R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-zoo/
前言
时间序列分析是一种动态数据处理的统计方法,通过对时间序列数据的分析,我们可以感觉到世界正改变着什么!R语言作为统计分析的利器,对时间序列处理有着强大的支持。在R语言中,单独为时间序列数据定义了一种数据类型zoo,zoo是时间序列的基础,也是股票分析的基础。
本文将介绍zoo库在R语言中的结构和使用。
目录
- zoo介绍
- zoo安装
- zoo的API介绍
- zoo使用
1. zoo介绍
zoo是一个R语言类库,zoo类库中定义了一个名为zoo的S3类型对象,用于描述规则的和不规则的有序的时间序列数据。zoo对象是一个独立的对象,包括索引、日期、时间,只依赖于基础的R环境,zooreg对象继承了zoo对象,只能用于规则的的时间序列数据。
R语言的其他程序包,都是以zoo, zooreg为时间序列数据的基础!
zoo的项目主页:http://zoo.r-forge.r-project.org/
2. zoo安装
系统环境
- Win7 64bit
- R: 3.0.1 x86_64-w64-mingw32/x64 b4bit
zoo安装
~ R
> install.packages("zoo")
> library(zoo)
3. zoo的API介绍
基础对象
- zoo: 有序的时间序列对象
- zooreg: 规则的的时间序列对象,继承zoo对象
类型转换
- as.zoo: 把一个对象转型为zoo类型
- plot.zoo: 为plot函数,提供zoo的接口
- xyplot.zoo: 为lattice的xyplot函数,提供zoo的接口
- ggplot2.zoo: 为ggplot2包,提供zoo的接口
数据操作
- coredata: 获得和修改zoo的数据部分
- index: 获得和修改zoo的索引部分
- window.zoo: 按时间过滤数据
- merge.zoo: 合并多个zoo对象
- read.zoo: 从文件读写zoo序列
- aggregate.zoo: 计算zoo数据
- rollapply: 对zoo数据的滚动处理
- rollmean: 对zoo数据的滚动,计算均值
NA值处理
- na.fill: NA值的填充
- na.locf: 替换NA值
- na.aggregate: 计算统计值替换NA值
- na.approx: 计算插值替换NA值
- na.StructTS: 计算seasonal Kalman filter替换NA值
- na.trim: 过滤有NA的记录
辅助工具
- is.regular: 检查是否是规则的序列
- lag.zoo: 计算步长和分差
- MATCH: 取交集
- ORDER: 值排序,输出索引
显示控制
- yearqtr: 以年季度显示时间
- yearmon: 以年月显示时间
- xblocks: 作图沿x轴分隔图型
- make.par.list: 用于给plot.zoo 和 xyplot.zoo 数据格式转换
- 1). zoo函数
- 2). zooreg函数
- 3). zoo的类型转换
- 4). ggplot2画时间序列
- 5). 数据操作
- 6). 数据滚动处理
- 7). NA值处理
- 8). 数据显示格式
- 9). 按时间分隔做衅
- 10). 从文件读入zoo序列
4. zoo使用
1). zoo函数
zoo对象包括两部分组成,数据部分、索引部分。
函数定义:
zoo(x = NULL, order.by = index(x), frequency = NULL)参数列表:
- x: 数据部分,允许向量,矩阵,因子
- order.by: 索引部分,唯一字段,用于排序
- frequency: 每个时间单元显示的数量
构建一个zoo对象,以时间为索引
> x.Date <- as.Date("2003-02-01") + c(1, 3, 7, 9, 14) - 1
> x.Date
[1] "2003-02-01" "2003-02-03" "2003-02-07" "2003-02-09" "2003-02-14"
> class(x.Date)
[1] "Date"
> x <- zoo(rnorm(5), x.Date)
> x
2003-02-01 2003-02-03 2003-02-07 2003-02-09 2003-02-14
0.01964254 0.03122887 0.64721059 1.47397924 1.29109889
> class(x)
[1] "zoo"
> plot(x)
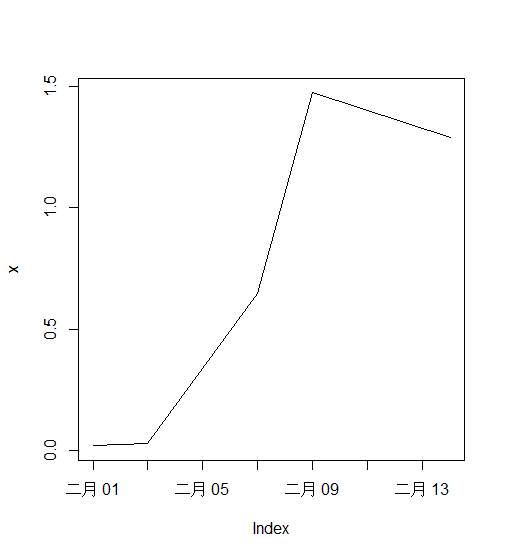
以数学为索引的,多组时间序列
> y <- zoo(matrix(1:12, 4, 3),0:30)
> y
