跨界知识聚会系列文章,“知识是用来分享和传承的”,各种会议、论坛、沙龙都是分享知识的绝佳场所。我也有幸作为演讲嘉宾参加了一些国内的大型会议,向大家展示我所做的一些成果。从听众到演讲感觉是不一样的,把知识分享出来,你才能收获更多。
关于作者
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-china-rhadoop-2013/

前言
今天有幸在2013年ChinaHadoop大会发言,为R语言推广做出一点点贡献,自己感觉非常的激动。自学习R语言以来,跨学科的思维模式,每天都在扩充自己的视野!“唯有跳出IT的圈子,才能体会IT正在改变着世界”。
以计算机技术和统计为工具,再结合行业知识,必将成为未来“数据掘金”的原动力!抓住时代的机会,是80后崛起的时候了!
目录
- 主题内容介绍
- 活动照片
1. 主题内容介绍
ChinaHadoop的大会主页:http://www.chinahadoop.com/
R语言为Hadoop注入统计血脉:PPT下载
- 1). 主题:R语言为Hadoop注入统计血脉
- 2). RHadoop基础程序
- 3). 分步式协同过滤ItemCF算法介绍
- 4). ItemCF算法:R本地程序实现
- 5). ItemCF算法:RHadoop实现
- 6). ItemCF算法:Java Hadoop MapReduce实现
- 7). ItemCF算法:Mahout 实现
- 8). 推荐结果,数据可视化
1). 主题:R语言为Hadoop注入统计血脉
主要内容:R语言为Hadoop注入统计血脉
2). RHadoop基础程序
主要内容:RHadoop实践系列之二:RHadoop安装与使用
源代码
#hdfs
library(rhdfs)
hdfs.init()
hdfs.ls("/user/")
hdfs.cat("/user/hdfs/o_t_account/part-m-00000")
#rmr
library(rmr2)
small.ints <- 1:10
sapply(small.ints, function(x) x^2)
small.ints <- to.dfs(keyval(1,1:10))
from.dfs(small.ints)
output<-mapreduce(input = small.ints, map = function(k, v) cbind(v, v^2))
from.dfs(output)
#rmr-wordcount
input<-"/user/hdfs/o_t_account/"
wordcount = function(input, output = NULL, pattern = ","){
wc.map = function(., lines) {
keyval(unlist( strsplit( x = lines,split = pattern)),1)
}
wc.reduce =function(word, counts ) {
keyval(word, sum(counts))
}
mapreduce(input = input ,output = output, input.format = "text",
map = wc.map, reduce = wc.reduce,combine = TRUE)
}
output<-wordcount(input)
from.dfs(output)
3). 分步式协同过滤ItemCF算法介绍
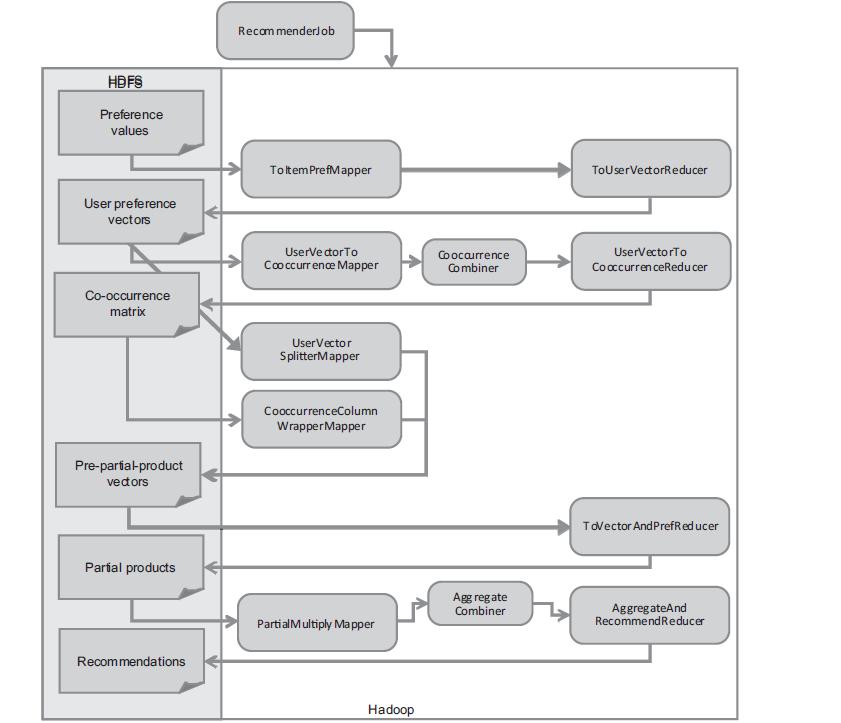
主要内容:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
4). ItemCF算法:R本地程序实现
主要内容:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
源代码:
library(plyr)
#读取数据集
train<-read.csv(file="small.csv",header=FALSE)
names(train)<-c("user","item","pref")
#计算用户列表
usersUnique<-function(){
users<-unique(train$user)
users[order(users)]
}
#计算商品列表方法
itemsUnique<-function(){
items<-unique(train$item)
items[order(items)]
}
