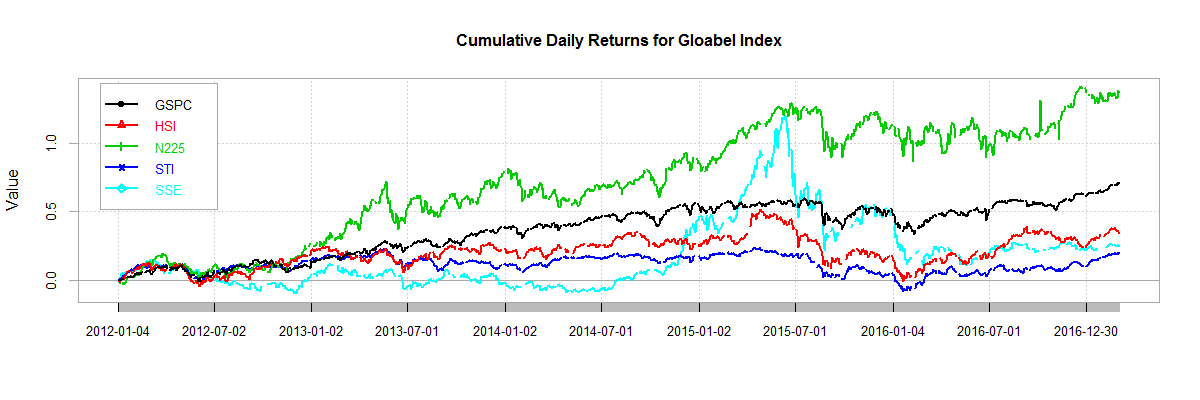
用IT技术玩金融系列文章,将介绍如何使用IT技术,处理金融大数据。在互联网混迹多年,已经熟练掌握一些IT技术。单纯地在互联网做开发,总觉得使劲的方式不对。要想靠技术养活自己,就要把技术变现。通过“跨界”可以寻找新的机会,创造技术的壁垒。
金融是离钱最近的市场,也是变现的好渠道!今天就开始踏上“用IT技术玩金融”之旅!
关于作者:
- 张丹(Conan), 程序员R,Nodejs,Java
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/finance-backtest

前言
经常看到做量化的朋友,晒出各种漂亮的回测曲线,准备一夜发家,但开始真金白银地去交易时,就会亏得一塌糊涂。
回测好,为什么实盘不靠谱?这里其实有很多的坑,不用钱买点教训,你是不会明白的。有经验的量化交易员,都是用钱磨炼出来。把你的回测慢慢贴近实盘,让回测结果越来越可靠。
本文为量子金服约稿文章。
目录
- 实例复盘
- 问题在哪?
- 量化理论和模型
1. 实例复盘
回测好,真的是因为策略好吗?
我们举个例子,你可能用到某个回测工具或平台,顺手复制了一个demo的代码,一点运行,就能跑出10%的收益率。接下来,你花了一个晚上彻夜研究,把参数用机器学习的方法来优化,黎明时,终于把收益率提高到了40%。虽然一夜没睡,但心里却是无限地兴奋,觉得多年所学的IT技术终于可以实现赚钱的理想了,金融市场不过如此。明天就先把1个月工资赚出来,下个月就辞职,再也不用看S*领导的脸色,真是浪费生命了。
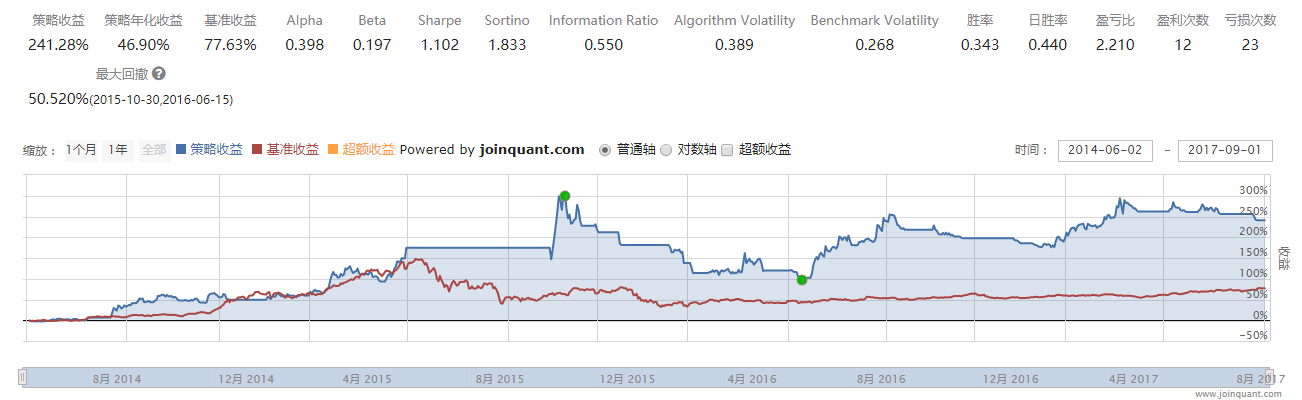
有过上面经历的同学,我想不在少数吧。第二天,就把打工2年多辛辛苦苦攒到的10万块投到了股市中。谁想股市风云变幻,不仅市场不仅没按照模型的方向走,而且又赶上严监管、去杠杆、大股东减持等等一系列的样本外事件发生,2个月后不仅没有赚到当初设想的钱,甚至亏损到了20%,感情上已经受不了,拒绝了之前定下的止损的规则,又经历了几周的连续下跌,最后亏损到达50%。
每天心都在滴血,连续3个月都是吃不好、睡不好,最后一咬牙全部割肉了。开始全盘怀疑自己,自信心被打击到了负值,封账号,再也不碰股市了。
