R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员Java,R,Nodejs
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-finance/

前言
做数据分析的朋友,一定听说过R语言。R语言是一门统计语言,在数据分析领域优势是非常明显的。
本文以 “R语言,为量化而生”为题,说明R语言真的很适合做金融做量化策略。金融本身是玩数据行业,R的最大的优势就是数据分析,所以用R来做量化投资的策略,真是很配,不仅顺手而且方便,用了你就会知识。
本文将由3个方面来介绍,R语言做量化是多么的适合。
目录
- 为什么是R语言?
- R语言的数据处理和时间序列
- R语言和金融模型
1. 为什么是R语言?
那么为什么是R语言,而不是其他的语言? 先简单介绍一下,我们的个人经历。
我是一个程序员,从2004年开始接触Java写了10多年的Java程序,期间还尝试过多种编程语言,VB、PHP、Python、SAS、R、Nodejs,最后把自己锁定在R,Nodejs和Java。谈不上对每一种语言都有很深的理解,但是每种语言的特点还是有点心得。
之所以选择R,Nodejs和Java这3种语言,有一部分情怀,更多的是理性。从技术发展来看,编程开发变得越来越简单,10年前用JavaEE做一个简单的web项目至少要2人月,现在用Nodejs新人边学边搞只需10人天。而且随着业务的多样化,单一的技术已经不足以支撑业务的发展,业务在从传统的软件开发向互联网和数据产品的方向在进化。根据不同语言的特点,每种都将在开发中占据一席之地,而很难在出现一种语言统一天下的情况。
R语言将在数据分析领域发挥着重要的作用。R语言的3个特性,数学计算、数据建模和数据可视化。R语言封装了多种基础学科的计算函数,我们在R语言编程的过程中只需要调用这些计算函数,就可以构建出面向不同领域、不同业务的、复杂的数学模型。
另外,R的知识体系结构是复杂的,要想学好R,就必须把多学科的知识综合运用,而最大的难点不在于R语言本身,在于使用者的知识基础和综合运用的能力。
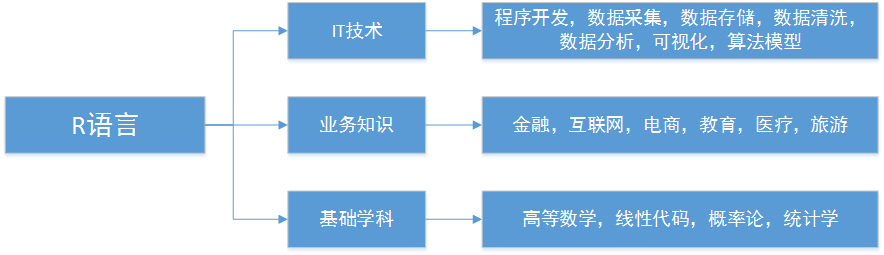
图中我将R语言知识体系结构分为3个部分:IT技术 + 业务知识 + 基础学科。
- IT技术:是数据大发展时代必备的技术之一,R语言就是我们应该要掌握的一门技术。
- 业务知识:是市场经验和法则,不管你在什么公司,你都了解业务是什么,产品是什么,用户是谁,公司的价值在哪里!
- 基础学科:是我们在学校里学到的理论知识,虽然当初学的时候并不理解,工作中如果你还能掌握并实际运用,那么这将是你最有价值的竞争力。
关于R的知识体系,可以参考文章,R语言知识体系概览
对于金融量化投资来说,刚好是一个交叉学科,你需要懂IT技术,熟悉金融市场的规则,有数学建模的能力。R语言,正好可以帮我们来解决这样的问题,所以“R语言,为量化而生”!
