让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务。
现在硬件越来越便宜,一台非品牌服务器,2颗24核CPU,配48G内存,2T的硬盘,已经降到2万块人民币以下了。这种配置如果简单地放几个web应用,显然是奢侈的浪费。就算是用来实现单节点的hadoop,对计算资源浪费也是非常高的。对于这么高性能的计算机,如何有效利用计算资源,就成为成本控制的一项重要议题了。
通过虚拟化技术,我们可以将一台服务器,拆分成12台VPS,每台2核CPU,4G内存,40G硬盘,并且支持资源重新分配。多么伟大的技术啊!现在我们有了12个节点的hadoop集群, 让Hadoop跑在云端,让世界加速。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-clone-improve
前言
把虚拟化的hadoop环境创建好之后,我们就要考虑如何对系统进行优化了。从运维的角度,我找到了4个优化的出发点,安装,配置,监控,管理。
为了完成1个人管理1000节点的目标,点滴的优化,都是未来成功的基石。
我在努力着。。。
目录
- 对系统优化简单分析
- 优化问题1:c1作为母体每次克隆时要停机。
- 优化问题2:手动操作步骤太多。
1. 对系统优化简单分析(10个节点)
刚才我们从运维的角度,提出了4点优化的出发点:安装,配置,监控,管理。
现在系统成功运行了2个节点,一步一步地,如何能方便的做出10个节点呢?
注:如果上来就想着1000个节点,我们失去方向。请已经熟悉1000个节点方案的朋友忽略这篇文章!
安装
简单概括就是安装要简单,最好是一条命令或者一个脚本就可以完成!在我们的虚拟环境中,安装一个hadoop节点,其实就创建一台新的虚拟机,就一条命令!
可是现在的结构,c1作为母体每次克隆时要停机,就意味着hadoop环境要停机,这不是我们希望的。我们将讨论如何进行改进!
配置
克隆体的hadoop节点创建成功后,由于hostname, ip, dns, 挂载磁盘等,都从母体复制过来的。但这几项配置要求每个节点是不一样的,需要手动修改。
所以,我们应该做一个脚本,每次自动去修改这些配置项,减少手动的修改,减少复杂性。保证新增加的节点能顺利的加入原有的hadoop集群。
监控
我们现在用KVM虚拟机,可以直接通过host虚拟机管理控制台查看每个节点的情况,当然这些信息是不够。我们还需要安装其他的系统监控工具,及各种的hadoop监控工具。
关于监控,我们将在后继续介绍。
管理
如果我们想整套的hadoop环境更易用,可以通过openstack做管理,这会是一种更理想的方案。
当然,这篇文章不会涉及到这个问题,我们将在后继续介绍。
2. 优化问题1:c1作为母体每次克隆时要停机。
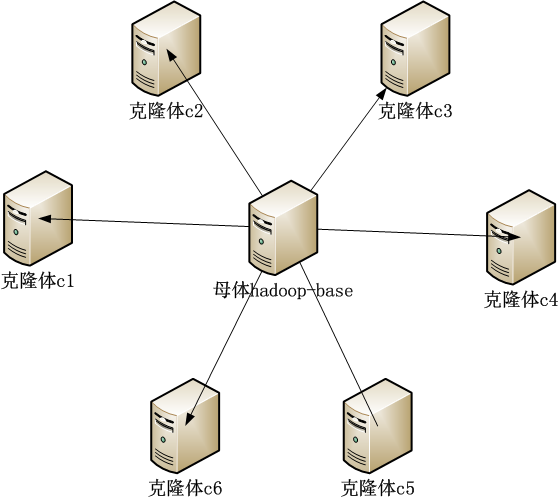
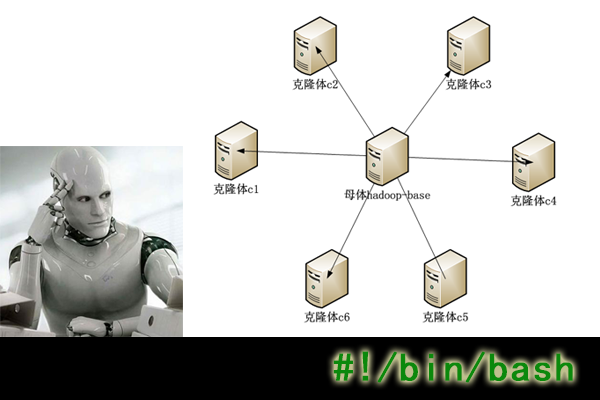
c1作为hadoop集群的,namenode节点不应该停止,因些我们重新制作一个名为hadoop-base的母体。通过新母体制造克隆体。
先停止hadoop,通过 让Hadoop跑在云端系列文章 之 克隆虚拟机增加Hadoop节点 文章的方法,克隆一个新的母体hadoop-base。
~ sudo virt-clone --connect qemu:///system -o c1 -n hadoop-base -f /disk/sdb1/hadoop-base.img
查看虚拟机列表
virsh # list --all
Id Name State
----------------------------------------------------
5 server3 running
6 server4 running
7 d2 running
8 r1 running
9 server2 running
18 server5 running
48 c3 running
50 c1 running
- c2 shut off
- d1 shut off
- hadoop-base shut off
- u1210-base shut off
重新启动hadoop集群c1,c3两个节点。
在c1中查看hadoop节点
~ hadoop dfsadmin -report
Warning: $HADOOP_HOME is deprecated.
Safe mode is ON
Configured Capacity: 317066272768 (295.29 GB)
Present Capacity: 293635162112 (273.47 GB)
DFS Remaining: 293635084288 (273.47 GB)
DFS Used: 77824 (76 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Name: 192.168.1.30:50010
Decommission Status : Normal
Configured Capacity: 158533136384 (147.65 GB)
DFS Used: 49152 (48 KB)
Non DFS Used: 15181529088 (14.14 GB)