2. 问题在哪?
那么,为什么回测好的策略实盘就不这么不靠谱呢?可能有以下几点原因。
2.1 算错了
当你的回测出现有显著的盈利时,最大的可能是你算错了。比如,在计算时写错了正负号、不应该用年化的时候用了年化的值,没有严格区别复权数据与非复权数据的区别、交易的周期没对齐、无风险收益率取值过小、四舍五入时保留位数过少、使用向理计算时出现的问题、NA值没有处理、使用了来自互联网的未经验证的数据等等。
总之各种的细节,都会让你的回测出错,而且如果你不理解每个指标的金融含义,你甚至都不知道自己错了。
2.2 未来函数
如果每个计算细节你都了解了,回测结果依然非常好,还是先别激动,检查一下是不是用到未来的函数。
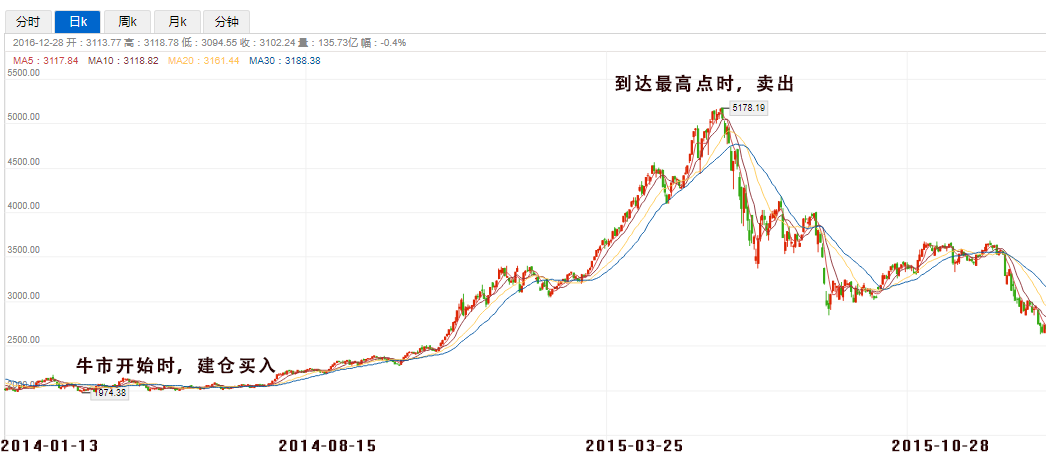
使用到未来函数也是很常见的一个问题,而且通常都是不知不觉的。比如,我们会经常听到股评分析师说:“在牛市开始时建仓买入,在到达最高点时卖出”,这其实就是用到了未来函数。在实际的交易过程中,我怎么会知道,什么时候是牛市的开始,又怎么会知道最高点是3600点还是5700点?如果我真的知道了,我还做什么量化交易,早就环游世界去了。
我们很多时候会都用已经知道的市场信息做回测,但实际交易时,你并不知道市场是什么样子的,会向什么方向变。比如,我们现在来看2017年上半年招商银行涨的很好,那么我就针对银行股开始做回测,而且给招商银行加大权重。在一切数据都算对的情况下,回测的资金曲线相当的漂亮,半年获得了30%以上的收益率,而且最大回撤控制在3%以内,夏普、詹森Alpha也都很不错,这些指标都表示了我的主动管理能力很强,我是个牛逼的基金经理。
真的是这样吗?你在不经意用到了未来函数,才使得你发现了招商银行,然后再对银行股做了回测,获得了较好的资金曲线。所以,这不是能力,也不是运气,是犯规了。
2.3 过拟合
从IT程序员转到金融的量化分析师们,在很多情况下都会用纯IT的方法,来解决金融建模的问题。比如,做了5年推荐系统的推荐算法专家,非常擅长用机器学习的方法,来找到数据之间的关系。于是就以纯数据的方式来切入,脱离金融的投资学理论,导致了数据的过度使用。通过历史数据试图预测未来,而且找到一条完美的投资曲线,穿过所有的样本点,最后将导致过拟合。