# 用户列表
users<-usersUnique()
users
# 商品列表
items<-itemsUnique()
items
#建立商品列表索引
index<-function(x) which(items %in% x)
data<-ddply(train,.(user,item,pref),summarize,idx=index(item))
data
#同现矩阵
cooccurrence<-function(data){
n<-length(items)
co<-matrix(rep(0,n*n),nrow=n)
for(u in users){
idx<-index(data$item[which(data$user==u)])
m<-merge(idx,idx)
for(i in 1:nrow(m)){
co[m$x[i],m$y[i]]=co[m$x[i],m$y[i]]+1
}
}
return(co)
}
#推荐算法
recommend<-function(udata=udata,co=coMatrix,num=0){
n<-length(items)
# all of pref
pref<-rep(0,n)
pref[udata$idx]<-udata$pref
# 用户评分矩阵
userx<-matrix(pref,nrow=n)
# 同现矩阵*评分矩阵
r<-co %*% userx
# 推荐结果排序
r[udata$idx]<-0
idx<-order(r,decreasing=TRUE)
topn<-data.frame(user=rep(udata$user[1],length(idx)),item=items[idx],val=r[idx])
topn<-topn[which(topn$val>0),]
# 推荐结果取前num个
if(num>0){
topn<-head(topn,num)
}
#返回结果
return(topn)
}
co<-cooccurrence(data)
co
#计算推荐结果
recommendation<-data.frame()
for(i in 1:length(users)){
udata<-data[which(data$user==users[i]),]
recommendation<-rbind(recommendation,recommend(udata,co,0))
}
recommendation
5). ItemCF算法:RHadoop实现
主要内容:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
源代码:
#加载rmr2包
library(rmr2)
#输入数据文件
train<-read.csv(file="small.csv",header=FALSE)
names(train)<-c("user","item","pref")
#把数据集存入HDFS
train.hdfs = to.dfs(keyval(train$user,train))
from.dfs(train.hdfs)
#STEP 1, 建立物品的同现矩阵
# 1) 按用户分组,得到所有物品出现的组合列表。
train.mr<-mapreduce(
train.hdfs,
map = function(k, v) {
keyval(k,v$item)
}
,reduce=function(k,v){
m<-merge(v,v)
keyval(m$x,m$y)
}
)
from.dfs(train.mr)
# 2) 对物品组合列表进行计数,建立物品的同现矩阵
step2.mr<-mapreduce(
train.mr,
map = function(k, v) {
d<-data.frame(k,v)
d2<-ddply(d,.(k,v),count)
key<-d2$k
val<-d2
keyval(key,val)
}
)
from.dfs(step2.mr)
# 2. 建立用户对物品的评分矩阵
train2.mr<-mapreduce(
train.hdfs,
map = function(k, v) {
df<-v
key<-df$item
val<-data.frame(item=df$item,user=df$user,pref=df$pref)
keyval(key,val)
}
)
from.dfs(train2.mr)
#3. 合并同现矩阵 和 评分矩阵
eq.hdfs<-equijoin(
left.input=step2.mr,
right.input=train2.mr,
