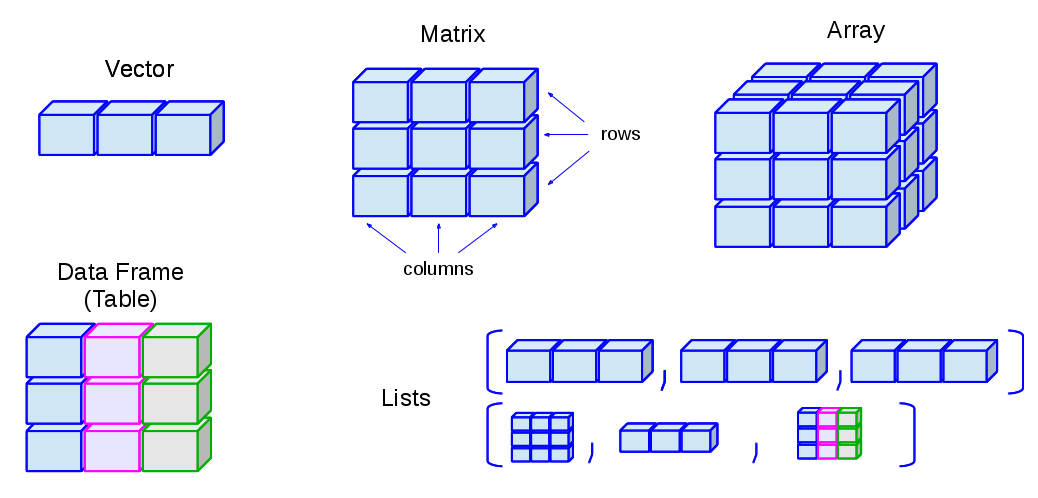
R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员/Quant: Java,R,Nodejs
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-matrix

前言
R是作为统计语言,生来就对数学有良好的支持。矩阵计算作为底层的数学工具,有非常广泛的使用场景。用R语言很好地封装了,矩阵的各种计算方法,一个函数一行代码,就能完成复杂的矩阵分解等操作。让建模人员可以更专注于模型推理和业务逻辑实现,把复杂的矩阵计算交给R语言来完成。
本文总结了R语言用于矩阵的各种计算操作。
目录
- 基本操作
- 矩阵计算
- 矩阵性质
- 矩阵分解
- 特殊矩阵
1. 基本操作
生成一个矩阵,计算行、列。
# 生成矩阵
> m<-matrix(1:20,4,5);m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
# 矩阵行
> nrow(m)
[1] 4
# 矩阵列
> ncol(m)
[1] 5
取对角线元素,生成对角矩阵,
# 对角线元素
> diag(m)
[1] 1 6 11 16
# 以对角线元素,生成对角矩阵
> diag(diag(m))
[,1] [,2] [,3] [,4]
[1,] 1 0 0 0
[2,] 0 6 0 0
[3,] 0 0 11 0
[4,] 0 0 0 16
上三角,下三角
# 上三角
> m<-matrix(1:20,4,5)
> upper.tri(m)
[,1] [,2] [,3] [,4] [,5]
[1,] FALSE TRUE TRUE TRUE TRUE
[2,] FALSE FALSE TRUE TRUE TRUE
[3,] FALSE FALSE FALSE TRUE TRUE
[4,] FALSE FALSE FALSE FALSE TRUE
# 上三角值
> m[which(upper.tri(m))]
[1] 5 9 10 13 14 15 17 18 19 20
# 上三角矩阵
> m[!upper.tri(m)]<-0;m
[,1] [,2] [,3] [,4] [,5]
[1,] 0 5 9 13 17
[2,] 0 0 10 14 18
[3,] 0 0 0 15 19
[4,] 0 0 0 0 20
# 下三角矩阵
> m[!lower.tri(m)]<-0;m
[,1] [,2] [,3] [,4] [,5]
[1,] 0 0 0 0 0
[2,] 2 0 0 0 0
[3,] 3 7 0 0 0
[4,] 4 8 12 0 0
矩阵转置
> m<-matrix(1:20,4,5);m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
# 转置,行列互转
> t(m)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
对角矩阵填充
# 创建方阵
> m<-matrix(1:16,4,4);m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
# 用上三角填充下三角
> m[lower.tri(m)]<-m[upper.tri(m)]
> m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 5 6 10 14
[3,] 9 13 11 15
[4,] 10 14 15 16
填充后,发现矩阵并不是对称的,原因是上三角取值按列取值,所以先取10后取13,导致上三角和下三角取值顺序不完全一致。
> m<-matrix(1:16,4,4);m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
# 上三角取值
> m[upper.tri(m)]
[1] 5 9 10 13 14 15
# 下三角取值
> m[lower.tri(m)]
[1] 2 3 4 7 8 12
调整后,我们要先转置,再取值再填充,形成对称结构。
> m<-matrix(1:20,4,5)
# 转置后,取下三角,填充下三角
> m[lower.tri(m)]<-t(m)[lower.tri(m)]
> m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 5 6 10 14
[3,] 9 10 11 15
[4,] 13 14 15 16
矩阵和data.frame转换,用行列形成索引结构
> m<-matrix(1:12,4,3);m
[,1] [,2] [,3]
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12
# 矩阵转行列data.frame
> row<-rep(1:nrow(m),ncol(m)) # 行
> col<-rep(1:ncol(m),each=nrow(m)) # 列
> df<-data.frame(row,col,v=as.numeric(m)) # 行列索引数据框
> df
row col v
1 1 1 1
2 2 1 2
3 3 1 3
4 4 1 4
5 1 2 5
6 2 2 6
7 3 2 7
8 4 2 8
9 1 3 9
10 2 3 10
11 3 3 11
12 4 3 12
# 行列索引数据框转矩阵
> m<-matrix(0,length(unique(df$row)),length(unique(df$col)) )
> apply(df,1,function(dat){
+ m[dat[1],dat[2]]<<-dat[3]
+ invisible()
+ })
# 打印矩阵
> m
[,1] [,2] [,3]
