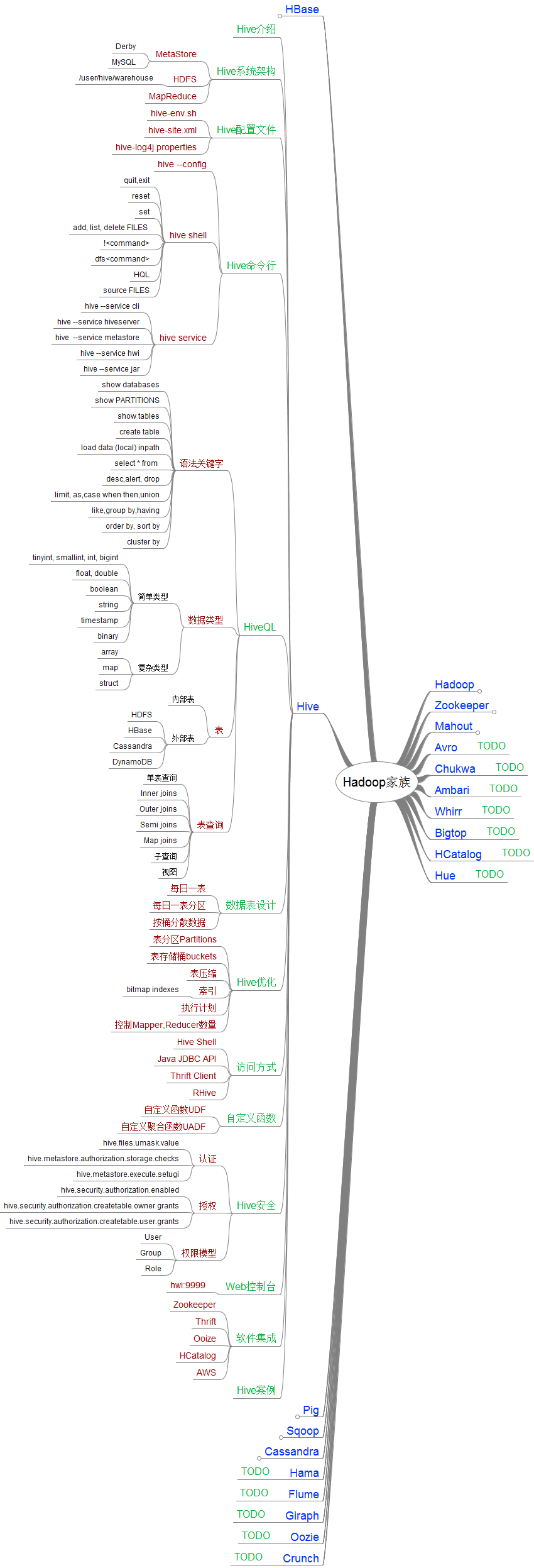
让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务。
现在硬件越来越便宜,一台非品牌服务器,2颗24核CPU,配48G内存,2T的硬盘,已经降到2万块人民币以下了。这种配置如果简单地放几个web应用,显然是奢侈的浪费。就算是用来实现单节点的hadoop,对计算资源浪费也是非常高的。对于这么高性能的计算机,如何有效利用计算资源,就成为成本控制的一项重要议题了。
通过虚拟化技术,我们可以将一台服务器,拆分成12台VPS,每台2核CPU,4G内存,40G硬盘,并且支持资源重新分配。多么伟大的技术啊!现在我们有了12个节点的hadoop集群, 让Hadoop跑在云端,让世界加速。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-hive-10g/

前言
Hadoop和Hive的环境已经搭建起来了,开始导入数据进行测试。我的数据1G大概对应500W行,MySQL的查询500W行大概3.29秒,用hive同样的查询大概30秒。如果我们把数据增加到10G,100G,让我们来看看Hive的表现吧。
目录
- 导出MySQL数据
- 导入到Hive
- 优化导入过程Hive Bucket
- 执行查询
1. 导出MySQL数据
下面是我的表,每天会产生一新表,用日期的方式命名。今天是2013年7月19日,对应的表是cb_hft,记录数646W条记录。
mysql> show tables;
+-----------------+
| Tables_in_CB |
+-----------------+
| NSpremium |
| cb_hft |
| cb_hft_20130710 |
| cb_hft_20130712 |
| cb_hft_20130715 |
| cb_hft_20130716 |
+-----------------+
6 rows in set (0.00 sec)
mysql> select count(1) from cb_hft;
+----------+
| count(1) |
+----------+
| 6461338 |
+----------+
1 row in set (3.29 sec)
快速复制表:
由于这个表是离线系统的,没有线上应用,我重命名表cb_hft为cb_hft_20130719,再复制表结构。
mysql> RENAME TABLE cb_hft TO cb_hft_20130719;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE cb_hft like cb_hft_20130719;
Query OK, 0 rows affected (0.02 sec)
mysql> show tables;
+-----------------+
| Tables_in_CB |
+-----------------+
| NSpremium |
| cb_hft |
| cb_hft_20130710 |
| cb_hft_20130712 |
| cb_hft_20130715 |
| cb_hft_20130716 |
| cb_hft_20130719 |
+-----------------+
7 rows in set (0.00 sec)
导出表到csv
以hft_20130712表为例
mysql> SELECT
SecurityID,TradeTime,PreClosePx,OpenPx,HighPx,LowPx,LastPx,
BidSize1,BidPx1,BidSize2,BidPx2,BidSize3,BidPx3,BidSize4,BidPx4,BidSize5,BidPx5,
OfferSize1,OfferPx1,OfferSize2,OfferPx2,OfferSize3,OfferPx3,OfferSize4,OfferPx4,OfferSize5,OfferPx5,
NumTrades,TotalVolumeTrade,TotalValueTrade,PE,PE1,PriceChange1,PriceChange2,Positions
FROM cb_hft_20130712
INTO OUTFILE '/tmp/export_cb_hft_20130712.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
Query OK, 6127080 rows affected (2 min 55.04 sec)
查看数据文件
~ ls -l /tmp
-rw-rw-rw- 1 mysql mysql 1068707117 Jul 19 15:59 export_cb_hft_20130712.csv
2. 导入到Hive
登陆c1.wtmart.com机器,下载数据文件
~ ssh cos@c1.wtmart.com
~ cd /home/cos/hadoop/sqldb
~ scp -P 10003 cos@d2.wtmart.com:/tmp/export_cb_hft_20130712.csv .
