用IT技术玩金融系列文章,将介绍如何使用IT技术,处理金融大数据。在互联网混迹多年,已经熟练掌握一些IT技术。单纯地在互联网做开发,总觉得使劲的方式不对。要想靠技术养活自己,就要把技术变现。通过“跨界”可以寻找新的机会,创造技术的壁垒。
金融是离钱最近的市场,也是变现的好渠道!今天就开始踏上“用IT技术玩金融”之旅!
关于作者:
转载请注明出处:
http://blog.fens.me/finance-mojie

前言
进入2016年,伴随世界经济危机的到来,中国互联网创业,也在经历长时间的寒冬,有不少的公司都因资金链断裂,停止了运营。与寒冬反差很大的是,AI技术却火了起来,受到资本的追捧。智能投顾作为金融领域的AI热点,一直在持续升温。
到2016年底,招商银行发布了一个名为“摩羯智投”的应用,一下子吸引了众多人的眼球,打开了银行进军智能投顾领域的大门。本文将用数据来解读“摩羯智投”的到底是怎么玩的。
目录
- 摩羯智投介绍
- 数据收集
- 数据建模分析
- 结论
1. 摩羯智投介绍
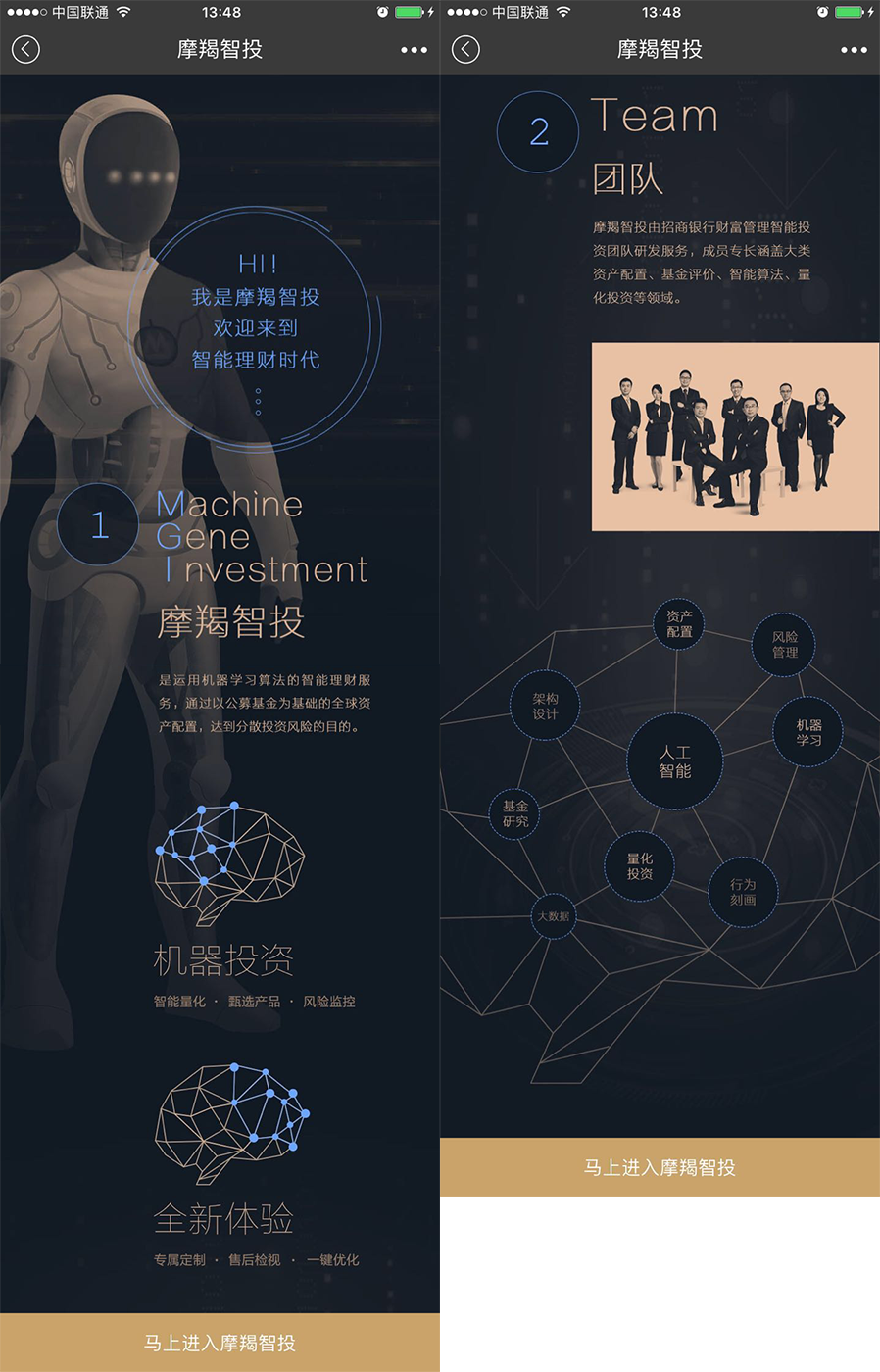
摩羯智投,是招商银行在2016年12月6日发布的一款手机端应用,嵌入在招商银行的APP中,加入了FinTech理念,把金融和人工智能进行了结合。
按招商银行发布的文章中介绍,摩羯智投是运用机器学习算法,构建的以公募基金为基础的、全球资产配置的“智能基金组合配置服务”。在客户进行投资期限和风险收益选择后,摩羯智投会根据客户自主选择的“目标—收益”要求、构建基金组合,由客户进行决策、“一键购买”并享受后续服务。
摩羯智投并非一个单一的产品,而是一套资产配置服务流程,它包含了目标风险确定、组合构建、一键购买、风险预警、调仓提示、一键优化、售后服务报告等,涉及基金投资的售前、售中、售后全流程服务环节。比如,摩羯智投会实时进行全球市场扫描,根据最新市场状况,去计算最优组合比例,如果客户所持组合偏离最优状态,摩羯智投将为客户提供动态的基金组合调整建议,在客户认可后,即可自主进行一键优化。
摩羯智投的开机画面。
看完招商银行官方的介绍,接下来我们从数据进行分析,看看“摩羯智投”到底有多智能。
2. 数据收集
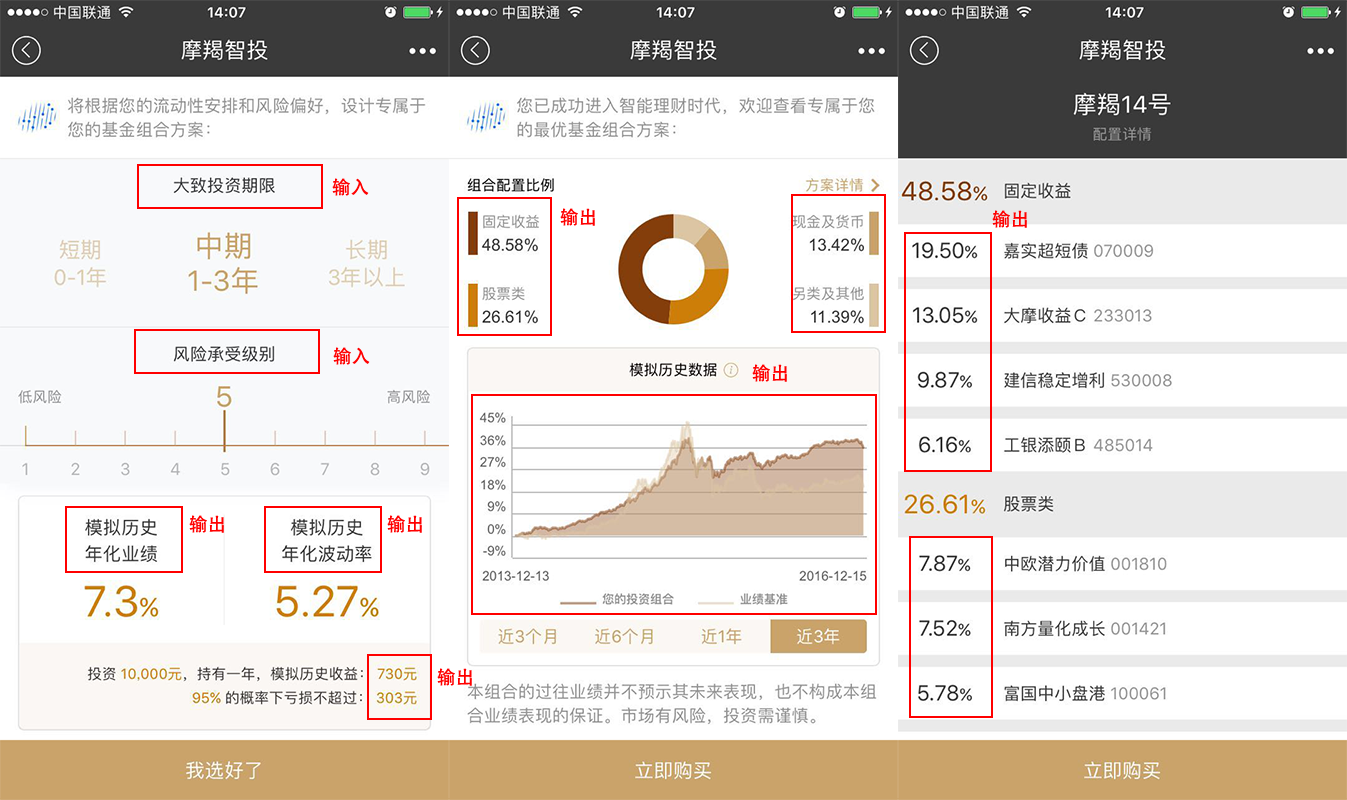
要做数据分析,我们就要以数据来思考。我的思路,要先收集数据,把应用所有的输入项和输出项的数据进行整理,然后我们通过统计的方法和金融知识来找到数据之间的关系。
注:由于应用中没有明确的字段定义,下面字段我按照字面意思进行解读。
数据输入项只有2个字段,包括
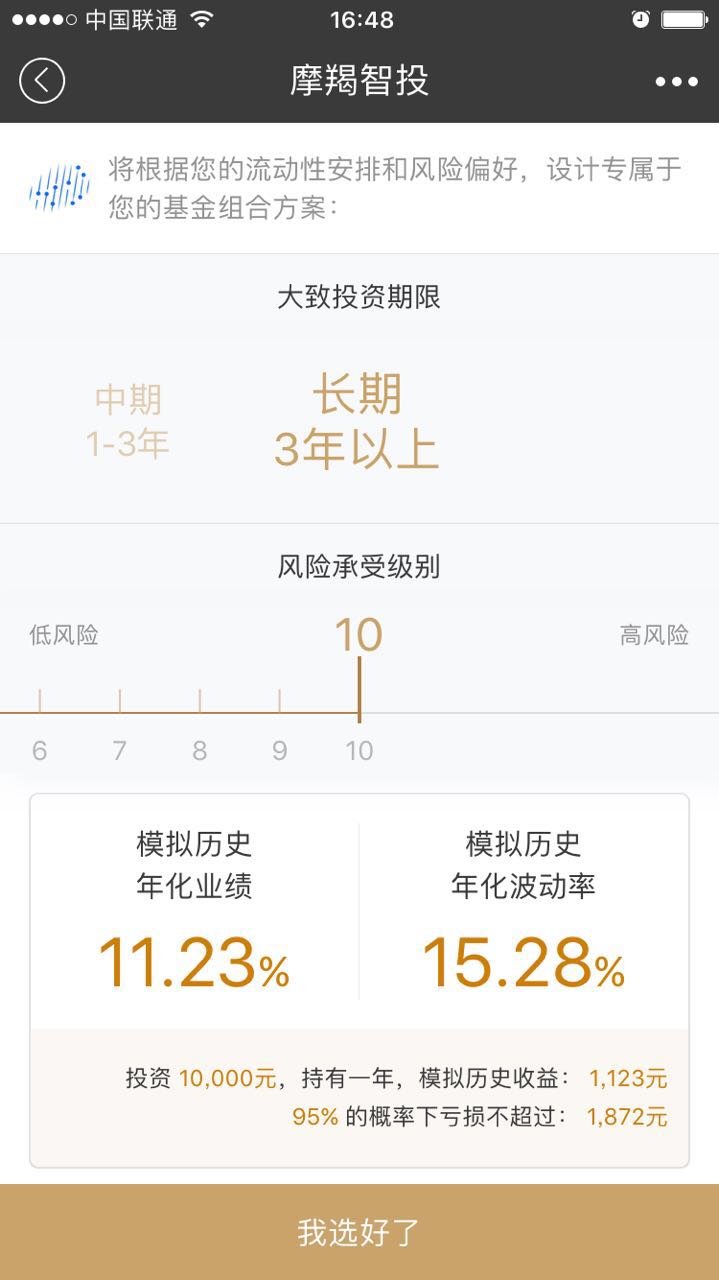
- 大致投资期限:从投资开始到投资结束的期限。
- 风险承受能力:承担多大的风险,以及风险带来的损失。
数据输出项,字段就比较多,包括
- 模拟历史年化收益(%):对历史数据回测,所获得的年化收益率。
- 模拟历史年化波动率(%):对历史数据回测,所获得的年化波动率。
- 模拟历史收益(元):在投资10000元,并持有一年,所获得的收益金额。
- 95%的概率下亏损(元):在95%概率下最大亏损金额。
- 固定收益(%):固定收益类基金的配置比例。
- 现金及货币(%):现金货币类基金的配置比例。
- 股票类(%):股票类基金的配置比例。
- 另类及其他(%):另类投资的类基金的配置比例。
- 投资组合收益率曲线:按比例构成的组合,生成的收益率曲线。
- 投资组合配置详情:4类资产对应的具体基金品种和配置比例