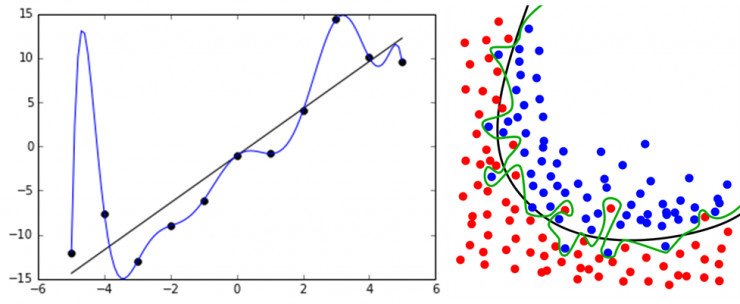
从IT转行到金融的朋友,通常有个特点,就是动手能力强,数据来就先丢到模型里,才不管到结果底能不能解释,反正我的回测曲线很漂亮。特别是深度学习,增强学习等方法的崛起,让程序员群体一下子高大上起来,通过一种算法,升维升维再升维,就能通吃所有的单一分类算法模型。这样的结果就是过拟合。回测曲线必然是非常漂亮的,但到实际环境一运行,就只能用惨不忍睹来形容了。
2.4 策略周期
从投资的角度,每种策略都有自己适应的场景。在合适的场景下,选到了适合的资产,那么你的策略会表现的非常棒。但是实际的金融市场是轮动的,资产配置随大的金融周期轮动,股票市场随着行业板块轮动。有可能你在回测的时候选对了风口,赶上了趋势,而实盘时候错过风口或者选错了金融资产,那么就会事与愿违了。
比如,你的策略就是研究债券的,从2016上半年到2017年上半年,选出了鹏华全球高收益债(000290)这支QDII基金,比国内的大部分债基表现都抢眼,走势非常稳定,持续上升,你坚定的买进加仓。但是不凑巧的是,你刚买入完,人民币就进入到了升值的区间,虽然债券本身是很稳定的,但人民币持续走强,由于汇率的影响让这支债基天天亏钱。如果你又懂债券又懂外汇,这个点没想到是能力问题。如果你完全不懂外汇,单从债券的角度考虑,那么就不是能力问题,也不是模型不行,而是运气太差,没把握到轮动的周期。
2.5 真实交易环境
真实的交易,是会被各种情况所影响的。当你的交易量过大时,你会影响市场,这时你的交易就会发生偏离,实际市场交易的冲击成本会比你回测时看到的成交量大得多,而且冲击成本又是很难被模拟和计算的。
当你购买流动性不好的金融产品时,模型的信号出来了,但是实际你却买不到,或者卖不出去,当你被迫用对手价来成交时,就会有比较大的滑点。滑点对于高频交易来说是致命的,对于长周期的趋势交易策略,倒是影响不大。
手续费也是一个不容小觑的因素,2017年7月开始黑色系商品期货被猛炒,焦炭、焦煤的平今手续费上调至3倍,铁矿石平今手续费上调到2倍。这种政策性的调整,在研发模型时是不可预知的,平今手续费的上调,直接就拍死了日内模型。2015年调整的股指期货的40倍手续费,几乎把所有的投机的模型都干掉了。