export_cb_hft_20130712.csv 100% 1019MB 39.2MB/s 00:26
在hive上建表
~ bin/hive shell
#删除已存在的表
hive> DROP TABLE IF EXISTS t_hft_tmp;
Time taken: 4.898 seconds
#创建t_hft_tmp表
hive> CREATE TABLE t_hft_tmp(
SecurityID STRING,TradeTime STRING,
PreClosePx DOUBLE,OpenPx DOUBLE,HighPx DOUBLE,LowPx DOUBLE,LastPx DOUBLE,
BidSize1 DOUBLE,BidPx1 DOUBLE,BidSize2 DOUBLE,BidPx2 DOUBLE,BidSize3 DOUBLE,BidPx3 DOUBLE,BidSize4 DOUBLE,BidPx4 DOUBLE,BidSize5 DOUBLE,BidPx5 DOUBLE,
OfferSize1 DOUBLE,OfferPx1 DOUBLE,OfferSize2 DOUBLE,OfferPx2 DOUBLE,OfferSize3 DOUBLE,OfferPx3 DOUBLE,OfferSize4 DOUBLE,OfferPx4 DOUBLE,OfferSize5 DOUBLE,OfferPx5 DOUBLE,
NumTrades INT,TotalVolumeTrade DOUBLE,TotalValueTrade DOUBLE,PE DOUBLE,PE1 DOUBLE,PriceChange1 DOUBLE,PriceChange2 DOUBLE,Positions DOUBLE
) PARTITIONED BY (tradeDate INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
Time taken: 0.189 seconds
#导入数据
hive> LOAD DATA LOCAL INPATH '/home/cos/hadoop/sqldb/export_cb_hft_20130712.csv' OVERWRITE INTO TABLE t_hft_tmp PARTITION (tradedate=20130712);
Copying data from file:/home/cos/hadoop/sqldb/export_cb_hft_20130712.csv
Copying file: file:/home/cos/hadoop/sqldb/export_cb_hft_20130712.csv
Loading data to table default.t_hft_tmp partition (tradedate=20130712)
Time taken: 16.535 seconds
当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置,这个表只有一个文件,文件没有切分成多份。
hive> dfs -ls /user/hive/warehouse/t_hft_tmp/tradedate=20130712;
Found 1 items
-rw-r--r-- 1 cos supergroup 1068707117 2013-07-19 16:07 /user/hive/warehouse/t_hft_tmp/tradedate=20130712/export_cb_hft_20130712.csv
3. 优化导入过程Hive Bucket
第二步导入,我们要把刚才的一个大文件切分成多少小文件,大概按照64M一个block的要求。我们设置做16个Bucket。
新建数据表t_hft_day,并定义CLUSTERED BY,SORTED BY,16 BUCKETS
hive> CREATE TABLE t_hft_day(
SecurityID STRING,TradeTime STRING,
PreClosePx DOUBLE,OpenPx DOUBLE,HighPx DOUBLE,LowPx DOUBLE,LastPx DOUBLE,
BidSize1 DOUBLE,BidPx1 DOUBLE,BidSize2 DOUBLE,BidPx2 DOUBLE,BidSize3 DOUBLE,BidPx3 DOUBLE,BidSize4 DOUBLE,BidPx4 DOUBLE,BidSize5 DOUBLE,BidPx5 DOUBLE,
OfferSize1 DOUBLE,OfferPx1 DOUBLE,OfferSize2 DOUBLE,OfferPx2 DOUBLE,OfferSize3 DOUBLE,OfferPx3 DOUBLE,OfferSize4 DOUBLE,OfferPx4 DOUBLE,OfferSize5 DOUBLE,OfferPx5 DOUBLE,
NumTrades INT,TotalVolumeTrade DOUBLE,TotalValueTrade DOUBLE,PE DOUBLE,PE1 DOUBLE,PriceChange1 DOUBLE,PriceChange2 DOUBLE,Positions DOUBLE
) PARTITIONED BY (tradeDate INT)
