无所不能的Java系列文章,涵盖了Java的思想,应用开发,设计模式,程序架构等,通过我的经验去诠释Java的强大。
说起Java,真的有点不知道从何说起。Java是一门全领域发展的语言,从基础的来讲有4大块,Java语法,JDK,JVM,第三方类库。官方又以面向不同应用的角度,又把JDK分为JavaME,JavaSE,JavaEE三个部分。Java可以做客户端界面,可以做中间件,可以做手机系统,可以做应用,可以做工具,可以做游戏,可以做算法…,Java几乎无所不能。
在Java的世界里,Java就是一切。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/linux-java-install/

前言
Java安装应该是件非常简单的事情,不知何时在Oracle官方下载JDK时,竟然强制要求用户登陆。这样就不能通过Linux命令wget下载了,真是有点让人火大。
想了个办法破解这种恶心的cookies验证行为!
目录
- Java在Windows中安装
- Java在Linux Ubuntu中安装
1 Java在Windows中安装
Java环境安装,是指Java开发环境的安装,包括JDK安装和Java的环境配置。在Windows中,很多的Java应用通过JRE就可以运行。但对Java的开发者来说,我们需要安装JDK,必须Oracle SUN官方发布的JDK。
在Windows系统上安装JDK是件非常简单的事情,下载可执行文件(exe),双击即可安装。下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
大家可以下载最新版本的Java SE 8,或者较早的JDK版本。本文中使用的是1.6.0_45版本的JDK。
下载后,双击安装。我安装在目录: D:\toolkit\java\jdk6
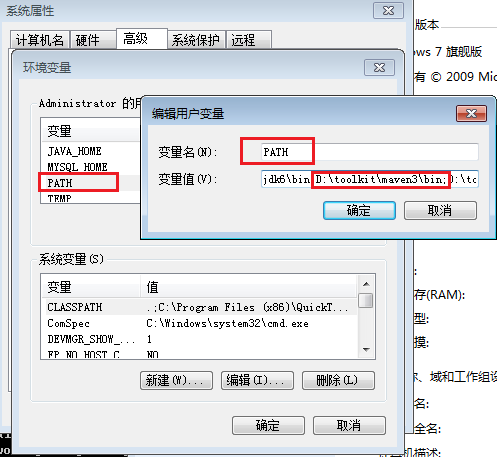
安装好JDK后,配置环境变量:
选择:控制面板 –> 系统和安全 –> 系统属性 –> 高级 –> 环境变量
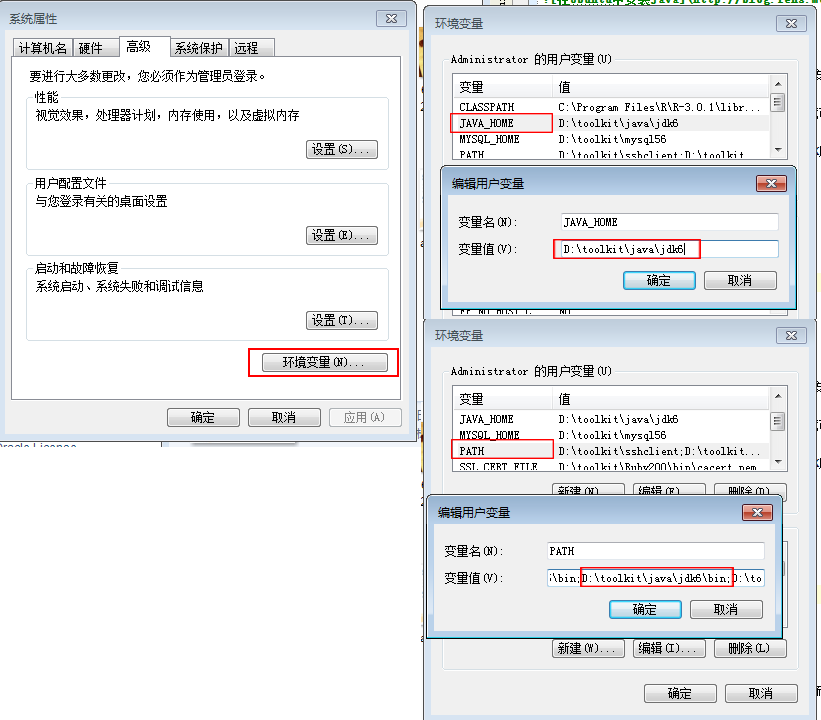
# 新建JAVA_HOME变量
JAVA_HOME=D:\toolkit\java\jdk6
# 新建PATH变量
PATH=D:\toolkit\java\jdk6\bin
注:如果PATH变量已存在,则在最后增加JDK的路径,用分号(;)与上个配置做分隔。
保存后,打开CMD命令窗口,测试Java的命令行操作。
# 查看Java安装版本
~ C:\Users\Administrator>java -version
java version "1.6.0_45"
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
Java HotSpot(TM) 64-Bit Server VM (build 20.45-b01, mixed mode)
# 测试Java命令
~ C:\Users\Administrator>java
Usage: java [-options] class [args...]
