从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可以帮助我们迅速建立web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站,个性化网站,我们自己的Geek网站!!
关于作者
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/nodejs-crawler-douban/

目录:
- 类库介绍
- win7安装jquery – 失败
- ubuntu安装jQuery – 成功
- 豆瓣爬虫
1. 类库介绍
1. web项目,基于express3, ejs模板
2. 通过request抓取网页
3. 通过jQuery, jsdom, htmlparser提取网页内容
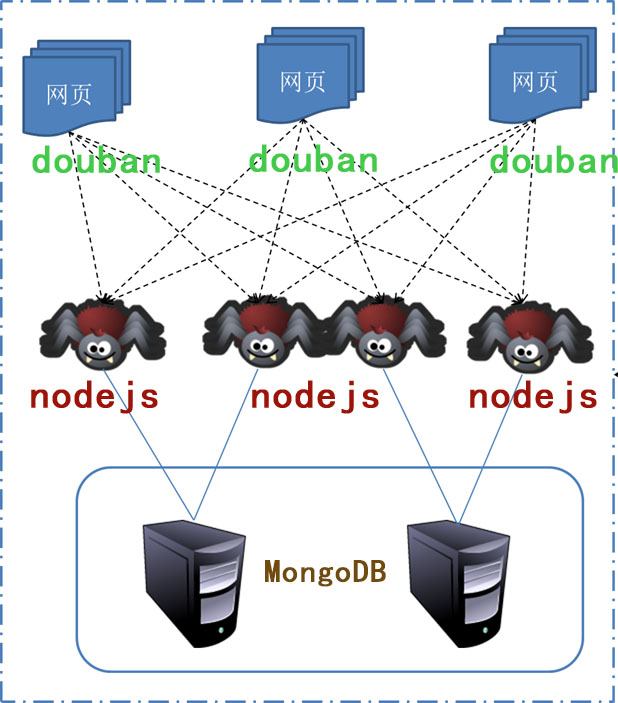
2. win7安装node-jquery – 失败
由于win7安装node-jquery的包报错,直接改成ubuntu下开发。
Ubuntu的Nodejs安装请参考:准备Nodejs开发环境Ubuntu
~ npm install jquery
D:\workspace\project\moiveme\node_modules\jquery\node_modules\contextify>node "D:\toolkit\nodejs\node_modules\npm\bin\no
de-gyp-bin\\..\..\node_modules\node-gyp\bin\node-gyp.js" rebuild
npm http 304 https://registry.npmjs.org/cssom
npm http GET https://registry.npmjs.org/cssom/-/cssom-0.2.5.tgz
npm http 304 https://registry.npmjs.org/request
npm http 304 https://registry.npmjs.org/cssstyle
npm http GET https://registry.npmjs.org/cssstyle/-/cssstyle-0.2.3.tgz
npm http GET https://registry.npmjs.org/request/-/request-2.21.0.tgz
npm http 200 https://registry.npmjs.org/cssom/-/cssom-0.2.5.tgz
npm http 200 https://registry.npmjs.org/request/-/request-2.21.0.tgz
npm http 200 https://registry.npmjs.org/cssstyle/-/cssstyle-0.2.3.tgz
C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\Microsoft.Cpp.InvalidPlatform.Targets(23,7): error MSB8007: 项目“cont
ex
tify.vcxproj”的平台无效。平台为“x64”。您会看到此消息的可能原因是,您尝试在没有解决方案文件的情况下生成项目,并且为此
项目指定了并不存在的非默认平台。 [D:\workspace\project\moiveme\node_
modules\jquery\node_modules\contextify\build\contextify.vcxproj]
gyp ERR! build error
