R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-word-quanteda/

前言
在互联网的今天,我们每天都会生产和消费大量的文本信息,如报告、文档、新闻、聊天、图书、小说、语音转化的文字等。海量的文本信息,不仅提供扩宽的研究对象和研究领域,也为商业使用带来了巨大的机会。
量化文本分析(Quantitative Analysis of Textual Data),一种新的方式,用结构化数据的方式来管理文本。quanteda包,提出以语料库的形式管理文本,语料库被定义为文本的集合,其中包括特定每个文本的文档级变量,和整个集合的元数据。用户可以轻松地按单词、段落、句子甚至用户提供的分隔符分割文本和标签,按文档级变量将它们分组为更大的文档,形成基于逻辑条件的变量组合。
本文内容为分享内容,详情请参考文章2021 微软Ignite Post Watching Part:用R语言进行量化文本分析,分享内容的PPT请自取。
目录
- quanteda包介绍
- quanteda包的核心函数
- quanteda包的使用
1. quanteda包介绍
Quanteda是一个用于管理和分析文本数据的R包,对于文本管理功能强大,而且还很快。Quanteda包的官方地址 https://quanteda.io/。 Quanteda包由 Quanteda Initiative公司开发,总部位于伦敦,是一家英国非营利组织,致力于推广开源文本分析软件。主要产品R包 quanteda, readtext, spacyr, stopwords等,公司网站 https://quanteda.org/
Quanteda从底层开始重新设计了文本处理过程,在语法与性能上得到了巨大提升。
- 内部使用stringi作为字符处理工具
- 内部基于data.table与Matrix包
- 统一的语法结构
quanteda 文本重新定义了文本处理的过程,自己负责底层文本数据结构,结合应用层不同的功能包进行扩展。quanteda 包的使用,有一套自己的生态。