对应到“摩羯智投”的操作界面上,我标出了输入数据和输出数据的提取点。
根据界面来收集到的数据,整理为CSV格式,便于之后的分析。数据收集,我分别存储到了3个CSV文件中。
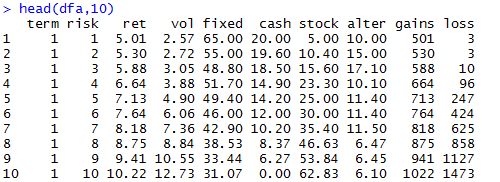
- a.csv:用于收集第1-2个界面的数据,用户直接输入和输出数据,包括:大致投资期限(term),风险承受能力(rick),模拟历史年化收益(ret),模拟历史年化波动率(vol),模拟历史收益(gains),亏损(loss),固定收益(fixed),现金及货币(cash),股票类(stock),另类及其他(alter)
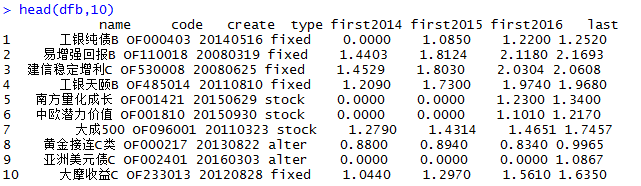
- b.csv:用于收集所有标的基金所对应的市场数据,从wind中采集,包括:基金名称(name),基金代码(code),基金成立时间(create),基金类型(type),净值20140101(first2014),净值20150101(first2015),净值20160101(first2016),净值20161208(last)
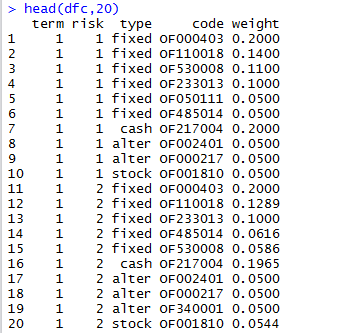
- c.csv:用于收集第3个界面的数据,每个组合的标的基金的配置比例,包括:大致投资期限(term),风险承受能力(rick),基金类型(type),基金代码(code),配置比例(weight)
a.csv的数据样例前10条,如下:
b.csv的数据样例前10条,如下:
c.csv的数据样例前20条,如下:
这里还需要特别说明的事,由于应用的数据,可能会动态的发生变化,我是采集的2016年12月8日的“摩羯智投”应用中的数据。
多说一句,数据花点时间谁都可以在应用中拿到,虽然我已经整理了数据,但请大家不要太随意地张嘴要数据和代码,毕竟写一篇文章非常辛苦。如果你想直接用我的数据和代码,请扫文章下面二维码,请作者喝杯咖啡吧。 :_D
3. 数据建模分析
收集好了数据,接下来就可以进行数据分析了。当然,分析的角度有很多种,可以从金融、统计、数据挖掘等专业方向,也可以计算一些简单的指标,最大值,最小值,平均值等等。我思考的出发点,主要在金融和统计上面,如果存在片面性,还请大家给予指正。
下面将从6个知识点,对“摩羯智投”进行分析。
3.1 分析一:只有2个输入项。
由于只有2个输入项,大致投资期限和风险承受能力。大致投资期限有3个选项,风险承受能力有10个选项,那么实际的组合个数就是3*10=30个。对于只有30个组合来说,并不能完全实现个性化,当有31个用户使用产品时,就会有2个人购买的组合是是重复的。
3.2 分析二:只有17只标的基金
我们对30个组合进行配置尝试后,发现详细持仓方案中,只有17只基金,配置比例不同而矣。标的过少,可能导致风险不能足够的分散化,遇到极端行情会导致大的回撤。17只基金分别是
> paste(dfb$name,"(",dfb$code,")",sep="")
[1] "工银纯债B(OF000403)" "易增强回报B(OF110018)" "建信稳定增利C(OF530008)"
[4] "工银天颐B(OF485014)" "南方量化成长(OF001421)" "中欧潜力价值(OF001810)"
[7] "大成500(OF096001)" "黄金接连C类(OF000217)" "亚洲美元债C(OF002401)"
[10] "大摩收益C(OF233013)" "博时信用债C(OF050111)" "兴权可转债(OF340001)"
