RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析。Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来替代Java的MapReduce实现。有了RHadoop可以让广大的R语言爱好者,有更强大的工具处理大数据1G, 10G, 100G, TB, PB。 由于大数据所带来的单机性能问题,可能会一去不复返了。
RHadoop实践是一套系列文章,主要包括”Hadoop环境搭建”,”RHadoop安装与使用”,”R实现MapReduce的协同过滤算法”,”HBase和rhbase的安装与使用”。对于单独的R语言爱好者,Java爱好者,或者Hadoop爱好者来说,同时具备三种语言知识并不容 易。此文虽为入门文章,但R,Java,Hadoop基础知识还是需要大家提前掌握。
关于作者
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-hadoop-book-big-data/

前言
最近的一本新书Big Data Analytics with R and Hadoop是关于R和Hadoop实践的第一本图书,作者Vignesh Prajapati曾经在图书出版的半年前联系过我,通过Google翻译发现了我的博客,希望把其中的1-2个例子放到他的书中。
没想到这本书,经过半年就出版了,作者效率还是挺高的。受Packt Publishing编辑Amol Bhosle委托为本书写个书评,于是就有本篇文章。
目录
- 图书概览
- 图书内容剖析
- 最后总结
1. 图书概览
本书的几个核心点:R,Hadoop, R+Hadoop, 数据分析案例,机器学习算法案例,R的数据访问接口。
我通过一个思维导图来表达。
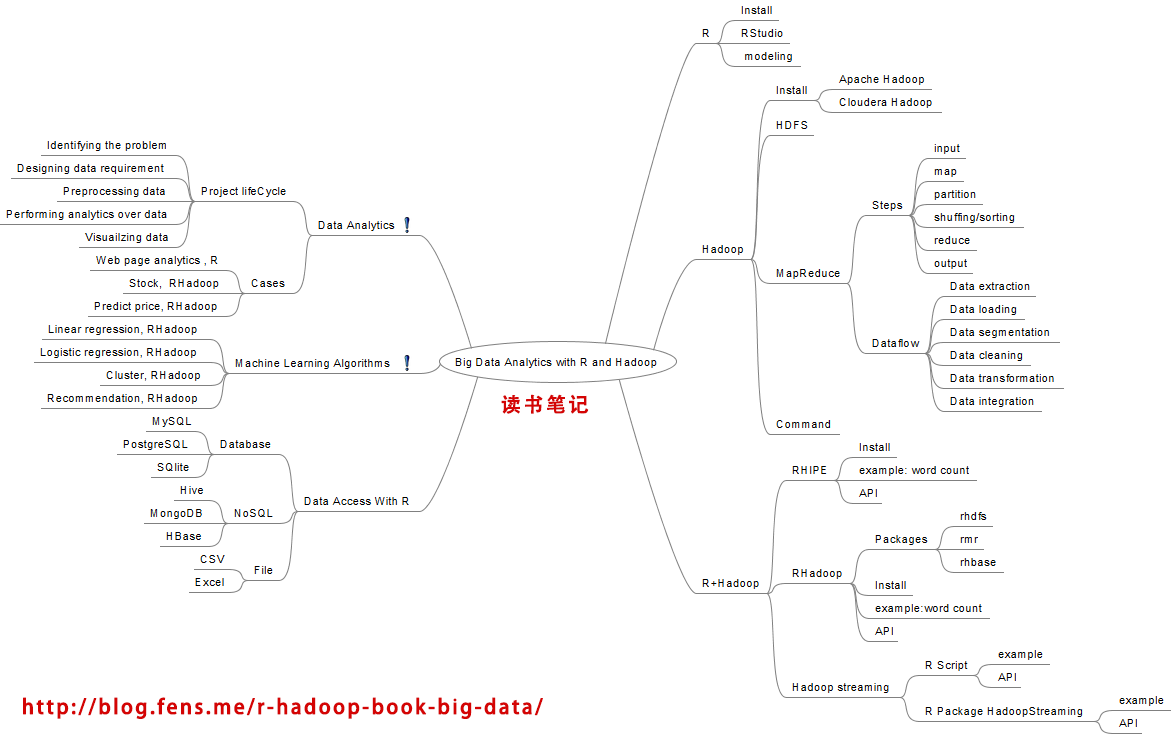
书中最重要的是案例部分,作者分别使用R语言单机实现,以及RHadoop的分步式实现,介绍是多个案例的实践。
2. 图书内容剖析
- R语言介绍
- Hadoop介绍
- R+Hadoop技术方案
- 数据分析案例
- 大数据分析案例
- R语言的数据访问接口
1). R语言介绍
简单地介绍了R安装,RStudio安装,R语言最擅长算法模型:回归,分类,聚类,推荐。
2). Hadoop介绍
主要是介绍了Hadoop安装,在几种不同的Linux系统上,用Apache Hadoop和Cloudera Hadoop二个版本对比安装。
简单介绍了HDFS,dateeode和namenode;讲了MapReduce的工作原理,和用MapReduce对数据处理的过程。
介绍了Hadoop的命令行的使用。
3). R+Hadoop技术方案
作者对于R+Hadoop做了3种技术方案讨论,分别是RHipe, RHadoop, R + Hadoop Streaming。
a. RHipe
RHipe是R与Hadoop的集成编程环境。RHIPE可以让R语言与Hadoop进行通信,访问Hadoop的HDFS和调用MapReduce,让R语言的使用者利用Hadoop的分步式环境进行行大数据的分析。
RHipe官方网站:http://www.datadr.org/
b. RHadoop
RHadoop是由RevolutionAnalytics公司开发的一个R与Hadoop的集成编程环境,与RHipe的功能一样。RHadoop包含三个R包 (rmr,rhdfs,rhbase),分别是对应Hadoop系统架构中的,MapReduce, HDFS, HBase 三个部分。在2013年底,又增加第4个R包plyrmr,用于数据处理操作。本书中并没有涉及plyrmr包。
RHadoop的发布页:https://github.com/RevolutionAnalytics/RHadoop/wiki