配合使用的其他包:readtext, stopwords,uanteda.textstats,quanteda.textmodels,quanteda.textplots,ggplot2,magrittr,stringr,plyr,dplyr,reshape2,seededlda 。
官方建议安装以下软件包,以便更好地支持和扩展quanteda的功能:
- readtext: 可将几乎任何格式的文本文件读入R
- spacyr: 使用spaCy库的NLP,包括词性标注,命名实体和依存语法
- quanteda.corpora : 用于quanteda的附加文本数据。
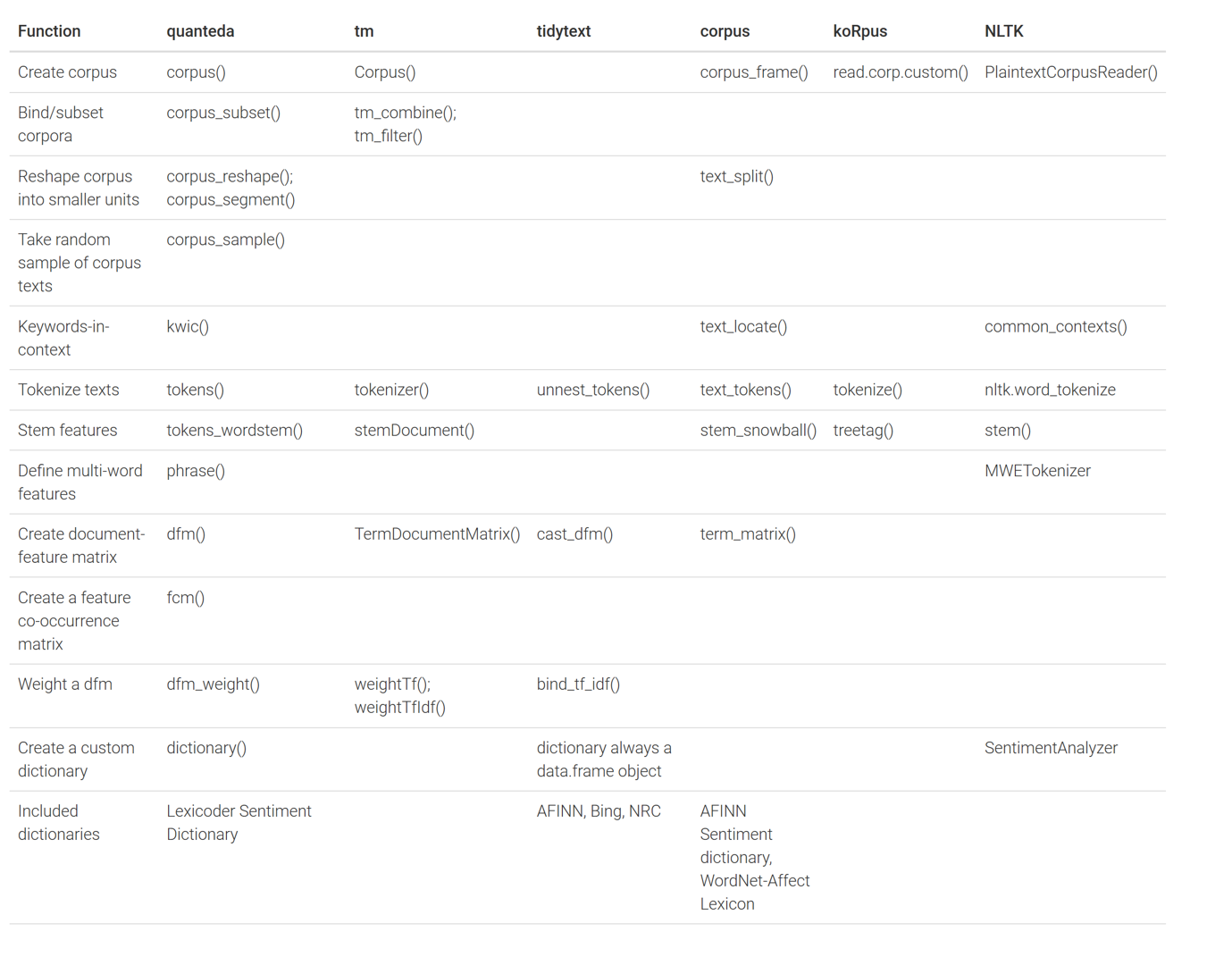
将quanteda包与用于定量文本分析的替代 R 包对比:tm、tidytext、corpus和koRpus
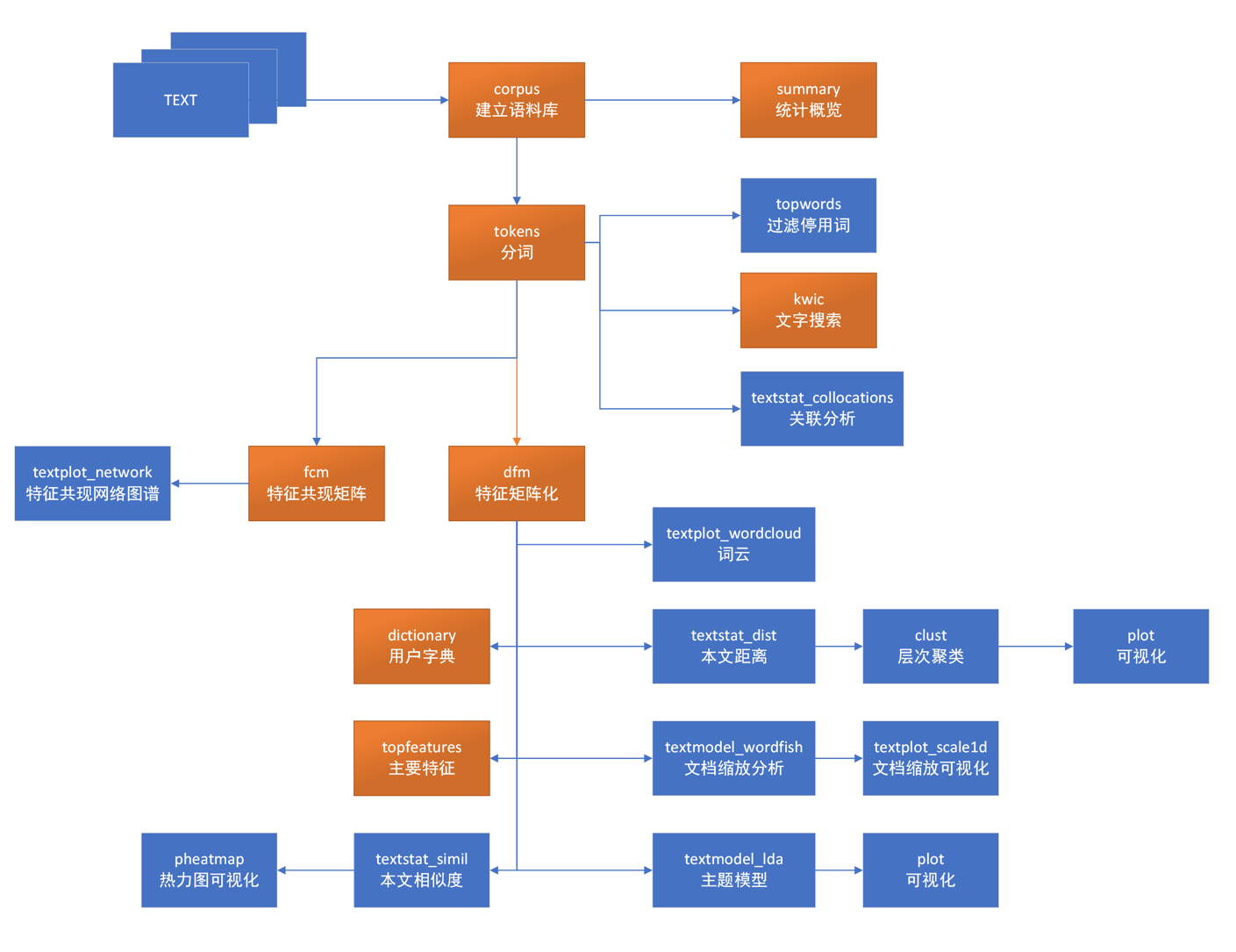
2. quanteda包的核心函数
quanteda软件包由几个核心数据类型,通过调用具有相同名称的构造器创建的。
核心对象类型及其构造函数:
- corpus():建立语料库对象
- tokens(): 构造一个分词对象
- dfm() : 创建文档特征矩阵
- fcm() : 创建特征共现矩阵
- kwic() : 关键字查询
- dictionary() : 创建字典
这些函数就是quanteda包的核心函数,也是我们用于文本分析的工具。使用好这些函数,可以快速实现对大量文本的分析。
官方API文档的解释:https://quanteda.io/reference/index.html
3. quanteda包的使用
首先进行quanteda包的安装,像其他包一样,安装过程很简单,然后加载quanteda包。
> install.packages("quanteda")
> library(quanteda)
具体操作步骤:
- 创建文本文件
- 使用readtext()的函数加载文本文件
- 从字符向量构建语料库
- 对语料库进行分词:按词、字、句子进行分隔
- 特征清洗和停用词
- 文字搜索
- 文本特征矩阵化
- 建立关键词字典,进行文档管理