[13] "创金多因子(OF002210)" "招商现金增值A(OF217004)" "富国中小盘(OF100061)"
[16] "工银瑞信全球(OF486002)" "南方成份(OF202005)"
3.3 分析三:相关性分析
直接利用a.csv的数据集,查看输入项和输出项的相关性,发现相关关系。
通过R语言程序实现
# 加载数据
> dfa<-read.csv(file="a.csv")
> names(dfa)<-c("term","risk","ret","vol","fixed","cash","stock","alter","gains","loss")
# 画出配对示意图
> pairs(df)
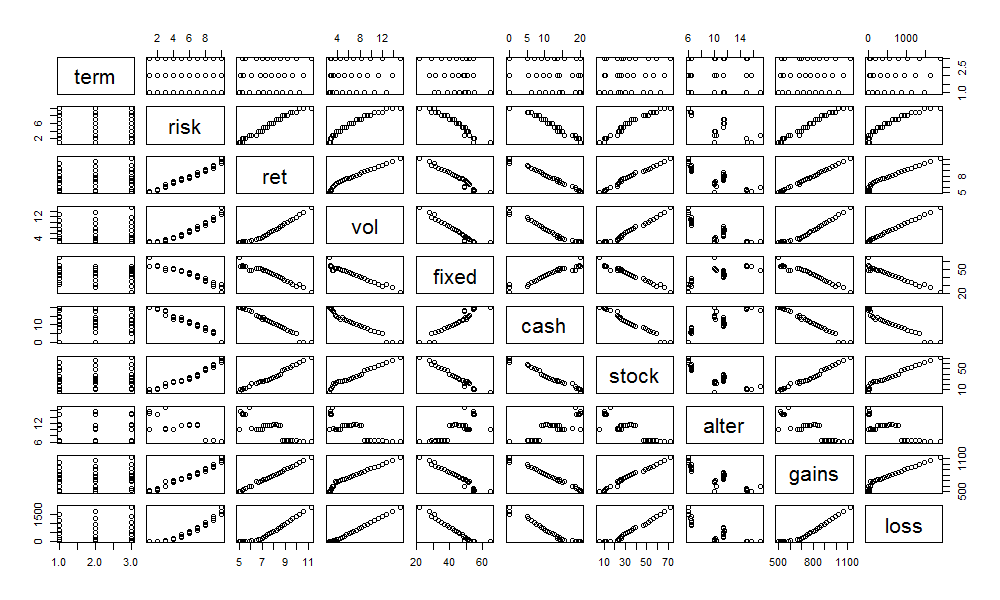
把数据变成可视化来显示,对于我们理解数据非常有帮助。
- term列,和其他列的散点图,完全呈现离散的分布,说明term列与其他列并没有相关性的关系。
- risk列,除了和alter列没有线性关系,和其他列呈现明显的线性关系。
我们把上面相关性图,再加上一些元素,如相关系数、拟合曲线、分布图等,重新画出相关性图,如下所示。
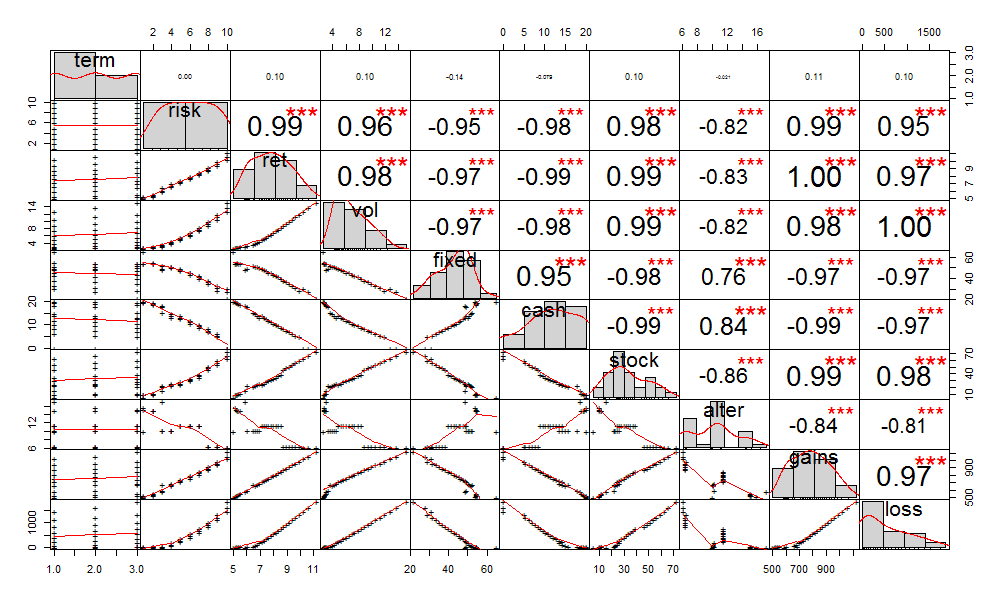
这样就清晰了多了。
- risk列,与模拟历史年化收益(ret),模拟历史年化波动率(vol),拟历史收益(gains),呈现极度正相关,输出项的数字完全受risk值影响。
- risk列,与固定收益(fixed)和现金及货币(cash),极度负相关;与股票类(stock),极度正相关;另类及其他(alter),负相关。这种情况,与资产的风险收益属性是匹配。
- vol列,与亏损(loss),是100%线性相关。
- ret列,与拟历史收益(gains),是100%线性相关,这里可以获得公司:gains = 10000 * ret 。
3.4 分析四:线性回归
通过相关性的检查,我们可以发现risk与很多列都是极度相关的。
那么我们可以用线性回归的方法,把risk与有相关性的列的参数估计出来。如果不太了解,一元线性回归的可以参考文章,R语言解读一元线性回归模型。
由于vol和loss是100%线性相关,以vol为x,loss为y,构建一元线性回归方程。
# 回归方程
> lv<-lm(loss~vol,data=dfa)
> summary(lv)
Call:
lm(formula = loss ~ vol, data = dfa)
Residuals:
Min 1Q Median 3Q Max
-36.119 -31.491 -6.621 27.884 67.305
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -447.514 13.056 -34.28 <2e-16 ***
vol 149.109 1.707 87.34 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 34.2 on 28 degrees of freedom
Multiple R-squared: 0.9963, Adjusted R-squared: 0.9962
F-statistic: 7629 on 1 and 28 DF, p-value: < 2.2e-16
进行线性回归的统计检查:T检查,F检查都非常显著,同时R-squared为0.9963,具有极度相关性。
# 画出散点图和拟合曲线
> plot(loss~vol,data=dfa)