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12
2. 矩阵计算
加法,减法
# 加载矩阵计算工具包
> library(matrixcalc)
# 新建2个矩阵,行列长度相同
> m0<-matrix(1:20,4,5);m0
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> m1<-matrix(sample(100,20),4,5);m1
[,1] [,2] [,3] [,4] [,5]
[1,] 40 79 97 57 78
[2,] 93 32 48 8 95
[3,] 63 6 56 12 9
[4,] 28 31 72 27 26
# 矩阵加法
> m0+m1
[,1] [,2] [,3] [,4] [,5]
[1,] 41 84 106 70 95
[2,] 95 38 58 22 113
[3,] 66 13 67 27 28
[4,] 32 39 84 43 46
# 矩阵减法
> m0-m1
[,1] [,2] [,3] [,4] [,5]
[1,] -39 -74 -88 -44 -61
[2,] -91 -26 -38 6 -77
[3,] -60 1 -45 3 10
[4,] -24 -23 -60 -11 -6
矩阵值相乘
> m0*m1
[,1] [,2] [,3] [,4] [,5]
[1,] 40 395 873 741 1326
[2,] 186 192 480 112 1710
[3,] 189 42 616 180 171
[4,] 112 248 864 432 520
矩阵乘法,满足第二个矩阵的列数和第一个矩阵的行数相等,所以把上面生成的m0矩阵(4行5列)转置为(5行4列),再用m1矩阵(4行5列),进行矩阵乘法,得到一个5行5列的结果矩阵。
> t(m0)%*%m1
[,1] [,2] [,3] [,4] [,5]
[1,] 527 285 649 217 399
[2,] 1423 877 1741 633 1231
[3,] 2319 1469 2833 1049 2063
[4,] 3215 2061 3925 1465 2895
[5,] 4111 2653 5017 1881 3727
# 通过函数实现矩阵相乘
> crossprod(m0,m1)
[,1] [,2] [,3] [,4] [,5]
[1,] 527 285 649 217 399
[2,] 1423 877 1741 633 1231
[3,] 2319 1469 2833 1049 2063
[4,] 3215 2061 3925 1465 2895
[5,] 4111 2653 5017 1881 3727
矩阵外积
> m<-matrix(1:6,2);m
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> t(m)
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
> m %o% t(m) # 外积,同outer(m,t(m))
, , 1, 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2, 1
[,1] [,2] [,3]
[1,] 3 9 15
[2,] 6 12 18
, , 3, 1
[,1] [,2] [,3]
[1,] 5 15 25
[2,] 10 20 30
, , 1, 2
[,1] [,2] [,3]
[1,] 2 6 10
[2,] 4 8 12
, , 2, 2
[,1] [,2] [,3]
[1,] 4 12 20
[2,] 8 16 24
, , 3, 2
[,1] [,2] [,3]
[1,] 6 18 30
[2,] 12 24 36
矩阵直和
> m0<-matrix(1:4,2,2);m0
[,1] [,2]
[1,] 1 3
[2,] 2 4
> m1<-matrix(1:9,3,3);m1
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> m0 %s% m1 #矩阵直和,同 direct.sum(m0,m1)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 0 0 0
[2,] 2 4 0 0 0
[3,] 0 0 1 4 7
[4,] 0 0 2 5 8
[5,] 0 0 3 6 9
矩阵直积
> m0<-matrix(1:4,2,2);m0
[,1] [,2]
[1,] 1 3
[2,] 2 4
> m1<-matrix(1:9,3,3);m1
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> m0 %x% m1 #矩阵直积,同 kronecker(m0,m1),direct.prod(m0,m1)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 4 7 3 12 21
[2,] 2 5 8 6 15 24
[3,] 3 6 9 9 18 27
[4,] 2 8 14 4 16 28
[5,] 4 10 16 8 20 32
[6,] 6 12 18 12 24 36
3. 矩阵性质
3.1 奇异矩阵
首先,我们线创建一个非奇异矩阵,判断非奇异矩阵方法,行列式不等于0,矩阵可逆,满秩。
# 创建一个非奇异矩阵
> m1<-matrix(sample(1:16),4)
# 行列式不等于0
> det(m1) # !=0
[1] 14193
# 有逆矩阵
> solve(m1) # 可逆
[,1] [,2] [,3] [,4]
[1,] -0.026210104 0.09666737 0.02473050 -0.119988727
[2,] -0.002325090 0.08384415 -0.07038681 0.008173043