RHadoop实践系列文章:http://blog.fens.me/series-rhadoop/
c. R + Hadoop Streaming
Hadoop Streaming是Hadoop提供的,允许任何可执行的脚本作为Mapper和Reducer的一种实现方实。R + Hadoop Streaming就是用R脚本实现Mapper和Reducer。作者用2种方式,进行了测试。
c1. R Script + Hadoop Streaming : 单纯的R语言脚本,通过Shell运行。
c2. HadoopStreaming + Hadoop Streaming: 使用一个封装好的R包HadoopStreaming来实现。
这3种技术方案,是目前R与Hadoop结合实现方案。我对RHadoop和R Script + Hadoop Streaming比较熟悉,经过我测试只有R Script + Hadoop Streaming这种方式,可以用于生产环境,RHadoop性能还是有一些问题的,可以提升的空间还是很大的。书中介绍的另外两种方法,我要有时间,再去试试。不过,我相信R和Hadoop的结合的项目,会越来越多的。
4). 数据分析案例
上面篇幅把技术的基础都说清楚,接下来就是核心案例了,书中介绍了如何使用R结合Hadoop进行数据分析。
首先书中介绍了,一个数据分析项目的框架,包括5个部分。
- 问题
- 定义数据需求
- 数据预处理
- 数据建模及执行
- 数据可视化
然后,作者介绍了3个应用案例。
- 网页分类:把一个网站中的网页按重要性进行排名
- 股票分析:通过历史交易数据计算股票市场的变化
- 价格预测:预测图书销售的价格,来自Kaggle的一道竞赛题
上面3个案例,都使用R和RHadoop进行实现,都是非常不错的案例,可以给我们的学习和使用提供很好的思路。
5). 机器学习算法案例
接下来,作者介绍了用RHadoop实现的基于大数据机器学习算法,充分结合了R和Hadoop的优势。作者把机器学习算法分为3类,监督学习算法,非监督学习算法,推荐算法。
4个算法的案例:
a. 线性回归
最简单的一种回归算法,可以下面公式表示。
y = ax + e 在R语言中,一个函数lm()就可以实现。
在大数据的背景下,利用RHadoop,需要自己实现lm()这个函数。
# Reducer
Sum = function(., YY) keyval(1, list(Reduce('+', YY)))
# XtX =
values(
# For loading hdfs data in to R
from.dfs(
# MapReduce Job to produce XT*X
mapreduce(
input = X.index,
# Mapper – To calculate and emitting XT*X
map =
function(., Xi) {
yi = y[Xi[,1],]
Xi = Xi[,-1]
keyval(1, list(t(Xi) %*% Xi))},
# Reducer – To reduce the Mapper output by performing sum
operation over them
reduce = Sum,
combine = TRUE)))[[1]]
b. Logistic回归
比线性回归稍微复杂一些,可以用公式表示。
logit(p) = β0 + β1 × x1 + β2 × x2 + ... + βn × xn
R程序还是一个函数glm()。
在大数据的背景下,利用RHadoop,需要自己实现glm()这个函数。
# Mapper – computes the contribution of a subset of points to the
gradient.
