让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务。
现在硬件越来越便宜,一台非品牌服务器,2颗24核CPU,配48G内存,2T的硬盘,已经降到2万块人民币以下了。这种配置如果简单地放几个web应用,显然是奢侈的浪费。就算是用来实现单节点的hadoop,对计算资源浪费也是非常高的。对于这么高性能的计算机,如何有效利用计算资源,就成为成本控制的一项重要议题了。
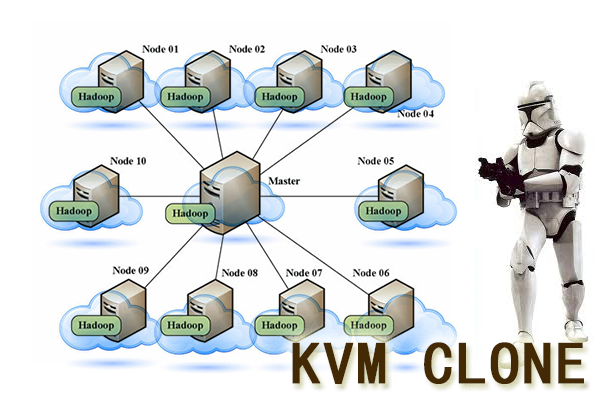
通过虚拟化技术,我们可以将一台服务器,拆分成12台VPS,每台2核CPU,4G内存,40G硬盘,并且支持资源重新分配。多么伟大的技术啊!现在我们有了12个节点的hadoop集群, 让Hadoop跑在云端,让世界加速。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-clone-node/
前言
通过虚拟化技术,我们可轻松的增加或删除一台虚拟机。像hadoop技术,安装,配置,运维,管理都很复杂,如果能通过虚拟化技术,降低运维成本,是多么开心的一件事啊!设想一下,如果一个人能够管理1000个hadoop节点,那么小型公司也可以随随便便构建像百度,阿里一样的强大的计算集群环境。世界也许会更奇妙!
当然,本文并不是讲一个人如何管理1000个hadoop节点。但我会介绍一种方式,通过克隆虚拟机来增加Hadoop节点。也许在大家的实践操作中,就能做出一个人运维1000个节点集群的方案。
目录
- 系统环境介绍
- 克隆虚拟机
- 完成2个节点的hadoop集群
1. 系统环境介绍
我延续上篇文章的系统环境,让Hadoop跑在云端系列文章 之 创建Hadoop母体虚拟机
我们已成功地创建了Hadoop母体虚拟机c1。接下来,我们要用clone的方式创建c2,c3,c4,c5 ,4台克隆虚拟机。
2. 克隆虚拟机
在host中,打开虚拟机管理软件,查看c1的状态。
~ sudo virsh
virsh # list
Id Name State
----------------------------------------------------
5 server3 running
6 server4 running
7 d2 running
8 r1 running
9 server2 running
18 server5 running
42 c1 running
c1正在运行中,由于c2之前已经创建,我们已c3来举例说明。
创建克隆体c3
~ sudo virt-clone --connect qemu:///system -o c1 -n c3 -f /disk/sdb1/c3.img
ERROR Domain with devices to clone must be paused or shutoff.
关闭c1,并重新克隆
virsh # destroy c1
Domain c1 destroyed
~ sudo virt-clone --connect qemu:///system -o c1 -n c3 -f /disk/sdb1/c3.img
ERROR A disk path must be specified to clone '/dev/sdb5'
分区硬盘引入的错误。(无比强大的google,已经找不到对这个错误的解释了)
接下的操作:
- 重新启动c1,注释/etc/fstab自动挂载/dev/vdb1的操作(自行解决)
- 卸载给c1分配的分区硬盘/dev/sdb5
~ edit c1
<!--
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none'/>
<source dev='/dev/sdb5'/>
<target dev='vdb' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
</disk>
-->
再次创建克隆体c3
~ sudo virt-clone --connect qemu:///system -o c1 -n c3 -f /disk/sdb1/c3.img
Cloning c1.img 1% [ ] 47 MB/s | 426 MB 14:14 ETA
Cloning c1.img | 40 GB 08:18
Clone 'c3' created successfully.
给克隆体c3挂载分区硬盘/dev/sdb7,并启动c3
virsh # edit c3
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none'/>
<source dev='/dev/sdb7'/>
<target dev='vdb' bus='virtio'/>
</disk>
virsh # start c3
virsh # console c3
Connected to domain c3
Escape character is ^]
Ubuntu 12.10 c1 ttyS0
c1 login: cos
Password:
Last login: Wed Jul 10 12:00:44 CST 2013 from 192.168.1.79 on pts/0
Welcome to Ubuntu 12.10 (GNU/Linux 3.5.0-32-generic x86_64)
* Documentation: https://help.ubuntu.com/
New release '13.04' available.