> abline(lv)
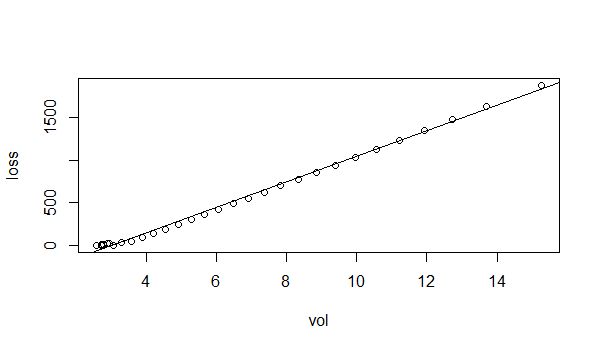
从图中看到,拟合效果非常好,可以整理出公式:loss = -447.514 + 149.109*vol。
另外,由于risk决定vol,再让我们算一下risk和loss的关系,以risk为x,loss为y,构建一元线性回归方程。
# 构建一元线性回归方程
> lm(loss~risk,data=dfa)
Call:
lm(formula = loss ~ risk, data = dfa)
Coefficients:
(Intercept) risk
-435.8 180.0
# 详细指标
> summary(lr)
Call:
lm(formula = loss ~ risk, data = dfa)
Residuals:
Min 1Q Median 3Q Max
-219.88 -136.93 -59.26 100.69 508.31
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -435.84 72.38 -6.021 1.73e-06 ***
risk 179.95 11.67 15.426 3.23e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 183.5 on 28 degrees of freedom
Multiple R-squared: 0.8947, Adjusted R-squared: 0.891
F-statistic: 238 on 1 and 28 DF, p-value: 3.232e-15
T检查和F检查,非常显著;R-squared 也比较高。
下面进行残差检查,发现30号点,是偏离比较大,可能是离群值。
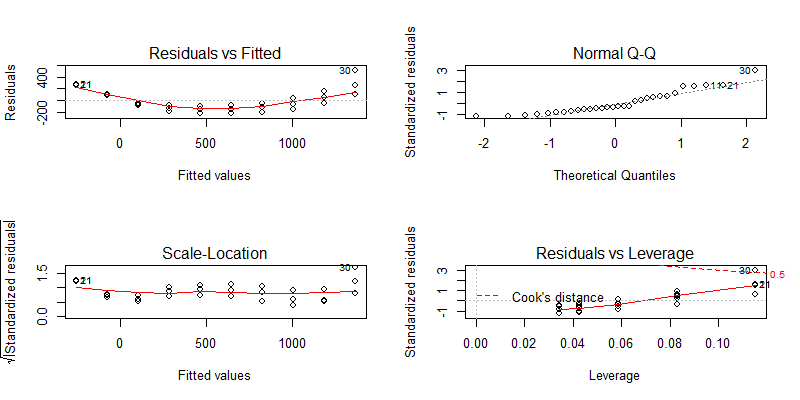
我们把30号点去掉,再做显著性检查和残差分析。
> dfa2<-dfa[-30,]
> lr2<-lm(loss~risk,data=dfa2)
> summary(lr2)
Call:
lm(formula = loss ~ risk, data = dfa2)
Residuals:
Min 1Q Median 3Q Max
-203.00 -100.98 -58.98 83.53 327.46
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -397.55 62.23 -6.389 7.64e-07 ***
risk 169.51 10.32 16.431 1.39e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 155.3 on 27 degrees of freedom
Multiple R-squared: 0.9091, Adjusted R-squared: 0.9057
F-statistic: 270 on 1 and 27 DF, p-value: 1.391e-15
在去掉30号点后,R-squared为0.9091,比之前的0.8947,有所提升。
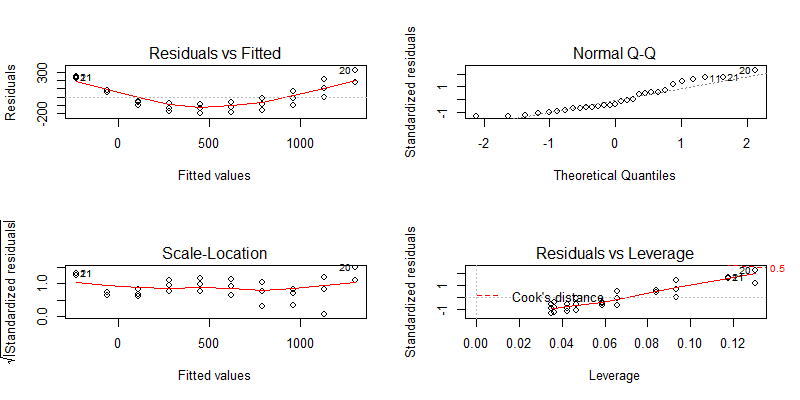
从残差图中,我们看到没有明显的离群值点,所以去掉30号点,是符合统计提升标准的。
3.5 分析五:关于30号点的金融思考