对于做过数据分析的人来说,大家都了解什么是最费时间的!!无疑就是数据处理的部分。
2. R语言的数据处理和时间序列
第二部分,我们来介绍一下R语言的数据类型和数据处理的一些方法。当然,本文并没有介绍如何入门R语言,新手入门请参考文章R的极客理想系列文章
2.1 基本数据类型
在R语言中,数据类型包括向量类型,字符串类型,数字类型,布尔类型,矩阵类型,数据框类型,list类型等,通常我们在使用R语言里做数据处理的时候,大部分都会以数据框(data.frame)类型为一个主要的数据内存类型来使用。
数据框(data.frame)类型是R语言内置的一种数据类型,我们可以简单地把它理解为,与关系型数据库中表的结构是类似的,是一种二维的数据结构。
# 新建一个数据框
> data.frame(A=1:6,B=LETTERS[1:6])
A B
1 1 A
2 2 B
3 3 C
4 4 D
5 5 E
6 6 F
正是由于R语言内置了这样的数据类型,使我们从数据库读取数据或导入CSV格式的数据时,与R语言有了一个很好的映射关系,直接加载到R语言的内存中变成标准化数据格式。
然后,就可以基于标准化的数据格式,用R语言的功能函数来处理数据了。比如,对于做数据库开发的人员来说,他可以使用sqldf包,在R语言中通过SQL语句对数据进行数据变换。同时,也可以按着数据框(data.frame)的标准方法进行数据处理,通过约定的向量索引下标的方式来按行按列来读取数据,或使用功能函数处理数据。
# sqldf包的使用
> library(sqldf)
> sqldf('select * from iris limit 6')
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
# 向量索引
> iris[1:6,]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
# head函数使用
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
我们经常还会对数据进行转型处理,把数据框(data.frame)类型和其他数据类型的进行转化。我们有时会使用矩阵计算,R语言中默认供了矩阵(matrix)数据类型,可以很方便地把数据框转类型成矩阵类型,有时也需要把数据框的某一行或某一列转型为一个向量类型数据,或者把数据框变成一个list类型。通过数据的格式变换,用标准化的数据结构来满足数据分析的要求。
虽然R语言是统计语言,从性能上来说比C++/Java等语言慢不少。但对于数据分析的业务场景,用R语言来做数据处理的时候,你不用考虑程序如何架构,指针怎么定义,内存是否会泄露,只要关注你的数据和算法就行了。唯一需要注意的一点,不要直接用for循环的方式处理数据,尽量使用向量计算或矩阵计算的计算方法。当必须用循环的时候,你就需要用apply家族函数,代替for循环来做数据处理。关于apply家族函数的用法,请参考文章掌握R语言中的apply函数族
如果你的数据量比较大,1GB,10GB,甚至有100GB,对于这种规模比较大的数据集,apply的计算方式就不太能满足计算性能的要求了。你依然可以用data.table包, bigmemory包, ff包等,或者并行计算的包加速R语言在单机上的计算的性能。data.table的使用方法,请参考文章超高性能数据处理包data.table。
那么再大规模的数据,超过1TB这个量级,不只是R语言,每种语言都会遇到计算性能的瓶颈。这个时候,我们需要把数据放到分布式系统中,如Hadoop或其他大数据的引擎中进行存储和计算。R语言与各种的大数据平台的通信接口都是通的,比如RHadoop,rhive, rhbase, rmongodb, rCassandra, SparkR, sparklyr等。如果你想了解hadoop的知识,请参考文章Hadoop家族系列文章,RHadoop实践系列文章, R利剑NoSQL系列文章 之 Hive。
2.2 时间序列类型
除了R语言的内置基础数据类型,对于金融的数据处理,一般我会把它变成标准的时间序列类型的数据,R语言中基本的时间序列的类型为 zoo 和 xts类型,当然还有一些其他包提供的数据类型。关于zoo和xts的详细介绍,请参考文章 R语言时间序列基础库zoo,可扩展的时间序列xts
通过类型变换可以很方便地把的data.frame或者matrix等基础类型数据,变成xts时间序列类型的数据。时间序列类型的好处是它默认会以时间作为索引,对于量化策略来说,每条数据记录他都会有数据产生的时间,那这个时间就正好可以作为索引列的时间。
# 数据框
> df<-data.frame(A=1:6,B=rnorm(6))
# xts时间序列类型
> xdf<-xts(df,order.by=as.Date('2016-01-01')+1:6);xdf
A B
2016-01-02 1 -1.24013232
2016-01-03 2 -0.21014651
2016-01-04 3 -1.63251615
2016-01-05 4 -0.67279885