第一步,新建一个文件,1.txt,填入文本信息。
国内知名211院校理工科硕士,具有一年半科技企业算法工程师经验,熟练掌握python,r,sql语言,熟悉神经网络,支持向量机,XGBoost等机器学习算法。工作积极主动,良好的沟通协调和自主学习能力,专业应用类别多,知识面广。
项目1:
(1) 数据导出,清洗和分析。数据库导出用户基础信息、行为数据等,并清洗脏数据,计算日活留存,疗效等指标。
(2) 特征提取和导出。根据数据分析结果提出一系列假设,寻找与疗效相关因素,并分析其相关性。使用 PCA 进行特征降维,Xgboost 特征选择等;
(3) 多种推荐算法和机器学习算法实现。根据用户特征使用协同过滤、机器学习、强化学习等为用户推荐更优的 App模块及组合,提升用户使用体验。
项目2:
(1) 设计数据模式和创建数据库:选择测量用户体验所需的特征指标,相应地创建6个特征指标
关系数据表(Table)。绘制其实体关系图(Entity-Relationship Diagrams),使用MySQL Workbench创建数据框架(Data Schema)。根据数据框架(Data Schema)生成合成数据(Synthetic Data),并通过PostgreSQL创建关系数据库(Relational Database)。
(2) 提取和清理数据:编写了Python代码进行数据预处理,并使用Tableau对数据进行可视化,这是建模前的必要工作。
(3) 建模:为了找到影响用户满意度的重要特征,团队应用了三种不同的机器学习模型(线性回
归、随机森林、神经网络)进行数据分析。线性回归提供了足够的解释性和快速的训练时间。在此基础上,随机森林和神经网络提高了精度和准确性。
第二步,使用readtext()的函数加载文本文件。
# 加载readtext包
> library(readtext)
# 读取文件
> dat<-readtext("./resume/1.txt", encoding = "UTF-8")
# 查看文件内容
> dat
readtext object consisting of 1 document and 0 docvars.