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
4 1 5 9
5 2 6 10
6 3 7 11
7 4 8 12
8 1 5 9
9 2 6 10
10 3 7 11
> plot(y)
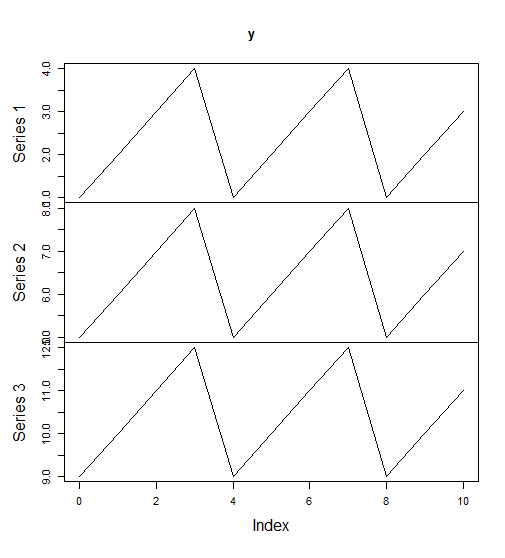
2). zooreg函数
函数定义:
zooreg(data, start = 1, end = numeric(), frequency = 1,
deltat = 1, ts.eps = getOption("ts.eps"), order.by = NULL)参数列表:
- data: 数据部分,允许向量,矩阵,因子
- start: 时间部分,开始时间
- end: 时间部分,结束时间
- frequency: 每个时间单元显示的数量
- deltat: 连续观测之间的采样周期的几分之一,不能与frequency同时出现,例如1/2
- ts.eps: 时间序列间隔,在时间间隔大于ts.eps时认为是相等的。通过getOption(“ts.eps”)设置,默认是1e-05
- order.by: 索引部分,唯一字段,用于排序, 继承zoo的order.by
构建一个zooreg对象
> zooreg(1:10, frequency = 4, start = c(1959, 2))
1959(2) 1959(3) 1959(4) 1960(1) 1960(2) 1960(3) 1960(4) 1961(1) 1961(2)
1 2 3 4 5 6 7 8 9
1961(3)
10
> as.zoo(ts(1:10, frequency = 4, start = c(1959, 2)))
1959(2) 1959(3) 1959(4) 1960(1) 1960(2) 1960(3) 1960(4) 1961(1) 1961(2)
1 2 3 4 5 6 7 8 9
1961(3)
10
> zr<-zooreg(rnorm(10), frequency = 4, start = c(1959, 2))
> plot(zr)
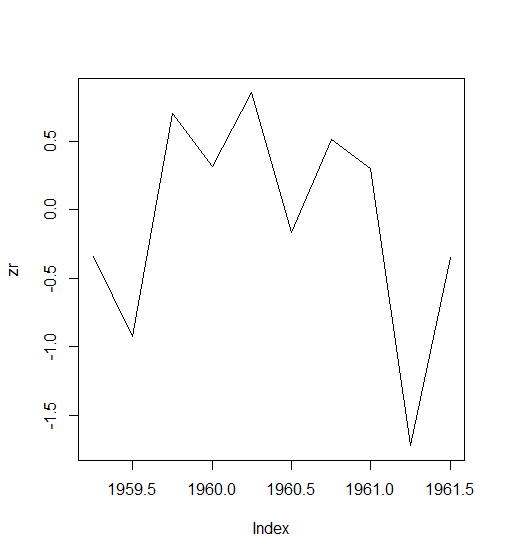
3). zoo的类型转换
转型到zoo类型
> as.zoo(rnorm(5))
1 2 3 4 5
-0.4892119 0.5740950 0.7128003 0.6282868 1.0289573
> as.zoo(ts(rnorm(5), start = 1981, freq = 12))
1981(1) 1981(2) 1981(3) 1981(4) 1981(5)
2.3198504 0.5934895 -1.9375893 -1.9888237 1.0944444
从zoo类型转型到其他类型
> x <- as.zoo(ts(rnorm(5), start = 1981, freq = 12))
> x
1981(1) 1981(2) 1981(3) 1981(4) 1981(5)
1.8822996 1.6436364 0.1260436 -2.0360960 -0.1387474
> as.matrix(x)
x
1981(1) 1.8822996
1981(2) 1.6436364
1981(3) 0.1260436
1981(4) -2.0360960
1981(5) -0.1387474
> as.vector(x)
[1] 1.8822996 1.6436364 0.1260436 -2.0360960 -0.1387474
> as.data.frame(x)
x
1981(1) 1.8822996
1981(2) 1.6436364
1981(3) 0.1260436
1981(4) -2.0360960
1981(5) -0.1387474
> as.list(x)
[[1]]
1981(1) 1981(2) 1981(3) 1981(4) 1981(5)
1.8822996 1.6436364 0.1260436 -2.0360960 -0.1387474
4). ggplot2画时间序列
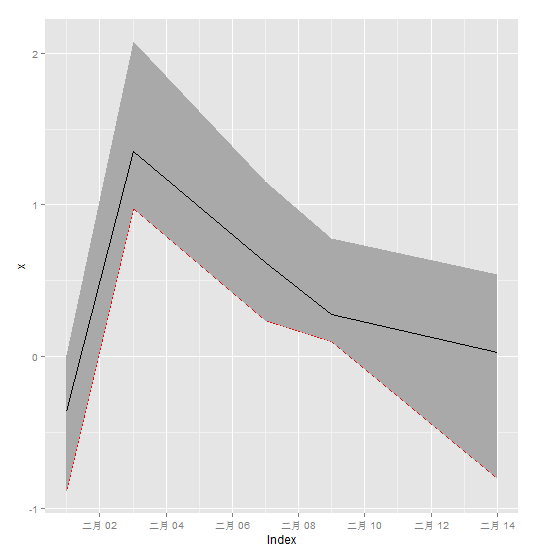
ggplot2::fortify函数,通过zoo::ggplot2.zoo函数,转换成ggplot2可识别的类型。
library(ggplot2)
library(scales)
x.Date <- as.Date(paste(2003, 02, c(1, 3, 7, 9, 14), sep = "-"))
x <- zoo(rnorm(5), x.Date)
xlow <- x - runif(5)
xhigh <- x + runif(5)
z <- cbind(x, xlow, xhigh)