CLUSTERED BY(SecurityID) SORTED BY(TradeTime) INTO 16 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
从t_hft_tmp临时数据表导入到t_hft_day数据表
#强制执行装桶的操作
hive> set hive.enforce.bucketing = true;
#数据导入
hive> FROM t_hft_tmp
INSERT OVERWRITE TABLE t_hft_day
PARTITION (tradedate=20130712)
SELECT SecurityID , TradeTime ,
PreClosePx ,OpenPx ,HighPx ,LowPx ,LastPx ,
BidSize1 ,BidPx1 ,BidSize2 ,BidPx2 ,BidSize3 ,BidPx3 ,BidSize4 ,BidPx4 ,BidSize5 ,BidPx5 ,
OfferSize1 ,OfferPx1 ,OfferSize2 ,OfferPx2 ,OfferSize3 ,OfferPx3 ,OfferSize4 ,OfferPx4 ,OfferSize5 ,OfferPx5 ,
NumTrades,TotalVolumeTrade ,TotalValueTrade ,PE ,PE1 ,PriceChange1 ,PriceChange2 ,Positions
WHERE tradedate=20130712;
MapReduce Total cumulative CPU time: 8 minutes 5 seconds 810 msec
Ended Job = job_201307191356_0016
Loading data to table default.t_hft_day partition (tradedate=20130712)
Partition default.t_hft_day{tradedate=20130712} stats: [num_files: 16, num_rows: 0, total_size: 1291728298, raw_data_size: 0]
Table default.t_hft_day stats: [num_partitions: 11, num_files: 176, num_rows: 0, total_size: 10425980914, raw_data_size: 0]
6127080 Rows loaded to t_hft_day
MapReduce Jobs Launched:
Job 0: Map: 4 Reduce: 16 Cumulative CPU: 485.81 sec HDFS Read: 1068771008 HDFS Write: 1291728298 SUCCESS
Total MapReduce CPU Time Spent: 8 minutes 5 seconds 810 msec
OK
Time taken: 172.617 seconds
导入操作累计CPU时间是8分05秒,8*60+5=485秒。由于有4个Map并行,16个Reduce并行,所以实际消耗时间是172秒。
我们再看一下新表的文件是否被分片:
hive> dfs -ls /user/hive/warehouse/t_hft_day/tradedate=20130712;
Found 16 items
-rw-r--r-- 1 cos supergroup 95292536 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000000_0
-rw-r--r-- 1 cos supergroup 97136495 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000001_0
-rw-r--r-- 1 cos supergroup 90695623 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000002_0
-rw-r--r-- 1 cos supergroup 84132171 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000003_0
-rw-r--r-- 1 cos supergroup 81552397 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000004_0
-rw-r--r-- 1 cos supergroup 80580028 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000005_0
-rw-r--r-- 1 cos supergroup 73195335 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000006_0
-rw-r--r-- 1 cos supergroup 68648786 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000007_0
