R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹,分析师/程序员/Quant: R,Java,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-crypto-aes/
前言
本文是介绍openssl包使用的第二篇文章,主要介绍AES算法的使用,还搭配了digest包做对比。虽然R语言不是专门做密码研究的工具,但实现个算法还是很方便的。作为数据分析师又学到了一些冷门知识,说不定哪天就会有用呢。openssl的文章分别是,R语言进行非对称加密RSA,R语言进行AES对称加密,R语言配合openssl生成管理应用x509证书,用R语言实现RSA+AES混合加密。
加密算法涉及到密码学的很多深入的知识,我并没有深入研究,本文只针对于openssl的使用,如果有任何与专业教材不符合的描述,请以专业教材为准。
目录
- AES算法介绍
- 用digest包进行AES加密解密
- 用openssl包进行AES加密解密
1. AES算法介绍
AES高级加密标准(Advanced Encryption Standard)为最常见的对称加密算法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES(Data Encryption Standard)。
AES的区块长度固定为128位,密钥长度则可以是128 bit,192 bit 或256位 bit 。换算成字节长度,就是密码必须是 16个字节,24个字节,32个字节。AES密码的长度更长,破解难度就增大了,所以就更安全。
AES 是对称加密算法,优点:加密速度快;缺点:如果秘钥丢失,就容易解密密文,安全性相对比较差。RSA 是非对称加密算法 , 优点:安全 ;缺点:加密速度慢。RSA算法介绍,请参见文章用openssl生成RSA私钥和公钥。
AES算法的使用场景,发送方将要发送的明文数据X使用秘钥K进行AES加密后会得到密文Y,将密文进行网络传输,接受方在收到密文Y后使用秘钥K进行AES解密后技能得到明文X,这样即使密文Y在网络上传输时被截获了,没有秘钥也难以破解其真实意思。
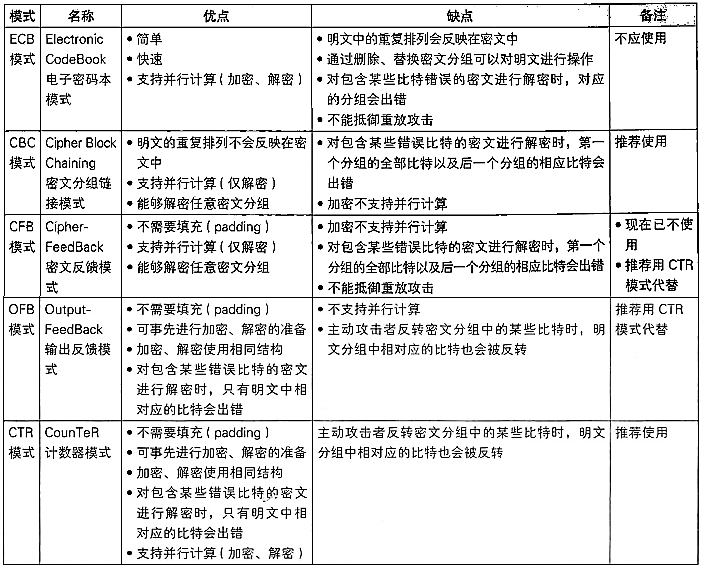
AES的加密模式有以下几种
- 电码本模式(Electronic codebook,ECB):需要加密的消息按照块密码的块大小被分为数个块,并对每个块进行独立加密。
- 密码分组链接模式(CBC):将整段明文切成若干小段,然后每一小段与初始块或者上一段的密文段进行异或运算后,再与密钥进行加密。
- 计算器模式(CTR):每个分组对应一个逐次累加的计数器,并通过对计数器进行加密来生成密钥流。
- 密码反馈模式(CFB):前一个密文分组会被送入密码算法的输入端,再将输出的结果与明文做异或。与ECB和CBC模式只能够加密块数据不同,CFB能够将块密文(Block Cipher)转换为流密文。
- 输出反馈模式(OFB):前一组密码算法输出会输入到下一组密码算法输入。先用块加密器生成密钥流,然后再将密钥流与明文流异或得到密文流,解密是先用块加密器生成密钥流,再将密钥流与密文流异或得到明文,由于异或操作的对称性所以加密和解密的流程是完全一样的。
在这五种模式里,只有ECB和CBC模式明文数据要求填充至长度为分组长度(16)的整数倍,因为ECB,CBC的加密运算会影响结果,而OFB,CFB,CTR只是最后一步的异或明文,所以不会影响结果,所以我们需要填充。
2. 用digest包进行AES加密解密
我们可以使用digest包的AES函数,进行AES的加密和解密操作,digest包的详细介绍,请参考文章R语言创建哈希摘要digest
使用AES函数时,需要输入3个参数:key, mode, IV。
- key, 分别作为AES-128、AES-192或AES-256,对应为16、24或32字节的原始向量的密钥。
- mode, 要使用的加密模式。目前只支持 “电子密码本”(ECB)、”密码块链”(CBC)、”密码反馈”(CFB)和 “计数器”(CTR)模式。
- IV,偏移量,在CBC和CFB模式的初始向量或CTR模式的初始计数器
2.1 ECB模式
使用ECB模式进行加密,可以使用同一个AES实例进行加密和解密。要求输入的原始数据为16的整数倍。
> library(digest)
# 把明文的转成二进制数据
> msg<- as.raw(c(1:16,1:32));msg
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
[36] 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20
# key转成二进制数据
> key <- as.raw(1:16)#;key
# 建立ECB的AES实例
> aes <- AES(key, mode="ECB")
# 加密
> a<-aes$encrypt(msg)
# 解密
> b<-aes$decrypt(a, raw=TRUE);b
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
[36] 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20