lr.map =
function(., M) {
Y = M[,1]
X = M[,-1]
keyval(1, Y * X * g(-Y * as.numeric(X %*% t(plane))))
}
# Reducer – Perform sum operation over Mapper output.
lr.reduce = function(k, Z) keyval(k, t(as.matrix(apply(Z,2,sum))))
# MapReduce job – Defining MapReduce function for executing logistic
regression
logistic.regression =
function(input, iterations, dims, alpha){
plane = t(rep(0, dims))
g = function(z) 1/(1 + exp(-z))
for (i in 1:iterations) {
gradient =
values(
from.dfs(
mapreduce(input, map = lr.map, reduce = lr.reduce, combine = T)))
plane = plane + alpha * gradient
}
plane
}
c. 聚类算法
这里介绍的是快速聚类kmeans,聚类属于非监督学习法。
通过R语言现实,一个函数kmeans()就可以完成了。
通过RHadoop现实,就需要自己重写这个迭代过程。
# distance calculation function
dist.fun = function(C, P) {
apply(C,1,function(x) colSums((t(P) - x)^2))
}
# k-Means Mapper
kmeans.map = function(., P) {
nearest = {
# First interations- Assign random cluster centers
if(is.null(C))
sample(1:num.clusters,nrow(P),replace = T)
# Rest of the iterations, where the clusters are assigned # based
on the minimum distance from points
else {
D = dist.fun(C, P)
nearest = max.col(-D)}}
if(!(combine || in.memory.combine))
keyval(nearest, P)
else
keyval(nearest, cbind(1, P))
}
# k-Means Reducer
kmeans.reduce = {
# calculating the column average for both of the conditions
if (!(combine || in.memory.combine) )
function(., P) t(as.matrix(apply(P, 2, mean)))
else function(k, P) keyval(k,t(as.matrix(apply(P, 2, sum))))
}
# k-Means MapReduce – for
kmeans.mr = function(P,num.clusters,num.iter,combine,in.memory.combine) {
C = NULL
for(i in 1:num.iter ) {
C = values(from.dfs(mapreduce(P,map = kmeans.map,reduce = kmeans.reduce)))
if(combine || in.memory.combine)
C = C[, -1]/C[, 1]
if(nrow(C) < num.clusters) {
C =rbind(C,matrix(rnorm((num.clusters -nrow(C)) * nrow(C)),ncol = row(C)) %*% C)
}
}
C
}
d. 推荐算法
这里介绍的是协同过滤算法,算法实现就有点复杂了。主要思想就是:
同现矩阵 * 评分矩阵 = 推荐结果注:由于这个案例出自我的博客,我就直接贴我的文章地址了,也方便中文读者了解算法细节。
R语言的算法实现:http://blog.fens.me/r-mahout-usercf/
RHadoop分步式算法实现:http://blog.fens.me/rhadoop-mapreduce-rmr/
6). R语言的数据访问接口
最后一部分,书中介绍了R语言的各种数据访问接口。
FILE:
- CSV: read.csv(), write.csv()
- Excel: xlsx, xlsxjars,rJava
Database:
- MySQL: RMySQL
- SQLite: RSQLite
- PostgreSQL: RPostgreSQL
NoSQL:
- MongoDB: rmongodb
- Hive: RHive
- HBase: RHBase
补充一下,我的博客中也写了R的数据访问接口的文章。
- MySQL: RMySQL数据库编程指南
- Hive: R利剑NoSQL系列文章 之 Hive
- Redis: R利剑NoSQL系列文章 之 Redis
- Cassandra: R利剑NoSQL系列文章 之 Cassandra
- HBase: RHadoop实践系列之四 rhbase安装与使用
R的多种接口已经打通,这也就说明R已经做好了准备,为工业界带来革命的力量。
3. 最后总结
这是一本不错的图书,从R+Hadoop的角度出发,打开R语言面向大数据应用的思路。这种结合是跨学科碰撞的结果,是市场需求的导向。但由于R+Hadoop还不够成熟,企业级应用依然缺乏成功案例,所以当实施R+Hadoop的应用时,还会碰到非常多的问题。期待有担当的公司和个人,做出被大家认可的产品来。
转载请注明出处:
http://blog.fens.me/r-hadoop-book-big-data/