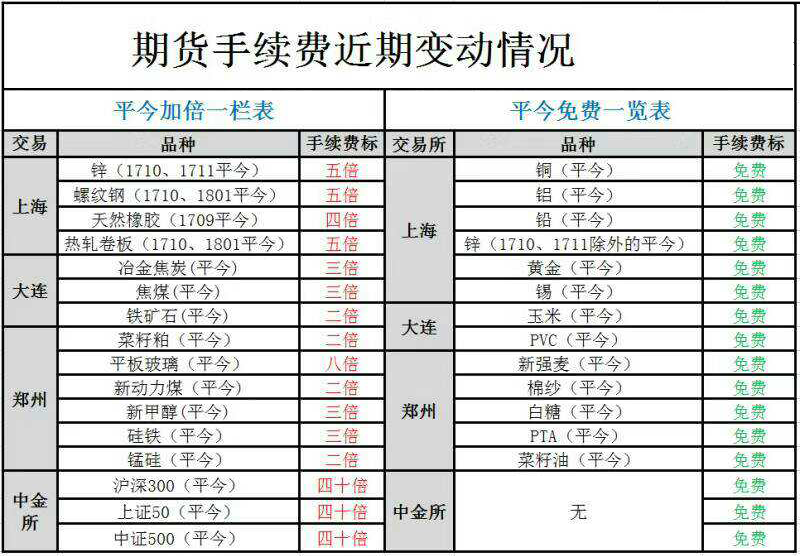
股票市场也很多真实交易环境的特殊性,比如2016年初开始试行的熔断机制,一共4天,发生了多次恐慌性的挤兑,上证指数下跌488.87点,相比4天前收盘点位下跌了13.8%,A股蒸发市值逾6万亿。
当然,也有一些真实交易环境中的乌龙指,有时会我们带来一些额外的惊喜。
真实交易环境是复杂的,也是很难在回测环境中模拟的,所以要深刻了解金融市场、了解市场运作的原理,你才能规避真实交易环境与回测环境中的差异点。
2.6 人工干预
还有一种情况,就是人工干预。当你建好一个模型,应用到实盘的时候,你要充分地相信你的模型,并且严格的执行。每当遇到回撤的时候,你依然要相信你的模型,坚持模型的策略。
如果你心理抗不住,开始干预时,也会造成回测与实盘的偏差。这个时候,就很难判断是模型不靠谱,还是人不靠谱了。每当我在干预实盘模型的时候,调来调去,觉得及时止盈止损了,实际上是在破坏自己的规则,更加影响了策略的稳定性。
当然,可能还有更多的原因,让回测到实盘有很大的差距。我们需要认真地思考,把每个细节都去实践,慢慢地才能让你的回测越来越接近实盘的效果。
3. 量化理论和模型
从专业角度来讲,投资就是要找到市场的规律,而规律的本质是符合金融市场的简单逻辑。赚钱的模型,通常都是很巧妙的把规律进行量化。
任何模型或者理论,第一步都是提出假设,定义应用场景,解决什么问题。
- 趋势追踪模型,是用移动平均来反应金融产品发展趋势的规律,请参考文章二条均线打天下。
- 均值回归模型,是价格偏离均衡价格水平一定程度后向均衡价格靠拢的规律,请参考文章 均值回归,逆市中的投资机会 。
- 追涨杀跌模型,是一定时期内强势资产能够延续上涨的规律,请参考文章 R语言构建追涨杀跌量化交易模型。
- 配对交易模型,是两个具有均衡关系的金融产品,价格走势出现背离的规律,请参考文章 R语言构建配对交易量化模型。
如果我们能够做出正确的假设,当然是可以赚到钱的,能够赚大钱还是赚小钱,就是运气了。
《海龟交易法》流行了很多年,至今仍然被广大的交易员所使用,书中所讲述是就是金融市场的规律。假设条件越简单,回测可能越靠谱,会越贴近实盘。
转载请注明出处:
http://blog.fens.me/finance-backtest