(to execute a class)
or java [-options] -jar jarfile [args...]
(to execute a jar file)
where options include:
-server to select the "server" VM
-hotspot is a synonym for the "server" VM [deprecated]
The default VM is server.
-cp
-classpath
A ; separated list of directories, JAR archives,
and ZIP archives to search for class files.
-D=
set a system property
-verbose[:class|gc|jni]
enable verbose output
-version print product version and exit
-version:
require the specified version to run
-showversion print product version and continue
-jre-restrict-search | -jre-no-restrict-search
include/exclude user private JREs in the version search
-? -help print this help message
-X print help on non-standard options
-ea[:...|:]
-enableassertions[:...|:]
enable assertions
-da[:...|:]
-disableassertions[:...|:]
disable assertions
-esa | -enablesystemassertions
enable system assertions
-dsa | -disablesystemassertions
disable system assertions
-agentlib:[=]
load native agent library , e.g. -agentlib:hprof
see also, -agentlib:jdwp=help and -agentlib:hprof=help
-agentpath:[=]
load native agent library by full pathname
-javaagent:[=]
load Java programming language agent, see java.lang.instrument
-splash:
show splash screen with specified image
# 测试Javac命令
~ C:\Users\Administrator>javac
用法:javac <选项> <源文件>
其中,可能的选项包括:
-g 生成所有调试信息
-g:none 不生成任何调试信息
-g:{lines,vars,source} 只生成某些调试信息
-nowarn 不生成任何警告
-verbose 输出有关编译器正在执行的操作的消息
-deprecation 输出使用已过时的 API 的源位置
-classpath <路径> 指定查找用户类文件和注释处理程序的位置
-cp <路径> 指定查找用户类文件和注释处理程序的位置
-sourcepath <路径> 指定查找输入源文件的位置
-bootclasspath <路径> 覆盖引导类文件的位置
-extdirs <目录> 覆盖安装的扩展目录的位置
-endorseddirs <目录> 覆盖签名的标准路径的位置
-proc:{none,only} 控制是否执行注释处理和/或编译。
-processor [,,...]要运行的注释处理程序的名称;绕过默认的搜索进程
-processorpath <路径> 指定查找注释处理程序的位置
-d <目录> 指定存放生成的类文件的位置
-s <目录> 指定存放生成的源文件的位置
-implicit:{none,class} 指定是否为隐式引用文件生成类文件