从数据中,我们发现30号点的最大亏损已经超过了收益,也就是说你可能承担了过大了风险,但是没有获得风险所给你带来的收益。
按照资本资产定价模型的理解,我们投资组合的收益来自2部分,无风险收益和风险收益。无风险收益可以用现金或货币类的基金获得,风险收益主要来自股票基金,债券基金,另类投资最基金。直观上理解,风险收益比至少是1:1,即损失100元时,要获得100元风险补偿。对于私募业务来说,投资人可能会要求更高,比如 风险:收益=1:2。
从另外一个角度分析,上面我所说的风险收益比并没有涉及到概率的部分,我猜95%是通过VaR值来做的概率计算。
3.6 分析六:通过标的基金计算收益率
在“摩羯智投”的应用中,我们可以获得各个基金的配置比例,基金净值的数据又可以在公开市场中获得,所以对于预期收益率,我们也可以自己计算一下,看看是不是与“摩羯智投”提供的结果是一致的。
接下来,就利用到上文介绍的数据集,b.csv和c.csv。
# 加载数据
> dfb<-read.csv(file="b.csv",encoding="utf-8",fileEncoding = "utf-8")
> names(dfb)<-c("name","code","create","type","first2014","first2015","first2016","last")
# 分别计算2014,2015,2016收益率
> dfb$ret2014<-(dfb$first2015-dfb$first2014)/dfb$first2014
> dfb$ret2015<-(dfb$first2016-dfb$first2015)/dfb$first2015
> dfb$ret2016<-(dfb$last-dfb$first2016)/dfb$first2016
# 把非法值赋值为0
> dfb$ret2014[c(which(is.na(dfb$ret2014)),which(is.infinite(dfb$ret2014)))]<-0
> dfb$ret2015[c(which(is.na(dfb$ret2015)),which(is.infinite(dfb$ret2015)))]<-0
> dfb$ret2016[c(which(is.na(dfb$ret2016)),which(is.infinite(dfb$ret2016)))]<-0
# 打印前6条
> head(dfb)
name code create type first2014 first2015 first2016 last ret2014 ret2015 ret2016
1 工银纯债B OF000403 20140516 fixed 0.0000 1.0850 1.2200 1.2520 0.00000000 0.12442396 0.026229508
2 易增强回报B OF110018 20080319 fixed 1.4403 1.8124 2.1180 2.1693 0.25834896 0.16861620 0.024220963
3 建信稳定增利C OF530008 20080625 fixed 1.4529 1.8030 2.0304 2.0608 0.24096634 0.12612313 0.014972419
4 工银天颐B OF485014 20110810 fixed 1.2090 1.7300 1.9740 1.9680 0.43093466 0.14104046 -0.003039514
5 南方量化成长 OF001421 20150629 stock 0.0000 0.0000 1.2300 1.3400 0.00000000 0.00000000 0.089430894