Run 'do-release-upgrade' to upgrade to it.
cos@c1:~$
对克隆体c3,有几个地方需要修改:
- hostname,hosts
- 静态IP
- DNS
- /dev/vdb1自动挂载
- 配置hadoop存储目录权限
- ssh自动验证
- hadoop的master,slave
1. hostname,hosts
~ sudo hostname c3
~ sudo vi /etc/hostname
c3
~ sudo vi /etc/hosts
127.0.1.1 c3
2. 静态IP
~ sudo vi /etc/network/interfaces
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
#iface eth0 inet dhcp
iface eth0 inet static
address 192.168.1.32
netmask 255.255.255.0
gateway 192.168.1.1
改完IP后,我们重启一下,用ssh连接。
~ ssh cos@c3.wtmart.com
~ ifconfig
eth0 Link encap:Ethernet HWaddr 52:54:00:06:b2:3a
inet addr:192.168.1.32 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::5054:ff:fe06:b23a/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:42 errors:0 dropped:0 overruns:0 frame:0
TX packets:33 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:6084 (6.0 KB) TX bytes:4641 (4.6 KB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:34 errors:0 dropped:0 overruns:0 frame:0
TX packets:34 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2560 (2.5 KB) TX bytes:2560 (2.5 KB)
3. DNS (内网的DNS)
~ sudo vi /etc/resolv.conf
nameserver 192.168.1.7
~ ping c1.wtmart.com
PING c1.wtmart.com (192.168.1.30) 56(84) bytes of data.
64 bytes from 192.168.1.30: icmp_req=1 ttl=64 time=0.485 ms
64 bytes from 192.168.1.30: icmp_req=2 ttl=64 time=0.552 ms
4. /dev/vdb1自动挂载
~ sudo mount /dev/vdb1 /home/cos/hadoop
~ sudo vi /etc/fstab
/dev/vdb1 /home/cos/hadoop ext4 defaults 0 0
~ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/u1210-root 36G 2.4G 32G 7% /
udev 2.0G 4.0K 2.0G 1% /dev
tmpfs 791M 224K 791M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 2.0G 0 2.0G 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/vda1 228M 29M 188M 14% /boot
/dev/vdb 148G 188M 140G 1% /home/cos/hadoop
5. 配置hadoop存储目录权限
~ sudo chown -R cos:cos hadoop/
~ mkdir /home/cos/hadoop/data
~ mkdir /home/cos/hadoop/tmp
~ sudo chmod 755 /home/cos/hadoop/data
~ sudo chmod 755 /home/cos/hadoop/tmp
6. ssh自动验证
~ rm -rf ~/.ssh/
~ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/cos/.ssh/id_rsa):
Created directory '/home/cos/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/cos/.ssh/id_rsa.
Your public key has been saved in /home/cos/.ssh/id_rsa.pub.
The key fingerprint is:
54:1f:51:5f:5c:1d:ac:8a:9d:8f:fd:da:65:7e:f9:8d cos@c3
The key's randomart image is:
+--[ RSA 2048]----+
| . oooo*|
| . . . o+|
| . . . .|
| . . |
| S o o |
| . + |
| + +|
| . o.=+|
| .Eo*|
+-----------------+
~ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
~ cat ~/.ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCtIK3+hGeJQOigIN1ydDVpUzFeg/urnX2DaHhuv5ik8bGGDZWmSA+qPWAZQoZFBGqGMTshvMQeksjA2WiINbFpQCGuxSFx5a9Ad0XU8bGDFi+yYfKlp1ROZ+7Jz1+cO4tjrCX4Ncr3nZlddl6Uh/yMYU+iuRQ4Ga7GXgeYoSf7C5vQmzkYija0XNa8wFr0+aeD3hau6s8dWwsw7Dn/xVA3eMqK+4LDGH6dkn6tc6nVyNbzofXdtPOsCkwHpwozwuRBL37LYcmELe+oT/GifWf0Qp4rQD/9ObtHkhKrSW45bRH/WzvkyNxl04dKlIj26zIsh9zjMHF8o0ce+zjUl7aD cos@c3
7. hadoop的master,slave
~ cd /home/cos/toolkit/hadoop-1.0.3/conf
~ vi slaves
c1.wtmart.com
c3.wtmart.com
3. 完成2个节点的hadoop集群
重新启动c1节点,配置2个节点的hadoop集群
~ ssh cos@c1.wtmart.com
~ sudo mount /dev/vdb1 /home/cos/hadoop
配置slave
~ cd /home/cos/toolkit/hadoop-1.0.3/conf
~ vi slaves
c1.wtmart.com
c3.wtmart.com
DNS (内网的DNS)
~ sudo vi /etc/resolv.conf
nameserver 192.168.1.7
~ ping c3.wtmart.com
PING c3.wtmart.com (192.168.1.32) 56(84) bytes of data.
64 bytes from 192.168.1.32: icmp_req=1 ttl=64 time=0.673 ms
64 bytes from 192.168.1.32: icmp_req=2 ttl=64 time=0.429 ms
交换ssh公钥
复制c3的authorized_keys到c1的authorized_keys
~ scp cos@c3.wtmart.com:/home/cos/.ssh/authorized_keys .