$text
[1] "\033[38;5;246m# A data frame: 1 × 2\033[39m"
[2] " doc_id text "
[3] " \033[3m\033[38;5;246m\033[39m\033[23m \033[3m\033[38;5;246m\033[39m\033[23m "
[4] "\033[38;5;250m1\033[39m 1.txt \033[38;5;246m\"\033[39m\\\"国内知名211院校理\\\"...\033[38;5;246m\"\033[39m"
$summary
$summary[[1]]
NULL
attr(,"class")
[1] "trunc_mat"
第三步,我们从字符向量构建语料库,建立语料库对象corp。共一个文本文件,15个句子,372个词,188个
# 把通过文本对象,建立语料库对象
> corp <- corpus(dat)
# 查看语料库的统计概览
> summary(corp)
Corpus consisting of 1 document, showing 1 document:
Text Types Tokens Sentences
1.txt 188 372 15
给语料库对象corp,增加属性信息。
> docvars(corp, "职位")<- "算法工程师"
> docvars(corp, "技能")<- "R语言"
# 查看语料库的统计概览,以多了2个属性字段
> summary(corp)
Corpus consisting of 1 document, showing 1 document:
Text Types Tokens Sentences 职位 技能
1.txt 188 372 15 算法工程师 R语言
查看corp对象基本属性
# 文档数量
> ndoc(corp)
[1] 1
# 文件名
> docnames(corp)
[1] "1.txt"
# 原始文本信息
> as.character(corp)
1.txt
"国内知名211院校理工科硕士,具有一年半科技企业算法工程师经验,熟练掌握python,r,sql语言,熟悉神经网络,支持向量机,XGBoost等机器学习算法。工作积极主动,良好的沟通协调和自主学习能力,专业应用类别多,知识面广。\n\n项目1:\n(1) 数据导出,清洗和分析。数据库导出用户基础信息、行为数据等,并清洗脏数据,计算日活留存,疗效等指标。\n(2) 特征提取和导出。根据数据分析结果提出一系列假设,寻找与疗效相关因素,并分析其相关性。使用 PCA 进行特征降维,Xgboost 特征选择等;\n(3) 多种推荐算法和机器学习算法实现。根据用户特征使用协同过滤、机器学习、强化学习等为用户推荐更优的 App模块及组合,提升用户使用体验。\n\n项目2:\n(1) 设计数据模式和创建数据库:选择测量用户体验所需的特征指标,相应地创建6个特征指标\n关系数据表(Table)。绘制其实体关系图(Entity-Relationship Diagrams),使用MySQL Workbench创建数据框架(Data Schema)。根据数据框架(Data Schema)生成合成数据(Synthetic Data),并通过PostgreSQL创建关系数据库(Relational Database)。\n(2) 提取和清理数据:编写了Python代码进行数据预处理,并使用Tableau对数据进行可视化,这是建模前的必要工作。\n(3) 建模:为了找到影响用户满意度的重要特征,团队应用了三种不同的机器学习模型(线性回\n归、随机森林、神经网络)进行数据分析。线性回归提供了足够的解释性和快速的训练时间。在此基础上,随机森林和神经网络提高了精度和准确性。"
第四步,对语料库进行分词。tokens()函数,提供了三种方式,按词、字、句子进行分隔。
按词进行分隔
> token<-tokens(corp)
# 查看分词的结果,前20个
> head(as.character(token[1]),20)
[1] "国内" "知名" "211" "院校" "理工科" "硕士" "," "具有" "一年半" "科技" "企业" "算法"
[13] "工程" "师" "经验" "," "熟练" "掌握" "python" ","
按句子进行分隔
> sentence <- tokens(corp, what = "sentence")
> sentence
Tokens consisting of 1 document and 2 docvars.