g<-ggplot(aes(x = Index, y = Value), data = fortify(x, melt = TRUE))
g<-g+geom_line()
g<-g+geom_line(aes(x = Index, y = xlow), colour = "red", data = fortify(xlow))
g<-g+geom_ribbon(aes(x = Index, y = x, ymin = xlow, ymax = xhigh), data = fortify(x), fill = "darkgray")
g<-g+geom_line()
g<-g+xlab("Index") + ylab("x")
g
> z
x xlow xhigh
2003-02-01 -0.36006612 -0.88751958 0.006247816
2003-02-03 1.35216617 0.97892538 2.076360524
2003-02-07 0.61920828 0.23746410 1.156569424
2003-02-09 0.27516116 0.09978789 0.777878867
2003-02-14 0.02510778 -0.80107410 0.541592929
5). 数据操作
修改zoo的数据部分coredata
> x.date <- as.Date(paste(2003, rep(1:4, 4:1), seq(1,20,2), sep = "-"))
> x <- zoo(matrix(rnorm(20), ncol = 2), x.date)
> coredata(x)
[,1] [,2]
[1,] -1.04571765 0.92606273
[2,] -0.89621126 0.03693769
[3,] 1.26938716 -1.06620017
[4,] 0.59384095 -0.23845635
[5,] 0.77563432 1.49522344
[6,] 1.55737038 1.17215855
[7,] -0.36540180 -1.45770721
[8,] 0.81655645 0.09505623
[9,] -0.06063478 0.84766496
[10,] -0.50137832 -1.62436453
> coredata(x) <- matrix(1:20, ncol = 2)
> x
2003-01-01 1 11
2003-01-03 2 12
2003-01-05 3 13
2003-01-07 4 14
2003-02-09 5 15
2003-02-11 6 16
2003-02-13 7 17
2003-03-15 8 18
2003-03-17 9 19
2003-04-19 10 20
修改zoo的索引部分index
> x.date <- as.Date(paste(2003, rep(1:4, 4:1), seq(1,20,2), sep = "-"))
> x <- zoo(matrix(rnorm(20), ncol = 2), x.date)
> index(x)
[1] "2003-01-01" "2003-01-03" "2003-01-05" "2003-01-07" "2003-02-09"
[6] "2003-02-11" "2003-02-13" "2003-03-15" "2003-03-17" "2003-04-19"
> index(x) <- 1:nrow(x)
> index(x)
[1] 1 2 3 4 5 6 7 8 9 10
按时间过滤数据window.zoo
> x.date <- as.Date(paste(2003, rep(1:4, 4:1), seq(1,20,2), sep = "-"))
> x <- zoo(matrix(rnorm(20), ncol = 2), x.date)
> window(x, start = as.Date("2003-02-01"), end = as.Date("2003-03-01"))
2003-02-09 0.7021167 -0.3073809
2003-02-11 2.5071111 0.6210542
2003-02-13 -1.8900271 0.1819022
> window(x, index = x.date[1:6], start = as.Date("2003-02-01"))
2003-02-09 0.7021167 -0.3073809
2003-02-11 2.5071111 0.6210542
> window(x, index = x.date[c(4, 8, 10)])
2003-01-07 1.4623515 -1.198597
2003-03-15 -0.5898128 1.318401
2003-04-19 -0.4209979 -1.648222