gyp ERR! stack Error: `C:\Windows\Microsoft.NET\Framework\v4.0.30319\msbuild.exe` failed with exit code: 1
gyp ERR! stack at ChildProcess.onExit (D:\toolkit\nodejs\node_modules\npm\node_modules\node-gyp\lib\build.js:267:23)
gyp ERR! stack at ChildProcess.EventEmitter.emit (events.js:98:17)
gyp ERR! stack at Process.ChildProcess._handle.onexit (child_process.js:784:12)
gyp ERR! System Windows_NT 6.1.7601
gyp ERR! command "node" "D:\\toolkit\\nodejs\\node_modules\\npm\\node_modules\\node-gyp\\bin\\node-gyp.js" "rebuild"
gyp ERR! cwd D:\workspace\project\moiveme\node_modules\jquery\node_modules\contextify
gyp ERR! node -v v0.10.5
gyp ERR! node-gyp -v v0.9.5
gyp ERR! not ok
npm ERR! weird error 1
npm ERR! not ok code 0
3. ubuntu安装node-jquery
ubuntu安装node-jquery还是有一些安装过程中的问题
- jsdom的依赖版本问题
- jQuery非jquery,两个包一字之差,其实是不一样的。
~ sudo npm install jsdom
安装可能会有错误,jsdom依赖的问题。修改packages.json文件,指定jsdom版本。
~ vi packages.json
"dependencies": {
"jsdom" : "https://github.com/tmpvar/jsdom/tarball/4cf155a1624b3fb54b2eec536a0c060ec1bab4ab"
}
继续安装依赖包,这里请使用jQuery包,不要用jquery会有错误。
~ sudo npm install jQuery
~ sudo npm install xmlhttprequest
~ sudo npm install request
~ sudo npm install htmlparser
安装完成。
4. 豆瓣爬虫
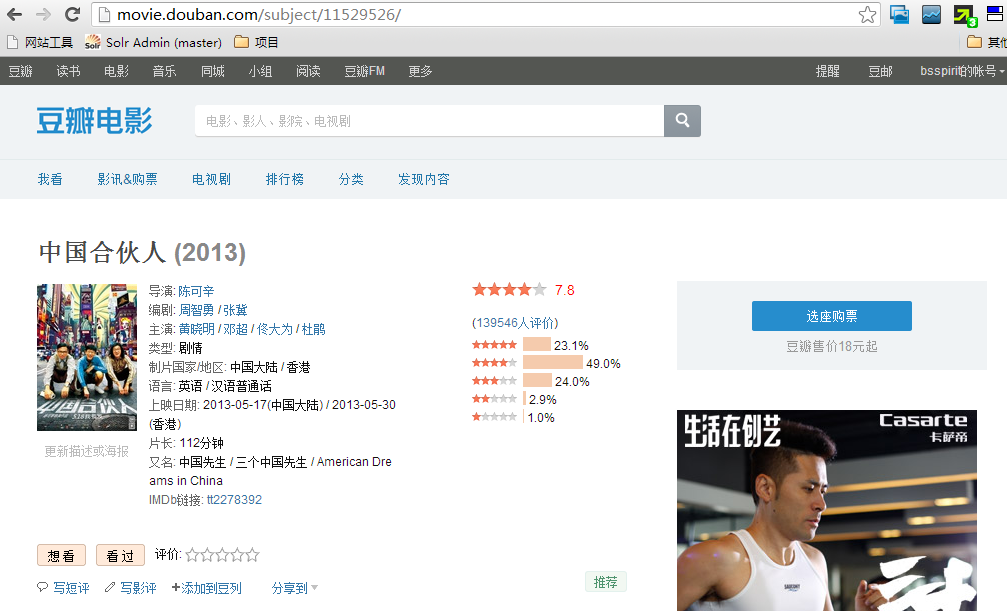
设计场景:对豆瓣电影进行爬取。
http://movie.douban.com/subject/11529526/
项目目录:
~ pwd
/home/conan/workspace/nodejs/nodejs-demo
~ ll
drwxr-xr-x 6 conan conan 4096 Jun 6 18:02 ./
drwxrwxr-x 4 conan conan 4096 Jun 6 14:19 ../
-rw-rw-r-- 1 conan conan 842 Jun 6 14:19 app.js
drwxr-xr-x 10 conan conan 4096 Jun 6 18:01 node_modules/
-rw-rw-r-- 1 conan conan 283 Jun 6 16:44 package.json
drwxr-xr-x 5 conan conan 4096 Jun 6 14:19 public/