2.2 CBC模式
使用CBC模式进行加密时,不能使用同一个AES实例进行加密和解密,需要一个新的AES实例进行解密。
# 把明文的转成二进制数据
> msg<- as.raw(c(1:16,1:32));msg
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
[36] 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20
# key转成二进制数据
> key <- as.raw(1:16)#;key
# 偏移量转成二进制数据
> iv <- rand_bytes(16)#;iv
# 建立CBC的AES实例
> aes <- AES(key, mode="CBC",iv)
# 加密
> a<-aes$encrypt(msg)
建立另一个实例,进行解密。
> aes2 <- AES(key, mode="CBC",iv)
# 解密
> b<-aes2$decrypt(a, raw=TRUE);b
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
[36] 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20
2.3 CFB模式
使用CFB模式进行加密时,不能使用同一个AES实例进行加密和解密,需要一个新的AES实例进行解密,同时要求IV的偏移量长度,与块的大小一致。
# 原始数据
> msg<- as.raw(c(1:16,1:32));msg
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
[36] 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20
# 创建IV偏移量,16字节
> iv <- rand_bytes(16)#;iv
# 创建AES实例
> aes <- AES(key, mode="CFB", iv)
# 查看块大小
> aes$block_size()
[1] 16
# 加密
> code <- aes$encrypt(msg)
# 新建实例
> aes2 <- AES(key, mode="CFB", iv)
# 解密
> aes2$decrypt(code,raw=TRUE)
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
[36] 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20
2.4 CTR模式
> msg<- as.raw(c(1:16,1:16));msg
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10
> key <- as.raw(1:16)
> iv <- rand_bytes(16)
> aes <- AES(key, mode="CTR", iv)
> code<-aes$encrypt(msg)
> aes2 <- AES(key, mode="CTR", iv)
> aes2$block_size()
[1] 16
> aes2$decrypt(code,raw=TRUE)
[1] 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10
2.5 报错:Text length must be a multiple of 16 bytes
在加密过程中,aes$encrypt(msg),msg文本可以是一个单元素的字符向量或一个原始向量,被要求字节长度是16字节长度的倍数。如果原始文本的二进制为非16字节长度,则会有 Text length must be a multiple of 16 bytes 错误。
# 任意原始文字
> msg<- charToRaw("ABCDj@*(;dj! 测试一下中文");msg
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4
> key <- as.raw(1:16)
> aes <- AES(key, mode="ECB")
# 非16长度倍数
> a<-aes$encrypt(msg)
Error in aes$encrypt(msg) : Text length must be a multiple of 16 bytes
2.6 PKCS5和PKCS7填充
当出现上面的错误的时候,我们需要用PKCS5和PKCS7进行填充补值。加密算法要求明文需要按一定长度对齐,叫做块大小(BlockSize),比如16字节,那么对于一段任意的数据,加密前需要对最后一个块填充到16 字节,解密后需要删除掉填充的数据。
- PKCS5,PKCS7Padding的子集,块大小固定为8字节。。
- PKCS7,块大小固定为1-256字节的长度进行分组,最后分剩下那一组,不够长度,就需要进行补齐。
由于digest包,没有提供实现,我自己写了3个函数,用于加密时填充补值和解密是移除补值。
| 原始字符 | 转二进制 | 补齐16的倍数长度 |
|---|---|---|
| A | 41 | 41 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f |