-encoding <编码> 指定源文件使用的字符编码
-source <版本> 提供与指定版本的源兼容性
-target <版本> 生成特定 VM 版本的类文件
-version 版本信息
-help 输出标准选项的提要
-Akey[=value] 传递给注释处理程序的选项
-X 输出非标准选项的提要
-J<标志> 直接将 <标志> 传递给运行时系统
这样我们就在Windows的系统中,配置好了Java环境。
2 Java在Linux Ubuntu中安装
Java安装,指定的是SUN Oracle官方的JDK软件包,而不是Linux Ubuntu系统中通过apt-get安装的OpenJDK。
注:请一定注意版本,必须使用SUN Oracle官方的JDK软件包
在Linux Ubuntu中,下载并安装JDK,这里我选择安装Java SE 1.6.45的64位版本的JDK。
2.1 下载JDK
不知道Oracle官方网站时候调整的JDK下载需要先登陆,因此直接使用wget命令,无法完成JDK的下载。
我们有下面2种解决方法:
- 1). 从浏览器中登陆下载,然后再传到Linux的服务器
- 2). 用wget命令模拟,浏览器中的用户cookies,进行下载
第一种方式没什么技术含量,不再展开介绍。接下来,使用第二种方式,用wget命令模拟浏览器中的用户cookies。
打开浏览器,登陆Oracle官网,进入Oracle JDK下载页面。把对应的cookies配置后wget后,进行下载。
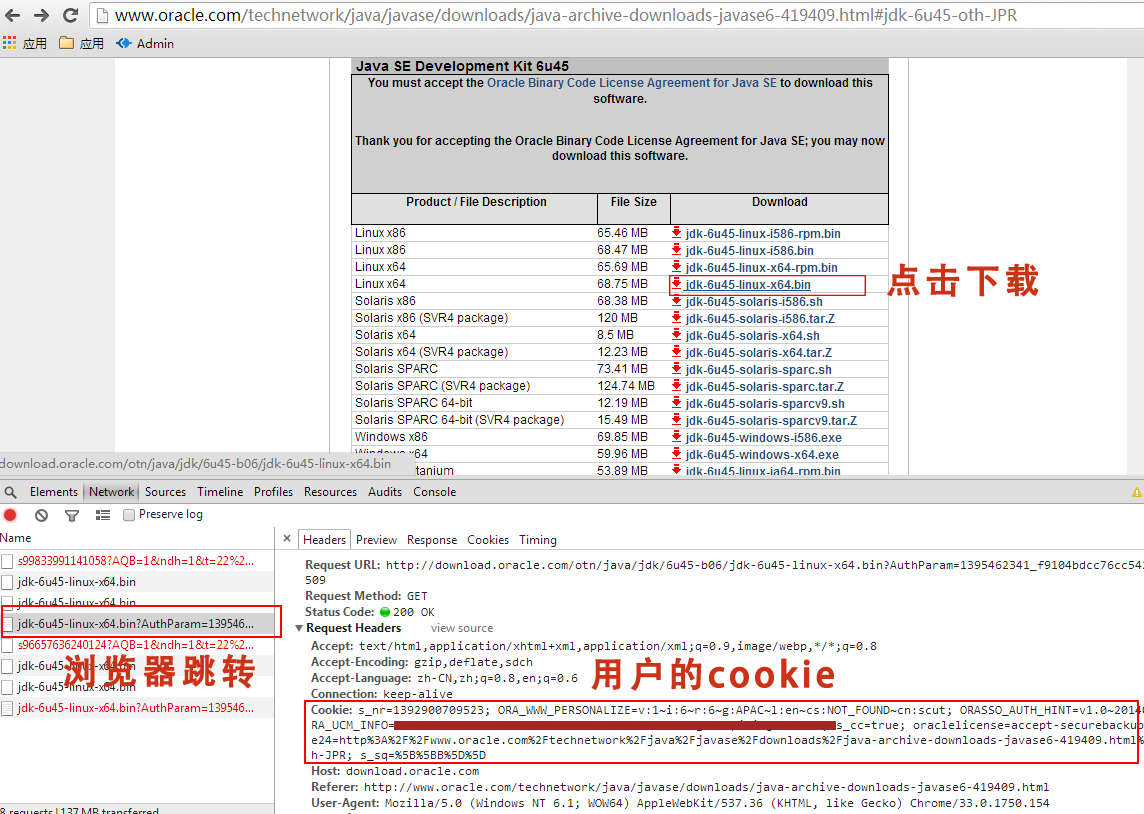
#下载JDK
~ wget --no-check-certificate --no-cookies --header "Cookie: s_nr=1392900709523; ORA_WWW_PERSONALIZE=v:1~i:6~r:6~g:APAC~l:en~cs:NOT_FOUND~cn:scut; ORASSO_AUTH_HINT=v1.0~20140322121132; ORA_UCM_INFO=3~xxxx21212xxxx~xxxx~xxxx~xxxx@163.com; s_cc=true; oraclelicense=accept-securebackup-cookie; gpw_e24=http%3A%2F%2Fwww.oracle.com%2Ftechnetwork%2Fjava%2Fjavase%2Fdownloads%2Fjava-archive-downloads-javase6-419409.html%23jdk-6u45-oth-JPR; s_sq=%5B%5BB%5D%5D;" http://download.oracle.com/otn-pub/java/jdk/6u45-b06/jdk-6u45-linux-x64.bin
有关账户信息的部分,我已经涂黑。
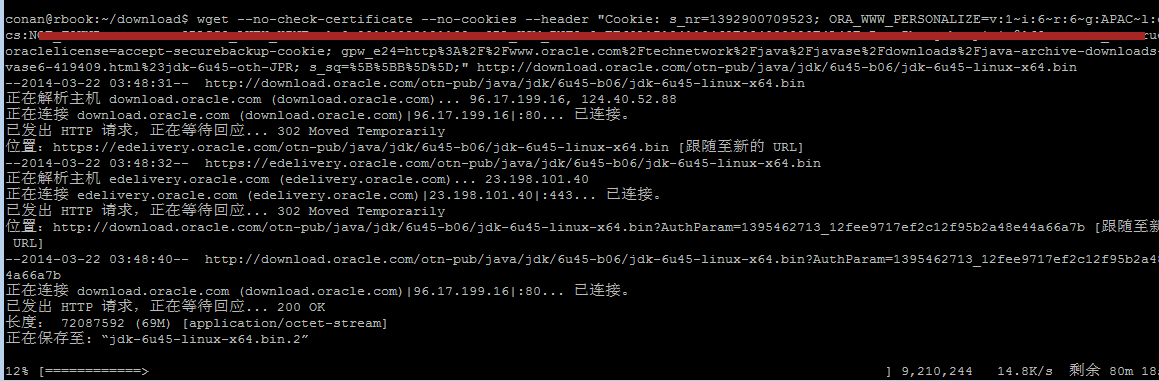
经常一番周折,我们下载就下载好了JDK。
2.2 安装JDK
通过shell命令安装JDK
# 安装JDK
~ sh ./jdk-6u45-linux-x64.bin
~ pwd
/home/conan/tookit
# 查看安装JDK安装后的目录
~ tree -L 2
.
├── jdk1.6.0_45
│ ├── bin
│ ├── COPYRIGHT
│ ├── db
│ ├── include
│ ├── jre
│ ├── lib
│ ├── LICENSE
│ ├── man
│ ├── README.html
│ ├── src.zip
│ └── THIRDPARTYLICENSEREADME.txt
└── jdk-6u45-linux-x64.bin
2.3 设置Java的环境变量
用vi编辑environemt文件
~ sudo vi /etc/environment
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/home/conan/tookit/jdk1.6.0_45/bin"
JAVA_HOME=/home/conan/tookit/jdk1.6.0_45
检查环境变量的设置