合并多个zoo对象merge.zoo
> y1 <- zoo(matrix(1:10, ncol = 2), 1:5)
> y2 <- zoo(matrix(rnorm(10), ncol = 2), 3:7)
> merge(y1, y2, all = FALSE)
y1.1 y1.2 y2.1 y2.2
3 3 8 0.9514985 1.7238941
4 4 9 -1.1131230 -0.2061446
5 5 10 0.6169665 -1.3141951
> merge(y1, y2, all = FALSE, suffixes = c("a", "b"))
a.1 a.2 b.1 b.2
3 3 8 0.9514985 1.7238941
4 4 9 -1.1131230 -0.2061446
5 5 10 0.6169665 -1.3141951
> merge(y1, y2, all = TRUE)
y1.1 y1.2 y2.1 y2.2
1 1 6 NA NA
2 2 7 NA NA
3 3 8 0.9514985 1.7238941
4 4 9 -1.1131230 -0.2061446
5 5 10 0.6169665 -1.3141951
6 NA NA 0.5134937 0.0634741
7 NA NA 0.3694591 -0.2319775
> merge(y1, y2, all = TRUE, fill = 0)
y1.1 y1.2 y2.1 y2.2
1 1 6 0.0000000 0.0000000
2 2 7 0.0000000 0.0000000
3 3 8 0.9514985 1.7238941
4 4 9 -1.1131230 -0.2061446
5 5 10 0.6169665 -1.3141951
6 0 0 0.5134937 0.0634741
7 0 0 0.3694591 -0.2319775
计算zoo数据aggregate.zoo
> x.date <- as.Date(paste(2004, rep(1:4, 4:1), seq(1,20,2), sep = "-"))
> x <- zoo(rnorm(12), x.date); x
2004-01-01 2004-01-03 2004-01-05 2004-01-07 2004-02-09 2004-02-11
0.67392868 1.95642526 -0.26904101 -1.24455152 -0.39570292 0.09739665
2004-02-13 2004-03-15 2004-03-17 2004-04-19
-0.23838695 -0.41182796 -1.57721805 -0.79727610
> x.date2 <- as.Date(paste(2004, rep(1:4, 4:1), 1, sep = "-")); x.date2
[1] "2004-01-01" "2004-01-01" "2004-01-01" "2004-01-01" "2004-02-01"
[6] "2004-02-01" "2004-02-01" "2004-03-01" "2004-03-01" "2004-04-01"
> x2 <- aggregate(x, x.date2, mean); x2
2004-01-01 2004-02-01 2004-03-01 2004-04-01
0.2791904 -0.1788977 -0.9945230 -0.7972761
6). 数据滚动处理
对zoo数据的滚动处理rollapply
> z <- zoo(11:15, as.Date(31:35))
> rollapply(z, 2, mean)
1970-02-01 1970-02-02 1970-02-03 1970-02-04
11.5 12.5 13.5 14.5
等价操作:rollapply , aggregate
> z2 <- zoo(rnorm(6))
> rollapply(z2, 3, mean, by = 3) # means of nonoverlapping groups of 3
2 5
-0.3065197 0.6350963
> aggregate(z2, c(3,3,3,6,6,6), mean) # same
3 6
-0.3065197 0.6350963
等价操作:rollapply, rollmean
> rollapply(z2, 3, mean) # uses rollmean which is optimized for mean
2 3 4 5
-0.3065197 -0.7035811 -0.1672344 0.6350963
> rollmean(z2, 3) # same
2 3 4 5