DFS Remaining: 143351558144(133.51 GB)
DFS Used%: 0%
DFS Remaining%: 90.42%
Last contact: Thu Jul 11 13:00:50 CST 2013
Name: 192.168.1.32:50010
Decommission Status : Normal
Configured Capacity: 158533136384 (147.65 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8249581568 (7.68 GB)
DFS Remaining: 150283526144(139.96 GB)
DFS Used%: 0%
DFS Remaining%: 94.8%
Last contact: Thu Jul 11 13:00:52 CST 2013
通过新的母体hadoop-base制造克隆体c4
~ sudo virt-clone --connect qemu:///system -o hadoop-base -n c4 -f /disk/sdb1/c4.img
#增加分区硬盘/dev/sdb7
~ sudo virsh
virsh # edit c4
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none'/>
<source dev='/dev/sdb8'/>
<target dev='vdb' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
</disk>
#启动c4
virsh # start c4
#进入c4
virsh # console c4
现在,母体已经从c1变成的hadoop-base。c1已经不需要再关机了。
3. 优化问题2:手动操作步骤太多。
我们手动操作分成2个脚本来处理
- 新克隆体虚拟机的配置
- 向集群增加克隆体配置
新克隆体虚拟机的配置
登陆c4后,通过脚本来代替手动的配置。
脚本对下面6个步骤进行配置修改操作:
- hostname host
- ip
- dns
- fdisk mount
- hadoop folder
- ssh
对以上6个步骤的解释,请参考:Hadoop跑在云端系列文章 之 克隆虚拟机增加Hadoop节点
#!/bin/bash
export HOST=c4
export DOMAIN=$HOST.wtmat.com
export IP=192.168.1.33
export DNS=192.168.1.7
#1. hostname host
echo "====================hostname host============================"
hostname $HOST
echo $HOST > /etc/hostname
sed -i -e "/127.0.0.1/d" /etc/hosts
sed -i -e 1"i\127.0.0.1 localhost ${HOST}" /etc/hosts
#2. ip
echo "====================ip address============================"
sed -i -e "/address/d;/^iface eth0 inet static/a\address ${IP}" /etc/network/interfaces
/etc/init.d/networking restart
#3. dns
echo "====================dns============================"
echo "nameserver ${DNS}" > /etc/resolv.conf
#4. fdisk mount
echo "====================fdisk mount============================"
(echo n; echo p; echo ; echo ; echo ; echo w) | fdisk /dev/vdb
mkfs -t ext4 /dev/vdb1
mount /dev/vdb1 /home/cos/hadoop
echo "/dev/vdb1 /home/cos/hadoop ext4 defaults 0 0 " >> /etc/fstab
#5. hadoop folder
echo "==================== hadoop folder============================"
mkdir /home/cos/hadoop/data
mkdir /home/cos/hadoop/tmp
chown -R cos:cos /home/cos/hadoop/
chmod 755 /home/cos/hadoop/data
chmod 755 /home/cos/hadoop/tmp
#6. ssh
echo "====================ssh============================"
rm -rf /home/cos/.ssh/*