1.txt :
[1] "国内知名211院校理工科硕士,具有一年半科技企业算法工程师经验,熟练掌握python,r,sql语言,熟悉神经网络,支持向量机,XGBoost等机器学习算法。"
[2] "工作积极主动,良好的沟通协调和自主学习能力,专业应用类别多,知识面广。"
[3] "项目1: (1) 数据导出,清洗和分析。"
[4] "数据库导出用户基础信息、行为数据等,并清洗脏数据,计算日活留存,疗效等指标。"
[5] "(2) 特征提取和导出。"
[6] "根据数据分析结果提出一系列假设,寻找与疗效相关因素,并分析其相关性。"
[7] "使用 PCA 进行特征降维,Xgboost 特征选择等; (3) 多种推荐算法和机器学习算法实现。"
[8] "根据用户特征使用协同过滤、机器学习、强化学习等为用户推荐更优的 App模块及组合,提升用户使用体验。"
[9] "项目2: (1) 设计数据模式和创建数据库:选择测量用户体验所需的特征指标,相应地创建6个特征指标 关系数据表(Table)。"
[10] "绘制其实体关系图(Entity-Relationship Diagrams),使用MySQL Workbench创建数据框架(Data Schema)。"
[11] "根据数据框架(Data Schema)生成合成数据(Synthetic Data),并通过PostgreSQL创建关系数据库(Relational Database)。"
[12] "(2) 提取和清理数据:编写了Python代码进行数据预处理,并使用Tableau对数据进行可视化,这是建模前的必要工作。"
[ ... and 3 more ]
按字进行分隔
> chars <- tokens(corp, what = "character")
> head(as.character(chars),50)
[1] "国" "内" "知" "名" "2" "1" "1" "院" "校" "理" "工" "科" "硕" "士" "," "具" "有" "一" "年" "半" "科" "技" "企"
[24] "业" "算" "法" "工" "程" "师" "经" "验" "," "熟" "练" "掌" "握" "p" "y" "t" "h" "o" "n" "," "r" "," "s"
[47] "q" "l" "语" "言"
第五步,特征清洗。清洗过程中,我们可以使用默认停用词库进行过滤,也可以自定义停用词库。
进行初步特征清洗。
# 计算默认分词的词的长度
> token_len<-length(as.character(token));token_len
[1] 372
# 去空格去符号后,词的长度
> t1<-tokens(token, remove_punct = TRUE, remove_numbers = TRUE)
> t1_len<-length(as.character(t1));t1_len
[1] 285
进行停用词的特征清洗,quanteda包中,提供了3个默认的停用词表。
默认的英文停用词表。
> stopwords("english")
[1] "i" "me" "my" "myself" "we" "our" "ours" "ourselves"
[9] "you" "your" "yours" "yourself" "yourselves" "he" "him" "his"
[17] "himself" "she" "her" "hers" "herself" "it" "its" "itself"
[25] "they" "them" "their" "theirs" "themselves" "what" "which" "who"
[33] "whom" "this" "that" "these" "those" "am" "is" "are"
[41] "was" "were" "be" "been" "being" "have" "has" "had"
[49] "having" "do" "does" "did" "doing" "would" "should" "could"
[57] "ought" "i'm" "you're" "he's" "she's" "it's" "we're" "they're"
[65] "i've" "you've" "we've" "they've" "i'd" "you'd" "he'd" "she'd"
[73] "we'd" "they'd" "i'll" "you'll" "he'll" "she'll" "we'll" "they'll"
[81] "isn't" "aren't" "wasn't" "weren't" "hasn't" "haven't" "hadn't" "doesn't"
[89] "don't" "didn't" "won't" "wouldn't" "shan't" "shouldn't" "can't" "cannot"
[97] "couldn't" "mustn't" "let's" "that's" "who's" "what's" "here's" "there's"
[105] "when's" "where's" "why's" "how's" "a" "an" "the" "and"
[113] "but" "if" "or" "because" "as" "until" "while" "of"
[121] "at" "by" "for" "with" "about" "against" "between" "into"
[129] "through" "during" "before" "after" "above" "below" "to" "from"
[137] "up" "down" "in" "out" "on" "off" "over" "under"