2016-01-06 5 0.01487863
2016-01-07 6 0.92012628
# 类型检查
> class(xdf)
[1] "xts" "zoo"
那么以时间作为数据的索引列的好处是,可以很方便地把数据以时间维度进行对齐。比如,你设计了一个股票交易策略和一个期货交易策略,由于股票是T+1交易,今天买了明天才能卖;而期货是T+0交易,今天买了马上就可以卖出。针对不同的市场规则,在设计交易策略时,可能就会选择不同的交易周期,那么这时两个策略的交易周期就会不一样,那么时间维度可能也不是对齐的。如果这两个策略是对冲的,那么我们就需要把它们以时间维度进行对齐,才能进行实现对策略模型对冲的准确计算。
把不同时间的维度的数据转化成同一个时间维度,相当于做时间的标准化。通过标准化的操作,让数据变成同一时间维度,数据之间才能够进行计算。
举个简单的例子,我们做股票交易,在实盘交易过程中,你可能最关心的是每秒最新的价格数据,每一秒都会产生一条数据,这是属于日内交易策略。另外,我们再做一个周期稍微长一点的策略,以日线为基础的,那么这里一条记录就是一天收盘价。对比日内策略,1秒钟一条数据和1天一条数据,它们不同维度的数据,是不能直接进行计算。
我们要处理这种不同周期维度数据的时候,就需要把数据转成同一个维度的。比如,我们对日线和周线的数据进行合并的时候,可以是把周线数据拆成日线数据,就是把一周分成五天。反过来,也可以把日线数据合并为周线数据,把5天的数据合并成一周。
所以这个时候就需要一个统一的数据格式进行标准化的数据定义,zoo和xts就是我们作为时间序列基础数据类型。这两个包是由第三方开发的,提供了很丰富的时间序列处理函数,我们可以直接使用这些函数来操作金融数据。很多其他的第三方金融算法分析包,也都是以这两个包作为基础开发。
3. R语言和金融模型
当我们掌握了R语言处理数据的方法,了解了如何使用R语言的基础数据类型和时间序列数据类型,下面我们就可以构建金融的策略模型。
金融建模跟其他行业的数据建模是类似的,只是由于行业不一样,金融行业有很多背景知识和金融市场规则需要我们了解。金融本身就是一个玩数据的行业,你可以通过获得交易数据,财务数据,上市公司的各种事件数据,基本面数据,宏观数据,舆情数据,互联网数据等,来构建你自己的交易策略。
我们需要把这些数据进行组合整理,结合你自己对业务的理解,使用R语言从数据中发现规律,并构建交易模型。用程序对历史数据进行回测,来验证规律的可靠性,是否会长期有效,并控制风险,最后把验证过的规律变成算法模型,这个就是金融策略建模的过程。
从金融交易分析的角度,可以从3个维度进行分析 基本面分析,技术面分析和消息面分析。
- 基本面:指对宏观经济、行业和公司基本情况的分析,包括公司经营理念策略、公司报表等的分析。长线投资一般用基本面分析,通过基本面可以判断是否值去交易。
- 技术面:指通过技术指标变化,判断股票走势形态,进行K线组合等,通过技术面可以判断如何进行交易。
- 消息面:指上市公司发布的利好和利空的消息,通过消息面可以判断市场的情绪。
对于量化模型,大部分都是基于技术指标的模型,通过技术指标建模,跟踪市场的表现。在不完全了解金融业务和金融市场的情况下,通过几个技术指标来监控市场的走势,发现市场的机会也是有可能的。
量化交易和主观交易并不是对立的,量化交易是对主观交易的补充,当我们以数据作为决策基础的时候,其实可以尽量减少拍脑袋过程,创建数据模型也可以给我们心里建立良好的信心。如果交易没有使用量化的方法,那就跟我们平时做事一样,你可能想到什么就是什么。没有数据基础,那完全就是感觉,这样子交易就是很容易赔钱。
对于中国很多的散户,听到一个消息就跟着风的买卖股票,或者凭自己感觉大盘该涨了就跟进去,这些操作其实都是很不理性的。如果你通过量化的方法,即使再简单,就靠几条均线来进行判断,这样也是能给自己一个数据的基础,建立信心,而不是完全拍脑袋的事儿。
量化交易模型主要是以技术指标为主,常用的技术指标有不少,虽然简单但还是很有用的。对于很多实盘上运行的量化策略,大都会基于这些基础的指标,但并不是把每个指标单独使用。而是把多个指标通过变换组合使用,比如说MACD是均线模型,大部分的趋势策略都以MACD做为基础指标,通过变换再生成新的衍生指标。
常用的技术指标还包括KDJ、Boll、RSI、CCI等,当你直接使用这些指标的时候,可能效果并不是太好。因为市场上普遍接受了这些技术指标,已经被大量使用。单纯地用一个指标,你掌握的信息并不比别人多,所以你可能抓不到市场上赚钱的机会。
我们需要把多种技术指标或者多个维度的指标进行结合,通过组合优化的方式来降低策略的不确定风险,同时提高收益率。如果你找到了一个只有你自己知道市场规律,你的策略产生的信号完全是跟别人有区别的,你抓住了别人看不到的机会,这个才是你的赚钱机会。你领先的越多,越少人知道这个规则,那你可能赚钱的机会就越多。
建立量化模型,其实和我们平时做数据分析的思考试是一样的。要把这件事做好,我们需要把IT技术,业务知识和基础学科知识做进一步的结合,当你发现这个结合是属于你自己特有一个知识体系,你才能更好的发挥你的才能。
我们为什么要用R来做这件事情?