-0.3065197 -0.7035811 -0.1672344 0.6350963
7). NA值处理
NA填充na.fill
> z <- zoo(c(NA, 2, NA, 3, 4, 5, 9, NA))
> z
1 2 3 4 5 6 7 8
NA 2 NA 3 4 5 9 NA
> na.fill(z, "extend")
1 2 3 4 5 6 7 8
2.0 2.0 2.5 3.0 4.0 5.0 9.0 9.0
> na.fill(z, c("extend", NA))
1 2 3 4 5 6 7 8
2 2 NA 3 4 5 9 9
> na.fill(z, -(1:3))
1 2 3 4 5 6 7 8
-1 2 -2 3 4 5 9 -3
NA替换na.locf
> z <- zoo(c(NA, 2, NA, 3, 4, 5, 9, NA, 11));z
1 2 3 4 5 6 7 8 9
NA 2 NA 3 4 5 9 NA 11
> na.locf(z)
2 3 4 5 6 7 8 9
2 2 3 4 5 9 9 11
> na.locf(z, fromLast = TRUE)
1 2 3 4 5 6 7 8 9
2 2 3 3 4 5 9 11 11
统计值替换NA值na.aggregate
> z <- zoo(c(1, NA, 3:9),
+ c(as.Date("2010-01-01") + 0:2,
+ as.Date("2010-02-01") + 0:2,
+ as.Date("2011-01-01") + 0:2))
> z
2010-01-01 2010-01-02 2010-01-03 2010-02-01 2010-02-02 2010-02-03 2011-01-01
1 NA 3 4 5 6 7
2011-01-02 2011-01-03
8 9
> na.aggregate(z)
2010-01-01 2010-01-02 2010-01-03 2010-02-01 2010-02-02 2010-02-03 2011-01-01
1.000 5.375 3.000 4.000 5.000 6.000 7.000
2011-01-02 2011-01-03
8.000 9.000
> na.aggregate(z, as.yearmon)
2010-01-01 2010-01-02 2010-01-03 2010-02-01 2010-02-02 2010-02-03 2011-01-01
1 2 3 4 5 6 7
2011-01-02 2011-01-03
8 9
> na.aggregate(z, months)
2010-01-01 2010-01-02 2010-01-03 2010-02-01 2010-02-02 2010-02-03 2011-01-01
1.0 5.6 3.0 4.0 5.0 6.0 7.0
2011-01-02 2011-01-03
8.0 9.0
> na.aggregate(z, format, "%Y")
2010-01-01 2010-01-02 2010-01-03 2010-02-01 2010-02-02 2010-02-03 2011-01-01
1.0 3.8 3.0 4.0 5.0 6.0 7.0
2011-01-02 2011-01-03
8.0 9.0
计算插值替换NA值
> z <- zoo(c(2, NA, 1, 4, 5, 2), c(1, 3, 4, 6, 7, 8));z
1 3 4 6 7 8
2 NA 1 4 5 2
> na.approx(z)
1 3 4 6 7 8
2.000000 1.333333 1.000000 4.000000 5.000000 2.000000
> na.approx(z, 1:6)
1 3 4 6 7 8
2.0 1.5 1.0 4.0 5.0 2.0
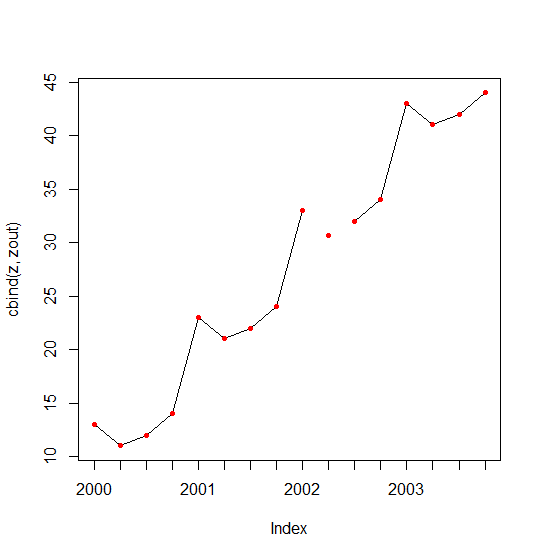
计算seasonal Kalman filter替换NA值
z <- zooreg(rep(10 * seq(4), each = 4) + rep(c(3, 1, 2, 4), times = 4),
start = as.yearqtr(2000), freq = 4)
z[10] <- NA
zout <- na.StructTS(z);zout
plot(cbind(z, zout), screen = 1, col = 1:2, type = c("l", "p"), pch = 20)
过滤有NA的行
> xx <- zoo(matrix(c(1, 4, 6, NA, NA, 7), 3), c(2, 4, 6));xx
2 1 NA
4 4 NA
6 6 7
> na.trim(xx)
6 6 7
8). 数据显示格式
以年+季度格式输出
> x <- as.yearqtr(2000 + seq(0, 7)/4)