-rw-r--r-- 1 cos supergroup 72210159 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000008_0
-rw-r--r-- 1 cos supergroup 66851502 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000009_0
-rw-r--r-- 1 cos supergroup 69292538 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000010_0
-rw-r--r-- 1 cos supergroup 75282272 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000011_0
-rw-r--r-- 1 cos supergroup 79572724 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000012_0
-rw-r--r-- 1 cos supergroup 78151866 2013-07-19 16:19 /user/hive/warehouse/t_hft_day/tradedate=20130712/000013_0
-rw-r--r-- 1 cos supergroup 86850954 2013-07-19 16:18 /user/hive/warehouse/t_hft_day/tradedate=20130712/000014_0
-rw-r--r-- 1 cos supergroup 92282912 2013-07-19 16:19 /user/hive/warehouse/t_hft_day/tradedate=20130712/000015_0
一共16个分片。
4. 执行查询
当前1G的文件,使用Hive执行一个简单的查询:34.974秒
hive> select count(1) from t_hft_day where tradedate=20130712;
MapReduce Total cumulative CPU time: 34 seconds 670 msec
Ended Job = job_201307191356_0017
MapReduce Jobs Launched:
Job 0: Map: 7 Reduce: 1 Cumulative CPU: 34.67 sec HDFS Read: 1291793812 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 34 seconds 670 msec
6127080
Time taken: 34.974 seconds
MySQL执行同样的查询,在开始时我已经测试过3.29秒。
相差了10倍的时间,不过只有1G的数据量,是发挥不出hadoop的优势的。
接下来,按照上面的方法,我们把十几天的数据都导入到hive里面,然后再进行比较。
查看已导入hive的数据集
hive> SHOW PARTITIONS t_hft_day;
tradedate=20130627
tradedate=20130628
tradedate=20130701
tradedate=20130702
tradedate=20130703
tradedate=20130704
tradedate=20130705
tradedate=20130708
tradedate=20130709
tradedate=20130710
tradedate=20130712
tradedate=20130715
tradedate=20130716
tradedate=20130719
Time taken: 0.099 seconds
在MySQL中,对5张表进行查询。(5G数据量)
#单表:由于PreClosePx不是索引列,第一次查询
mysql> select SecurityID,20130719 as tradedate,count(1) as count from cb_hft_20130716 where PreClosePx>8.17 group by SecurityID limit 10;
+------------+-----------+-------+
| SecurityID | tradedate | count |
+------------+-----------+-------+
| 000001 | 20130719 | 5200 |
| 000002 | 20130719 | 5193 |
| 000003 | 20130719 | 1978 |
| 000004 | 20130719 | 3201 |
| 000005 | 20130719 | 1975 |
| 000006 | 20130719 | 1910 |
| 000007 | 20130719 | 3519 |
| 000008 | 20130719 | 4229 |
| 000009 | 20130719 | 5147 |
| 000010 | 20130719 | 2176 |
+------------+-----------+-------+
