度的说明,真是非常有心。让我学习在过程中,不仅是知识的学习,还有对于产品规划的认识。
微软认证体系:
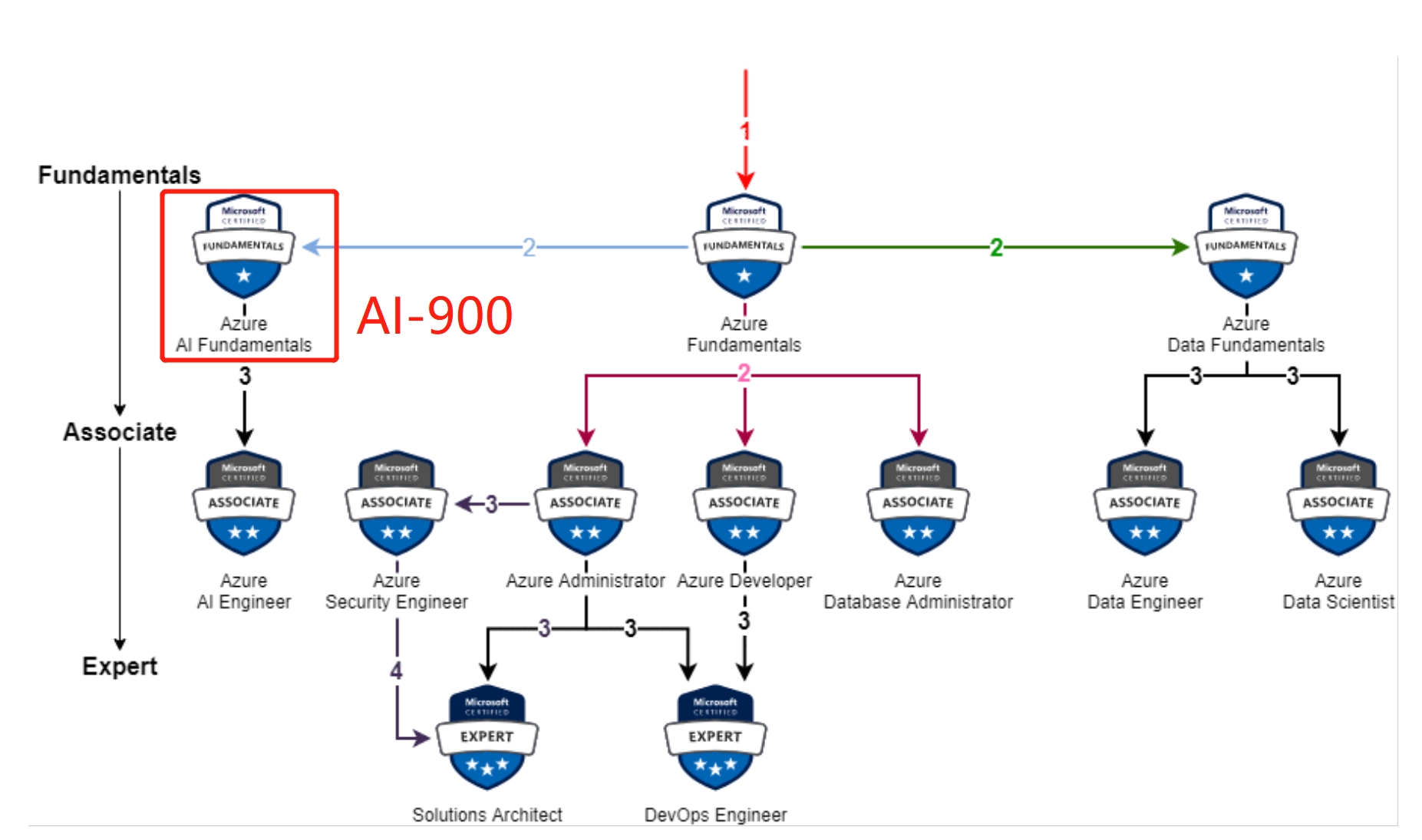
考试完成后,会获得一份考试能力评估表,来告诉你哪部分做的好,哪部分做的不好。我考试的能力评估表:我考了830分(700通过),总体来说还是不错的成绩。

最后,就获得的证书电子版的证书 Microsoft Certified: Azure AI Fundamentals。

2. 学习路径
Microsoft Certified: Azure AI Fundamentals ,AI-900认证考试是Azure AI的基础使用的认证,包括机器学习和深度学习等智能算法,在结构化数据、图片、文字和语音的应用,主要涉及5大部分内容。
- 描述 AI 工作负荷和注意事项
- 描述 Azure 上机器学习的基本原理
- 描述 Azure 上的计算机视觉工作负荷的功能
- 描述 Azure上自然语言处理(NLP)工作负荷的特性
- 描述 Azure 上的对话式 AI 工作负荷的功能
微软docs上,给出了AI-900完整的学习路径,https://docs.microsoft.com/zh-cn/learn/certifications/azure-ai-fundamentals
学习大纲
第一部分:描述 AI 工作负荷和注意事项
人工智能 (AI) 为令人惊异的新的解决方案和体验赋能,Microsoft Azure 提供了易用的服务来帮助你入门。
- 1.1 Azure 上的 AI 入门
第二部分:描述 Azure 上机器学习的基本原理
机器学习是人工智能的核心,很多新式应用程序和服务都依赖于预测机器学习模型。 了解如何使用 Azure 机器学习在不编写代码的情况下创建和发布模型。
- 2.1 使用 Azure 机器学习中的自动化机器学习
- 2.2 使用 Azure 机器学习设计器创建回归模型
- 2.3 使用 Azure 机器学习设计器创建分类模型
- 2.4 使用 Azure 机器学习设计器创建聚类分析模型
第三部分:描述 Azure 上的计算机视觉工作负荷的功能
计算机视觉是人工智能 (AI) 的一个领域,在该领域中,软件系统旨在通过摄像头、图像和视频以可视方式感知这个世界。 AI 工程师和数据科学家可以通过混合使用自定义机器学习模型和平台即服务 (PaaS) 解决方案(包括 Microsoft Azure 中的众多认知服务),来解决多种特定类型的计算机视觉问题。
- 3.1 使用计算机视觉服务分析图像
- 3.2 使用自定义视觉服务对图像进行分类
- 3.3 使用自定义视觉服务检测图像中的对象