> x
[1] "2000 Q1" "2000 Q2" "2000 Q3" "2000 Q4" "2001 Q1" "2001 Q2" "2001 Q3"
[8] "2001 Q4"
> format(x, "%Y Quarter %q")
[1] "2000 Quarter 1" "2000 Quarter 2" "2000 Quarter 3" "2000 Quarter 4"
[5] "2001 Quarter 1" "2001 Quarter 2" "2001 Quarter 3" "2001 Quarter 4"
> as.yearqtr("2001 Q2")
[1] "2001 Q2"
> as.yearqtr("2001 q2")
[1] "2001 Q2"
> as.yearqtr("2001-2")
[1] "2001 Q2"
以年+月份格式输出
> x <- as.yearmon(2000 + seq(0, 23)/12)
> x
[1] "一月 2000" "二月 2000" "三月 2000" "四月 2000" "五月 2000"
[6] "六月 2000" "七月 2000" "八月 2000" "九月 2000" "十月 2000"
[11] "十一月 2000" "十二月 2000" "一月 2001" "二月 2001" "三月 2001"
[16] "四月 2001" "五月 2001" "六月 2001" "七月 2001" "八月 2001"
[21] "九月 2001" "十月 2001" "十一月 2001" "十二月 2001"
> as.yearmon("mar07", "%b%y")
[1] NA
> as.yearmon("2007-03-01")
[1] "三月 2007"
> as.yearmon("2007-12")
[1] "十二月 2007"
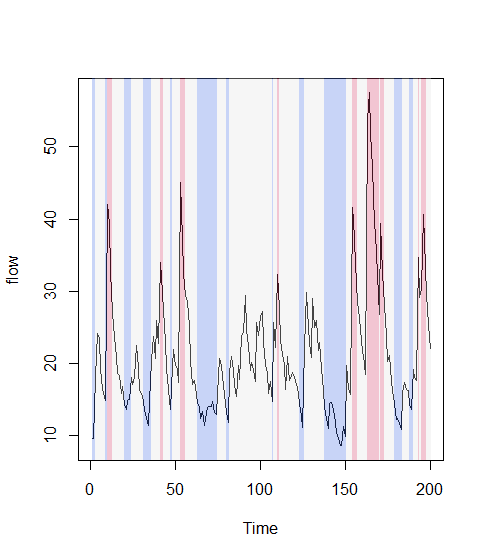
9). 按时间分隔线
使用xblock函数, 以不同的颜色划分3个区间(-Inf,15),[15,30],(30,Inf)
set.seed(0)
flow <- ts(filter(rlnorm(200, mean = 1), 0.8, method = "r"))
rgb <- hcl(c(0, 0, 260), c = c(100, 0, 100), l = c(50, 90, 50), alpha = 0.3)
plot(flow)
xblocks(flow > 30, col = rgb[1]) ## high values red
xblocks(flow < 15, col = rgb[3]) ## low value blue
xblocks(flow >= 15 & flow <= 30, col = rgb[2]) ## the rest gray
10). 从文件读入zoo序列
创建文件:read.csv
~ vi read.csv
2003-01-01,1.0073644,0.05579711
2003-01-03,-0.2731580,0.06797239
2003-01-05,-1.3096795,-0.20196174
2003-01-07,0.2225738,-1.15801525
2003-02-09,1.1134332,-0.59274327
2003-02-11,0.8373944,0.76606538
2003-02-13,0.3145168,0.03892812
2003-03-15,0.2222181,0.01464681
2003-03-17,-0.8436154,-0.18631697
2003-04-19,0.4438053,1.40059083
读文件并生成zoo序列
> r <- read.zoo(file="read.csv",sep = ",", format = "%Y-%m-%d")
> r
V2 V3
2003-01-01 1.0073644 0.05579711
2003-01-03 -0.2731580 0.06797239
2003-01-05 -1.3096795 -0.20196174
2003-01-07 0.2225738 -1.15801525
2003-02-09 1.1134332 -0.59274327
2003-02-11 0.8373944 0.76606538
2003-02-13 0.3145168 0.03892812
2003-03-15 0.2222181 0.01464681
2003-03-17 -0.8436154 -0.18631697
2003-04-19 0.4438053 1.40059083
> class(r)
[1] "zoo"
我们已经完全掌握了zoo库及zoo对象的使用,接下来就可以放手去用R处理时间序列了!