map.left=function(k,v){
keyval(k,v)
},
map.right=function(k,v){
keyval(k,v)
},
outer = c("left")
)
from.dfs(eq.hdfs)
#4. 计算推荐结果列表
cal.mr<-mapreduce(
input=eq.hdfs,
map=function(k,v){
val<-v
na<-is.na(v$user.r)
if(length(which(na))>0) val<-v[-which(is.na(v$user.r)),]
keyval(val$k.l,val)
}
,reduce=function(k,v){
val<-ddply(v,.(k.l,v.l,user.r),summarize,v=freq.l*pref.r)
keyval(val$k.l,val)
}
)
from.dfs(cal.mr)
#5. 按输入格式得到推荐评分列表
result.mr<-mapreduce(
input=cal.mr,
map=function(k,v){
keyval(v$user.r,v)
}
,reduce=function(k,v){
val<-ddply(v,.(user.r,v.l),summarize,v=sum(v))
val2<-val[order(val$v,decreasing=TRUE),]
names(val2)<-c("user","item","pref")
keyval(val2$user,val2)
}
)
from.dfs(result.mr)
6). ItemCF算法:Java Hadoop MapReduce实现
主要内容:用Hadoop构建电影推荐系统
源代码:https://github.com/bsspirit/maven_hadoop_template/releases/tag/recommend
7). ItemCF算法:Mahout 实现
主要内容:Mahout分步式程序开发 基于物品的协同过滤ItemCF
源代码: https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8
8). 推荐结果,数据可视化
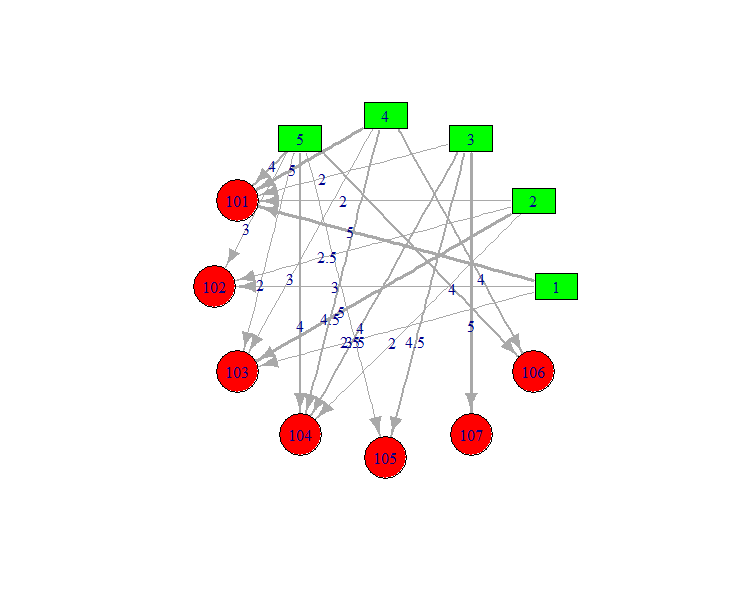
数据集:small.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
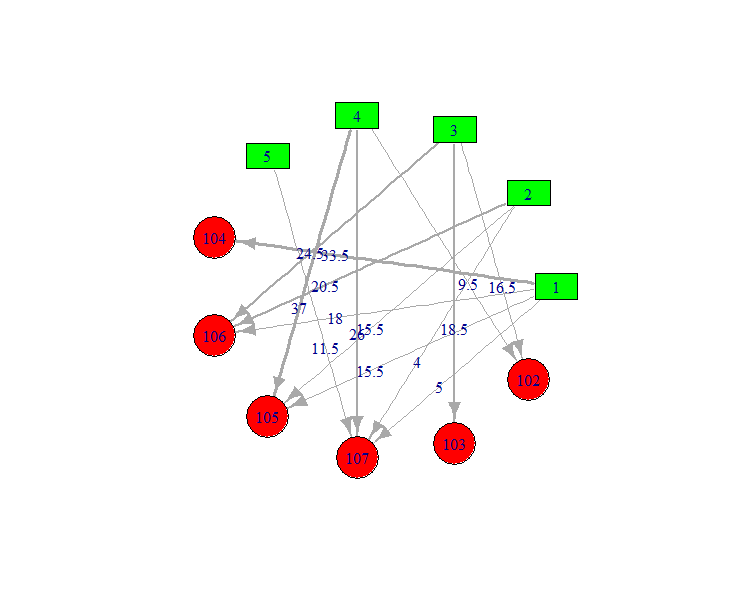
结果集: result.csv
1,104,33.5
1,106,18
1,105,15.5
1,107,5
2,106,20.5
2,105,15.5
2,107,4
3,103,24.5
3,102,18.5
3,106,16.5
4,102,37
4,105,26
4,107,9.5
5,107,11.5
R语言Socail Graph可视化
library(igraph)
train<-read.csv(file="small.csv",header=FALSE)
drawGraph<-function(data){
names(data)<-c("from","to","f")
g <- graph.data.frame(data, directed=TRUE)
V(g)$label <- V(g)$name
V(g)$size <- 25
V(g)$color <- c(rep("green",5),rep("red",7))
V(g)$shape <- c(rep("rectangle",5),rep("circle",7))
E(g)$color <- grey(0.5)
E(g)$weight<-data$f
E(g)$width<-scale(E(g)$weight,scale=TRUE)+2
g2 <- simplify(g)
plot(g2,edge.label=E(g)$weight,edge.width=E(g)$width,layout=layout.circle)
}
#small
drawGraph(train)
#recommandation
recommendation<-read.csv(file="result.csv",header=FALSE)
drawGraph(recommendation)
2. 活动照片



转载请注明出处:
http://blog.fens.me/hadoop-china-rhadoop-2013/