drwxr-xr-x 2 conan conan 4096 Jun 6 15:59 routes/
drwxr-xr-x 2 conan conan 4096 Jun 6 14:19 views/
增加myUtil.js文件
~ vi myUtil.js
var MyUtil = function () {
};
var http = require('http');
var request = require('request');
MyUtil.prototype.get=function(url,callback){
request(url, function (error, response, body) {
if (!error && response.statusCode == 200) {
callback(body,response.statusCode);
}
})
}
module.exports = new MyUtil();
修改控制器 routes/index.js
~ vi routes/index.js
var myUtil = require('../myUtil.js');
var $ = require('jQuery');
exports.index = function(req, res){
var url="http://movie.douban.com/subject/11529526";
console.log(url);
myUtil.get(url,function(content,status){
console.log("status:="+status);
res.send(content);
});
};
这里我们已经把content内容,输出到了本地程序里。
打开浏览器:http://192.168.1.104:3000
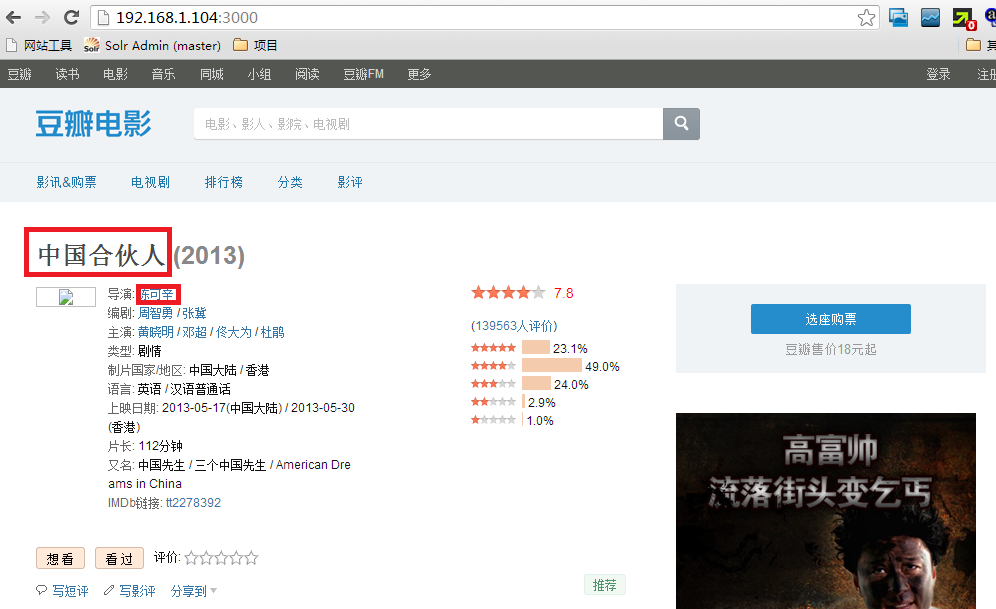
用jQuery提出红色的文字:
~ vi routes/index.js
var myUtil = require('../myUtil.js');
var $ = require('jQuery');
exports.index = function(req, res){
var url="http://movie.douban.com/subject/11529526";
console.log(url);
myUtil.get(url,function(content,status){
console.log("status:="+status);
var movie={}
movie.name = $(content).find('span[property="v:itemreviewed"]').text();
movie.director = $(content).find('#info span:nth-child(1) a').text();
console.log(movie);
res.send(content);
});
};
查看server的日志输出
http://movie.douban.com/subject/11529526
status:=200
{ name: '中国合伙人', director: '陈可辛' }
GET / 200 4480ms - 72.55kb
通过jQuery的xpath,我们很容易分析出“电影名”和“导演”的字段。
用Nodejs写爬虫代码几有短短几行,比起JAVA动一下就千行的代码量来说,让我们轻松了很多。
效率上,终于可以达到以1人顶100人的目的了。
希望我的介绍对你用处。
转载请注明出处:
http://blog.fens.me/nodejs-crawler-douban/

cool
So Cool!