[3,] -0.007186641 -0.13478475 0.05516804 0.176777285
[4,] 0.074614246 0.03663778 -0.01395054 -0.080462200
# 满秩
> library(matrixcalc)
> matrix.rank(m1) # 长度=n,满秩
[1] 4
再创建一个奇异矩阵,判断奇异矩阵方法包括,行列式等于0,矩阵不可逆,不是满秩。
# 奇异矩阵
> m0<-matrix(1:16,4)
# 计算行列式
> det(m0)
[1] 0
# 不可逆
> solve(m0)
Error in solve.default(m0) :
Lapack routine dgesv: system is exactly singular: U[3,3] = 0
# 不是满秩
> matrix.rank(m0) # 长度<4
[1] 2
3.2 逆矩阵
# 创建方阵,非奇异矩阵
> m0<-matrix(sample(100,16),4,4);m0
[,1] [,2] [,3] [,4]
[1,] 24 31 80 37
[2,] 84 13 42 71
[3,] 95 62 93 86
[4,] 69 16 94 35
# 计算矩阵的逆矩阵
> solve(m0)
[,1] [,2] [,3] [,4]
[1,] -0.03083680 -0.0076561475 0.01258023 0.017218514
[2,] -0.01710957 -0.0270246488 0.03152548 -0.004553923
[3,] 0.01384721 -0.0003070371 -0.00886117 0.007757524
[4,] 0.03142440 0.0282722871 -0.01541411 -0.024126340
# 逆矩阵的性质,逆矩阵与原矩阵进行矩阵乘法,得到对角矩阵。
> round(solve(m0) %*% m0) # 对角矩阵
[,1] [,2] [,3] [,4]
[1,] 1 0 0 0
[2,] 0 1 0 0
[3,] 0 0 1 0
[4,] 0 0 0 1
广义逆矩阵,将逆矩阵的概率推广到奇异矩阵和长方形矩阵上,就产生了广义逆矩阵。
# 创建奇异矩阵
> m<-matrix(1:16,4,4);m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
# 逆矩阵计算失败
> solve(m)
Error in solve.default(m) :
Lapack routine dgesv: system is exactly singular: U[3,3] = 0
# 广义逆矩阵
> library(MASS) # 加载MASS包
> ginv(m)
[,1] [,2] [,3] [,4]
[1,] -0.285 -0.1075 0.07 0.2475
[2,] -0.145 -0.0525 0.04 0.1325
[3,] -0.005 0.0025 0.01 0.0175
[4,] 0.135 0.0575 -0.02 -0.0975
用ginv函数计算非奇异矩阵,和solve()函数比较。
# 非奇异矩阵
> m0<-matrix(sample(100,16),4,4);m0
[,1] [,2] [,3] [,4]
[1,] 5 61 75 74
[2,] 10 67 11 21
[3,] 29 32 92 17
[4,] 72 23 87 36
# 计算广义矩阵的逆矩阵,与solve()结果相同
> ginv(m0)
[,1] [,2] [,3] [,4]
[1,] -0.0080590817 0.006534814 -0.011333076 0.018105645
[2,] -0.0041284695 0.017615769 0.005333304 -0.004308072
[3,] 0.0009226026 -0.006671759 0.016312821 -0.005707878
[4,] 0.0165261737 -0.008200731 -0.020163889 0.008112906
# 计算矩阵的逆矩阵
> solve(m0)
[,1] [,2] [,3] [,4]
[1,] -0.0080590817 0.006534814 -0.011333076 0.018105645
[2,] -0.0041284695 0.017615769 0.005333304 -0.004308072
[3,] 0.0009226026 -0.006671759 0.016312821 -0.005707878
[4,] 0.0165261737 -0.008200731 -0.020163889 0.008112906
逆矩阵的特性
> m<-matrix(1:16,4,4);m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
# 原矩阵%*%广义逆矩阵%*%原矩阵=原矩阵
> m %*% ginv(m) %*% m
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
# 广义逆矩阵%*%原矩阵%*%广义逆矩阵=广义逆矩阵
> ginv(m) %*% m %*% ginv(m)
[,1] [,2] [,3] [,4]
[1,] -0.285 -0.1075 0.07 0.2475
[2,] -0.145 -0.0525 0.04 0.1325
[3,] -0.005 0.0025 0.01 0.0175
[4,] 0.135 0.0575 -0.02 -0.0975
# 原矩阵%*%广义逆矩阵=转置后的,原矩阵%*%广义逆矩阵
> m %*% ginv(m)
[,1] [,2] [,3] [,4]
[1,] 0.7 0.4 0.1 -0.2
[2,] 0.4 0.3 0.2 0.1