- 3.4 使用人脸服务检测和分析人脸
- 3.5 使用计算机视觉服务读取文本
- 3.6 利用“表单识别器”服务分析收据
第四部分:描述 Azure上自然语言处理(NLP)工作负荷的功能
自然语言处理功能支持能看到用户、听到用户的声音、与用户交谈和理解用户的意图的应用程序。 凭借文本分析、翻译和语言理解服务,Microsoft Azure 让你能够轻松构建支持自然语言的应用程序。
- 4.1 使用文本分析服务分析文本
- 4.2 识别和合成语音
- 4.3 翻译文本和语音
- 4.4 使用“语言理解”创建语言模型
第五部分:描述 Azure 上的对话式 AI 工作负荷的功能
对话式 AI 是一种人工智能工作负载,它可处理 AI 代理与人类用户之间的对话。
- 5.1 使用 QnA Maker 和 Azure 机器人服务构建机器人
学习的内容很有意思,与我目前的工作有大量的交集。我们在用R语言进行独立开发和实现的,也可以通过本次的学习,看看如果能利用微软的产品,来完成复杂的机器学习的任务。
3. 复习准备
虽然,微软docs已经有了完整的学习大纲,真学起来还是要花点时间的,重点就在于名词解释。没想到在Azure AI里体系里,定义这么多的产品和新名词。虽然我已经用过了各种云的服务和产品,但对于全面的AI产品也并不是太了解,所以借着这次考认证,正好是全面的学习。
Azure机器学习算法备忘单,用于Azure的机器学习设计器,Azure 机器学习包含来自分类、推荐系统、聚类、异常检测、回归和文本分析系列的大型算法库。每个都旨在解决不同类型的机器学习问题。
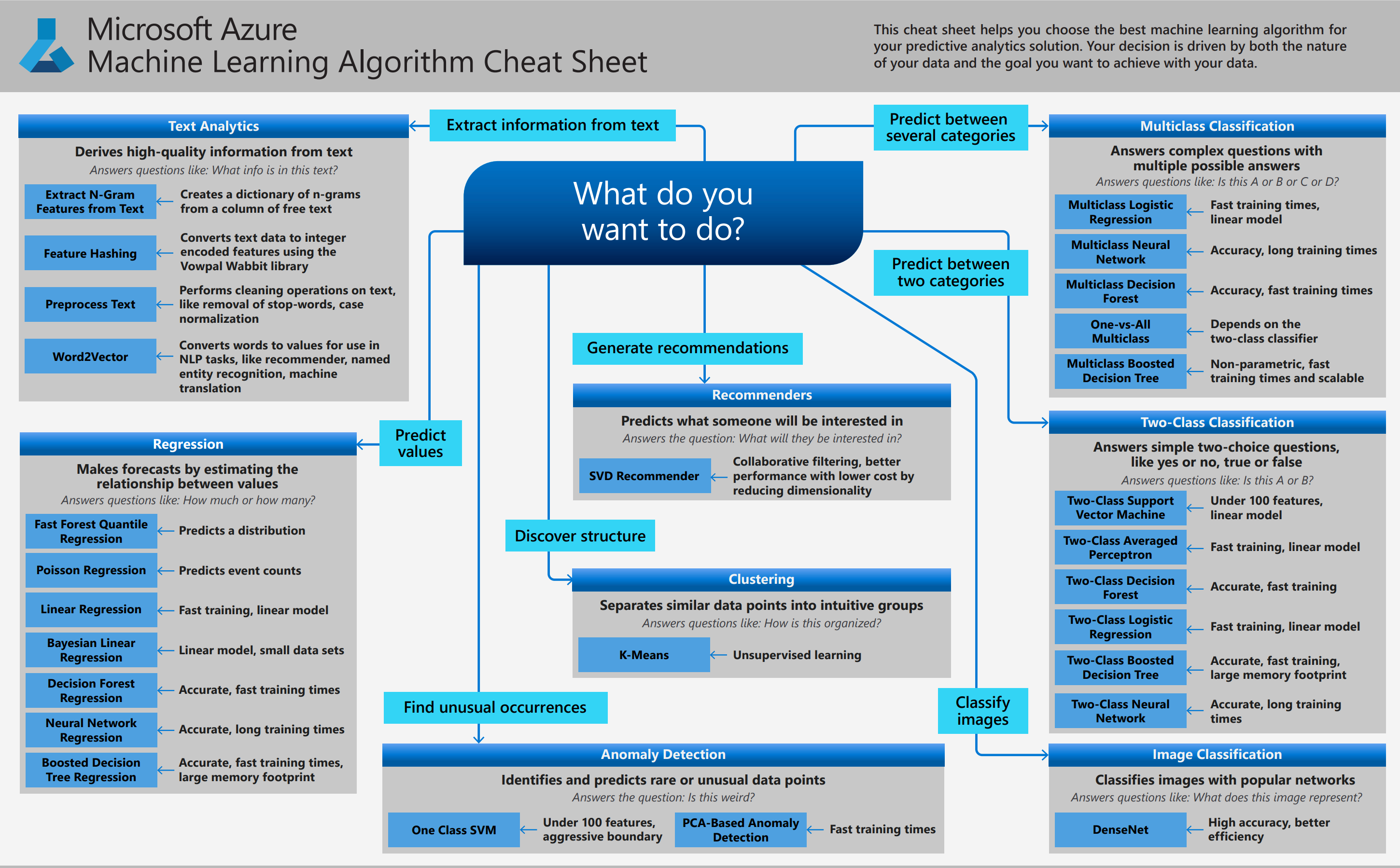
3.1 名字解释
下面开始,名词解释:
Azure Machine Learning designer,Azure机器学习设计器使您可以在交互式画布上直观地连接数据集和模块,以创建机器学习模型。
Resource: Pipelines,Datasets,Compute resources,Registered models,Published pipelines,Real-time endpoints
可以使用的云资源: 计算实例:数据科学家可用于处理数据和模型的开发工作站。 计算群集:用于按需处理试验代码的可扩展虚拟机群集。 推理群集:使用已训练模型的预测服务的部署目标。
Computer Vision :基于云的Computer Vision API使开发人员可以访问用于处理图像和返回信息的高级算法。通过上传图像或指定图像URL,Microsoft Computer Vision算法可以根据输入和用户选择以不同方式分析视觉内容。通过快速入门,教程和示例,学习如何以不同的方式分析视觉内容。