| AB | 41 42 | 41 42 0e 0e 0e 0e 0e 0e 0e 0e 0e 0e 0e 0e 0e 0e |
| ABC | 41 42 43 | 41 42 43 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d |
| ABCD | 41 42 43 44 | 41 42 43 44 0c 0c 0c 0c 0c 0c 0c 0c 0c 0c 0c 0c |
| ABCDE | 41 42 43 44 45 | 41 42 43 44 45 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b |
| ABCDEF | 41 42 43 44 45 46 | 41 42 43 44 45 46 0a 0a 0a 0a 0a 0a 0a 0a 0a 0a |
| ABCDEFG | 41 42 43 44 45 46 47 | 41 42 43 44 45 46 47 09 09 09 09 09 09 09 09 09 |
| ABCDEFGH | 41 42 43 44 45 46 47 48 | 41 42 43 44 45 46 47 48 08 08 08 08 08 08 08 08 |
| ABCDEFGHI | 41 42 43 44 45 46 47 48 49 | 41 42 43 44 45 46 47 48 49 07 07 07 07 07 07 07 |
| ABCDEFGHIJ | 41 42 43 44 45 46 47 48 49 4a | 41 42 43 44 45 46 47 48 49 4a 06 06 06 06 06 06 |
| ABCDEFGHIJK | 41 42 43 44 45 46 47 48 49 4a 4b | 41 42 43 44 45 46 47 48 49 4a 4b 05 05 05 05 05 |
| ABCDEFGHIJKL | 41 42 43 44 45 46 47 48 49 4a 4b 4c | 41 42 43 44 45 46 47 48 49 4a 4b 4c 04 04 04 04 |
| ABCDEFGHIJKLM | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 03 03 03 |
| ABCDEFGHIJKLMN | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 02 02 |
| ABCDEFGHIJKLMNO | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 01 |
| ABCDEFGHIJKLMNOP | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 50 | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 50 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 |
| ABCDEFGHIJKLMNOPQ | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 50 51 | 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 50 51 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f 0f |
接下来,自己写个函数进行实现
# PKCS5填充
> pkcs5_padding<-function(text){
+ bit<-8
+ if(!is.raw(text)){
+ text<-charToRaw(text)
+ }
+ b<- bit - (length(text)+bit) %% bit
+ c(text,as.raw(rep(as.hexmode(b),b)))
+ }
# PKCS7填充
> pkcs7_padding<-function(text,bit=16){
+ if(bit>256 | bit<1){
+ stop("bit is not in 1-256")
+ }
+ if(!is.raw(text)){
+ text<-charToRaw(text)
+ }
+ b<- bit - (length(text)+bit) %% bit
+ c(text,as.raw(rep(as.hexmode(b),b)))
+ }
# PKCS7移除
> pkcs_strip<-function(rtext){
+ n<-length(rtext)
+ pos<-as.integer(rtext[n])
+ rtext[1:c(n-pos)]
+ }
输出自定的字符串,使用pkcs7_padding()来自动补齐数据。
# 原始明文转二进制
> plaintext<-charToRaw("ABCDj@*(;dj! 测试一下中文");plaintext
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4