10 rows in set (24.60 sec)
#多表查询
select t.SecurityID,t.tradedate,t.count
from (
select SecurityID,20130710 as tradedate,count(1) as count from cb_hft_20130710 where PreClosePx>8.17 group by SecurityID
union
select SecurityID,20130712 as tradedate,count(1) as count from cb_hft_20130712 group by SecurityID
union
select SecurityID,20130715 as tradedate,count(1) as count from cb_hft_20130715 where PreClosePx>8.17 group by SecurityID
union
select SecurityID,20130716 as tradedate,count(1) as count from cb_hft_20130716 where PreClosePx>8.17 group by SecurityID
union
select SecurityID,20130719 as tradedate,count(1) as count from cb_hft_20130719 where PreClosePx>8.17 group by SecurityID ) as t
limit 10
#超过3分钟,无返回结果。
....
在Hive中,对同样的5张表进行查询。(5G数据量)
select SecurityID,tradedate,count(1) from t_hft_day where tradedate in (20130710,20130712,20130715,20130716,20130719) and PreClosePx>8.17 group by SecurityID,tradedate limit 10;
MapReduce Total cumulative CPU time: 3 minutes 56 seconds 540 msec
Ended Job = job_201307191356_0023
MapReduce Jobs Launched:
Job 0: Map: 25 Reduce: 7 Cumulative CPU: 236.54 sec HDFS Read: 6577084486 HDFS Write: 1470 SUCCESS
Total MapReduce CPU Time Spent: 3 minutes 56 seconds 540 msec
OK
000001 20130710 5813
000004 20130715 3546
000005 20130712 1820
000005 20130719 2364
000006 20130716 1910
000008 20130710 2426
000011 20130715 2113
000012 20130712 3554
000012 20130719 3756
000013 20130716 1646
Time taken: 66.32 seconds
#对以上14张表的查询
MapReduce Total cumulative CPU time: 8 minutes 40 seconds 380 msec
Ended Job = job_201307191356_0022
MapReduce Jobs Launched:
Job 0: Map: 53 Reduce: 15 Cumulative CPU: 520.38 sec HDFS Read: 14413501282 HDFS Write: 3146 SUCCESS
Total MapReduce CPU Time Spent: 8 minutes 40 seconds 380 msec
OK
000001 20130716 5200
000002 20130715 5535
000003 20130705 1634
000004 20130704 2173
000005 20130703 996
000005 20130712 1820
000006 20130702 1176
000007 20130701 2973
000007 20130710 4084
000010 20130716 2176
Time taken: 119.161 seconds
我们看到hadoop对以G为单位量级的数据增长是不敏感的,多了3倍的数据(15G),执行查询的时间是原来(5G)的两倍。而MySQL数据增长到5G,查询时间几乎是不可忍受的。
1G以下的数据是单机可以处理的,MySQL会非常好的完成查询任务。Hadoop只有在数据量大的情况下才能发挥出优势,当数据量到达10G时,MySQL的单表查询就显得就会性能不足。如果数据量到达了100G,MySQL就已经解决不了了,要通过各种优化的程序才能完成查询。
测试过程已经描述的很清楚了,我们接下来的工作就是把过程自动化。
转载请注明出处:
http://blog.fens.me/hadoop-hive-10g/