转载请注明出处:
http://blog.fens.me/r-zoo/

这个总结的太好了,xblock 那个蛮好用,以前还没注意到呢。
最近做R服务端接口,基础库有好多要整理啊!!!你好像现在每篇文章都看呢?!
恩,你总结得很好啊,必须每篇都看一看。
[…] 本文是继R语言zoo时间序列基础库的扩展实现。看上去简单的时间序列,内藏复杂的规律。zoo作为时间序列的基础库,是面向通用的设计,可以用来定义股票数据,也可以分析天气数据。但由于业务行为的不同,我们需要更多的辅助函数,来帮助我们更高效的完成任务。 […]
非常好,比英文帮助文档好多了,请教博主一个问题,
eur class(eur)
[1] “data.frame”
> e<-as.xts(eur)
错误于as.POSIXlt.character(x, tz, …) :
character string is not in a standard unambiguous format
想把数据转换成xts烈类型为什么总会报错
as.POSIXlt.character(x, tz, …) :字符串的日期格式,不能被自动转型。
参考这篇文章转型xts
http://blog.fens.me/r-xts/
看了一下帮助文档,其中日期格式EXCEL不能生成”2001-02-03″ and “2001/02/03″类型的,我用origin,但是还是报错
as.POSIXlt(eur,origin = “2014-01-02″, tz=”UTC”)
错误于as.POSIXlt.default(eur, origin = “2014-01-02”, tz = “UTC”) :
不知如何将’eur’转换成“POSIXlt”类别
[…] R语言本身提供了丰富的金融函数工具包,quantmod包就是最常用的一个,另外还要配合时间序列包zoo和xts,指标计算包TTR,可视包ggplot2等一起使用。关于zoo包和xts包的详细使用可以参考文章R语言时间序列基础库zoo,可扩展的时间序列xts。 […]
张老师,这个包,能构造时间序列,画出图像,那么关键的是怎么像TSA包那样做时间序列分析呢?zoo对象如果能转成ts对象就好了
zoo只是提供基本数据结构的功能,分析要用别的包来做。zoo和ts应该可以互换吧。
请教一下,我想让时间的X轴输出如Fri,Sat,Sun这样的缩写,不想输出为周五、周六、周日这样的X轴刻度。需要怎么修改。我的系统是win7中文,R是英文的。
重画X坐标轴就行了,有对应的API。
[…] R语言本身提供了丰富的金融函数工具包,时间序列包zoo和xts,指标计算包TTR,数据处理包plyr,可视包ggplot2等,我们会一起使用这些工具包来完成建模、计算和可视化的工作。关于zoo包和xts包的详细使用可以参考文章,R语言时间序列基础库zoo,可扩展的时间序列xts。 […]
[…] R语言本身提供了丰富的金融函数工具包,时间序列包zoo和xts,指标计算包TTR,数据处理包plyr,可视包ggplot2等,我们会一起使用这些工具包来完成建模、计算和可视化的工作。关于zoo包和xts包的详细使用可以参考文章,R语言时间序列基础库zoo,可扩展的时间序列xts。 […]
怎么画出分钟间隔的时间序列呢
用XTS包,按分钟分组。
http://blog.fens.me/r-xts/
具体怎么做呢?要得出股票一年的交易时间(按5min为间隔)
[…] R语言时间序列基础库zoo […]