# pkcs7_padding填充
> ptext<-pkcs7_padding(plaintext)
# 创建AES对象
> aes <- AES(key, mode="ECB")
# 加密
> a <- aes$encrypt(ptext);a
[1] 63 e6 d4 e5 74 c1 13 b3 d5 be 1f 0f a6 db 75 50 d7 d8 3d fb 53 b0 4e 61 67 d1 91 a6 db fe b8 e0
# 解密
> b<-aes$decrypt(aes128, raw=TRUE);b
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4 06 06 06 06 06 06
# 移除增加的补齐数据
> pkcs7_strip(b)
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4
# 把二进制转明文
> rawToChar(pkcs7_strip(b))
[1] "ABCDj@*(;dj! 测试一下中文"
3. 用openssl包进行AES加密解密
我们可以使用openssl包的AES函数,进行AES的加密和解密操作,openssl包的详细介绍,请参考文章用openssl生成RSA私钥和公钥。
在openssl包中,支持CBC,CTR,GCM三种模式,分别对应aes_cbc_encrypt(), aes_ctr_encrypt(), aes_gcm_encrypt()的三种函数。
在CBC模式下使用AES块状密码进行低级别的对称加密/解密。密钥是一个原始向量,例如一些秘密的散列。当没有共享秘密时,可以使用随机密钥,通过非对称协议(如RSA)进行交换。
从API的使用上,openssl包提供的API函数,要比digest包提供的API函数,看起来更容易一点。
3.1 CBC模式
> library(openssl)
# 设置key 和 iv
> key <- aes_keygen();key
aes e2:40:0a:12:33:9e:83:e9:04:d5:5c:aa:6f:40:d2:cc
> iv <- rand_bytes(16);iv
[1] 9a a7 24 f9 1d eb da 25 30 f9 ba b3 1b 69 12 e4
# 原始字符转字节码
> msg<-charToRaw("ABCDj@*(;dj! 测试一下中文");msg
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4
# 加密
> blob <- aes_cbc_encrypt(msg, key, iv = iv)
# 解密
> message <- aes_cbc_decrypt(blob, key, iv)
# 字节码转字符串
> out <- rawToChar(message);out
[1] "ABCDj@*(;dj! 测试一下中文"
3.2 CTR模式
> key <- aes_keygen();key
aes 11:65:5a:17:2d:28:f4:92:38:44:90:b1:45:cb:d2:5f
> iv <- rand_bytes(16);iv
[1] 94 e0 f6 b1 6a 64 e6 0a a0 cf c1 13 ea be 65 dd
> msg<-charToRaw("ABCDj@*(;dj! 测试一下中文");msg
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4
> blob <- aes_ctr_encrypt(msg, key, iv = iv)
> message <- aes_ctr_decrypt(blob, key, iv)
> out <- rawToChar(message);out
[1] "ABCDj@*(;dj! 测试一下中文"
3.3 GCM模式
> key <- aes_keygen();key
aes 38:31:8a:ea:66:96:c7:7d:6d:72:d5:bd:75:62:92:db
> iv <- rand_bytes(12);iv
[1] 99 ca b1 36 bf b9 af 78 c5 22 a4 06
> msg<-charToRaw("ABCDj@*(;dj! 测试一下中文");msg
[1] 41 42 43 44 6a 40 2a a3 a8 3b 64 6a 21 20 b2 e2 ca d4 d2 bb cf c2 d6 d0 ce c4
> blob <- aes_gcm_encrypt(msg, key, iv = iv)
> message <- aes_gcm_decrypt(blob, key, iv)
> out <- rawToChar(message);out
[1] "ABCDj@*(;dj! 测试一下中文"
本文介绍对称加密算法AES在digest包和openssl包的使用,虽然加密和解密不是R语言的主业,但是真的实现起来,没想到还是挺方便的。哈哈哈,又学到一招。
本文代码已上传到github: https://github.com/bsspirit/encrypt/blob/master/aes.r
转载请注明出处:
http://blog.fens.me/r-crypto-aes/