# 让环境变量生效
~ . /etc/environment
# 检查环境变量
~ export|grep jdk
declare -x OLDPWD="/home/conan/tookit/jdk1.6.0_45"
declare -x PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/home/conan/tookit/jdk1.6.0_45/bin"
~ echo $JAVA_HOME
/home/conan/tookit/jdk1.6.0_45
运行Java命令
~ java -version
java version "1.6.0_45"
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
Java HotSpot(TM) 64-Bit Server VM (build 20.45-b01, mixed mode)
~ java
Usage: java [-options] class [args...]
(to execute a class)
or java [-options] -jar jarfile [args...]
(to execute a jar file)
where options include:
-d32 use a 32-bit data model if available
-d64 use a 64-bit data model if available
-server to select the "server" VM
The default VM is server.
-cp
-classpath
A : separated list of directories, JAR archives,
and ZIP archives to search for class files.
-D=
set a system property
-verbose[:class|gc|jni]
enable verbose output
-version print product version and exit
-version:
require the specified version to run
-showversion print product version and continue
-jre-restrict-search | -jre-no-restrict-search
include/exclude user private JREs in the version search
-? -help print this help message
-X print help on non-standard options
-ea[:...|:]
-enableassertions[:...|:]
enable assertions
-da[:...|:]
-disableassertions[:...|:]
disable assertions
-esa | -enablesystemassertions
enable system assertions
-dsa | -disablesystemassertions
disable system assertions
-agentlib:[=]
load native agent library , e.g. -agentlib:hprof
see also, -agentlib:jdwp=help and -agentlib:hprof=help
-agentpath:[=]
load native agent library by full pathname
-javaagent:[=]
load Java programming language agent, see java.lang.instrument
-splash:
show splash screen with specified image
通过上面的操作,我们就把Java在Linux Ubuntu中的系统安装完成。
转载请注明出处:
http://blog.fens.me/linux-java-install/