首先,R语言本身提供了很多数学、统计的基础包,让数学计算变得非常容易。R语言提供了常用的数据结构,向量、数据框、矩阵等,把数据变成标准化的数据,你的关注点只在数据上就可以了。另外,R语言是免费开源的,很多的第三方开发者提供了丰富的数据挖掘包,让你可以方便的使用各种算法模型,短短几行代码,就可以搞定一个复杂的事情。
R语言,在金融领域提供了很多交易框架或者计算模型,如果你了解了金融的理论知识以后,同时有一定的金融市场经验,你可以很方便的利用这些别人提供的这些技术框架,来构建自己的交易模型。CRAN上发布的金融项目,你可以去 R的官方网站 (https://cran.r-project.org/),找到Task Views 菜单里的 Finance标签。

通过调用第三方的程序包,自己的代码量就变的非常少。我们做一个R语言的策略,如果是很复杂的,你可能要写100-200行,但是如果你要实现同样复杂的策略,放到C++/Java去实现,这个策略就是没有1000-2000行是不可能实现的。在CRAN上面,简单数一下Finance标签下面列出的金融包就有141个,我相信没有哪种语言会比R语言对金融行业支持的更多了。

虽然说R语言在性能上有些问题,但是我们会有多少了交易策略是基于一种高频的模型,对性能要求极高的呢?其实很少。就算是高频交易策略,几秒钟交易一次,R语言都可能满足要求。
海量金融数据我们怎么处理呢?
我们可以把基于海量数据的计算变成离线模型,金融行业每天都会产生大量的数据,像每日产生的交易数据,中国市场每天可能都是以GB的量来增长,跟互联网比起来不是很快,但对于你程序加载10年的数据,他要GB或TB的一个量级。
R语言本身真的很难处理这种量级的数据,但是这种量级数据对于其他语言来说同样是很难处理的。我们并不需要把这种体量的数据,都加载到内存中,进行实时数据计算。变成离线的计算模型,仅用于建模回测。把海量数据能变成离线的方式,放到hadoop或spark计算,用海量数据进行模型的训练。
我们用到的实时数据,一般就是一天或几天的数据,会不很大,每天从开盘到收盘可能也就1-2GB,对于这个大小,我们完全有能力放到内存中,进行各种各样的计算。
做量化交易难点还是在于如何发现市场机会,R语言可以很好的满足数据计算,建模,分析等的所有技术的部分。利用你的擅长,找到市场的机会,然后去实盘交易赚到钱,我们就完成了整个的交易过程。
本文并没有介绍,如何用R语言真正的去实现一个交易策略,你可以通过下面的列表找到对应的文章。
2015年我在创业,希望能推动R语言在金融量化领域的发展,但是由于种种原因项目没有持续发展。接下来,我还会以个人的方式继续努力,继续推动R在金融领域的发展。R对我们的影响和改变是非常大的,我认识R是非常好的一门语言,我会把推动R的发展,当成一项事业来做。希望也能和各位业界朋友,一起努力,把这份事业做下去。
转载请注明出处:
http://blog.fens.me/r-finance/

[…] 本次分享的主题 R语言为量化而生,主要内容来自我的一篇博客文章:R语言为量化而生。希望能够解释清楚,在量化投资中为什么要用R语言。从程序员的角度看,C++,Java,Python, C#都是可行方案;从数据人员的角度看,Excel, SAS, Matlab更是不错的。那么为什么是R语言呢,R语言的优势在哪里体现? […]
[…] R语言程序实现,我们主要会用到2个包,quantmod和PerformanceAnalytics。对于为什么要用R语言,可以参考文章R语言为量化而生 […]