[3,] 0.1 0.2 0.3 0.4
[4,] -0.2 0.1 0.4 0.7
> t(m %*% ginv(m))
[,1] [,2] [,3] [,4]
[1,] 0.7 0.4 0.1 -0.2
[2,] 0.4 0.3 0.2 0.1
[3,] 0.1 0.2 0.3 0.4
[4,] -0.2 0.1 0.4 0.7
# 广义逆矩阵%*%原矩阵=转置后的,广义逆矩阵%*%原矩阵
> ginv(m) %*% m
[,1] [,2] [,3] [,4]
[1,] 0.7 0.4 0.1 -0.2
[2,] 0.4 0.3 0.2 0.1
[3,] 0.1 0.2 0.3 0.4
[4,] -0.2 0.1 0.4 0.7
> t(ginv(m) %*% m)
[,1] [,2] [,3] [,4]
[1,] 0.7 0.4 0.1 -0.2
[2,] 0.4 0.3 0.2 0.1
[3,] 0.1 0.2 0.3 0.4
[4,] -0.2 0.1 0.4 0.7
3.3 特征值和特征向量
# 创建一个方阵
> m0<-matrix(sample(100,16),4,4);m0
[,1] [,2] [,3] [,4]
[1,] 97 93 11 70
[2,] 19 58 23 90
[3,] 17 94 6 35
[4,] 79 71 43 88
# 计算特征值和特征向量
> eigen(m0)
eigen() decomposition
$values
[1] 236.14449+ 0.00000i 40.51501+ 0.00000i -13.82975+32.81166i -13.82975-32.81166i
$vectors
[,1] [,2] [,3] [,4]
[1,] 0.6055193+0i -0.6428709+0i 0.2114869-0.0613776i 0.2114869+0.0613776i
[2,] 0.4115920+0i 0.3939259+0i -0.0781518+0.3993580i -0.0781518-0.3993580i
[3,] 0.3054253+0i 0.6482306+0i 0.7557355+0.0000000i 0.7557355+0.0000000i
[4,] 0.6088134+0i -0.1064728+0i -0.3210016-0.3342655i -0.3210016+0.3342655i
当symmetric=TRUE时,计算对称矩阵的特征值和特征向量,当m0不是对称矩阵时,则取下三角对称结构进行计算。
> eigen(m0,symmetric = TRUE)
eigen() decomposition
$values
[1] 231.824838 87.176816 -3.422899 -66.578756
$vectors
[,1] [,2] [,3] [,4]
[1,] -0.4801643 0.7155875 0.5040624 -0.05742733
[2,] -0.5024315 -0.5470752 0.2262475 -0.63014551
[3,] -0.3634220 -0.4138943 0.3287896 0.76714627
[4,] -0.6204267 0.1316618 -0.7659181 0.10538188
# 生成下三角矩阵的对称矩阵
> m0[upper.tri(m0)]<-t(m0)[upper.tri(m0)];m0
[,1] [,2] [,3] [,4]
[1,] 97 19 17 79
[2,] 19 58 94 71
[3,] 17 94 6 43
[4,] 79 71 43 88
# 计算特征值,与eigen(m0,symmetric = TRUE) 一致
> eigen(m0)
eigen() decomposition
$values
[1] 231.824838 87.176816 -3.422899 -66.578756
$vectors
[,1] [,2] [,3] [,4]
[1,] -0.4801643 0.7155875 0.5040624 -0.05742733
[2,] -0.5024315 -0.5470752 0.2262475 -0.63014551
[3,] -0.3634220 -0.4138943 0.3287896 0.76714627
[4,] -0.6204267 0.1316618 -0.7659181 0.10538188
4. 矩阵分解
下面将介绍4种矩阵常用的分解的方法,包括三解分解LU,choleskey分解,QR分解,奇异值分解SVD。
4.1 三解分解LU
三角分解法是将原方阵分解成一个上三角形矩阵和一个下三角形矩阵,这样的分解法又称为LU分解法。它的用途主要在简化一个大矩阵的行列式值的计算过程,求逆矩阵,和求解联立方程组。这种分解法所得到的上下三角形矩阵不唯一,一对上三角形矩阵和下三角形矩阵,矩阵相乘会得到原矩阵。
创建一个矩阵
> m0<-matrix(sample(100,16),4);m0
[,1] [,2] [,3] [,4]
[1,] 25 88 35 87
[2,] 26 75 73 15
[3,] 36 62 80 53
[4,] 70 44 21 47
# 三角分解
> lu<-lu.decomposition(m0)
> lu
$L # 下三角矩阵
[,1] [,2] [,3] [,4]
[1,] 1.00 0.000000 0.000000 0
[2,] 1.04 1.000000 0.000000 0
[3,] 1.44 3.917676 1.000000 0
[4,] 2.80 12.251816 4.617547 1
$U # 上三角矩阵
[,1] [,2] [,3] [,4]
[1,] 25 88.00 35.0000 87.0000
[2,] 0 -16.52 36.6000 -75.4800
[3,] 0 0.00 -113.7869 223.4262