Azure Custom Vision用户自定义图像识别服务,可让您构建,部署和改进自己的图像标识符。图像标识符根据图像的视觉特征将标签(代表类或对象)应用于图像。与Computer Vision服务不同,Custom Vision允许您指定标签并训练自定义模型以检测它们。
Facial recognition: 将面部识别功能嵌入到您的应用中,以提供无缝且高度安全的用户体验。 不需要机器学习专业知识。 功能包括:人脸检测,可感知图像中的人脸和属性; 与您最多100万人的私人存储库中的个人匹配的个人标识; 感知到的情感识别,可以检测到各种面部表情,例如幸福,轻蔑,中立和恐惧; 以及图像中相似面孔的识别和分组。
Optical Character recognition(OCR): 光学字符识别,该功能可从图像中提取打印或手写的文本。您可以从图像中提取文本,例如车牌照片或带有序列号的容器,以及文档(发票,账单,财务报告,物品等)中的文本。
Object detection : 对象检测类似于标记,但是API返回找到的每个对象的边界框坐标(以像素为单位)。例如,如果图像包含狗,猫和人,则“检测”操作将列出这些对象及其在图像中的坐标。 您可以使用此功能来处理图像中对象之间的关系。 它还使您可以确定图像中是否存在同一标签的多个实例。
Text Analytics:一种AI服务,可在非结构化文本中发现洞察力,例如情感,实体和关键短语
Natural Language Processing(NLP):自然语言处理(NLP)用于执行诸如情感分析,主题检测,语言检测,关键词提取和文档分类之类的任务。NLP可用于对文档进行分类,例如将文档标记为敏感或垃圾邮件。 NLP的输出可用于后续处理或搜索。 NLP的另一个用途是通过识别文档中存在的实体来汇总文本。 这些实体还可以用于用关键字标记文档,从而可以基于内容进行搜索和检索。 实体可以合并为主题,摘要描述每个文档中存在的重要主题。 检测到的主题可以用于对文档进行分类以进行导航,或者在给定所选主题的情况下枚举相关文档。 NLP的另一种用途是对文本进行情感评分,以评估文档的正面或负面基调。
Key phrase extraction : 关键短语提取技能可评估非结构化文本,并为每条记录返回关键短语列表。
Named Entity Recognition(NER): 命名实体识别(NER)是在文本中标识不同实体并将其分类为预定义类或类型的能力,例如:人员,位置,事件,产品和组织。
Sentiment Analysis:情感分析功能,可评估文本并返回每个句子的情感分数和标签。 这对于检测社交媒体,客户评论,论坛等中的正面和负面情绪很有用。