[145] "again" "further" "then" "once" "here" "there" "when" "where"
[153] "why" "how" "all" "any" "both" "each" "few" "more"
[161] "most" "other" "some" "such" "no" "nor" "not" "only"
[169] "own" "same" "so" "than" "too" "very" "will"
优化的英文停用词表
stopwords(language = "en", source = "smart")
[1] "a" "a's" "able" "about" "above" "according" "accordingly"
[8] "across" "actually" "after" "afterwards" "again" "against" "ain't"
[15] "all" "allow" "allows" "almost" "alone" "along" "already"
[22] "also" "although" "always" "am" "among" "amongst" "an"
[29] "and" "another" "any" "anybody" "anyhow" "anyone" "anything"
[36] "anyway" "anyways" "anywhere" "apart" "appear" "appreciate" "appropriate"
[43] "are" "aren't" "around" "as" "aside" "ask" "asking"
[50] "associated" "at" "available" "away" "awfully" "b" "be"
[57] "became" "because" "become" "becomes" "becoming" "been" "before"
[64] "beforehand" "behind" "being" "believe" "below" "beside" "besides"
[71] "best" "better" "between" "beyond" "both" "brief" "but"
[78] "by" "c" "c'mon" "c's" "came" "can" "can't"
//....省略
中文停用词表
> stopwords(language = "zh",source="misc")
[1] "按" "按照" "俺" "们" "阿" "别" "别人" "别处" "是" "别的"
[11] "别管" "说" "不" "不仅" "不但" "不光" "不单" "不只" "不外乎" "不如"
[21] "不妨" "不尽" "然" "不得" "不怕" "不惟" "不成" "不拘" "料" "不是"
[31] "不比" "不然" "特" "不独" "不管" "不至于" "若" "不论" "不过" "不问"
[41] "比" "方" "比如" "及" "本身" "本着" "本地" "本人" "本" "巴巴"
[51] "巴" "并" "并且" "非" "彼" "时" "彼此" "便于" "把" "边"
[61] "鄙人" "罢了" "被" "般" "的" "此" "间" "此次" "此时" "此外"
[71] "处" "此地" "才" "才能" "朝" "朝着" "从" "从此" "从而" "除非"
[81] "除此之外" "除" "开" "除外" "除了" "诚" "诚如" "出来" "出于" "曾"
[91] "趁" "着" "在" "乘" "冲" "等等" "等到" "等" "第" "当"
//....省略
使用停用词表进行特征过滤,就是在tokens_select(),输入停用词参数。由于都是中文字符,所以用英文停用词表,并没有实际过滤去词。
> t2 <- tokens_select(t1, stopwords('english'),selection='remove')
> t2_len<-length(as.character(t1));t2_len
[1] 285
第六步,文字搜索。针对核心的关键词进行搜索,使用kwic()函数,支持正则匹配。
针对“算法”进行搜索,匹配文本中,算法的关键词,同时匹配中,算法前后的上下文的词。共找到4处“算法”出现的位置,可以让我们非常直观的定位核心段落。
> kwic(t2, pattern = "算法", valuetype = "regex")
Keyword-in-context with 4 matches.
[1.txt, 10] 硕士 具有 一年半 科技 企业 | 算法 | 工程 师 经验 熟练 掌握
[1.txt, 30] 机 XGBoost 等 机器 学习 | 算法 | 工作 积极 主动 良好 的
[1.txt, 108] 特征 选择 等 多种 推荐 | 算法 | 和 机器 学习 算法 实现
[1.txt, 112] 推荐 算法 和 机器 学习 | 算法 | 实现 根据 用户 特征 使用
以“精通”、"硕士"关键字进行匹配。
> kwic(t2, pattern = "精通", valuetype = "regex")
Keyword-in-context with 0 matches.
> kwic(t2, pattern = "硕士", valuetype = "regex")
Keyword-in-context with 1 match.
[1.txt, 5] 国内 知名 院校 理工科 | 硕士 | 具有 一年半 科技 企业 算法
以正则表达式 "R|python|sql",进行多词匹配。
> kwic(t2, pattern = "R|python|sql", valuetype = "regex")
Keyword-in-context with 10 matches.