~ cat authorized_keys >> /home/cos/.ssh/authorized_keys
~ cat /home/cos/.ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCuWCgfB8qSyEpKmUwnXvWtiCbzza1oD8oM3jm3EJzBRivEC/QV3k8v8zOHt2Cf4H6hYIvYHoSMilA2Wqbh1ny/70zcIYrwFiX5QvSjbEfsj7UmvxevxjB1/5F66TRLN/PyTiw3FmPYLkxvTP8CET02D2cgAN0n+XGTXQaaBqBElQGuiOJUAIvMUl0yg3mH7eP8TRlS4qYpllh04kirSbkOm6IYRDtGsrb90ew63l6F/MpPk/H6DVGC23PnD7ZcMr7VFyCkNPNqcEBwbL8qL1Hhnf7Lvlinp3M3zVU0Aet3TjkgwvcLPX8BWmrguVdBJJ3yqcocylh0YKN9WImAhVm7 cos@c1
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDU4sIHWxuyicIwFbRpDcoegDfSaUhmaBTSFSVTd/Uk8w0fTUcERNx9bZrtuiiPsOImvsBy9hN2Au/x36Jp4hO8DFxzqTNBcfD9xcEgOzHGqH7ZC5qMqx3Poy6DzN/rk9t/+wXyNCfR4kRhrPBNiF6gMDMTRQLpKK9VnY0nQ6FvOQ407gMAsyf0Fn31sHZJLtM4/kxsSOEsSNIk1V+gbIxJv2fJ/AON0/iW1zu7inUC/+YvEuTLClnUMzqFb/xKp25XxSV6a5YzThxs58KO5JCRq2Kk/SM0GSmCSkjKImUYDDjmi1P6wbrd4mh/4frQr1DqYyPeHE4UlHXD90agw767 cos@c3
把c1的authorized_keys,再分发给c3
~ scp /home/cos/.ssh/authorized_keys cos@c3.wtmart.com:/home/cos/.ssh/authorized_keys
从c1启动hadoop集群
~ start-all.sh
starting namenode, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-namenode-c1.out
c1.wtmart.com: Warning: $HADOOP_HOME is deprecated.
c1.wtmart.com:
c1.wtmart.com: starting datanode, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-datanode-c1.out
c3.wtmart.com: Warning: $HADOOP_HOME is deprecated.
c3.wtmart.com:
c3.wtmart.com: starting datanode, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-datanode-c3.out
c1.wtmart.com: Warning: $HADOOP_HOME is deprecated.
c1.wtmart.com:
c1.wtmart.com: starting secondarynamenode, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-secondarynamenode-c1.out
starting jobtracker, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-jobtracker-c1.out
c3.wtmart.com: Warning: $HADOOP_HOME is deprecated.
c3.wtmart.com:
c3.wtmart.com: starting tasktracker, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-tasktracker-c3.out
c1.wtmart.com: Warning: $HADOOP_HOME is deprecated.
c1.wtmart.com:
c1.wtmart.com: starting tasktracker, logging to /home/cos/toolkit/hadoop-1.0.3/libexec/../logs/hadoop-cos-tasktracker-c1.out
查看c1的进程
~ jps
8861 JobTracker
8486 NameNode
8750 SecondaryNameNode
9123 Jps
9001 TaskTracker
8612 DataNode
查看c3的进程
~ jps
3180 TaskTracker
3074 DataNode
3275 Jps
这样就建立起了,2个节点的hadoop集群。
上面是我们手动操作的过程比较复杂,接下来我们的任务就是写一个自动化的脚本完成上面的操作。
转载请注明出处:
http://blog.fens.me/hadoop-clone-node/

太赞了,我估计这个是国内记载虚拟机做Hadoop集群最详细的博文了。
似乎确实没有什么文章,是关于虚拟化和hadoop的。
明天应该可以把设计的5个节点都搞定了,你又要等一天才能用了。:-)
[…] 让Hadoop跑在云端系列文章 之 克隆虚拟机增加Hadoop节点 […]
[…] 克隆虚拟机增加Hadoop节点 […]
楼主好,看到您这一系列的文章特别感动,记载的非常详细。我最近也在调研这方面,主要是想实现大规模基于hadoop的视频编解码集群,不知道您有没有做过相关的测试。就是5台物理服务器和在这些服务器中创建一定数量的vm,然后都搭建hadoop做分布式计算,哪种方案性能好。
我想做一些初期的测试,但是目前还没有开始,在调研阶段,希望能得到您的一些建议。非常感谢。
你好yunfei
1. 编解码没做过。
2. 做VM的目的应该是很明确的,就是不能充分利用物理机的资源。
3. 我没有做过这种测试,你需要自己测试一下。
如果你测试完,能分享你的测试报告,估计会有很多人,帮助你选择方案。
楼主您好,有在6台物理服务器上的话,直接搭建hadoop,是不是没必要创建VM拆分成多台?
一个节点一个task处理的任务,但是一个tasktracker是可以并发处理多个task的
任务是串行运行的。
有物理多好,没必要玩VM的