这只是一部具体的电影,如何体现爬?有没有demo可以看?
后面工作,我没有写出来,并不难!
1. 建个URL列表 ,写个循环就行,读网页。
2. 提取电影数据,存储数据库。
3. 提取网页的URL,补充URL列表
4. 反复操作第二步
没有demo,等有时间再写吧。
这个真是不错,这个爬虫做的我感觉好爽啊,比情人节干别的爽啊
程序员就要有热情。呵呵。
你知道你在说什么吗?
如果使用request & cheerio这两个模块也挺方便的
是的,cheerio更方便一些,request则有点底层。
cheerio确实更方便,win下jquery安装太操蛋了
是的,我也是这么折腾过来的。
Hi,为啥我抓取到的影片名称跟导演是乱码呢?
我是在linux,你如果在win中有可能乱码,自己配置一下字符集。
Error: jQuery requires a window with a document
同遇到这个问题,不管是jQery还是jquery都需要一个叫jsdom的包里的createWindow函数,但这个包没有。
jsdom比较重,而且需要依赖于window底层的库,已经不建议使用了,换成cheerio。
cheerio好用啊,不需要python的环境了。
🙂
没有调度器,没有容错机制。根本不叫爬虫。就是一个几行代码实现的下载器而已。
http://git.oschina.net/dreamidea/neocrawler
真正的nodejs爬虫
本文只是爬虫的一部分,我有时间看看你说的爬虫。
你这个爬虫我高不来啊。
想想,我的爬虫需求,不需要很频繁的爬数据,准备用此文的思路自己做一个了。
你提供的这个项目,我研究了半天,不会用。哎。
windows 系统可以安装成功。
版本信息:Win8.1 系统,node 0.10.29, npm 1.4.14
jsdom比较重,现在都倾向于用cheerio
cheerio依赖jQuery吗?
已转到cheerio,谢了
cheerio感觉很方便,跟jquery用法差不了多少
大牛我有一个地方不解啊。用js做爬虫不会涉及跨域问题吗?
node.js是后台应用,运行在服务器上而不是浏览器里,没有跨域问题。
原来如此。
我用你的代码爬别的网页都没有问题,唯独这两个url不行:http://blog.designashirt.com
http://photos.designashirt.com
没有收到任何响应,而这两个页面确实是存在的,您知道这可能是什么地方的问题吗?
哦,看到了,输出了response.statusCode, 看到了403。知道问题再哪了。
多谢大牛上面的解释!
问题解决了,在request中加上headers:{’User-Agent’: ‘request’},即request({url:url, headers: {‘User-Agent’: ‘request’}}, function (error, response, body) {}),就可以了。
🙂
问一下,用cheerio 抓取 JS动态生成的页面时如何处理。正常的页面抓取都没问题了,遇到那种ajax或者JS生成的页面就抓取不到?大神问问如何解决
找一个webkit引擎,先把页面渲染了再抓
感谢大神,问问有实例参考吗?
google搜索 node webkit spider有很多的结果。比如:http://phantomjs.org/
对于node来说,可以用node-phantom库
https://www.npmjs.com/package/node-phantom
为什么我什么东西都没有 是空的 没有抓下来
楼主写的好赞!
分享一个免费好用的云端爬虫开发平台
http://www.shenjianshou.cn/