6 中欧潜力价值 OF001810 20150930 stock 0.0000 0.0000 1.1010 1.2170 0.00000000 0.00000000 0.105358765
由于基金中,招商现金增值A(OF217004)为现金类基金,所以收益率需要直接取年化收益,而不是按上面的计算方法。
#现金类,收益率从wind查年化收益率,进行赋值
dfb[which(dfb$code=='OF217004'),]$ret2014<-0.0452
dfb[which(dfb$code=='OF217004'),]$ret2015<-0.036
dfb[which(dfb$code=='OF217004'),]$ret2016<-0.0237
再加载c.csv基金的详细配置方案。
> dfc<-read.csv(file="c.csv")
> names(dfc)<-c("term","risk","type","code","weight")
# 查看数据
> head(dfc)
term risk type code weight
1 1 1 fixed OF000403 0.20
2 1 1 fixed OF110018 0.14
3 1 1 fixed OF530008 0.11
4 1 1 fixed OF233013 0.10
5 1 1 fixed OF050111 0.05
6 1 1 fixed OF485014 0.05
把数据变型,以type列转置为横表,去掉code列,以weight值进行填充,得到新数据集为r1。
> head(r1)
term risk alter cash fixed stock
1 1 1 0.1000 0.2000 0.6500 0.0500
2 1 2 0.1500 0.1965 0.5491 0.1044
3 1 3 0.1562 0.1842 0.4881 0.1715
4 1 4 0.1011 0.1490 0.5162 0.2337
5 1 5 0.1137 0.1416 0.4943 0.2504
6 1 6 0.1143 0.1208 0.4655 0.2994
我们生成plan1的配置方案,当term=1,risk=1时。
# 只保留term=1,risk=1时数据
> plan1<-dfc[dfc$term==1 & dfc$risk==1,]
# 合并plan1数据集和dfb数据集
> plan1m<-merge(plan1[,c("term","risk","code","type","weight")],dfb[,c("code","ret2014","ret2015","ret2016")],by="code")
# 按分配比例计算收益率
> plan1m$ret2014w<-plan1m$weight*plan1m$ret2014
> plan1m$ret2015w<-plan1m$weight*plan1m$ret2015
> plan1m$ret2016w<-plan1m$weight*plan1m$ret2016
# plan1的,各基金分别在2014,2015,2016贡献的收益率
> plan1m
code term risk type weight ret2014 ret2015 ret2016 ret2014w ret2015w ret2016w