[4,] 0 0.00 0.0000 -303.5137
# 三角分解的下三角矩阵L %*% 三角分解的上三角矩阵U = 原矩阵
> lu$L %*% lu$U
[,1] [,2] [,3] [,4]
[1,] 25 88 35 87
[2,] 26 75 73 15
[3,] 36 62 80 53
[4,] 70 44 21 47
4.2 choleskey分解
Cholesky 分解是把一个对称正定的矩阵表示成一个下三角矩阵L和其转置的乘积的分解。它要求矩阵的所有特征值必须大于零,故分解的下三角的对角元也是大于零的。Cholesky分解法又称平方根法,是当A为实对称正定矩阵时,LU三角分解法的变形。
创建对称方阵
> m1<-diag(5)+2;m1
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# choleskey分解
> chol(m1)
[,1] [,2] [,3] [,4] [,5]
[1,] 1.732051 1.154701 1.1547005 1.1547005 1.1547005
[2,] 0.000000 1.290994 0.5163978 0.5163978 0.5163978
[3,] 0.000000 0.000000 1.1832160 0.3380617 0.3380617
[4,] 0.000000 0.000000 0.0000000 1.1338934 0.2519763
[5,] 0.000000 0.000000 0.0000000 0.0000000 1.1055416
# choleskey分解的性质
# chol分解的逆矩阵 %*% chol分解矩阵 = 原矩阵
> t(chol(m1))%*%chol(m1)
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# chol分解矩阵的对角线值的平方的积 = 行列式的模数
> prod(diag(chol(m1))^2)
[1] 11
> det(m1)
[1] 11
# chol分解的逆
> chol2inv(m1)
[,1] [,2] [,3] [,4] [,5]
[1,] 0.166658199 -0.055580958 -0.01859473 -0.006401463 -0.002743484
[2,] -0.055580958 0.166590459 -0.05578418 -0.019204390 -0.008230453
[3,] -0.018594726 -0.055784179 0.16598080 -0.057613169 -0.024691358
[4,] -0.006401463 -0.019204390 -0.05761317 0.160493827 -0.074074074
[5,] -0.002743484 -0.008230453 -0.02469136 -0.074074074 0.111111111
> chol2inv(chol(m1))
[,1] [,2] [,3] [,4] [,5]
[1,] 0.8181818 -0.1818182 -0.1818182 -0.1818182 -0.1818182
[2,] -0.1818182 0.8181818 -0.1818182 -0.1818182 -0.1818182
[3,] -0.1818182 -0.1818182 0.8181818 -0.1818182 -0.1818182
[4,] -0.1818182 -0.1818182 -0.1818182 0.8181818 -0.1818182
[5,] -0.1818182 -0.1818182 -0.1818182 -0.1818182 0.8181818
4.3 QR分解
QR分解法是将矩阵分解成一个正规正交矩阵与上三角形矩阵,所以称为QR分解法,与此正规正交矩阵的通用符号Q有关。
# 创建对称方阵
> m1<-diag(5)+2;m1
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# QR分解
> q<-qr(m1);q
$qr
[,1] [,2] [,3] [,4] [,5]
[1,] -5.0 -4.8000000 -4.8000000 -4.8000000 -4.8000000
[2,] 0.4 -1.4000000 -0.6857143 -0.6857143 -0.6857143
[3,] 0.4 0.2142857 -1.2205720 -0.4012839 -0.4012839
[4,] 0.4 0.2142857 0.1560549 -1.1527216 -0.2852095
[5,] 0.4 0.2142857 0.1560549 0.1246843 1.1168808
$rank
[1] 5
$qraux
[1] 1.600000 1.928571 1.975343 1.992196 1.116881
$pivot
[1] 1 2 3 4 5
attr(,"class")
[1] "qr"
# 计算QR分解矩阵的R值
> qr.R(q)
[,1] [,2] [,3] [,4] [,5]
[1,] -5 -4.8 -4.8000000 -4.8000000 -4.8000000
[2,] 0 -1.4 -0.6857143 -0.6857143 -0.6857143
[3,] 0 0.0 -1.2205720 -0.4012839 -0.4012839
[4,] 0 0.0 0.0000000 -1.1527216 -0.2852095
[5,] 0 0.0 0.0000000 0.0000000 1.1168808
# 计算QR分解矩阵的Q值
> qr.Q(q)
[,1] [,2] [,3] [,4] [,5]
[1,] -0.6 0.62857143 0.36784361 0.26144202 -0.2030692