Translator:转换器是基于云的机器翻译服务,并且是用于构建智能应用程序的Azure认知服务认知API系列的一部分。 转换器易于集成到您的应用程序,网站,工具和解决方案中。 它使您可以添加70多种语言的多语言用户体验,并且可以在具有任何操作系统的任何硬件平台上用于文本翻译。
Language Detection:语言检测技能可检测输入文本的语言,并针对请求提交的每个文档报告一个语言代码。 语言代码与指示分析强度的分数配对。
Speech recognition and speech synthesis:语音识别和合成样本,语音识别确实是一种令人称奇的人类能力,尤其是当您认为正常对话需要每秒识别10到15个音素时。事实证明,尝试制造机器(计算机)识别系统很困难。另一方面,各种语音合成系统已经使用了一段时间。尽管功能有限且通常缺乏人类语音的自然质量,但这些系统现在已成为我们生活中的常见组成部分。
Classification : 分类,是一种机器学习方法,它使用数据来确定项目或数据行的类别,类型或类别。 例如,您可以使用分类来:将电子邮件过滤器分类为垃圾邮件,垃圾邮件或良品。确定患者的实验室样本是否癌变。根据客户对销售活动的响应倾向对其进行分类,确定情绪是正面还是负面。
Regression : 回归,是一种广泛用于从工程到教育的领域的方法。 例如,您可以使用回归来基于区域数据来预测房屋的价值,或者创建有关未来入学人数的预测。
Clustering: 聚类,是一种将数据点分组为相似聚类的方法。
Cross-Validate Model: 交叉验证模型模块将带有标签的数据集以及未经训练的分类或回归模型作为输入。 它将数据集划分为一定数量的子集(折叠),在每个折叠上构建模型,然后为每个折叠返回一组准确性统计信息。 通过比较所有折痕的准确性统计信息,您可以解释数据集的质量并了解模型是否易受数据变化的影响。
Anomaly Detection: 异常检测,包含机器学习中的许多重要任务:确定潜在的欺诈交易。指示已发生网络入侵的学习模式。寻找异常患者群。检查输入到系统中的值。根据定义,异常是罕见事件,因此很难收集代表性的数据样本用于建模,可通过使用不平衡的数据集来解决构建和训练模型的核心挑战。
QnA Makter :QnA Maker。 该认知服务支持创建和发布具有内置自然语言处理功能的知识库。可轻松在您的数据上创建自然的对话层。 它可用于从您的自定义知识库(KB)信息中为任何给定的自然语言输入找到最合适的答案。使用此认知服务,你可以快速构建一个可以问答知识库,用它构成用户和 AI 代理之间对话的基础。