1 OF000217 1 1 alter 0.05 0.01590909 -0.06711409 0.194844125 0.0007954545 -0.003355705 0.0097422062
2 OF000403 1 1 fixed 0.20 0.00000000 0.12442396 0.026229508 0.0000000000 0.024884793 0.0052459016
3 OF001810 1 1 stock 0.05 0.00000000 0.00000000 0.105358765 0.0000000000 0.000000000 0.0052679382
4 OF002401 1 1 alter 0.05 0.00000000 0.00000000 0.000000000 0.0000000000 0.000000000 0.0000000000
5 OF050111 1 1 fixed 0.05 0.87631433 0.12603844 0.034050727 0.0438157167 0.006301922 0.0017025363
6 OF110018 1 1 fixed 0.14 0.25834896 0.16861620 0.024220963 0.0361688537 0.023606268 0.0033909348
7 OF217004 1 1 cash 0.20 0.04520000 0.03600000 0.023700000 0.0090400000 0.007200000 0.0047400000
8 OF233013 1 1 fixed 0.10 0.24233716 0.20354665 0.047405509 0.0242337165 0.020354665 0.0047405509
9 OF485014 1 1 fixed 0.05 0.43093466 0.14104046 -0.003039514 0.0215467328 0.007052023 -0.0001519757
10 OF530008 1 1 fixed 0.11 0.24096634 0.12612313 0.014972419 0.0265062977 0.013873544 0.0016469661
把数据进行合并,分别计算plan1方案的收益率,和plan1方案不同资产的收益率贡献。
# plan1方案的收益率
> plan1r<-ddply(plan1m,.(term,risk),summarise,ret2016=sum(ret2016w),ret2015=sum(ret2015w),ret2014=sum(ret2014w))
> plan1r
term risk ret2016 ret2015 ret2014
1 1 1 0.03632506 0.09991751 0.1621068
#计算3年的累积收益率曲线
> plan1r$cumret<-sum(c(plan1r$ret2016,plan1r$ret2015,plan1r$ret2014))
> plan1r
term risk ret2016 ret2015 ret2014 cumret
1 1 1 0.03632506 0.09991751 0.1621068 0.2983493
# plan1方案不同资产的收益率贡献
> plan1rm<-ddply(plan1m,.(term,risk,type),summarise,ret2016=sum(ret2016w),ret2015=sum(ret2015w),ret2014=sum(ret2014w))
> plan1rm