sudo -u cos ssh-keygen -t rsa -N "" -f /home/cos/.ssh/id_rsa
sudo -u cos cat /home/cos/.ssh/id_rsa.pub >> /home/cos/.ssh/authorized_keys
exit
向集群增加克隆体配置
返回c1节点,用脚本完成加载c4的操作。
脚本对下面3步骤进行操作:
- 同步ssh公钥
- 同步hadoop的slaves文件
- 把c4加入到集群环境
下面脚本使用sshpaas软件,请提前安装
sudo apt-get install sshpass
脚本代码
#!/bin/bash
export NEW_NODE=c4.wtmart.com
export PASS=cos
export SLAVES=c1.wtmart.com:c3.wtmart.com:c4.wtmart.com
IFS=:
#1. sync ssh
sshpass -p ${PASS} scp -o StrictHostKeyChecking=no cos@${NEW_NODE}:/home/cos/.ssh/authorized_keys .
cat authorized_keys >> /home/cos/.ssh/authorized_keys
for SLAVE in $SLAVES
do
echo scp $SLAVE
sshpass -p ${PASS} scp /home/cos/.ssh/authorized_keys cos@$SLAVE:/home/cos/.ssh/authorized_keys
done
#2. sync hadoop slaves
rm /home/cos/toolkit/hadoop-1.0.3/conf/slaves
for SLAVE in $SLAVES
do
echo $SLAVE >> /home/cos/toolkit/hadoop-1.0.3/conf/slaves
done
for SLAVE in $SLAVES
do
echo scp $SLAVE
scp /home/cos/toolkit/hadoop-1.0.3/conf/slaves cos@$SLAVE:/home/cos/toolkit/hadoop-1.0.3/conf/slaves
done
#3. restart hadoop cluster
stop-all.sh
start-all.sh
重启hadoop集群,看到新的节点c4,已经加入到集群
~ hadoop dfsadmin -report
Safe mode is ON
Configured Capacity: 475598360576 (442.94 GB)
Present Capacity: 443917721600 (413.43 GB)
DFS Remaining: 443917615104 (413.43 GB)
DFS Used: 106496 (104 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 3 (3 total, 0 dead)
Name: 192.168.1.30:50010
Decommission Status : Normal
Configured Capacity: 158533136384 (147.65 GB)
DFS Used: 49152 (48 KB)
Non DFS Used: 15181529088 (14.14 GB)
DFS Remaining: 143351558144(133.51 GB)
DFS Used%: 0%
DFS Remaining%: 90.42%
Last contact: Thu Jul 11 15:55:57 CST 2013
Name: 192.168.1.32:50010
Decommission Status : Normal
Configured Capacity: 158533136384 (147.65 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8249581568 (7.68 GB)
DFS Remaining: 150283526144(139.96 GB)
DFS Used%: 0%
DFS Remaining%: 94.8%
Last contact: Thu Jul 11 15:55:56 CST 2013
Name: 192.168.1.33:50010
Decommission Status : Normal
Configured Capacity: 158532087808 (147.64 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8249528320 (7.68 GB)
DFS Remaining: 150282530816(139.96 GB)
DFS Used%: 0%
DFS Remaining%: 94.8%
Last contact: Thu Jul 11 15:55:58 CST 2013
有了这2个脚本,我们生成10个-20个节点,基本就是文件复制的时间了。
优化问题我们将继续深入进行。。。
转载请注明出处:
http://blog.fens.me/hadoop-clone-improve