Azure Bot Service: 专为机器人开发而构建的托管服务
Conversation AI: 会话式AI是计算中的下一个用户界面(UI)浪潮。 我们已经从必须学习和适应计算机的世界演变为现在正在学习如何理解和与我们互动的计算机。 与计算机的自然交互从语言,语音和语义理解开始,并通过支持丰富的多模型交互而继续。
Language Understand (LUIS), 语言理解(LUIS)是基于云的对话式AI服务,将定制的机器学习智能应用于用户的对话式自然语言文本,以预测整体含义并提取相关的详细信息。LUIS的客户端应用程序是任何以自然语言与用户通信以完成任务的会话应用程序。客户端应用程序的示例包括社交媒体应用程序,AI聊天机器人和启用语音的桌面应用程序。
Text Analytics一种AI服务,可在非结构化文本中发现洞察力,例如情感,实体和关键短语。
Ink Recognizer: 一种AI服务,可识别数字墨水内容,例如手写,形状和墨水文档布局。
Form Recognizer: 由AI驱动的文档提取服务可以理解您的表格。
Cortana: Cortana是Microsoft的个人生产力助手,可以帮助您节省时间并将精力集中在最重要的事情上。
Principles for Responsible AI:指导AI开发和使用的六项原则:公平性,可靠性和安全性,隐私性和安全性,包容性,透明度和问责制。
- Fairness: 公平性,人工智能系统应公平对待每个人,并避免以不同方式影响处境相似的人群。例如,假设你创建了一个机器学习模型来为银行的贷款审批应用程序提供支持。 该模型应在不考虑任何基于性别、种族或其他因素的偏见的情况下,对是否应批准贷款做出预测,这些偏见可能导致特定的申请人群遭受不公平的差别待遇。
- Reliability and safety: 可靠性和保障性,AI 系统应可靠且安全地运行。 例如,大家思考一下基于 AI 的自动驾驶软件系统,或诊断患者症状并推荐处方的机器学习模型这些案例。 这些系统一旦出现不可靠性,就可能会给生命安全带来重大风险。
- Privacy and security:隐私性和安全性,AI 系统应该保护并尊重隐私。 AI 系统所基于的机器学习模型依赖于大量数据,这些数据可能包含必须保密的个人详细信息。 即使对模型进行了训练且系统已投入生产,它仍可能在使用新数据进行预测或采取行动时侵犯隐私或安全。
- Inclusiveness,包容性,包容性设计实践可以帮助系统开发人员理解和解决产品环境中可能无意排除人员的潜在障碍。 AI 系统应该成为人们的有力助手,并与人互动。 AI 应不分身体能力、性别、性取向、种族或其他因素,造福社会各个阶层。