[2,] -0.4 -0.77142857 0.36784361 0.26144202 -0.2030692
[3,] -0.4 -0.05714286 -0.85272836 0.26144202 -0.2030692
[4,] -0.4 -0.05714286 -0.03344033 -0.89127960 -0.2030692
[5,] -0.4 -0.05714286 -0.03344033 -0.02376746 0.9138115
# QR分解的性质
# Q的值 %*% R值 = 原矩阵
> qr.Q(q) %*% qr.R(q) #=m1
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# X值 = 原矩阵,同Q的值 %*% R值
> qr.X(q) #=m1
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# Q值的转置矩阵 * Q值 =
> t(qr.Q(q)) %*% qr.Q(q)
[,1] [,2] [,3] [,4] [,5]
[1,] 1.000000e+00 -3.469447e-17 -2.081668e-17 1.214306e-17 5.551115e-17
[2,] -3.469447e-17 1.000000e+00 7.199102e-17 5.204170e-17 -7.632783e-17
[3,] -2.081668e-17 7.199102e-17 1.000000e+00 3.382711e-17 -6.938894e-18
[4,] 1.214306e-17 5.204170e-17 3.382711e-17 1.000000e+00 3.122502e-17
[5,] 5.551115e-17 -7.632783e-17 -6.938894e-18 3.122502e-17 1.000000e+00
4.4 奇异值分解SVD
奇异值分解 (singular value decomposition, SVD) 是一种正交矩阵分解法。SVD是最可靠的分解法,但是它比QR 分解法要花上近十倍的计算时间。[U,S,V]=svd(A),其中U和V分别代表两个正交矩阵,而S代表一对角矩阵。 和QR分解法相同, 原矩阵A不必为正方矩阵。使用SVD分解法的用途是解最小平方误差法和数据压缩。
# 创建对称方阵
> m1<-diag(5)+2;m1
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# 奇异值分解
> s<-svd(m1);s
$d
[1] 11 1 1 1 1
$u
[,1] [,2] [,3] [,4] [,5]
[1,] -0.4472136 4.440892e-17 -3.330669e-17 -3.108624e-16 0.8944272
[2,] -0.4472136 -3.219647e-16 2.414735e-16 8.660254e-01 -0.2236068
[3,] -0.4472136 -5.773503e-01 5.773503e-01 -2.886751e-01 -0.2236068
[4,] -0.4472136 -2.113249e-01 -7.886751e-01 -2.886751e-01 -0.2236068
[5,] -0.4472136 7.886751e-01 2.113249e-01 -2.886751e-01 -0.2236068
$v
[,1] [,2] [,3] [,4] [,5]
[1,] -0.4472136 0.000000e+00 0.000000e+00 0.0000000 0.8944272
[2,] -0.4472136 -1.665335e-16 1.457168e-16 0.8660254 -0.2236068
[3,] -0.4472136 -5.773503e-01 5.773503e-01 -0.2886751 -0.2236068
[4,] -0.4472136 -2.113249e-01 -7.886751e-01 -0.2886751 -0.2236068
[5,] -0.4472136 7.886751e-01 2.113249e-01 -0.2886751 -0.2236068
# 奇异分解性质
# svd的u矩阵 %*% svd的d矩阵的对角性值 %*% svd的v的转置矩阵 = 原矩阵
> s$u %*% diag(s$d) %*% t(s$v) #=m1
[,1] [,2] [,3] [,4] [,5]
[1,] 3 2 2 2 2
[2,] 2 3 2 2 2
[3,] 2 2 3 2 2
[4,] 2 2 2 3 2
[5,] 2 2 2 2 3
# svd的u矩阵的转置矩阵 %*% svd的u矩阵 = svd的s矩阵的转置矩阵 %*% svd的v矩阵
> t(s$u) %*% s$u
[,1] [,2] [,3] [,4] [,5]
[1,] 1.000000e+00 0.000000e+00 -5.551115e-17 0.000000e+00 -2.775558e-17
[2,] 0.000000e+00 1.000000e+00 -2.775558e-17 -1.387779e-16 8.326673e-17
[3,] -5.551115e-17 -2.775558e-17 1.000000e+00 6.245005e-17 -6.938894e-17
[4,] 0.000000e+00 -1.387779e-16 6.245005e-17 1.000000e+00 -1.387779e-16
[5,] -2.775558e-17 8.326673e-17 -6.938894e-17 -1.387779e-16 1.000000e+00
> t(s$v) %*% s$v
[,1] [,2] [,3] [,4] [,5]