term risk type ret2016 ret2015 ret2014
1 1 1 alter 0.009742206 -0.003355705 0.0007954545
2 1 1 cash 0.004740000 0.007200000 0.0090400000
3 1 1 fixed 0.016574914 0.096073214 0.1522713174
4 1 1 stock 0.005267938 0.000000000 0.0000000000
用我计算的结果,分别对比“摩羯智投”中,近1年和近3年的收益率曲线。
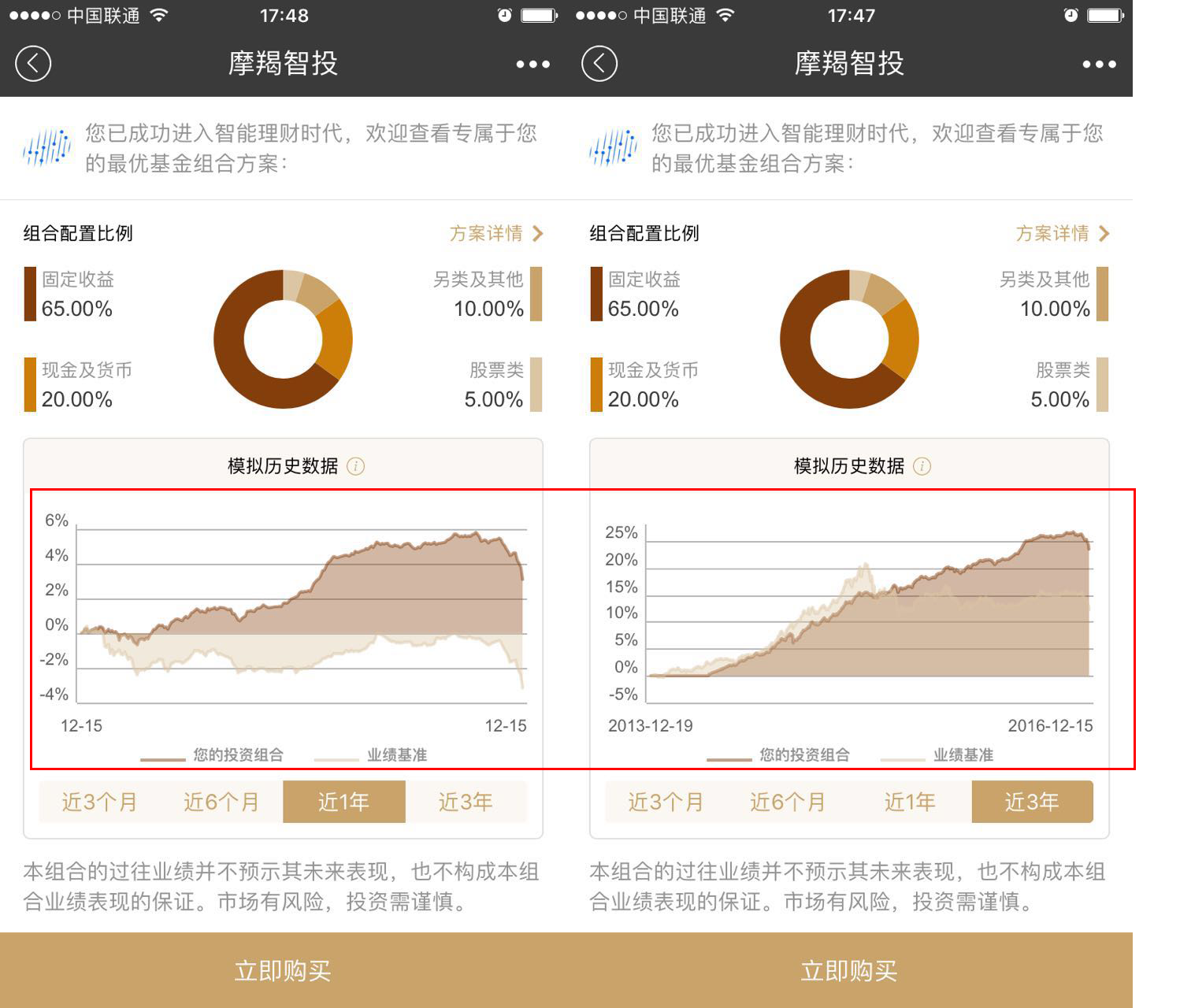
近1年对应plan1r$ret2016=0.03632506=3.63%,近3年对应plan1r$cumret=0.2983493=29.83%。我发现计算结果存在差异,从最终结果的数字上来看差异并不大。但对于近3年的收益率曲线的走势来看,差异还是非常明显的。“摩羯智投”给出的近3年收益率曲线是,均匀平稳上升的,而我算出来的,3年数据2014年涨了16%,2015年涨了9%,2016年涨了3%,逐年收益率在递减。所以不应该呈现均匀平稳上升的形状。
究其原因,再来看plan1的组合数据,发现股票基金只有配了一只中欧潜力价值(OF001810),而这只基金在2015年09月30日才成立,所以并不能构建出该基金在2014,2015的年度收益率组合。以此来判断,这个组合势必存在着中间调仓的过程,而“摩羯智投”的收益率曲线,并没有展示出调仓过程的数据,所以收益率曲线是不透明的,不能够直接做为用户购买决策的依据。
接下来,我们把30种组合的收益率,都计算出来。再与“摩羯智投”给出的收益率进行比较。
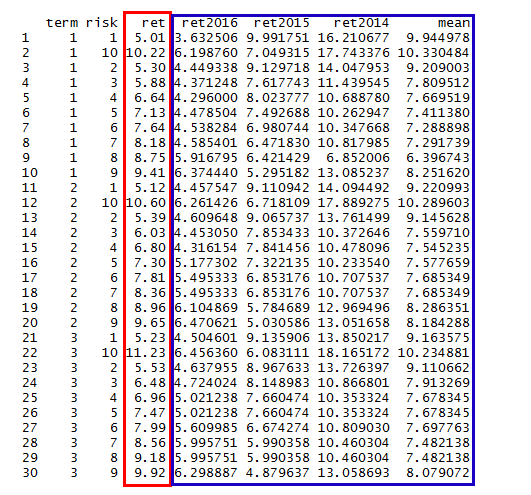
上图中,ret列为“摩羯智投”界面上采集的数据;ret2016,ret2015,ret2014分别为我们根据基金的公开市场的数据,计算出来的百分比结果;mean为ret2016,ret2015,ret2014算数平均数。从数据上看,ret列和mean列,有部分值接近。我们再做一次相关性分析。
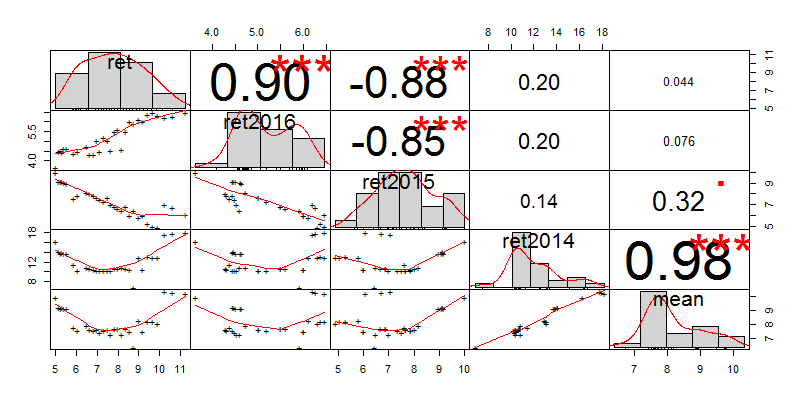
这样解读结果就容易多了,ret与2016年的收益率是线性相关的,而mean与2014年的收益率是线性相关的,我猜2014底的“股债双牛”使均值发生了偏离。所以,ret和mean没有关系,“摩羯智投”对于收益率的预期,对于近1年的组合收益可能有更大的权重分配。
所以对于“摩羯智投”给出预期收益和净值曲线,我们并不能通过已知的数据计算出来,这些可能就涉及到它背景的算法,我们就无从知晓了。
4. 结论
以上从数据的角度给对“摩羯智投”进行了分析,首先摩羯构建的组合是线性组合,符合风险收益为基础资本资产定价模型(CAPM)。但由于组合数量有限,基金标的有限,算法不够透明、无法利用已知数据重现结果,缺少客户持续跟踪等部分,所以我把“摩羯智投”理解为是基于金融专业性架构,结合快速上线为目标的试水。可以实现对散户的简单、高效的财富管理体验,部分解放理财经理的压力。但对于专业的投资经理来说,这还仅仅是个玩具,还有相当大的提升空间。
本文只是人个出于兴趣,对“摩羯智投”应用的从数据角度的分析,不代表任何公司或其他第三方机构的立场。由于所获得数据有限,以及个人知识能力有限,如有片面的理解,还指大家指正。
转载请注明出处:
http://blog.fens.me/finance-mojie