- Transparency, 透明度,透明度的关键部分是我们所说的可理解性,即对AI系统及其组件的行为的有用解释。要提高清晰度,就要求利益相关者理解其工作方式和原因,以便识别潜在的性能问题,安全和隐私问题,偏见,排他性做法或意想不到的结果。AI 系统应该是可理解的。 应让用户能充分了解系统的用途、工作方式以及局限性。
- Accountability,问责制,设计和部署AI系统的人员必须对其系统的运行方式负责。组织应借鉴行业标准来制定问责制规范。应有相关人员对 AI 系统负责。 设计和开发基于 AI 的解决方案的人员应在管理和组织原则的框架内工作,以确保解决方案符合定义明确的道德和法律标准。
Azure Kubernetes Service (AKS):Azure Kubernetes服务(AKS)使在Azure中部署托管Kubernetes群集变得简单。 AKS通过将大部分责任转移给Azure来降低管理Kubernetes的复杂性和运营开销。作为托管的Kubernetes服务,Azure可为您处理关键任务,例如运行状况监视和维护。 Kubernetes母版由Azure管理。您仅管理和维护代理节点。实时节点必须部署在AKS集群上。
3.2 模拟考试
整理完上面的名词解释,准备工作就算到位了,最后就是找份模拟题练练手。由于AI-900的认证考试是近期刚推出的,所以网上没有太多的复习资料,也没有什么攻略。
我发现的免费模拟题只有CertBolt网站上提供了,可以用 CertBolt Microsoft AI-900 模拟题库,共有55道题目。另外,在qubits42网站上有20模拟题,链接已经不能访问了。我整理成了AI模拟题PDF文件供大家下载,练习一下也就够用了。
毕竟是初级认证,考试都是基础知识,按照微软的文档进行复习准备,大概率都是可以通过的,本文的目的也是帮助大家准备考试,做到心中有底。
3.3 现场考试
最后,就是按照约好的时间,去考试中心完成考试,要带2种证明身份的证件。进到考场后,包要存起来,不能带任何东西,不能吃东西,不能喝水,不能与其他人说话等等,可以提前交卷。交卷后,找工作人员,拿到考试评估单,就可以回家庆祝了。与AZ-900的现场考试流程一样,大家可以参考文章AZ-900认证考试攻略。
本文主要是记录一下考试的前后经历,对于IT的小伙伴们,考个认证系统地学习知识,还是很有用的。未来的成就,都是之前的积累,爆发就在未来的某个瞬间。祝大家考试顺利!
刚刚又获得一张免费考试券,下一个要考啥呢!微软会一直从知识上面鞭策我们学习。
转载请注明出处:
http://blog.fens.me/certificate-ai900/