[1,] 1.000000e+00 0.000000e+00 5.551115e-17 -1.665335e-16 2.775558e-17
[2,] 0.000000e+00 1.000000e+00 8.326673e-17 -8.326673e-17 0.000000e+00
[3,] 5.551115e-17 8.326673e-17 1.000000e+00 1.595946e-16 2.775558e-17
[4,] -1.665335e-16 -8.326673e-17 1.595946e-16 1.000000e+00 -8.326673e-17
[5,] 2.775558e-17 0.000000e+00 2.775558e-17 -8.326673e-17 1.000000e+00
5. 特殊矩阵
下面介绍的多种特殊矩阵,都是在matrixcalc库中提供的。
5.1 Hankel Matrix
汉克尔矩阵 (Hankel Matrix) 是具有恒定倾斜对角线的方形矩阵。 Hankel矩阵的行列式称为catalecticant。该函数根据n向量x的值构造n阶Hankel矩阵。 矩阵的每一行是前一行中值的循环移位。
矩阵定义:
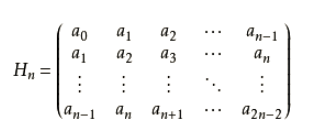
> hankel.matrix(6, 1:50)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 2 3 4 5 6
[2,] 2 3 4 5 6 7
[3,] 3 4 5 6 7 8
[4,] 4 5 6 7 8 9
[5,] 5 6 7 8 9 10
[6,] 6 7 8 9 10 11
5.2 Hilbert Matrix
希尔伯特矩阵是一种数学变换矩阵,正定,且高度病态(即,任何一个元素发生一点变动,整个矩阵的行列式的值和逆矩阵都会发生巨大变化),病态程度和阶数相关。希尔伯特矩阵是一种特殊的汉克尔矩阵,该函数返回n乘n希尔伯特矩阵。
矩阵定义:
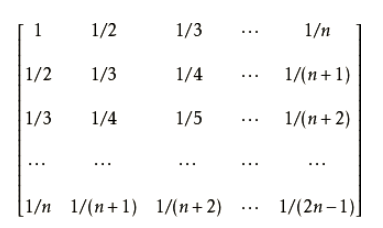
> hilbert.matrix(4)
[,1] [,2] [,3] [,4]
[1,] 1.0000000 0.5000000 0.3333333 0.2500000
[2,] 0.5000000 0.3333333 0.2500000 0.2000000
[3,] 0.3333333 0.2500000 0.2000000 0.1666667
[4,] 0.2500000 0.2000000 0.1666667 0.1428571
5.3 Creation Matrix
创造矩阵,n阶创建矩阵也称为推导矩阵,该函数返回阶数n创建矩阵,在主对角线下方的子对角线上具有序列1,2,…,n-1的方阵。
矩阵定义:

> creation.matrix(5)
[,1] [,2] [,3] [,4] [,5]
[1,] 0 0 0 0 0
[2,] 1 0 0 0 0
[3,] 0 2 0 0 0
[4,] 0 0 3 0 0
[5,] 0 0 0 4 0
5.4 Stirling Matrix
斯特林公式(Stirling’s approximation)是一条用来取n的阶乘的近似值的数学公式。一般来说,当n很大的时候,n阶乘的计算量十分大,所以斯特林公式十分好用,而且,即使在n很小的时候,斯特林公式的取值已经十分准确。
斯特林矩阵(Stirling Matrix),该函数构造并返回斯特林矩阵,该矩阵是包含第二类斯特林数的下三角矩阵。
矩阵定义:

> stirling.matrix(4)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 0 0 0 0
[2,] 0 1 0 0 0
[3,] 0 1 1 0 0
[4,] 0 1 3 1 0
[5,] 0 1 7 6 1
5.5 Pascal matrix
帕斯卡矩阵:由杨辉三角形表组成的矩阵称为帕斯卡(Pascal)矩阵。此函数返回n乘以Pascal矩阵。在数学中,尤其是矩阵理论和组合学,Pascal矩阵是一个下三角矩阵,行中有二项式系数。 通过对相同顺序的对称Pascal矩阵执行LU分解并返回下三角矩阵,可以容易地获得它。
帕斯卡的三角形是由数字行组成的三角形。 第一行具有条目1.每个后续行通过添加前一行的相邻条目而形成,替换为0,其中不存在相邻条目。 pascal函数通过选择与指定矩阵维度相对应的Pascal三角形部分来形成Pascal矩阵,
矩阵定义:

> pascal.matrix(4)
[,1] [,2] [,3] [,4]
[1,] 1 0 0 0
[2,] 1 1 0 0
[3,] 1 2 1 0
[4,] 1 3 3 1
5.6 Fibonacci matrix
斐波纳契矩阵,该函数构造了从Fibonacci序列导出的n + 1平方Fibonacci矩阵。
计算公式:
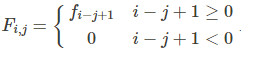
> fibonacci.matrix(4)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 1 0 0 0
[2,] 2 1 1 0 0
[3,] 3 2 1 1 0
[4,] 5 3 2 1 1
[5,] 8 5 3 2 1
5.7 Frobenius Matrix
Frobenius矩阵也称为伴随矩阵,它出现在线性一阶微分方程组的解中。
此函数返回一个在数值数学中有用的Fronenius矩阵。
矩阵定义:
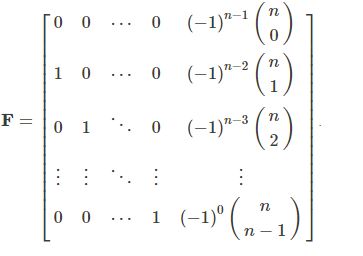
> frobenius.matrix(4)
[,1] [,2] [,3] [,4]
[1,] 0 0 0 -1
[2,] 1 0 0 4
[3,] 0 1 0 -6
[4,] 0 0 1 4
5.8 Duplication matrix
复制矩阵,当A是对称矩阵时,该函数构造将vech(A)映射到vec(A)的线性变换D.