[1.txt, 16] 工程 师 经验 熟练 掌握 | python | r sql 语言 熟悉 神经
[1.txt, 17] 师 经验 熟练 掌握 python | r | sql 语言 熟悉 神经 网络
[1.txt, 18] 经验 熟练 掌握 python r | sql | 语言 熟悉 神经 网络 支持
[1.txt, 171] 绘制 其实 体 关系 图 | Entity-Relationship | Diagrams 使用 MySQL Workbench 创建
[1.txt, 172] 其实 体 关系 图 Entity-Relationship | Diagrams | 使用 MySQL Workbench 创建 数据
[1.txt, 174] 关系 图 Entity-Relationship Diagrams 使用 | MySQL | Workbench 创建 数据 框架 Data
[1.txt, 175] 图 Entity-Relationship Diagrams 使用 MySQL | Workbench | 创建 数据 框架 Data Schema
[1.txt, 193] 数据 Synthetic Data 并 通过 | PostgreSQL | 创建 关系 数据 库 Relational
[1.txt, 198] PostgreSQL 创建 关系 数据 库 | Relational | Database 提取 和 清理 数据
[1.txt, 206] 和 清理 数据 编写 了 | Python | 代码 进行 数据 预 处理
第七步,文本特征矩阵化,形成分词后的词频矩阵。
# 对原始分词进行矩阵化
> dfm1<-dfm(token)
# 查看输出
> dfm1
Document-feature matrix of: 1 document, 186 features (0.00% sparse) and 2 docvars.
features
docs 国内 知名 211 院校 理工科 硕士 , 具有 一年半 科技
1.txt 1 1 1 1 1 1 25 1 1 1
[ reached max_nfeat ... 176 more features ]
对特征清洗后的特征进行矩阵化
> dfm1<-dfm(t2)
> dfm1
Document-feature matrix of: 1 document, 172 features (0.00% sparse) and 2 docvars.
features
docs 国内 知名 院校 理工科 硕士 具有 一年半 科技 企业 算法
1.txt 1 1 1 1 1 1 1 1 1 4
[ reached max_nfeat ... 162 more features ]
查看前100个高频的特征
> topfeatures(dfm1, 100)
数据 和 的 特征 学习 用户 等 使用 算法 机器 分析 并 进行 创建
16 9 8 7 6 6 5 5 4 4 4 4 4 4
神经 网络 导出 库 指标 根据 性 模 关系 data 了 python xgboost 工作
3 3 3 3 3 3 3 3 3 3 3 2 2 2
应用 项目 清洗 基础 疗效 提取 相关 选择 推荐 体验 框架 schema 建 线性
2 2 2 2 2 2 2 2 2 2 2 2 2 2
随机 森林 国内 知名 院校 理工科 硕士 具有 一年半 科技 企业 工程 师 经验
2 2 1 1 1 1 1 1 1 1 1 1 1 1
熟练 掌握 r sql 语言 熟悉 支持 向量 机 积极 主动 良好 沟通 协调
1 1 1 1 1 1 1 1 1 1 1 1 1 1
自主 能力 专业 类别 多 知识 面 广 信息 行为 脏 计算 日 活
1 1 1 1 1 1 1 1 1 1 1 1 1 1
留存 结果 提出 一系列 假设 寻找 与 因素 其 pca 降 维 多种 实现
1 1 1 1 1 1 1 1 1 1 1 1 1 1
协同 过滤
1 1
第八步,建立关键词字典,对文本向量按字典进行分组统计。
# 建立字典向量
> dict <- dictionary(
+ list(算法 = c("算法","模型","统计"),
+ 业务 = c("业务","行业","需求"),
+ 大数据 = c("hadoop","Spark","Flink"),
+ 编程 = c("R","Python","Java","sql")))
# 对文本向量按字典进行分组统计
> tokens_lookup(t2,dictionary = dict) %>%
+ dfm()%>%
+ dfm_group(groups = 职位)
Document-feature matrix of: 1 document, 4 features (50.00% sparse) and 2 docvars.
features
docs 算法 业务 大数据 编程
算法工程师 5 0 0 4
本文我们了解了quanteda包的核心函数的使用,通过quanteda包可以让我们进行文本分析事倍功半。确实功能强大,下一篇文章,我们将用quanteda包做一个招聘职位的数据分析案例,请参考文章基于quanteda包招聘职位分析案例。
本文的代码已上传到github:https://github.com/bsspirit/quanteda/blob/main/quanteda-basic.r
转载请注明出处:
http://blog.fens.me/r-word-quanteda/