计算公式:
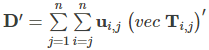
> D.matrix(3)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 0 0 0 0 0
[2,] 0 1 0 0 0 0
[3,] 0 0 1 0 0 0
[4,] 0 1 0 0 0 0
[5,] 0 0 0 1 0 0
[6,] 0 0 0 0 1 0
[7,] 0 0 1 0 0 0
[8,] 0 0 0 0 1 0
[9,] 0 0 0 0 0 1
5.9 K matrix
k矩阵是由H.matrices()函数构造的,利用直积进行计算子列表的分量。K.matrix(r, c = r),返回阶数为p = r * c的方阵,对于r行c列的矩阵A,计算A和t(A)的直积。
计算公式:

> K.matrix(2,3)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 0 0 0 0 0
[2,] 0 0 1 0 0 0
[3,] 0 0 0 0 1 0
[4,] 0 1 0 0 0 0
[5,] 0 0 0 1 0 0
[6,] 0 0 0 0 0 1
5.10 E Matrices
E矩阵列表,E.matrices(n)使得每个子列表的分量,是从n阶单位矩阵计算向量的外积导出的方阵。
计算公式:
![]()
> E.matrices(3)
[[1]]
[[1]][[1]]
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 0 0 0
[3,] 0 0 0
[[1]][[2]]
[,1] [,2] [,3]
[1,] 0 1 0
[2,] 0 0 0
[3,] 0 0 0
[[1]][[3]]
[,1] [,2] [,3]
[1,] 0 0 1
[2,] 0 0 0
[3,] 0 0 0
[[2]]
[[2]][[1]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 1 0 0
[3,] 0 0 0
[[2]][[2]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 1 0
[3,] 0 0 0
[[2]][[3]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 1
[3,] 0 0 0
[[3]]
[[3]][[1]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
[3,] 1 0 0
[[3]][[2]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
[3,] 0 1 0
[[3]][[3]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
[3,] 0 0 1
5.11 H Matrices
H矩阵列表,H.matrices(r, c = r)使得r阶c阶的子列表的分量,计算从r行和c列的单位矩阵的列向量的外积导出的方阵。
> H.matrices(2,3)
[[1]]
[[1]][[1]]
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 0 0 0
[[1]][[2]]
[,1] [,2] [,3]
[1,] 0 1 0
[2,] 0 0 0
[[1]][[3]]
[,1] [,2] [,3]
[1,] 0 0 1
[2,] 0 0 0
[[2]]
[[2]][[1]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 1 0 0
[[2]][[2]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 1 0
[[2]][[3]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 1
5.12 T Matrices
T矩阵列表,T.matrices(n) 高级别列表中的组件数为n。 n个组件中的每一个也是列表。 每个子列表具有n个分量,每个分量是n阶矩阵。
计算公式:
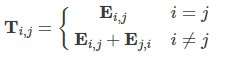
> T.matrices(3)
[[1]]
[[1]][[1]]
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 0 0 0
[3,] 0 0 0
[[1]][[2]]
[,1] [,2] [,3]
[1,] 0 1 0
[2,] 1 0 0
[3,] 0 0 0
[[1]][[3]]
[,1] [,2] [,3]
[1,] 0 0 1
[2,] 0 0 0
[3,] 1 0 0
[[2]]
[[2]][[1]]
[,1] [,2] [,3]
[1,] 0 1 0
[2,] 1 0 0
[3,] 0 0 0
[[2]][[2]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 1 0
[3,] 0 0 0
[[2]][[3]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 1
[3,] 0 1 0
[[3]]
[[3]][[1]]
[,1] [,2] [,3]
[1,] 0 0 1
[2,] 0 0 0
[3,] 1 0 0
[[3]][[2]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 1
[3,] 0 1 0
[[3]][[3]]
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
[3,] 0 0 1
通过R语言,我们实现了对于矩阵的各种计算操作,非常方便!有了好的工具,不管是学习还是应用,都会事半功倍。本文只是列举了矩阵的操作方法,没有解释计算的推到过程,推到过程请参考线性代码的教科书。
转载请注明出处:
http://blog.fens.me/r-matrix